4.3 PROTEIN EVOLUTION AND THE ORIGIN OF NEW PROTEINS
The amino acid sequences of more than a million proteins are known, and the particular three-dimensional structure has been determined for each of more than 10,000 proteins. While few of the sequences and structures are identical, many are sufficiently similar that the proteins can be grouped into about 25,000 protein families that are structurally and functionally related. Why are there not more types of proteins? The number of possible sequences is unimaginably large. For example, for a polypeptide of only 62 amino acids, there are 2062 possible sequences (because each of the 62 positions could be occupied by any of the 20 amino acids). The number 2062 equals approximately 1080; this number is also the estimated total number of electrons, protons, and neutrons in the entire universe! So why are there so few protein families? The most likely answer is that the chance that any random sequence of amino acids would fold into a stable configuration and carry out some useful function in the cell is very close to zero.
4.3.1 Most proteins are composed of modular folding domains.
If functional proteins are so unlikely, how could life have evolved? The answer is that the earliest proteins were probably much shorter than modern proteins and needed only a trace of function. Only as proteins evolved through billions of years did they become progressively longer and more specialized in their functions. Many protein families that exist today exhibit small regions of three-dimensional structure in which the protein folding is similar. These regions range in length from 25 to 100 or more amino acids. A region of a protein that folds in a similar way relatively independently of the rest of the protein is known as a folding domain.
Several examples of folding domains are illustrated in Figure 4.21. Many folding domains are functional units in themselves. The folding domain in Figure 4.21a is a globin fold composed of multiple alpha helices that have a hydrophobic core and a hydrophilic exterior. The globin fold is characteristic of hemoglobin and other oxygen-carrying proteins. Figure 4.21b is a Rossman fold, which in many enzymes binds a nicotinamide adenine dinucleotide (NAD) used in oxidation reactions. The TIM barrel (Figure 4.21c) is named after the enzyme triose phosphate isomerase in which it is a prominent feature. The TIM barrel consists of alternating alpha helices and parallel beta sheets connected by loops; in many enzymes with a TIM barrel, the active site is formed by the loops at the carboxyl ends of the sheets. Finally, Figure 4.21d is a beta barrel formed from antiparallel beta sheets. Beta barrel structures occur in proteins in some types of bacteria, usually in proteins that span the cell membrane and where the beta barrel provides a channel that binds hydrophobic molecules.
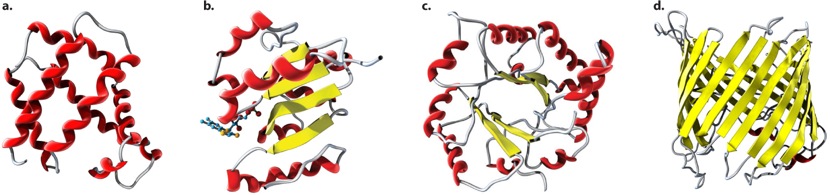
The number of known folding domains is only about 2500, which is far fewer than the number of protein families. The reason for the discrepancy is that different protein families contain different combinations of folding domains. Modern protein families are composed of different combinations of a number of folding domains, each of which contributes some structural or functional feature of the protein. Different types of protein folds occur again and again in different contexts and combinations. The earliest proteins may have been little more than single folding domains that could aggregate to form more complex functional units. As life evolved, the proteins became longer by joining the DNA coding for the individual folding units together into a single molecule.
4-16
4-17
4-18
For example, human tissue plasminogen activator, a protein that is used in treating strokes and heart attacks because it dissolves blood clots, contains domains shared with cell-surface receptors, a domain shared with cellular growth factors, and a domain that folds into large loops facilitating protein–protein interactions. Hence, novel proteins do not always evolve from random combinations of amino acids; instead, they often evolve by combining already functional folding domains into novel combinations.
4.3.2 Amino acid sequences evolve through mutation and selection.
Another important reason that complex proteins can evolve seemingly against long odds is that evolution proceeds stepwise through the processes of mutation and selection. A mutation is a change in the sequence of a gene. The process of mutation is discussed in Chapter 14, but for now all you need to know is that mutations affecting proteins occur at random in regard to their effects on protein function. In protein-coding genes, some mutations may affect the amino acid sequence; others might change the level of protein expression or the time in development or type of cell in which the protein is produced. Here, we will consider only those mutations that change the amino acid sequence.
By way of analogy, we can use a word game that we call Change-One-Letter. The object of the game is to change an ordinary English word into another meaningful English word by changing exactly one letter. Consider the word GONE. To illustrate “mutations” of the word that are random with respect to function (that is, random with respect to whether the change will yield a meaningful new word), we wrote a computer program that would choose one letter in GONE at random and replace it with a different random letter. The first 26 “mutants” of GONE are:
| UONE | GNNE | GONJ | GOZE |
| GONH | GOLE | GFNE | XONE |
| NONE | GKNE | GJNE | DONE |
| GCNE | GONB | GOIE | GGNE |
| GONI | GFNE | GPNE | GENE |
| BONE | GOWE | OONE | GYNE |
Most of the mutant words are gibberish, corresponding to the biological reality that most random amino acid replacements impair protein function to a greater or lesser extent. On the other hand, some mutant proteins function just as well as the original, and a precious few change function. In the word-game analogy, the mutants that can persist correspond to meaningful words, those words shown above in red.
In a population of organisms, random mutations are retained or eliminated through the process of selection among individuals on the basis of their ability to survive and reproduce. This process is considered in greater detail in Chapter 21, but the principle is straightforward. Most mutations that impair protein function will be eliminated because, to the extent that the function of the protein contributes to survival and reproduction, the individuals carrying these mutations will leave fewer offspring than others. Mutations that do not impair function may remain in the population for long periods because their carriers survive and reproduce in normal numbers; a mutation of this type has no tendency to either increase or decrease in frequency over time. In contrast, individuals that carry the occasional mutation that improves protein function will reproduce more successfully than others. Through their enhanced reproduction, the mutant gene encoding the improved protein will gradually increase in frequency and spread throughout the entire population.
In the word game, any of the mutants in red may persist in the population, but suppose that one of them, GENE for example, is actually superior to GONE (considered more euphonious, perhaps). Then GENE will gradually displace GONE, and eventually GONE will be gone. In a similar way that one meaningful word may replace another, one amino acid sequence may be replaced with a different one in the course of evolution.
A real-world example that mirrors the word game is found in the evolution of resistance of the malaria parasite to the drug pyrimethamine. This drug inhibits an enzyme known as dihydrofolate reductase, which the parasite needs to survive and reproduce inside red blood cells. Resistance to pyrimethamine is known to have evolved through a stepwise sequence of four amino acid replacements. In the first replacement, serine (S) at the 108th amino acid in the polypeptide sequence (position 108) was replaced with asparagine (N); then cysteine (C) at position 59 was replaced with arginine (R); asparagine (N) at position 51 was then replaced with isoleucine (I), and finally isoleucine (I) at position 164 was replaced with leucine (L). If we list the amino acids according to their single-letter abbreviation in the order of their occurrence in the protein, the evolution of resistance followed this pathway:

where the mutant amino acids are shown in red. Each successive amino acid replacement increased the level of resistance, so that a greater concentration of drug was needed to treat the disease. The quadruple mutant IRNL is resistant to such high levels that the drug is no longer useful.
4-19
Depicted according to stepwise amino acid replacements, the analogy between the evolution of pyrimethamine resistance and the change-one-letter game is clear. It should also be clear from our earlier discussion that hundreds of other mutations causing amino acid replacements in the enzyme must have occurred in the parasite during the course of evolution, but only these amino acid changes occurring in this order persisted and increased in frequency because they conferred greater survival and reproduction of the parasite under treatment with the drug.