2.4 Minimizing Bias in Psychological Research
17
What is the difference between random variation in behavior and bias, and why is bias the more serious problem?
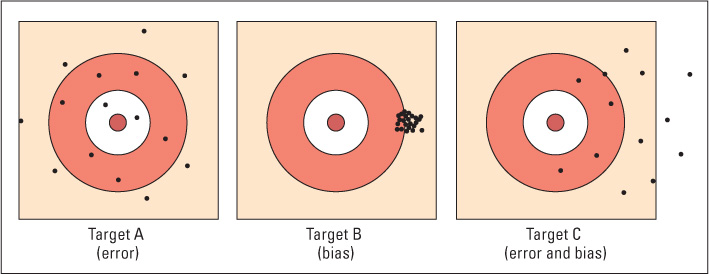
Good scientists strive to minimize bias in their research. Bias, as a technical term, refers to nonrandom (directed) effects caused by some factor or factors extraneous to the research hypothesis. The difference between bias and random variation in behavior can be visualized by thinking of the difference between the sets of holes produced by two archers engaged in target practice. One is a novice. He hasn’t learned to hold the bow steady, so it wavers randomly as he shoots. The arrows rarely hit the bull’s-eye but scatter randomly around it (target A of Figure 2.4). His average shot, calculated as the average geometric location of his entire set of shots, is on or near the bull’s-eye, even if few or none of his individual shots are on or near it. The distance between each arrow and the bull’s-eye in this case exemplifies random variation. The other archer is experienced, but the sights on her bow are out of alignment. Because of that defect, all her arrows strike the target some distance to the right of the bull’s-eye (target B). Those misses exemplify bias, and they are not correctable by averaging. No matter how many times the archer shoots or how carefully she aims, the average location of the whole set of arrows will be off the bull’s-eye. Of course, random variation and bias can occur together, as would happen if a novice archer were given a defective bow sight (target C). In that case, the arrows would be widely scattered around a center that was some distance away from the bull’s-eye.
46
Bias is a very serious problem in research because statistical techniques cannot identify it or correct for it. Whereas error only reduces the chance that researchers will find statistically significant results (by increasing the variability of the data), bias can lead researchers to the false conclusion that their hypothesis has been supported when, in fact, some factor irrelevant to the hypothesis has caused the observed results. Three types of bias are sampling biases, measurement biases, and expectancy biases.
Avoiding Biased Samples
18
How can a nonrepresentative selection of research subjects introduce bias into (a) an experiment and (b) a descriptive study?
One source of bias in research has to do with the way in which the individuals to be studied are selected or assigned to groups. If the members of a particular group are initially different from those of another group in some systematic way, or are different from the larger population that the researcher is interested in, then that group is a biased sample. Conducting research with a biased sample is like shooting with a bow whose sights are misaligned. No matter how large the sample, the results will be off target.

Suppose that in the experiment on depression (Figure 2.1) the researchers had not randomly assigned the subjects to the different treatments but had allowed them to choose their own. In that case, biased samples could have resulted because people’s choices might have been based on pre-existing differences among them. For example, those who felt most motivated to overcome their depression might have been particularly likely to choose the psychotherapy condition. Thus, any greater improvement by those in psychotherapy compared with the others might have resulted not from the psychotherapy but from the pre-existing difference in motivation. When subjects are assigned randomly to groups, their individual differences are merely a source of error (and can be taken into account by inferential statistics); but when subjects are not assigned randomly, their differences can be a source of bias as well as error.
A sample is biased when it is not representative of the larger population that the researchers are trying to describe. A classic example of the effect of a biased sample in descriptive research is the Literary Digest’s poll of U.S. voters in 1936, which led the Digest to announce that Alf Landon would beat Franklin D. Roosevelt in the presidential election that year by a margin of 2 to 1 (Huff, 1954). It turned out that the publication’s conclusion could not have been more mistaken—Roosevelt won by a landslide. The Literary Digest had conducted its poll by telephoning its subscribers. In 1936, in the midst of the Great Depression, people who could afford magazine subscriptions and telephones may indeed have favored Landon, but the great majority of voters, as the election showed, did not.
47
In terms of biased samples, one problem that psychological scientists run into is that the human subjects who are easily available to be studied may not be representative of the greater population. For instance, social and cognitive psychologists frequently test college students enrolled in Introductory Psychology classes and generalize their findings to the broader population. That is, they presume that what is true of college students is true of the population in general. Of course, college students are rarely representative of adults in a country: They are, on average, better educated (or at least on their way to being better educated), from more affluent backgrounds, and younger than typical adults. This makes generalizing results obtained with college students to the entire adult population of a nation a bit suspect. However, even when researchers go outside the confines of academia to get their samples by advertising for subjects online or testing specific populations of people, they still rarely get a sample that is representative of humankind in general. Joseph Henrich and his colleagues (2010) pointed out that most psychological research is drawn from samples from Western, Educated, Industrialized, Rich, and Democratic (WEIRD) societies, and that this greatly limits what we can say about any universal characteristics we may uncover. The solution to this dilemma, of course, is to include non-WEIRD people in samples whenever possible, but this is often more easily said than done. For now, you should just be aware of some of the biases that are inherent in selecting research subjects and be cautious when interpreting a researcher’s claims of uncovering a universal feature of humanity.
Reliability and Validity of Measurements
Psychological researchers must give careful thought to their measures of behavior. A good measure is both reliable and valid. What do we mean by “reliable” and “valid”?
Reliability
19
What is the difference between the reliability and the validity of a measurement procedure? How can lack of validity contribute to bias?
Reliability has to do with measurement error, not bias. A measure is reliable to the degree that it yields similar results each time it is used with a particular subject under a particular set of conditions, sometimes referred to as replicability. Measuring height with a cloth measuring tape is not as reliable as measuring it with a metal measuring tape because the elasticity of the cloth causes the results to vary from one time to the next. A psychological test is not reliable if the scores are greatly affected, in a random manner, by the momentary whims of the research subjects. Because it is a source of error, low reliability decreases the chance of finding statistical significance in a research study.
A second type of reliability is interobserver reliability: the same behavior seen by one observer is also seen by a second observer. This requires that the behavior in question be carefully defined ahead of time. This is done by generating an operational definition, specifying exactly what constitutes an example of your dependent measure. An operational definition defines something in terms of the identifiable and repeatable procedures, or operations, by which it can be observed and measured. For instance, an operational definition of aggression could be based on specific behaviors in a specific context (hits, kicks, or pushes other children on the playground) or the results of a questionnaire designed to measure aggression. In the study discussed earlier by Baumrind (1971) assessing the relation between parenting styles (authoritarian, authoritative, and permissive) and the psychological outcomes of children (for instance, how friendly, happy, cooperative, and disruptive they were), how were the various parenting styles defined, as well as children’s psychological characteristics? Were they based on observations, and if so, what specific behaviors were used to define each parenting style and to describe each psychological outcome of the children? Baumrind used observations of parents in their homes, deriving several different categories of behavior that she believed were related to parenting styles. For example, some of Baumrind’s measures for the category of “Firm Enforcement” included Cannot be coerced by the child, Forces confrontation when child disobeys, Disapproves of defiant stance, and Requires child to pay attention. Even when definitions are agreed upon, will different people record the behaviors similarly? To ensure interobserver reliability, most investigations require that at least two independent observers record the target behavior, and these recordings are then compared statistically to determine if the two people are seeing the same things. Interobserver reliability in Baumrind’s study was generally high, suggesting that the operational definitions of the various behaviors were clear.
48
Validity
Validity is an even more critical issue than reliability because lack of validity can be a source of bias. A measurement procedure is valid if it measures or predicts what it is intended to measure or predict. A procedure may be reliable and yet not be valid. For example, assessing intelligence in adults by measuring thumb length is highly reliable (you would get nearly the same score for a given person each time) but almost certainly not valid (thumb length is almost assuredly unrelated to adult intelligence). This invalid measure exemplifies bias because it would produce false conclusions, such as the conclusion that tall people (who would have longer thumbs) are more intelligent than short people. If common sense tells us that a measurement procedure assesses the intended characteristic, we say the procedure has face validity. A test of ability to solve logical problems has face validity as a measure of intelligence, but thumb length does not.
20
How can we assess the validity of a measurement procedure?
A more certain way to gauge the validity of a measurement procedure is to correlate its scores with another, more direct index of the characteristic that we wish to measure or predict. In that case, the more direct index is called the criterion, and the validity is called criterion validity. For example, suppose that we operationally defined intelligence as the quality of mind that allows a person to achieve greatness in any of various realms, including business, diplomacy, science, literature, and art. With this definition, we might use the actual achievement of such greatness as our criterion for intelligence. We might identify a group of people who have achieved such greatness and a group who, despite similar environmental opportunities, have not and assess the degree to which they differ on various potential measures of intelligence. The more the two groups differ on any of the measures, the greater the correlation between that measure and our criterion for intelligence, and the more valid the test. As you can see from this example, the assessment of validity requires a clear operational definition of the characteristic to be measured or predicted. If your definition of intelligence differs from ours, you will choose a different criterion from us for assessing the validity of possible intelligence tests.

49
Avoiding Biases from Observers’ and Subjects’ Expectancies
Being human, researchers inevitably have wishes and expectations that can affect how they behave and what they observe when recording data. The resulting biases are called observer-expectancy effects. A researcher who desires or expects a subject to respond in a particular way may unintentionally communicate that expectation and thereby influence the subject’s behavior. As you recall, Pfungst discovered that this sort of effect provided the entire basis for Clever Hans’s apparent ability to answer questions. That episode occurred nearly a century ago, but the power of observer expectancies to delude us is as strong today as ever. A dramatic example concerns a technique designed to enable people with autism to communicate.
The Facilitated-Communication Debacle
21
How can the supposed phenomenon of facilitated communication by people with autism be explained as an observer-expectancy effect?
Autism is a disorder characterized by a deficit in the ability to form emotional bonds and to communicate with other people; it typically manifests before age 3. Some people with autism are almost completely unable to use either spoken or written language. Some years ago, in the prestigious Harvard Educational Review, Douglas Biklen (1990) described an apparently remarkable discovery, made originally by Rosemary Crossley in Australia. The discovery was that people with severe autism, who had previously shown almost no language ability, could type meaningful statements with one finger on a keyboard. They could answer questions intelligently, describe their feelings, display humor, and even write emotionally moving poetry by typing. To do this, however, a “facilitator” had to help by holding the typing hand and finger of the person with autism. According to Crossley and Biklen, the handholding was needed to calm the person, to keep the typing hand steady, and to prevent repeated typing of the same letter. (People with autism tend to repeat their actions.)
The community concerned with autism—including special educators and parents of children with autism—responded with great excitement to this apparent discovery. It takes enormous dedication and emotional strength to care for and work with people who don’t communicate their thoughts and feelings, so you can imagine the thrill that parents and teachers felt when their children with autism typed, for the first time, something like “I love you.” The motivation to believe in this new method was enormous. Workshops were held to teach people to be facilitators, and thousands of teachers and parents learned the technique. By 1993, over $100 million a year was being spent by the U.S. educational system on equipment and personnel for facilitated communication (Levine et al., 1994).

50
Yet, from the beginning, there were skeptics. The credulity of some was strained by the sudden appearance of literary skills and erudition in people who had never previously shown evidence that they could read, write, or speak, or even understand much of what others said. As an alternative theory, the skeptics proposed that the messages were not communications from the persons with autism but unconscious creations of the facilitators (Dillon, 1993; Levine et al., 1994). The skeptics suggested that hand movements, made unconsciously by the facilitator, guided the finger of the person with autism to the keys. Consistent with this view, some skeptics noticed that the persons with autism often did not even look at the keyboard as they ostensibly did their typing, whereas the facilitators always looked. The issue soon became important for moral and legal reasons as well as educational and scientific ones. Some children with autism, working with facilitators, typed out messages that accused parents or other caregivers of sexually abusing them (Bligh & Kupperman, 1993; Heckler, 1994). Could facilitated messages be used by child-welfare authorities as a basis for taking a child into protective custody, or even prosecuting the accused parent?
Partly in response to court cases, many experiments were performed in the 1990s to test whether facilitated messages are creations of the person with autism or of the facilitator. In a typical experiment, pairs consisting of a facilitator and a person with autism, chosen because of their experience working together and their putative skill at the technique, were tested under two conditions. In one condition, the item of information that the person with autism was asked to communicate was also shown to the facilitator, and in the other condition it was not. For example, the person with autism might be shown a picture of a common object (such as an apple or a dog) and asked to type the name of that object, under conditions in which the facilitator either saw the object or did not. The inevitable result was that many correct responses were typed in the first condition (in which the facilitator was shown what the person with autism was shown), but not in the second condition. When the facilitator did not know what object the person with autism was shown, the number of correct responses was no more than what would be produced by random guessing (Jacobson et al., 1995; Mostert, 2001). Subsequent research revealed directly that, in fact, facilitators unconsciously control the other person’s hand movements (Wegner et al., 2003). It does not feel to them as if they are creating the messages and controlling the typing, even though they are.
The original observers of facilitated communication, who were also the original facilitators, were deluded by a powerful effect of their own expectations. To understand that effect, imagine that you are a facilitator who truly believes that the person with autism you are helping can type meaningful messages. At any given time during the facilitation, you have some idea in mind (perhaps unconsciously) of what the person is trying to type and what letter should come next. Your expectation that a particular letter will be typed next leads you to feel that the person’s finger is moving toward that letter on the keyboard, so you experience yourself as merely “facilitating” that movement, when you are actually guiding it and creating it.
Avoiding Observer-Expectancy Effects in Typical Experiments
22
What are two ways in which an observer’s expectations can bias results in a typical experiment? How does blind observation prevent such bias?
In the experiments testing the validity of facilitated communication, the influence of observer expectancy was the focus of study and was assessed by varying the observers’ (in this case, the facilitators’) knowledge about what was supposed to be communicated. In a more typical psychological experiment, the objective is not to study observer-expectancy effects, but to eliminate them in order to observe other effects without this form of bias.
Suppose you are conducting an experiment to test the hypothesis that subjects given treatment A will smile more than those given treatment B. Your expectation of more smiling by the former than the latter might cause you, unconsciously, to behave differently toward the two groups of subjects, in ways that could produce the results you expect. For example, you might unconsciously smile more yourself at the A subjects than at the B subjects, causing them to smile more in return. In that case, you would end up believing that treatment A caused the increased smiling, when in fact it was your own smiling that caused it.
51
In addition to influencing subjects’ behavior, observers’ expectations can influence observers’ perceptions or judgments concerning that behavior. In the smiling experiment, for example, your expectation of seeing more smiles in one condition than in another might lead you to interpret ambiguous facial expressions as smiles in the one condition and as something else in the other.
The best way to prevent observer-expectancy effects is to keep the observer blind—that is, uninformed—about those aspects of the study’s design that could lead him or her to form potentially biasing expectations. Thus, in a between-groups experiment, a blind observer would not be told which subjects received which treatment, so the observer would have no basis for expecting particular subjects to behave differently from other subjects. In our hypothetical experiment on smiling, you, as the blind observer, would not know who got which treatment, so you would have no basis for knowing which subjects “should” smile more or less than others. In DiMascio’s study of treatments for depression (illustrated in Figure 2.1), the clinicians who evaluated the patients’ depression at the end of the treatment period were blind to treatment condition. To keep them blind, patients were instructed not to say anything about their treatment during the evaluation interviews.
Avoiding Subject-Expectancy Effects
23
How can subjects’ expectancies bias the results of an experiment? How does a double-blind procedure control both subjects’ and observers’ expectancies?
Subjects also have expectations. If different treatments in an experiment induce different expectations in subjects, then those expectations, rather than anything else about the treatments, may account for observed differences in how the subjects respond. Effects of this sort are called subject-expectancy effects. For example, people who take a drug may subsequently behave or feel a certain way simply because they believe that the drug causes such a behavior or feeling. Similarly, subjects who receive psychotherapy may improve simply because they believe that psychotherapy will help them.

Ideally, to prevent bias from subject expectancy, subjects should be kept blind about the treatment they are receiving. Any experiment in which both the observer and the subjects are kept blind in this way is called a double-blind experiment. For example, in double-blind drug experiments, some subjects receive the drug while others receive a placebo, an inactive substance that looks like the drug, and neither the subjects nor the observers know who received the drug and who did not. Consequently, any observed difference between those who got the drug and those who did not must be due to the drug’s chemical qualities, not to the subjects’ or observers’ expectancies.
Subjects cannot always be kept blind concerning their treatment. For instance, it is impossible to administer psychotherapy to people without their knowing it. As a partial control in some psychotherapy experiments, subjects in the nonpsychotherapy group are given a fake form of therapy designed to induce subject expectancies equivalent to those induced by actual psychotherapy. In DiMascio’s depression experiment described earlier, subjects were not blind about their treatment. Those in the nondrug groups did not receive a placebo, and those in the nonpsychotherapy groups did not receive fake psychotherapy. Therefore, the results depicted in Figure 2.1 might possibly be placebo effects—that is, subject-expectancy effects caused by subjects’ beliefs that the treatment would help them.
52
SECTION REVIEW
Bias—nonrandom effects caused by extraneous factors—must be avoided.
Biased Samples
- Unless subjects in a between-groups experiment are assigned to groups randomly, an observed difference in the dependent variable may be caused by systematic a priori differences between the groups rather than by the independent variable.
- Bias and false conclusions can occur if the subjects in a study are not representative of the group to which the researcher wants to generalize the results.
- Most psychological research with people is done from samples from Western, Educated, Industrialized, Rich, and Democratic (WEIRD) societies, which are not representative of all humans.
Measurement Error and Bias
- A good measure is reliable—able to yield similar results with repeated use on the same subjects in the same conditions.
- An operational definition specifies exactly what constitutes an example of your dependent measure, defining something in terms of the operations by which it could be observed and measured.
- Unreliable measurement produces random variability that makes it more difficult to establish statistical significance.
- A good measure is also valid—able to measure what it is intended to measure. Invalid measures are sources of bias.
- A measure that seems valid on the basis of common sense has face validity. A measure that correlates significantly with another, more direct measure of the variable has criterion validity.
Expectancy Effects
- A researcher’s expectations about a study’s results can influence those results. This is observer-expectancy bias.
- Subjects’ expectations as to how they should respond can also influence results. This is subject-expectancy bias.
- Such expectancy effects can occur without intention or even awareness.
- In observer-blind studies, the observer is deliberately kept ignorant of information that could create expectancies. In double-blind studies, both observers and subjects are kept ignorant of such information.