10.4 The Practice and Theory of Intelligence Testing
People differ from one another in many ways. Some are stronger, some are braver, some are more sociable, some are more dependable, some are kinder, and some are more mentally adept than others. It is that last difference that concerns us here. The variable capacity that underlies individual differences in reasoning, solving problems, and acquiring new knowledge is referred to as intelligence. Cognitive psychologist Robert Sternberg (1997) offered a more technical definition of intelligence as “the mental activities necessary for adaptation to, as well as shaping and selecting of, any environmental context … Intelligence is not just reactive to the environment but also active in forming it. It offers people an opportunity to respond flexibly to challenging situations” (p. 1030).
Psychologists have long been interested in measuring intelligence. Much of that interest derives from practical concerns. The first applied psychologists—practitioners who try to solve real-world problems using insights from psychology—were intelligence testers. School systems wanted intelligence tests to determine who could profit most from education; employers wanted them to help decide whom to hire for jobs that require mental ability; armies wanted them to help decide how to assign recruits to ranks and tasks. Intelligence tests have long served all these functions. But psychologists have also been interested in intelligence testing for theoretical, scientific reasons. By correlating individual differences in intelligence test scores with other characteristics of people and their experiences, psychologists have aimed to understand the biological and experiential factors that contribute to intelligence.
A Brief History of Intelligence Testing
Let’s begin historically. Although a number of researchers, notably Sir Francis Galton (1822–1911) in England, investigated the relation between intellectual achievement and a range of basic sensory and cognitive abilities, modern intelligence tests have their ancestry in a test called the Binet-Simon [Bĭ-nā'-Sĭ-mōn'] Intelligence Scale, which was developed in France in 1905 by Alfred Binet (1857–1911) and his assistant Theophile Simon. Binet’s view of intelligence was quite different from Galton’s. Binet believed that intelligence is best understood as a collection of various higher-order mental abilities that are only loosely related to one another (Binet & Henri, 1896). He also believed that intelligence is nurtured through interaction with the environment and that the proper goal of schooling is to increase intelligence. In fact, the major purpose of Binet and Simon’s test—developed at the request of the French Ministry of Education—was to identify children who were not profiting as much as they should from their schooling so that they might be given special attention.
392
Binet and Simon’s test was oriented explicitly toward the skills required for schoolwork. It included questions and problems designed to test memory, vocabulary, common knowledge, use of numbers, understanding of time, and ability to combine ideas. To create the test, problems were pretested with schoolchildren of various ages, and the results were compared with teachers’ ratings of each child’s classroom performance (Binet & Simon, 1916/1973). Items were kept in the test only if more of the high-rated than low-rated children answered them correctly; otherwise, they were dropped. Binet was aware of the circularity of this process: His test was intended to measure intelligence better than existing measures did, but to develop it, he had to compare results with an existing measure (teachers’ ratings). Yet, once developed, the test would presumably have advantages over teachers’ ratings. Among other things, it would allow for comparison of children who had had different teachers or no formal schooling at all.
By 1908, the Binet-Simon test was widely used in French schools. Not long after that, English translations of the test appeared, and testing caught on in England and North America even more rapidly than it did in France.
18
What sorts of subtests make up modern IQ tests, such as the Wechsler tests? How is IQ determined?
The first intelligence test commonly used in North America was the Stanford-Binet Scale, a modification of Binet and Simon’s test that was developed in 1916 at Stanford University. The Stanford-Binet Scale has been revised over the years and is still used, but the most common individually administered intelligence tests today are variations of a test that was developed by David Wechsler in the 1930s and was modeled after Binet’s. The descendants of Wechsler’s tests that are most widely used today are the Wechsler Adult Intelligence Scale, Fourth Edition (WAIS-IV), the Wechsler Intelligence Scale for Children, Fourth Edition (WISC-IV) for children 7 to 16 years old, and the Wechsler Preschool and Primary Scale of Intelligence, Fourth Edition (WPPSI-IV) for children 2 to 7 years old.
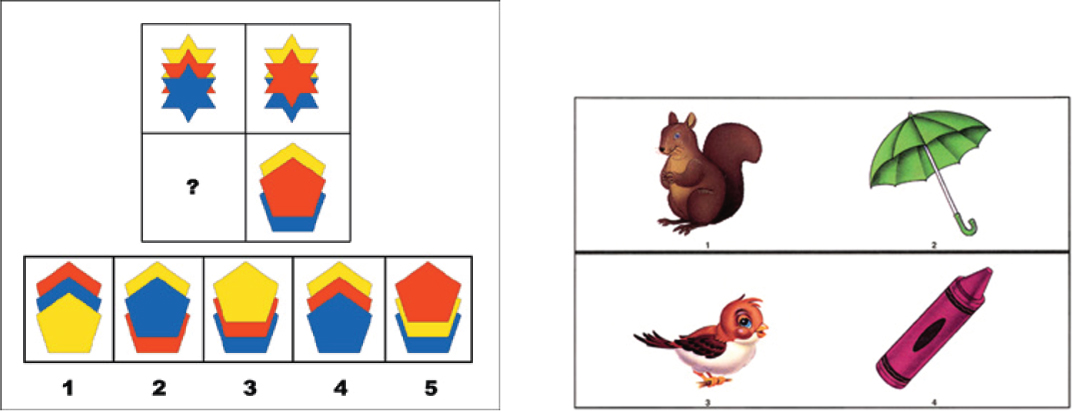
Table 10.2 summarizes the core subtests of the WAIS-IV used in computing the full-scale IQ score. (There are five supplemental, or optional, subtests to the WAIS-IV but they are not used in computing the full-scale IQ score and so are not listed here.) As indicated in the table, the subtests are grouped into four categories. The verbal comprehension category provides an index of verbal abilities and includes three core subtests: Vocabulary; Similarities, the ability to explain how similar concepts are alike; and Information, general knowledge and general understanding of the social and physical world. The perceptual reasoning category subtests depend much less than the verbal comprehension subtests on verbal skills and already-acquired knowledge and more on spatial and quantitative reasoning; this category includes the core subtests of: Block Design, the ability to match visual designs; Matrix Reasoning (similar to the problem shown in Figure 10.1 on p. 373); and Visual Puzzles, which assesses the ability to detect and combine visual patterns. The working memory category includes two core subtests: Digit Span, the number of randomly presented digits than can be remembered in a row; and Arithmetic, in which subjects must concentrate while manipulating mental mathematical problems. Finally, the processing speed category includes two core subsets: Symbol Search, the ability to spot target symbols quickly in arrays of visual symbols; and Coding, assessing the ability to transform digits according to the rules of a code.
Core subtests of the Wechsler Adult Intelligence Scale, Fourth Edition

393
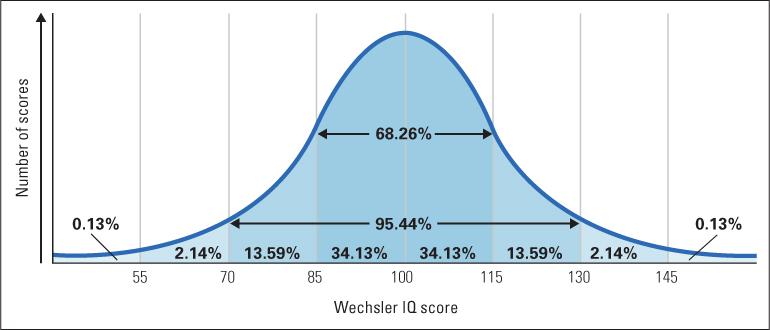
The scoring system for every modern intelligence test uses results obtained from large samples of individuals who have already taken the test. These results are used as normative data to translate each individual’s raw score on an intelligence test into an IQ (intelligence quotient) score. A person whose performance is exactly average for the comparison group is assigned an IQ score of 100. People whose performance is above or below average receive scores above or below 100, assigned in such a way that the overall distribution of scores fits the bell-shaped curve known as a normal distribution, depicted in Figure 10.8. (For a more precise description of normal distributions and the method for standardizing test scores, see the Statistical Appendix at the end of the book.) For children, the comparison group for determining IQ is always a set of children who are the same age as the child being scored.
394
The Validity of Intelligence Tests as Predictors of Achievement
19
How have psychologists assessed the validity of IQ tests? What are the general results of such assessments?
Recall from Chapter 2 that a test is valid if it measures what it is intended to measure. If intelligence tests measure intellectual ability, then IQ scores should correlate with other indices of a person’s intellectual functioning. For the most part, researchers have assessed IQ validity in terms of the tests’ abilities to predict success in school and careers. Not surprisingly—given that most modern intelligence tests are direct or indirect descendants of Binet’s, which was explicitly designed to measure school abilities—IQ scores do correlate moderately well with grades in school; the correlation coefficients in various studies range from 0.3 to 0.7 (Jensen, 1980; Neisser et al., 1996).
How well do IQ scores predict achievement outside of school? Many studies have shown that people with higher IQ scores are much more likely than those with lower scores to gain employment in intellectually demanding occupations such as medicine, law, science, and business management (Brody, 1997; Neisser et al., 1996). This is true even if the comparison is just among people who were raised in the same or similar families, originating from the same socioeconomic background (Schmidt & Hunter, 2004). Still, the conclusions one can draw from such studies are limited by the fact that intellectually demanding jobs generally require high educational attainment. Thus, in theory, the relation between IQ and employment could be secondary to the fact that people with high IQs perform better in school.
A better index of the relation between IQ and career success comes from research correlating IQ with on-the-job performance as measured by supervisors’ ratings, colleagues’ ratings, or direct observations. Many such studies have been conducted, and they regularly show moderate positive correlations (Schmidt & Hunter, 2004). Not surprising, the strength of the correlations depends on the type of job. For jobs that require relatively little judgment and reasoning—such as assembly-line work—the average correlation is about 0.2; for jobs that require a great deal of judgment and reasoning—such as scientist, accountant, and shop manager—the correlation is typically about 0.5 to 0.6 (Schmidt & Hunter, 2004). For jobs in the high-mental-complexity category, IQ tests are better predictors of performance than any other measures that have been developed, including measures aimed at testing specific knowledge and skills related to the job (Gottfredson, 2002; Schmidt & Hunter, 2004).
In addition to predicting school and work performance, IQ scores predict health (Batty et al., 2006) and longevity (Deary, 2008). A study in Scotland, for example, revealed that people who scored high on an IQ test that was given to all 11-year-olds in the nation were significantly more likely to still be alive at age 76 than were those who scored lower on the test (Deary, 2008; Deary & Der, 2005). This was true even for people who were similar in education and socioeconomic status. The numbers were such that a 15-point difference in IQ was associated with a 21 percent difference in survival rate. At least one reason for longer survival, apparently, is better self-care. In that study as well as others, IQ scores were found to correlate positively with physical fitness and healthy diets and negatively with alcoholism, smoking, obesity, and traffic accidents (Gottfredson & Deary, 2004).
The Concept of General Intelligence and Attempts to Explain It
Historically, concern with the practical uses of intelligence tests for placement in school and jobs has always been paralleled by theories and research aimed at characterizing and explaining intelligence. What is the rationale for conceiving of “intelligence” as a unitary, measurable entity? How broadly, or narrowly, should intelligence be defined? Can variations in intelligence be related to properties of the nervous system? What is the evolutionary function of intelligence? These questions are still subject to heated debate. What we tell here, very briefly, is the most common story, the one told most often by those who are most centrally concerned with these questions.
395
General Intelligence (g)
20
What was Spearman’s concept of general intelligence, or g? Why did Spearman think that g is best measured with a battery of tests rather than with any single test?
In the early twentieth century, the British psychologist and mathematician Charles Spearman (1927) conducted many research studies in which he gave dozens of different mental tests to people—all of whom were members of the same broad cultural group—and found that the scores always correlated positively with one another if his sample was large enough. This has been confirmed by decades of research and is termed the positive manifold. That is, people who scored high on any one test also, on average, tended to score high on all other tests. Scores on tests of simple short-term memory span correlated positively with scores on tests of vocabulary, which correlated positively with scores on tests of visual pattern completion, which correlated positively with scores on tests of general knowledge, and so on. Most of the correlations were of moderate strength, typically in the range of 0.3 to 0.6.
From this observation—coupled with a mathematical procedure called factor analysis, which he invented for analyzing patterns of correlations—Spearman concluded that some common factor is measured, more or less well, by every mental test. Spearman labeled that factor g, for general intelligence.
To Spearman and to the many researchers still following in his footsteps, general intelligence is the underlying ability that contributes to a person’s performance on all mental tests (Jensen, 1998). In their view, every mental test is partly a measure of g and partly a measure of some more specific ability that is unique to that test. Accordingly, the best measures of g are derived from averaging the scores on many diverse mental tests. That is exactly the logic that lies behind the use of many very different subtests, in standard intelligence tests such as the WAIS-IV, to determine the full-scale IQ score (refer back to Table 10.2).

Fluid Intelligence and Crystallized Intelligence
Raymond Cattell was a student and research associate of Spearman’s in England until he moved to the United States in 1937. Cattell (1943, 1971) agreed with Spearman that scores on mental tests reflect a combination of general intelligence and a specific factor that varies from test to test, but he contended that general intelligence itself is not one factor but two. More specifically, he proposed that Spearman’s g is divisible into two separate gs. He called one of them fluid intelligence and the other crystallized intelligence.
21
What evidence led Cattell to distinguish between fluid intelligence and crystallized intelligence?
Fluid intelligence, as defined by Cattell (1971), is the ability to perceive relationships among stimuli independently of previous specific practice or instruction concerning those relationships. It is best measured by tests in which people identify similarities or lawful differences between stimulus items that they have never previously experienced, or between items so common that everyone in the tested population would have experienced them. According to Cattell, fluid abilities are biologically determined and reflected by tests of memory span, speed of processing, and spatial thinking. An example of a test assessing fluid intelligence is Raven’s Progressive Matrices test, discussed earlier and illustrated in Figure 10.1 (on p. 373). Verbal analogy problems constructed only from common words that essentially all speakers of the language would know, such as the two problems presented back on page 372, are a second example of tasks that tap fluid intelligence.
A verbal analogy problem that would not be a good measure of fluid intelligence is the following (modified from Herrnstein & Murray, 1994):
RUNNER is to MARATHON as OARSMAN is to (a) boat, (b) regatta, (c) fleet, or (d) tournament.
Solving this problem is limited not just by ability to perceive relationships but also by knowledge of uncommon words (especially regatta), and such knowledge reflects crystallized intelligence, not fluid intelligence.
396
Crystallized intelligence, according to Cattell (1971), is mental ability derived directly from previous experience. It is best assessed in tests of knowledge, such as knowledge of word meanings (What is a regatta?), cultural practices (Do forks go to the right or left of plates in a proper table setting?), and how particular tools or instruments work (How does a mercury-filled thermometer work?). Although people may differ in the domains of their knowledge (one person may know a lot of words but little about tools, for example), Cattell considered crystallized intelligence to be a component of general intelligence. One’s accumulated knowledge can be applied broadly to solve a wide variety of problems.
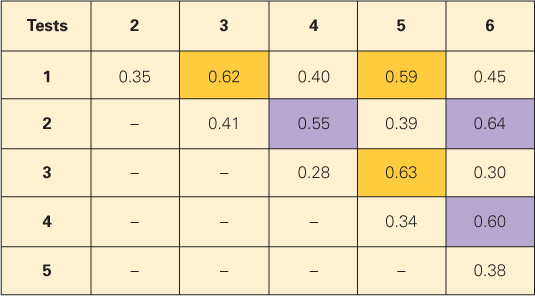
Like Spearman, Cattell based his theory largely on the factor analysis of scores on many different mental tests. Cattell’s analysis indicated that mental tests tend to fall into two clusters: those that depend mostly on raw reasoning ability and those that depend mostly on previously learned information. Test scores within each cluster correlate more strongly with one another than with scores in the other cluster (see Figure 10.9). In addition, Cattell (1971) found that measures of fluid and crystallized intelligence change differently with age. Fluid ability typically peaks at about age 20 to 25 and declines gradually after that, while crystallized ability typically continues to increase until about age 50 or even later.
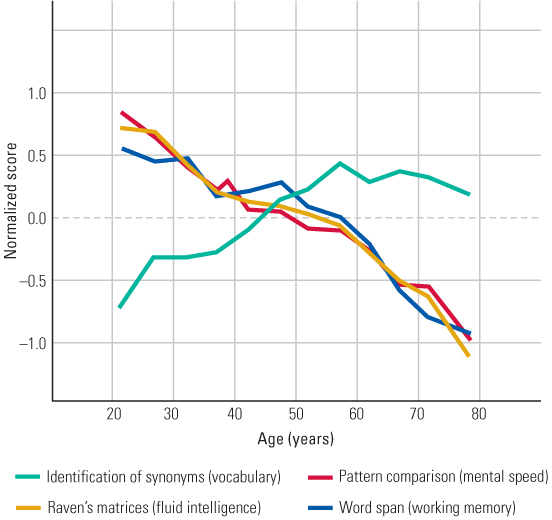
Many research studies have corroborated Cattell’s conclusions about the differences between fluid and crystallized intelligence in their variation with age. Figure 10.10 shows the combined results from many such studies for four mental tests (Salthouse, 2004). As you can see in the figure, vocabulary (ability to identify synonyms) increases steadily until the mid-50s and then levels off or decreases slightly. In contrast, ability to solve Raven’s matrix problems decreases steadily throughout adulthood. The figure also shows that word span (a measure of working memory capacity) and mental speed decline in a manner that is essentially identical to the decline in scores on Raven’s Progressive Matrices.
The evidence from the analysis of correlation patterns, and the differing effects of age, led Cattell to argue that fluid and crystallized intelligences are distinct from each other. He did not, however, think that they are entirely independent. He noted that within any given age group crystallized- and fluid-intelligence scores correlate positively. This, he suggested, is because people with higher fluid intelligence learn and remember more from their experiences than do people with lower fluid intelligence. In that sense, he claimed, crystallized intelligence depends on fluid intelligence. Researchers indeed have found significant correlations between measures of fluid intelligence and at least some measures of verbal learning ability (Tamez et al., 2008).
397
Mental Speed as a Possible Basis for g
22
What findings have revived Galton’s idea of mental quickness as a basis for general intelligence?
Might some basic cognitive abilities underlie general intelligence? This was an idea originally proposed by Francis Galton in the nineteenth century, and revived in the latter part of the twentieth century, using more sophisticated measures and measuring devices (Sheppard & Vernon, 2008).
One such measure is inspection time—the minimal time that subjects need to look at or listen to a pair of stimuli to detect the difference between them. In one common test of inspection time, two parallel lines, one of which is 1.4 times as long as the other, are flashed on a screen and subjects must say which line is longer. The duration of the stimulus varies from trial to trial, and inspection time is the shortest duration at which a subject can respond correctly at some level significantly above chance. Studies correlating fast inspection time with IQ scores have typically revealed correlation coefficients of about 0.3 for measures of fluid intelligence and about 0.2 for measures of crystallized intelligence (Sheppard & Vernon, 2008). The correlations are about as strong when untimed IQ tests are used as when timed tests are used (Vernon & Kantor, 1986), so they do not simply result from the fact that the subtests of some standard IQ tests require quick reaction.
Executive Functions as a Possible Basis for g
23
How might executive functions provide a basis for individual differences in intelligence, and how might mental quickness affect that capacity? What evidence supports this logical possibility?
Recall from Chapter 9 our discussion of executive functions, a set of relatively basic and general-purpose information-processing mechanisms that, together, are important in planning, regulating behavior, and performing complex cognitive tasks. Executive functions are conceptualized as involving three related components (working memory, switching, and inhibition), and these, either together or separately, have been hypothesized to underlie g.
Consider working memory, or updating. In the context of executive functions it refers to the ability to monitor and rapidly add or delete the contents of the short-term store. Recall that the short-term store can hold only a limited amount of information at any given time. While it is the center of conscious thought, it is also a bottleneck that limits the amount of information you can bring together to solve a problem. Information fades quickly from working memory when it is not being acted upon, so the faster you can process information, the more items you can maintain in working memory at any given time, to make a mental calculation or arrive at a reasoned decision. Consistent with this idea, correlations are high between measures of mental speed and working memory; according to some psychologists, this is why mental speed correlates positively with fluid intelligence (Miller & Vernon, 1992).
Recall from Chapter 9 that the capacity of the short-term store is assessed by working-memory span tasks, in which subjects must remember information while performing some “work” on that information. For example, subjects are asked to solve a series of simple addition problems and then to recall, in order, the sum of each problem. Such working-memory span problems are better predictors of cognitive abilities than simpler memory-span measures that ask subject to recall some information (such as a series of digits) without having to perform any “work” simultaneously. In fact, in one study, working-memory span at age 5 predicted academic performance at age 11 better than IQ, measured either at age 5 or at age 11 (Alloway & Alloway, 2010).
398
Researchers have also found that people with different levels of intellectual attainment differ in executive functions. For example, children and adults with intellectual impairment perform more poorly on executive-function tasks (Kittler et al., 2008) than people without intellectual impairment, and gifted children have higher levels of executive functions than nongifted children do (Arffa, 2007; Mahone et al. 2002). In other research, children’s ability to self-regulate their emotions and behaviors accounted for more than twice as much of individual differences in subsequent measures of academic performance (for example, school grades, school attendance, hours spent doing homework) as did IQ (Duckworth & Seligman, 2005).
The finding of a connection between individual differences in executive functions and intelligence is consistent with Robert Sternberg’s theory of intelligence as “mental self-government.” By this he means that people who perform well on intelligence tests are those who can control their mental resources in a way that allows for efficiency in problem solving (that is, who use the “slow” thinking system well). To perform well on most cognitively demanding tasks, one must remain focused, avoid distraction, and distinguish between relevant and irrelevant information. These skills also seem to be involved in most if not all IQ tests and subtests, especially those that tap fluid intelligence more than crystallized intelligence. Some psychologists, in fact, consider fluid intelligence and executive functions to be essentially the same concept (Gray et al., 2003; Kane & Engle, 2002).
General Intelligence as an Evolutionary Adaptation for Novelty
24
What reasoning suggests that general intelligence is an adaptation for dealing with evolutionarily novel problems?
General intelligence is sometimes equated with a general ability to cope adaptively with one’s environment (Snyderman & Rothman, 1987). In the opinion of most intelligence researchers, however, that is much too broad a definition. Cockroaches cope very well with their environment but perform poorly on IQ tests. All basic human capacities, like the basic capacities of any other species, came about through natural selection because they helped individuals adapt to the prevailing conditions of life. For example, human emotionality and sociability are valuable, evolved characteristics that help us survive in our social environments. People vary in measures of social and emotional competence, and these measures generally do not correlate reliably with measures of either fluid or crystallized intelligence (Kanazawa, 2004). You can be intellectually brilliant but emotionally and socially incompetent, or vice versa.

From an evolutionary perspective, it is reasonable to assume that general intelligence evolved in humans as a means of solving problems that are evolutionarily novel (Kanazawa, 2004). People, more than other creatures, are capable of dealing effectively with a wide range of environmental conditions, including conditions that were never regularly faced by our evolutionary ancestors. Our capacity to see analogies, to reason inductively, to deduce the logical consequences of statements, to achieve creative insights, and to predict and plan for future events all help us to cope with the novelties of life and to find ways to survive in conditions for which we are not in other ways biologically well prepared. The same intelligence that allowed hunter-gatherers to find new ways of hunting game or processing roots to make them edible allows us to figure out how to operate computers.
399
SECTION REVIEW
Efforts to characterize and measure intelligence have both practical and theoretical goals.
History and Validity of Intelligence Testing
- Binet regarded intelligence as a loose set of higher-order mental abilities that can be increased by schooling. His tests used school-related questions and problems.
- Most modern intelligence tests are rooted in Binet’s approach and use a variety of verbal and nonverbal subtests.
- IQ scores correlate moderately well with school grades and job performance. Such correlations are commonly used as indices of IQ validity.
Nature of General Intelligence
- Spearman proposed that general intelligence, or g, is a single factor that contributes to all types of mental performance.
- Cattell argued that g consists of two factors—fluid and crystallized intelligence.
- Modern measures of mental quickness and executive functions correlate significantly with IQ.
- Sternberg proposed that the efficiency of mental self-government accounts for individual differences in intelligence.
- General intelligence may have been selected for in human evolution because it helps us deal with novel problems.