27.2 Assessing Intelligence
27-
intelligence test a method for assessing an individual’s mental aptitudes and comparing them with those of others, using numerical scores.
An intelligence test assesses people’s mental abilities and compares them with others, using numerical scores. Psychologists classify such tests as either aptitude tests, intended to predict your ability to learn a new skill, or achievement tests, intended to reflect what you have already learned. How do we design such tests, and what makes them credible? Consider why psychologists created tests of mental abilities and how they have used them.
aptitude test a test designed to predict a person’s future performance; aptitude is the capacity to learn.
achievement test a test designed to assess what a person has learned.
What Do Intelligence Tests Test?
27-
Barely a century ago, psychologists began designing tests to assess people’s abilities. Some measured aptitude (ability to learn). Others assessed achievement (what people have already learned).
ALFRED BINET: PREDICTING SCHOOL ACHIEVEMENT Modern intelligence testing traces its birth to early-

mental age a measure of intelligence test performance devised by Binet; the chronological age that most typically corresponds to a given level of performance. Thus, a child who does as well as an average 8-
In 1905, Binet and his student, Théodore Simon, first presented their work under the archaic title, “New Methods for Diagnosing the Idiot, the Imbecile, and the Moron” (Nicolas & Levine, 2012). They began by assuming that all children follow the same course of intellectual development, but that some develop more rapidly. A “dull” child should score much like a typical younger child, and a “bright” child like a typical older child. Binet and Simon now had a clear goal: They would measure each child’s mental age, the level of performance typically associated with a certain chronological age. The average 8-
“The IQ test was invented to predict academic performance, nothing else. If we wanted something that would predict life success, we’d have to invent another test completely.”
Social psychologist Robert Zajonc (1984b)
Binet and Simon tested a variety of reasoning and problem-
RETRIEVE IT
Question
What did Binet hope to achieve by establishing a child's mental age?
Stanford-Binet the widely used American revision (by Terman at Stanford University) of Binet’s original intelligence test.
LEWIS TERMAN: THE INNATE IQ Binet’s fears were realized soon after his death in 1911, when others adapted his tests for use as a numerical measure of inherited intelligence. Stanford University professor Lewis Terman (1877-
intelligence quotient (IQ) defined originally as the ratio of mental age (ma) to chronological age (ca) multiplied by 100 (thus, IQ = ma/ca × 100). On contemporary intelligence tests, the average performance for a given age is assigned a score of 100.

From such tests, German psychologist William Stern derived the famous intelligence quotient, or IQ. The IQ was simply a person’s mental age divided by chronological age and multiplied by 100 to get rid of the decimal point. Thus, an average child, whose mental age (8) and chronological age (8) are the same, has an IQ of 100. But an 8-
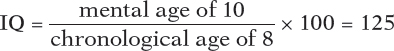
The original IQ formula worked fairly well for children but not for adults. (Should a 40-
RETRIEVE IT
Question
What is the IQ of a 4-
Wechsler Adult Intelligence Scale (WAIS) the WAIS and its companion versions for children are the most widely used intelligence tests; contain verbal and performance (nonverbal) subtests.
DAVID WECHSLER: SEPARATE SCORES FOR SEPARATE SKILLS Psychologist David Wechsler created what is now the most widely used individual intelligence test, the Wechsler Adult Intelligence Scale (WAIS). There is a version for school-

Similarities—Considering the commonality of two objects or concepts (“In what way are wool and cotton alike?”)
Vocabulary—Naming pictured objects, or defining words (“What is a guitar?”)
Block Design—Visual abstract processing (“Using the four blocks, make one just like this.”)

Letter-
Number Sequencing —On hearing a series of numbers and letters, repeat the numbers in ascending order, and then the letters in alphabetical order (“R-2- C- 1- M- 3.”)
The WAIS yields both an overall intelligence score and individual scores for verbal comprehension, perceptual organization, working memory, and processing speed. Striking differences among these individual scores can provide clues to cognitive strengths or weaknesses. For example, a low verbal comprehension score combined with high scores on other subtests could indicate a reading or language disability. Other comparisons can help a therapist establish a rehabilitation plan for a stroke patient. In such ways, these tests help realize Binet’s aim: to identify opportunities for improvement and strengths that teachers and others can build upon.
RETRIEVE IT
Question
An employer with a pool of applicants for a single available position is interested in testing each applicant's potential. To help her decide whom she should hire, she should use an (achievement/aptitude) test. That same employer wishing to test the effectiveness of a new, on-the-job training program would be wise to use an (achievement/aptitude) test.
Three Tests of a “Good” Test
27-
To be widely accepted, a psychological test must be standardized, reliable, and valid. The Stanford-
standardization defining uniform testing procedures and meaningful scores by comparison with the performance of a pretested group.
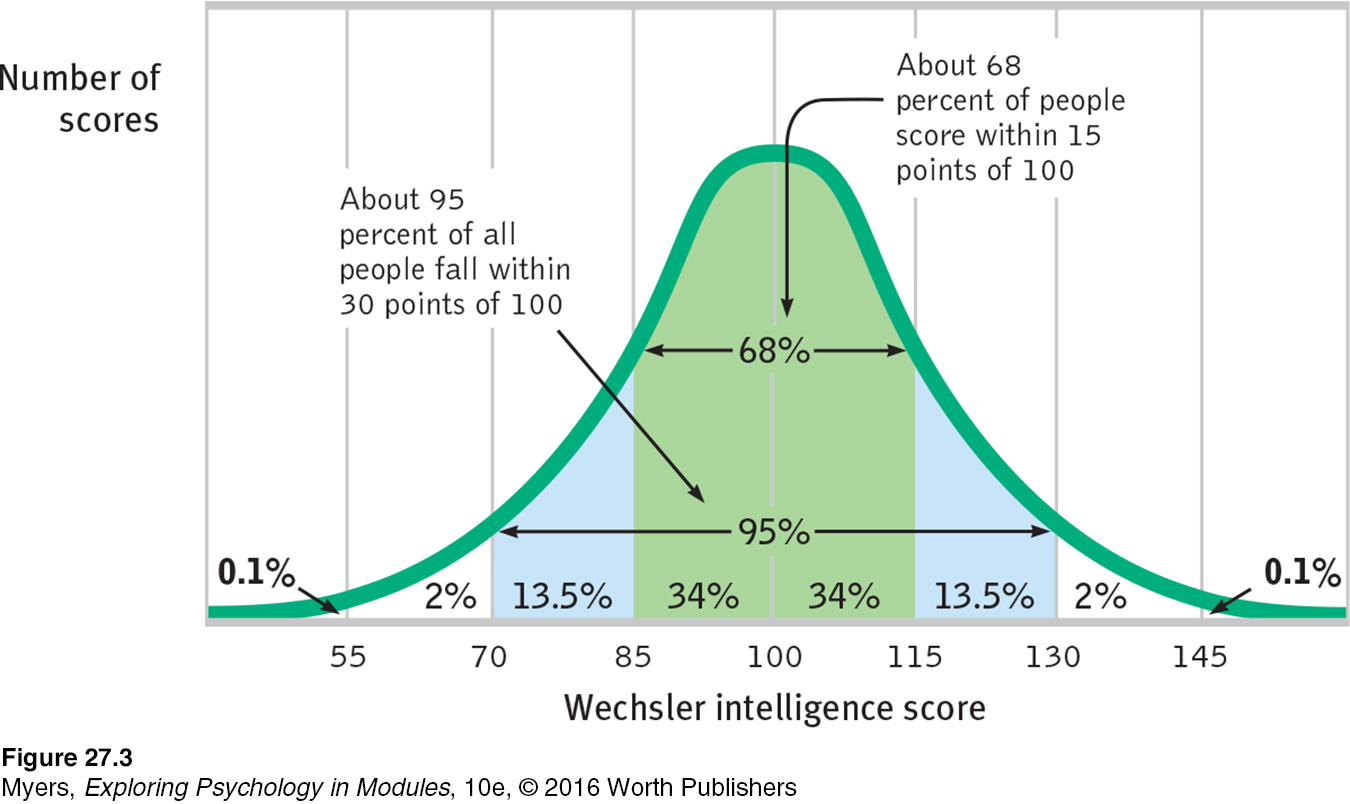
normal curve the bell-
WAS THE TEST STANDARDIZED? The number of questions you answer correctly on an intelligence test would reveal almost nothing. To know how well you performed, you would need some basis for comparison. That’s why test-
If we construct a graph of test-
reliability the extent to which a test yields consistent results, as assessed by the consistency of scores on two halves of the test, on alternative forms of the test, or on retesting.
IS THE TEST RELIABLE? Knowing your score in comparison to the standardization group still won’t tell you much unless the test has reliability. A reliable test gives consistent scores, no matter who takes the test or when they take it. To check a test’s reliability, researchers test people many times. They may retest people using the same test, or they may split the test in half and see whether odd-
validity the extent to which a test measures or predicts what it is supposed to. (See also content validity and predictive validity.)
 See LaunchPad’s Video: Correlational Studies below for a helpful tutorial animation.
See LaunchPad’s Video: Correlational Studies below for a helpful tutorial animation.
IS THE TEST VALID? High reliability does not ensure a test’s validity—the extent to which the test actually measures or predicts what it promises. Imagine using a miscalibrated tape measure to measure people’s heights. Your results would be very reliable. No matter how many times you measured, people’s heights would be the same. But your results would not be valid, because you would not be giving the information you promised: real height.
content validity the extent to which a test samples the behavior that is of interest.
predictive validity the success with which a test predicts the behavior it is designed to predict; it is assessed by computing the correlation between test scores and the criterion behavior. (Also called criterion-
Tests that tap the pertinent behavior, or criterion, have content validity. The road test for a driver’s license has content validity because it samples the tasks a driver routinely faces. Course exams have content validity if they assess your mastery of course material. But we expect intelligence tests to have predictive validity: They should predict future performance, and to some extent they do.
The predictive power of aptitude tests is fairly strong in the early school years, but later it weakens. Past grades, which reflect both aptitude and motivation, are better predictors of future achievements.
RETRIEVE IT
Question
What are the three criteria that a psychological test must meet in order to be widely accepted? Explain.
Question
Correlation coefficients were used in this module. Here's a quick review: Correlations do not indicate cause-