Inferential Statistics
Preview Question
Question
 What is the value of the experimental method for testing cause–
What is the value of the experimental method for testing cause–
Let’s introduce inferential statistics in the context of an important empirical question: Does driving while talking on a cell phone affect one’s driving? Many legislators seem to think so: As of this writing, the use of handheld cellular telephones while driving has been banned in 14 states plus Washington, D.C., Puerto Rico, Guam, and the U.S. Virgin Islands. Many other states have left it to local jurisdictions to ban their use, including Massachusetts, Michigan, Ohio, and Pennsylvania. Note, however, that no state currently bans all drivers from using hands-
A-
Hunton and Rose (2005) investigated our opening question experimentally. They tested the hypothesis that driving performance would grow increasingly worse across three conditions: (1) during no conversation, (2) during a conversation with a passenger, and (3) during a hands-
A-
| Number of Errors Committed in Passenger Versus Cell- |
|
|---|---|
|
Passenger Condition |
Cell- |
|
3 |
5 |
|
3 |
5 |
|
5 |
7 |
|
5 |
7 |
|
5 |
7 |
|
5 |
7 |
|
7 |
9 |
|
7 |
9 |
|
7 |
9 |
|
7 |
9 |
|
7 |
9 |
|
7 |
9 |
|
9 |
11 |
|
9 |
11 |
|
9 |
11 |
|
9 |
11 |
|
11 |
13 |
|
11 |
13 |
|
ΣX = 126 N (or n) = 18 μ (or M) = 7 σ (or s) = 2.38 |
ΣX = 162 N (or n) = 18 μ (or M) = 9 σ (or s) = 2.38 |
The descriptive statistics indicate that the means between these two experimental conditions are different; those who used a hands-
Based on the means, can you now conclude that hands-
Recall from Chapter 2 that in order to comfortably make the claim that a manipulation caused changes in a dependent variable, you have to hold all other factors constant—
So, did this study (Hunton & Rose, 2005) pass this test? First, take a moment to think about what possible individual differences could have influenced participants’ performance during the driving simulations. If you reasoned that differences in individuals’ driving skills could be a factor, then you are on the same page as the researchers. How might they have controlled for these differences? People’s driving skills were controlled by—
Of course, the researchers also had to be very careful to rule out alternative explanations having to do with the research procedure, so they held a number of environmental variables constant. For instance, participants in both conditions were told that the purpose of the study was to test the quality of the simulation software and that they would be observed by a representative of the manufacturer. The “representative,” who was actually a confederate of the researchers, was instructed to ask participants the same set of questions, in the same order, and at the same pace. This way, if the groups did differ, no one could argue that it was due to differences in the way they experienced the experimental procedure.
A-
In summary, the researchers (Hunton & Rose, 2005) ruled out several alternative explanations for any differences they observed in the number of errors by randomly assigning participants to conditions and by treating both groups in exactly the same way, except for the manipulation. Are you justified in concluding that hands-
WHAT DO YOU KNOW?…
Question A.10
A researcher wanted to test the hypothesis that when someone hears a description of a person, the traits presented first in a list will be more influential in forming an impression than those presented last. She asked participants to listen to her as she read a list of traits describing an individual, then to rate how much they like her. Half the participants were randomly assigned to a condition in which positive words were presented first, and half to a condition in which positive words were presented last.
- j1kIchCm/WGF0eMvCyhY1nbEGBzByUZJOu/VHPpRwxPuyAIcjJZwyap6+KjHsxwcYz1CaeXkE55/pc1zeUMEkIWJqnI+nGPwTA2EBz2vI0OqB65F57PvhhwtBcXxmE8Kp0iGMY1k8WCCMTUKPfLh0ZgLbKROO7GUnGyNtTg90ozezNNA
- NtpXZLx3KTZ3n+cau2K5vXv0f0anG0LbEc9QZHSwDROb9VHlunHIep6OCby6uqL1SrJpf+M8Am9ln2EAbsmfbzHSUZ+avAr0HMLCYq4Rg4xsrdI3Gm7LSyb/6+hoXMPQGDIQHdE4wymCKaR6hbN7nP+zcw7t1yzskKDJpWwHozIxdwBWDDcyew+CNxGIl55EIWvxc3rVa+aT6c10XMthHTtQakXK/WTpfw4DMod2Mjl6QgIQJV+J4yX6iIQqQW26
a. She randomly assigned participants to conditions. b. It would have been important for her to hold constant the rate at which she read the traits. Other answers are possible.
Were the Observed Differences Due to Chance?
Preview Question
Question
How do researchers determine whether the differences they observe in an experiment are due to the effect of their manipulation or due to chance?
Imagine for the moment that someone wants to convince you he has a magic coin. You know that if the coin were not magic, and he were to flip it a bazillion times, there is a 50-
Here is your challenge, then: You want to test the hypothesis that this is a magic coin. You know that the most thorough and convincing test of this hypothesis would involve flipping the coin an infinite number of times, but by definition you cannot do that. Researchers face a similar problem when they want to test their hypotheses. For example, imagine a researcher wanted to test the hypothesis that the majority of the people in New Haven, Connecticut, prefer organically grown produce to conventionally grown produce. She knows that the most convincing test of this hypothesis would involve asking the entire population of New Havenites their preference, but she has neither the time nor the funding to do so. What would you recommend she do? If you carefully read Chapter 2, you recognize that this situation calls for representative sampling. You might recommend that she randomly select a sample of New Havenites, ask them “Do you prefer organically grown produce to conventionally grown produce?” then tabulate her results.
A-
Imagine she finds that 56% of those sampled said they prefer organically grown produce. Can she reasonably conclude that her hypothesis is correct? Alert readers will point out that this depends entirely on how successful she was in selecting a representative sample. Even if the majority of people in New Haven prefer conventionally grown produce, she could, by chance alone, have randomly selected a sample that included a majority of people who prefer organic. How can she find out whether her results are attributable to chance? She might begin by asking, “If I repeatedly sampled the population of New Havenites, how often would I find results that disconfirmed my hypothesis?” As explained below, this is the question that essentially drives inferential statistics.
THE NULL VERSUS ALTERNATIVE HYPOTHESIS. The researcher above was interested in testing the hypothesis that most of the people of New Haven preferred organically grown produce. For the sake of introducing hypothesis testing, though, it may help to go back to the study that asked whether driving while talking with a hands-
You will start by hypothesizing that in the populations from which you drew your samples, there are no differences in safety between those who talk to passengers and those who talk on cell phones. Why? Odd as it may sound, when researchers want to test a hypothesis, they begin by assuming it’s not true. In doing so, they test what is called the null hypothesis—which states that no relationship exists between the variables they are observing and that any relationship they do observe is attributable to chance. The null hypothesis for this particular study is that in the population of drivers who talk to passengers, people commit the same number of errors, on average, as in the population of drivers who talk on cell phones.
The hypothesis you are truly interested in, of course, is that there is a difference in the mean number of errors committed between the population of people who talk on a hands-
THE DISTRIBUTION OF SAMPLE MEANS AND SAMPLING ERROR. Earlier, you learned that when you sample from a population, you’re not always going to draw samples whose means perfectly represent the population’s mean. By chance alone, you could draw samples whose means differ from the mean of the population. The difference between the mean of the population and the means of the samples drawn from it is called sampling error.
To illustrate sampling error, imagine that you have a (very small) population consisting of four people whose scores are: 4, 6, 8, and 10, with a mean of 7. If you were to repeatedly draw samples of two people from this population, then replace them, how often would you obtain samples whose means were also 7? You can find out by listing all the possible combinations of samples of n = 2 people. Table A-
A-
| All Possible Samples of n = 2 from a Population in Which N = 4, and the Scores Are 4, 6, 8, and 10 | |||
|---|---|---|---|
| Sample Number | First Score | Second Score | Sample Means |
|
1 |
4 |
4 |
4 |
|
2 |
4 |
6 |
5 |
|
3 |
4 |
8 |
6 |
|
4 |
4 |
10 |
7 |
|
5 |
6 |
4 |
5 |
|
6 |
6 |
6 |
6 |
|
7 |
6 |
8 |
7 |
|
8 |
6 |
10 |
8 |
|
9 |
8 |
4 |
6 |
|
10 |
8 |
6 |
7 |
|
11 |
8 |
8 |
8 |
|
12 |
8 |
10 |
9 |
|
13 |
10 |
4 |
7 |
|
14 |
10 |
6 |
8 |
|
15 |
10 |
8 |
9 |
|
16 |
10 |
10 |
10 |
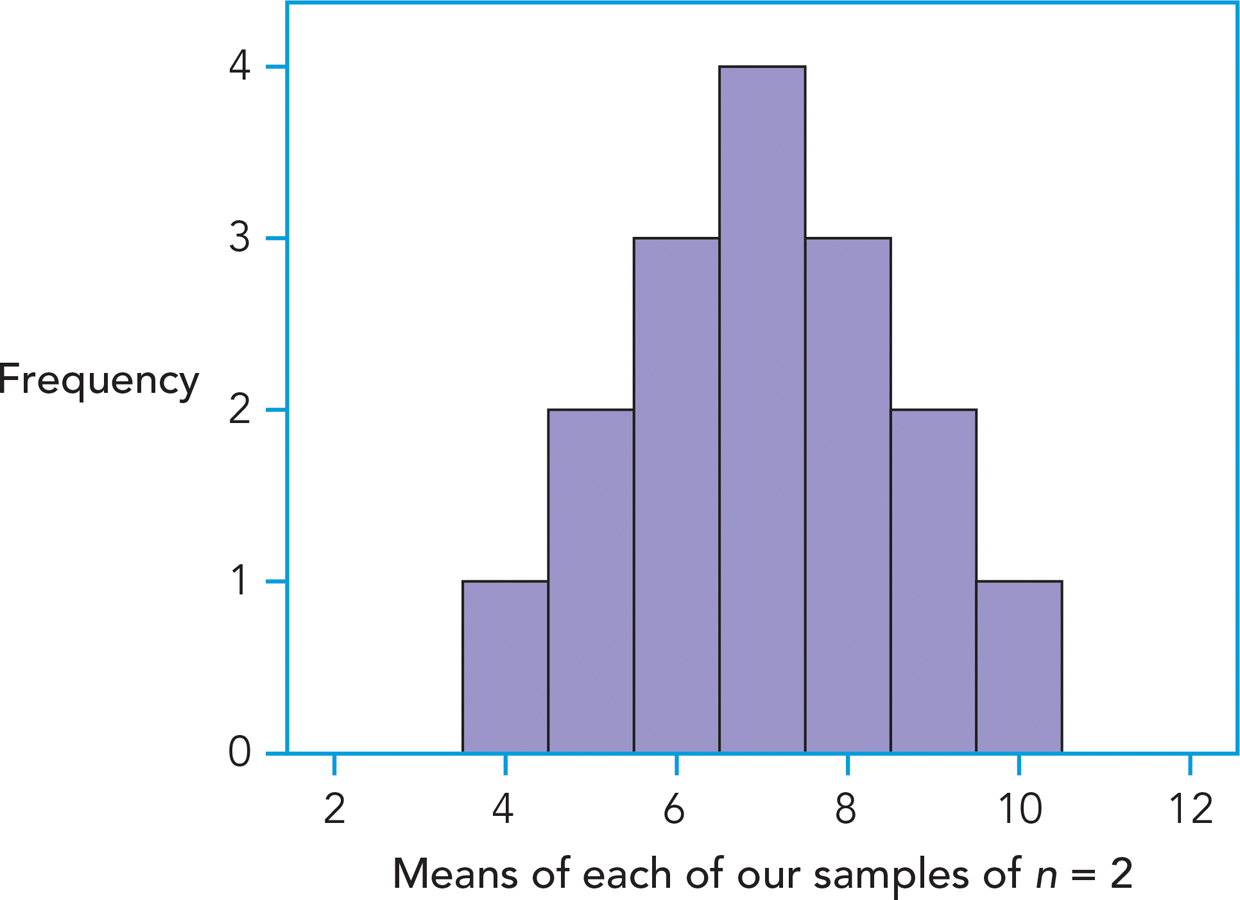
Each of those means is plotted on the frequency distribution graph depicted in Figure A-
A-
What you just constructed by plotting the sample means for all possible combinations of samples is a distribution of sample means, which is a hypothetical distribution of all possible sample means of a given sample size from a specified population. Do researchers really plot the means for all possible combinations of samples? No, they don’t. As you’ve probably figured out by now, the distribution of sample means is hypothetical; no one would painstakingly list all possible combinations of samples of a given size just to find out the probabilities of randomly selecting various sample means. Statisticians have created computer simulations that calculate and plot these sample mean differences in frequency distribution graphs so that we don’t have to.
A-
Psychologists use the distribution of sample means, also called a sampling distribution, to help them draw inferences about the probability of their particular data if the null hypothesis is true. In particular, they ask, “If the null hypothesis were true, how likely is it that we would observe the particular outcome of our study?”
Let’s return to the data presented in Table A-
SIGNIFICANCE TESTING AND t-TESTS. When you are interested in testing whether two groups’ means are different beyond chance, you will be evaluating differences between two samples in a statistical procedure called a t-test. The particular t-test you will learn about is often referred to as the independent-
You will use the data in Table A-
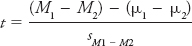
Take a look at the numerator of the t-statistic formula, in particular, the term “μ1 − μ 2,” which refers to the hypothesized difference between the experimental groups in the population. Because you’re testing the null hypothesis, you hypothesize this value to be 0; in other words, under the null you expect that there will be no difference between the two groups in the population from which you’re sampling. The term “(M 1 − M 2)” refers to the difference between our sample means. The denominator contains the standard error, which as mentioned previously is a value that quantifies sampling error or chance. The standard error for this example is .79, a value that takes into account the variability of your samples and sample size. Conceptually, it can be represented as
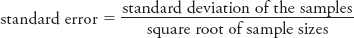
It was calculated following a procedure you can learn about when you take a class in statistics for the behavioral sciences. Plugging in the values to the t-statistic formula, you will find
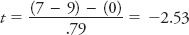
The fact that you have divided the mean difference by a standard score (the standard error) enables you to make use of the empirical rule to determine the probability of our data under the null hypothesis. Earlier, you learned that according to the empirical rule, about 68%, 95%, and 99% of scores tend to fall within 1, 2, and 3 standard deviations of the mean, respectively. The same rule applies even when the distribution is of sample means instead of scores and even when using the standard error instead of standard deviation. If 95% of scores tend to fall within 2 standard errors of the mean of the sampling distribution, then 5% of scores tend to fall outside of this region. These are values we would be less likely to observe if the null hypothesis were true. A t-statistic of ±2 would correspond to a mean difference that was highly improbable; the probability of observing it would be about 5%.
A-
Our actual t-statistic, −2.53, was even more improbable; in fact, the actual probability of observing it happens to be about .02, which means that if the null hypothesis were true, you would have a 2% chance of obtaining a mean difference as extreme as this one. Consequently, you will happily reject the null hypothesis and conclude that driving while speaking on a hands-
To reiterate, if the null hypothesis were true, the difference in errors you observed between your samples would have been so unlikely that you would be comfortable rejecting the null hypothesis. Researchers refer to this procedure as null hypothesis significance testing—the process through which statistics are used to calculate the probability that a research result could have occurred by chance alone. Your data were extremely unlikely under the null hypothesis, so you would conclude that your results were statistically significant, in other words, very unlikely to have occurred by chance alone.
How improbable should your observed difference have been for you to decide to reject the null hypothesis? This is up to the researcher; however, convention dictates that you set a probability level, or p-level, of .05, meaning the probability that you got these results by chance is 5%. The probability that our observed difference was due to chance, 2%, was lower than our 5% cutoff.
TYPE I ERRORS. Does having rejected the null hypothesis mean you can state with certainty that you proved the alternative hypothesis is true? In a word, no. When a researcher decides to set his or her p-level at .05, he or she is essentially saying, “My findings are unlikely to be due to chance. However, it is still possible that I selected samples whose mean differences were this extreme by chance alone and the probability of this is 5%.” In other words, whenever you reject the null hypothesis, you risk doing so incorrectly. You risk making what is called a type I error—rejecting the null hypothesis when it is, in fact, true. What is the probability of making a type I error? It is the probability level (the p-level) you set at the outset (more professionally referred to as the “alpha level”). Though your mean differences were unlikely to have been obtained by chance, the probability is not nil, so you can never feel comfortable saying that you proved the hypothesis to be correct (which is why researchers often prefer to say that they have “demonstrated” a relationship between variables).
VARIABILITY, SAMPLE SIZE, AND CHANCE. How does the amount of variability within a sample affect your ability to reject the null hypothesis? This can be answered in the context of the cell-
There’s still one aspect of the experiment over which you have no control: pre-
A-
Figure A-
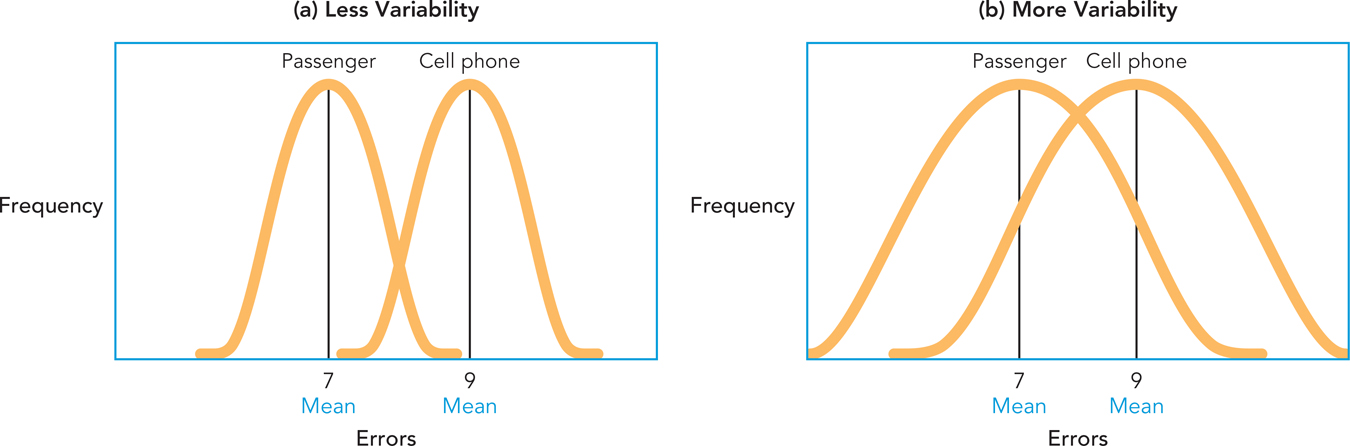
Now take a look at Figure A-
Statisticians had exactly the above idea in mind when creating the formula for t. Here is the t-statistic formula again:
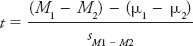
As noted, the term in the denominator, the standard error (sM1 − M2), is calculated by dividing the standard deviation of the samples by the square root of n:
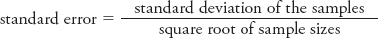
What’s important here is that the standard deviation is an index of how much variability exists within the samples. If there is a lot of variability, the standard deviation, and by extension the standard error, will increase. Keep this in mind as you take another look at the t-statistic formula. What would happen to the value of t if the standard deviation were to increase? As the standard deviation increases, t would decrease, as would your ability to confidently reject the null hypothesis.
A-
So, how does sample size affect your ability to reject the null hypothesis? Read on for the intuitive answer and then the technical one. Whose data would you find more convincing for making the case that talking on hands-
Again, the t-statistic formula takes this very idea into account in its calculation of the standard error. Take another look at the formula for the standard error; you’ll see that, as sample size increases, the standard error decreases. So if you’re planning a study and want to lower the probability that chance is playing a role in your results, recruit lots of people!
WHAT DO YOU KNOW?…
Question A.11
Match the concept on the left with its corresponding description on the right. The context is the study in which participants interacted with someone on a hands-
Question A.12
For the pair of variables below, specify whether the correlation is positive or negative:
- dp4gUq4HRDBDBIz+8nH85P6wf6y/bHSo4kenUycyVXcXn7HGB5DYj6JFAgufbhk2jgJw7L6f+EZYziDiIsDtIRUu0lAk9+vzS2BAusmtcChfOcC0qwxNYIdX7a46Qre7A/SfapOGQHHcRtEq1R4Em0hLT1JKvUi6VkPJQQ==
- PxezTaNKOsqY2FXfRO2J+f9ZYFqi3UOGtHeKUqRgyGaamACT4eklFYfyrzOuxWH14qDChR6JXWUnqjI1qq7yZEHvQU/O1VojsorPlUci0gGFWMSmjGMpWkOTKdNKKFbBhEvN6aNiPh0bxd8+
A-
How Large Are the Observed Differences?
Preview Question
Question
How do researchers determine just how meaningful their results are?
In your cell phone study, you ruled out chance as an explanation for the differences in errors between the cell phone and passenger groups. Should you now lobby your legislators to ban all cell phone use? Before you risk being ostracized by your community for taking away the joy of talking to loved ones while stuck in traffic, you need to consider whether the differences you observed were more than just statistically significant. You should consider whether the effect you observed was sizable. Effect size is a measure of how big the effect is; however, it’s more than that. It tells us how big the effect is when you control for the amount of variability that existed within your sample(s).
What the significance test told you was the probability that your differences are due to chance; it told you nothing about whether your findings were “significant” in the way you’re probably accustomed to using the term—
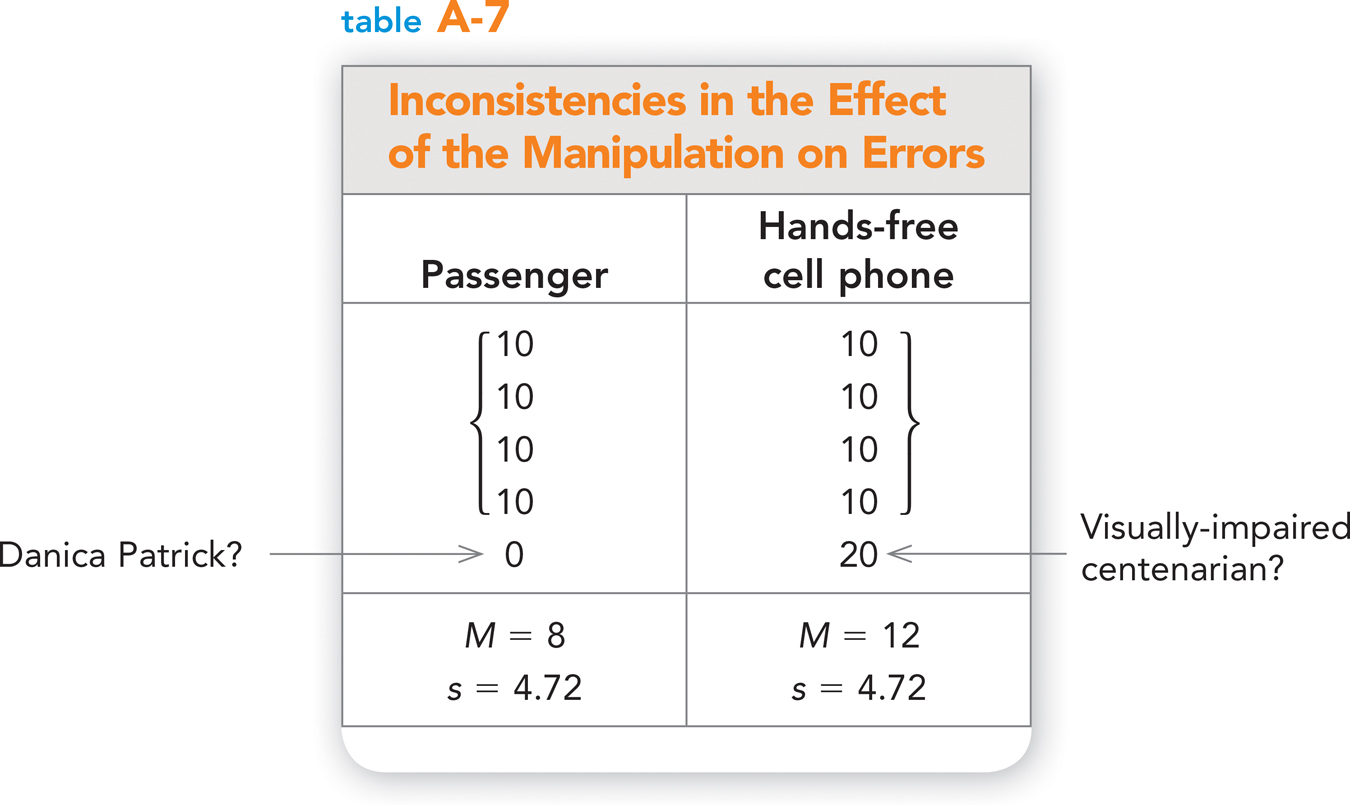
If you were to only pay attention to the mean differences between your groups, you might be quite impressed with the data: There is, on average, a difference of four errors between the two conditions. When you take a closer look, though, you can see that the effect of your manipulation wasn’t consistent from person to person—
“But you just told us that the standard error takes this variability into account!” you must be thinking. Yes, of course, you’re right: When calculating the standard error, you divide the variability within your groups (quantified by the standard deviation) by the square root of your sample size. Here’s where things get interesting. Because there is an inverse relationship between sample size and standard error, if an effect is inconsistent from person to person (as it is above), your findings can still be statistically significant. Check it out. Earlier, you found that there was a 2-
A-
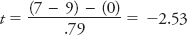
Recall that the standard error, your operational definition of chance, is calculated by dividing the standard deviation of our samples by the square root of your sample size.
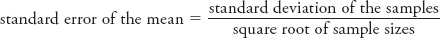
Immediately you can see that even if there were a lot of variability within your cell phone and passenger conditions, a sufficiently large sample size could enable you to reject the null hypothesis; however, if there had been a lot variability in your data, it would’ve been hard to make the case that the effect of your manipulation had been fully consistent across people. In short, the size of your sample can work to reduce standard error enough so that you can reject the null, even if the effect doesn’t hold for most individuals.
So if sample size poses problems for the inferences we make about our data, what would you suggest we do? If you’re thinking, “Why not come up with a formula for effect size that takes into account the size of the effect and the consistency of the effect and that ignores sample size?” then you’re right on. Psychologists rely on a number of formulas for determining effect size. The formula to focus on here is Cohen’s d:
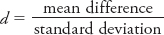
Cohen’s d is a measure of effect size that expresses the difference between sample means in standard deviation units. Cohen’s d offers a benchmark against which you can evaluate the size of your differences. These criteria, set forth by Cohen (1992), are presented in Table A-
A-
| Effect Sizes: Cohen’s d | |
|---|---|
|
d |
Size of effect |
|
.2 |
Small |
|
.5 |
Medium |
|
.8 |
Large |
In the cell-
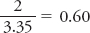
In this example, your d indicates you have a medium effect, because .60 is closest to the cutoff of .50. What you have just learned is that participants in your cell-
Is it time to call the legislators? Well, notice first that the above table provides standardized guidelines, but not standardized recommendations (e.g., “Medium effect: Start panicking”). The decision concerning how to act, armed with your data, will depend on various considerations. For instance, your dependent variable happened to be errors, but what if the numbers referred not to errors but to highway fatalities? In this circumstance, you might wish to call your legislators right away (but not while driving). Statistics do not do our thinking for us—
WHAT DO YOU KNOW?…
Question A.13
QMUYw0qQWfoxZiqgSTZBbd9cSYqpa9wtL4myRi1Jui2EWDzpxqmuSBIP1vKDO1/4B15hMQPrAubnr3CdwOTHsBaU90JKvyGKAJOetq4f5xcN2utY/jgdA+fT4mTMiFxPA-