8.4 Seeing Forms, Patterns, and Objects
The purpose of human vision is not to detect the simple presence or absence of light or different wavelengths, but to identify meaningful objects and actions. As you look at the top of your desk, for example, your retinas are struck by a continuous field of light, varying from point to point in intensity and wavelength. But you see the scene neither as a continuous field nor as a collection of points. Instead, you see objects: a computer, a pencil, a stapler, and a pile of books. Each object stands out sharply from its background. Your visual system has sorted all the points and gradations that are present in the reflected light into useful renditions of the objects on your desk. It has provided you with all the information you need to reach out and touch, or pick up, whichever object you want to use next. How does your visual system accomplish this remarkable feat?
Vision researchers generally conceive of object perception as a type of unconscious problem solving, in which sensory information provides clues that are analyzed using information that is already stored in the person’s head. In this section, we will explore how our visual system organizes such clues in ways that allow us to see forms, patterns, and objects.
The Detection and Integration of Stimulus Features
Any object that we see can be thought of as consisting of a set of elementary stimulus features, including the various straight and curved lines that form the object’s contours, the brightness and color of the light that the object reflects, and the object’s movement or lack of movement with respect to the background. Somehow our visual system registers all these features and brings them together to form one unified perception of the object. A major objective of brain research on vision, for the past 60 years or so, has been to understand how the brain detects and integrates the elementary stimulus features of objects.
Feature Detection in the Visual Cortex
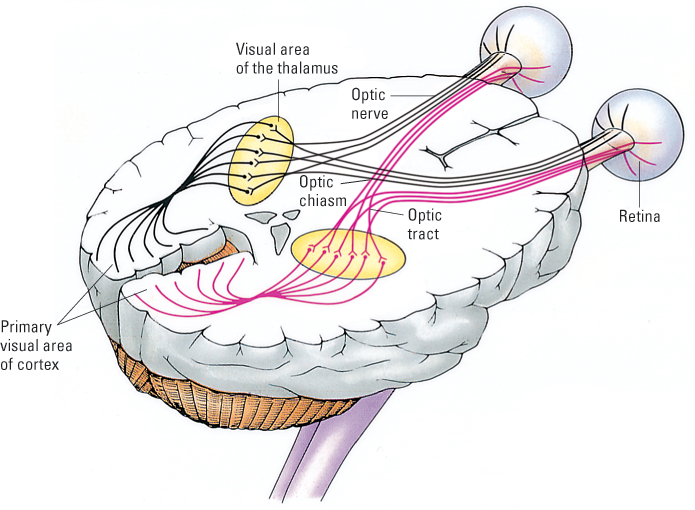
The primary method of studying feature detection in laboratory animals has been to record the activity of individual neurons in visual areas of the brain while directing visual stimuli into the animals’ eyes. As depicted in Figure 8.12, ganglion cells of the optic nerve run to the thalamus, in the middle of the brain, and form synapses with other neurons that carry their output to the primary visual area of the cerebral cortex. Within the primary visual area, millions of neurons are involved in analyzing the sensory input. Researchers have inserted thin electrodes into individual neurons in this area of the animal’s cortex in order to record the neurons’ rates of action potentials as various visual stimuli are presented. In a typical experiment the animal—usually a cat or a monkey—is anesthetized, so it is unconscious, but its eyes are kept open and the neural connections from the eyes to the relevant brain neurons are intact.
294
12
What kinds of stimulus features influence the activity of neurons in the primary visual cortex?
In a classic series of experiments of this sort, David Hubel and Torsten Wiesel (1962, 1979) recorded the activity of individual neurons in the primary visual cortex of cats while the cats’ eyes were stimulated by simple black-and-white patterns of various shapes, sizes, and orientations. They found that different neurons responded preferentially to different patterns. For example, some neurons responded best (most strongly) to stimuli that contained a straight contour separating a black patch from a white patch. Hubel and Wiesel referred to these neurons as edge detectors. Other neurons, which they called bar detectors, responded best to a narrow white bar against a black background, or to a narrow black bar against a white background. Hubel and Wiesel found, moreover, that any given edge detector or bar detector responded best to a particular orientation of the edge or bar. Some responded best when it was oriented vertically, others responded best when it was oriented horizontally, and still others responded best when it was slanted at a specific angle.
Subsequent research showed that neurons in the primary visual cortex are sensitive not just to the orientation of visual stimuli, but also to other visual features, including color and rate of movement. Thus, one neuron might respond best to a yellow bar on a blue background, tilted 15 degrees clockwise and moving slowly from left to right. Taken as a whole, the neurons of the primary visual cortex and nearby areas seem to keep track of all the bits and pieces of visual information that would be available in a scene. Because of their sensitivity to the elementary features of a scene, these neurons are often referred to as feature detectors.
Treisman’s Two-Stage Feature-Integration Theory of Perception
13
What is the difference between parallel processing and serial processing? What role does each play in Treisman’s feature-integration theory of perception?
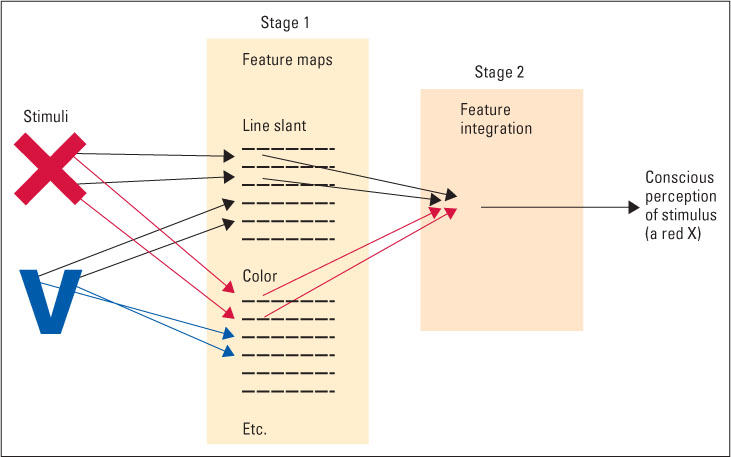
Anne Treisman (1986, 1998) developed a theory of visual perception that she called a feature-integration theory. She developed the theory partly from neurophysiological evidence concerning feature detectors, but mostly from behavioral evidence concerning the speed with which people can perceive various stimuli. The theory begins with the assertion that any perceived stimulus, even a simple one such as the X shown in Figure 8.13, consists of a number of distinct primitive sensory features, such as its color and the slant of its individual lines. To perceive the stimulus as a unified entity, the perceptual system must detect these individual features and integrate them into a whole. The essence of Treisman’s theory is that the detection and integration occur sequentially, in two fundamentally different steps or stages of information processing.
295
The first stage is the detection of features, which occurs instantaneously and involves parallel processing. Parallel processing means that this step operates simultaneously on all parts of the stimulus array. That is, our visual system picks up at once all the primitive features of all the objects whose light rays strike our retinas. Even if we are paying attention just to the X in Figure 8.13, our visual system simultaneously picks up the primitive features of the V in that figure and of all other stimuli in our field of view.
The second stage is the integration of features, which requires more time and leads eventually to our perception of whole, spatially organized patterns and objects. This step involves serial processing, which occurs sequentially, at one spatial location at a time, rather than simultaneously over the entire array. When looking at Figure 8.13, we can integrate the features of the X and then, an instant later, the features of the V, but we cannot integrate the two sets of features simultaneously.
Research Support for Treisman’s Theory
14
How do pop-out phenomena and mistakes in joining features provide evidence for Treisman’s theory?
To understand some of the evidence on which Treisman based her theory, look at the array of stimuli in Figure 8.14a. Notice that no effort is needed to find the single slanted line. You don’t have to scan the whole array in serial fashion to find it; it just “pops out” at you. According to Treisman, this is because line slant is one of the primitive features that are processed automatically through parallel processing. Now look at Figure 8.14b and find the single slanted green line among the vertical green lines and slanted red lines. In this case the target does not pop out; you have to scan through the array in serial fashion to find it (though you can still find it fairly quickly).
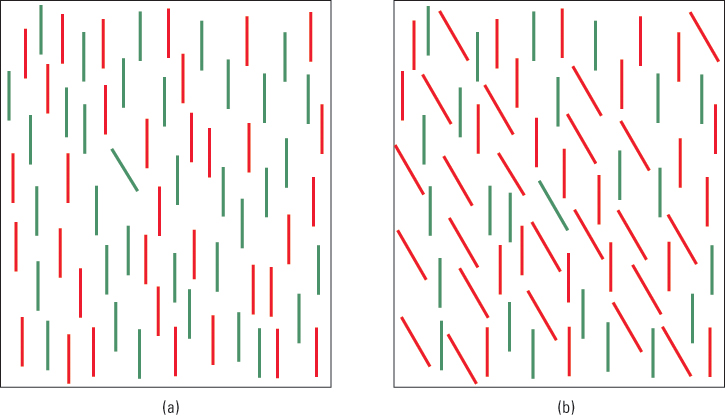

In controlled experiments, Treisman and Stephen Gormican (1988) measured the time it took for people to locate specific target stimuli in arrays like those of Figure 8.14 but with varying numbers of distractors (nontarget stimuli). As long as the target differed from all the distractors in one or more of Treisman’s list of primitive features—such as slant, curvature, color, brightness, and movement—subjects detected it equally quickly no matter how many distractors were present.
This lack of effect of the number of distractors on detection time is indicative of parallel processing. In contrast, when the target did not differ from the distractors in any single visual feature, but differed only in its conjoining of two or more features that were present in different sets of distractors, as in Figure 8.14b, the amount of time required to locate the target increased in direct proportion to the number of distractors. This increase in detection time is indicative of serial processing—the necessity to attend separately to each item (or to small groups of items) until the target is found. Identification of a single unique feature can be accomplished with parallel processing (stage 1), but identification of a unique conjoining of two or more features requires serial processing (stage 2).
296
Treisman also found that subjects who saw simple stimuli flashed briefly on a screen easily identified which primitive features were present but sometimes misperceived which features went together, a phenomenon called illusory conjunctions. For example, when shown a straight red line and a green curved one, all subjects knew that they had seen a straight line and a curved line, and a red color and a green color, but some were mistaken about which color belonged to which line. Such findings led Treisman to conclude that parallel processing (stage 1) registers features independently of their spatial location and that different features that coincide in space (such as the color and curvature of a given line) are joined perceptually only in serial processing (stage 2), which requires separate attention to each spatial location. Thus, stage 2 operates by assigning primitive features to specific spatial locations and then weaving the features together in patterns that reflect their locations.
Not all research findings are consistent with Treisman’s theory. Some researchers have argued, with evidence, that the registration and integration of visual features are not as separate as Treisman proposed (Mordkoff & Halterman, 2008; Roelfsema, 2006). However, to date, no well-accepted newer theory has emerged to replace Treisman’s. Moreover, researchers continue to find new examples of perceptual phenomenon that fit with predictions from Treisman’s theory. For one such example, which could have serious practical consequences, read the caption to Figure 8.15.
Gestalt Principles of Perceptual Grouping
In the early twentieth century, long before Treisman had developed her model of feature integration, adherents to the school of thought known as Gestalt psychology had argued that we automatically perceive whole, organized patterns and objects. Gestalt is a German word that translates roughly as “organized shape” or “whole form.” The premise of the Gestaltists—including Max Wertheimer, Kurt Koffka, and Wolfgang Köhler—was that the mind must be understood in terms of organized wholes, not elementary parts. A favorite saying of theirs was, “The whole is different from the sum of its parts.” A melody is not the sum of the individual notes, a painting is not the sum of the individual dots of paint, and an idea is not the sum of its elementary concepts. In each of these examples, something new emerges from the arrangement of the parts, just as meaning emerges when words are arranged to form a sentence. From the Gestalt point of view, the attempt by psychologists to understand perception by focusing on elementary features was like trying to explain the beauty of the Mona Lisa by carefully weighing the amount of paint used to produce each part of the masterpiece.
Most early Gestalt research was in the area of visual perception. In many laboratory demonstrations, Gestalt psychologists showed that in conscious experience whole objects and scenes take precedence over parts. For example, when looking at a chair, people perceive and recognize the chair as a whole before noticing its arms, legs, and other components. Treisman and other modern perceptual psychologists would not disagree with this point. In our conscious experience, we do typically perceive wholes before we perceive parts; the building up of the wholes from the parts occurs through unconscious mental processes. They would also agree that the whole is different from the sum of its parts because the whole is defined by the way the parts are organized, not just by the parts themselves.
297
Built-in Rules for Organizing Stimulus Elements into Wholes
15
What are some principles of grouping proposed by Gestalt psychologists, and how does each help explain our ability to see whole objects?
The Gestaltists proposed that the nervous system is innately predisposed to respond to patterns in the stimulus world according to certain rules, or Gestalt principles of grouping. These principles include the following (Koffka, 1935; Wertheimer, 1923/1938).
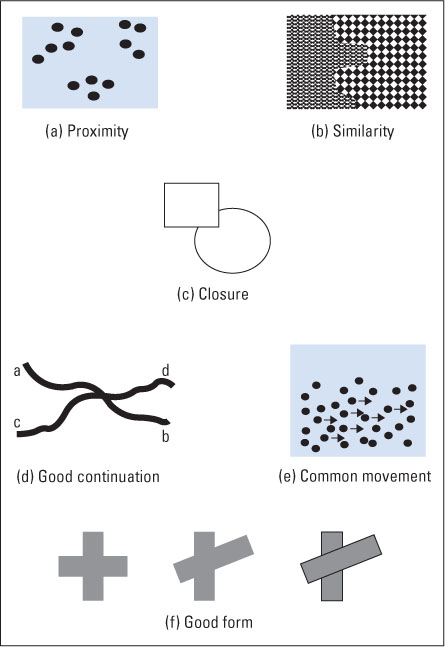
- Proximity. We tend to see stimulus elements that are near each other as parts of the same object and those that are separated as parts of different objects. This helps us organize a large set of elements into a smaller set of objects. In Figure 8.16a, because of proximity, we see three clusters of dots rather than 13 individual dots.
- Similarity. We tend to see stimulus elements that physically resemble each other as parts of the same object and those that do not resemble each other as parts of different objects. For example, as illustrated in Figure 8.16b, this helps us distinguish between two adjacent or overlapping objects on the basis of a change in their texture elements. (Texture elements are repeated visual features or patterns that cover the surface of a given object.)
- Closure. We tend to see forms as completely enclosed by a border and to ignore gaps in the border. This helps us perceive complete objects even when they are partially occluded by other objects. For example, in Figure 8.16c we automatically assume that the boundary of the circle is complete, continuing behind the square.
- Good continuation. When lines intersect, we tend to group the line segments in such a way as to form continuous lines with minimal change in direction. This helps us decide which lines belong to which object when two or more objects overlap. In Figure 8.16d, for example, we see two smooth lines, ab and cd, rather than four shorter lines or two sharply bent lines such as ac or bd.
- Common movement. When stimulus elements move in the same direction and at the same rate, we tend to see them as part of a single object. This helps us distinguish a moving object (such as a camouflaged animal) from the background. If the dots marked by arrows in Figure 8.16e were all moving as a group, you would see them as a single object.
- Good form. The perceptual system strives to produce percepts that are elegant—simple, uncluttered, symmetrical, regular, and predictable (Chater, 1996; Koffka, 1935). This rather unspecific principle encompasses the other principles listed above but also includes other ways by which the perceptual system organizes stimuli into their simplest (most easily explained) arrangement. For example, in Figure 8.16f, the left-hand figure, because of its symmetry, is more likely than the middle figure to be seen as a single object. The middle figure, because of its lack of symmetry, is more likely to be seen as two objects, as shown to its right.
298

Figure and Ground
In addition to proposing the six principles of grouping just listed, the Gestaltists (particularly Rubin, 1915/1958) called attention to our automatic tendency to divide any visual scene into figure (the object that attracts attention) and ground (the background). As an example, see Figure 8.17. The illustration could, in theory, be described as two unfamiliar figures, one white and one black, whose borders happen to coincide, but you almost certainly do not see it that way. Most people automatically see it as just one white figure against a black background. The division into figure and ground is not arbitrary, but is directed by certain stimulus characteristics. In Figure 8.17, the most important characteristic is probably circumscription: Other things being equal, we tend to see the circumscribing form (the one that surrounds the other) as the ground and the circumscribed form as the figure.


16
How do reversible figures illustrate the visual system’s strong tendency to separate figure and ground, even in the absence of sufficient cues for deciding which is which?
The figure–ground relationship is not always completely determined by characteristics of the stimulus. With some effort, you can reverse your perception of figure and ground in Figure 8.17 by imagining that the illustration is a black square with an oddly shaped hole cut out of it, sitting on a white background. When cues in the scene are sparse or ambiguous, the mind may vacillate in its choice of which shape to see as figure and which as ground. This is illustrated by the reversible figure in Figure 8.18, where at any given moment you may see either two faces in profile or a vase. In line with the Gestalt figure–ground principle, the same part of the figure cannot simultaneously be both figure and ground, and thus at any instant you may see either the vase or the faces, but not both.
299
Evidence That Wholes Can Affect the Perception of Parts
When you look at a visual scene, the elementary stimulus features certainly affect your perception of the whole, but the converse is also true: The whole affects your perception of the features. Without your conscious awareness, at a speed measurable in milliseconds, your visual system uses the sensory input from a scene to draw inferences about what is actually present—a process referred to as unconscious inference. Once your visual system has hit upon a particular solution to the problem of what is there, it may actually create or distort features in ways that are consistent with that inference. Examples of such creations and distortions are illusory contours and illusory lightness differences.
Illusory Contours
17
How do illusory contours illustrate the idea that the whole influences the perception of parts? How are illusory contours explained in terms of unconscious inference?
Look at Figure 8.19. You probably see a solid white triangle sitting atop some other objects. The contour of the white triangle appears to continue across the white space between the other objects. This is not simply a misperception caused by a fleeting glance. The longer you look at the whole stimulus, the more convinced you may become that the contour (border) between the white triangle and the white background is really there; the triangle seems whiter than the background. But if you try to see the contour isolated from the rest of the stimulus, by covering the black portions with your fingers or pieces of paper, you will find that the contour isn’t really there. The white triangle and its border are illusions.

The white triangle, with its illusory contour, apparently emerges from the brain’s attempt to make sense of the sensory input (Parks & Rock, 1990). The most elegant interpretation of the figure—consistent with the Gestalt principle of good form and with expectations drawn from everyday experience—is to assume that it contains a white triangle lying atop a black triangular frame and three black disks. That is certainly simpler and more likely than the alternative possibility—three disks with wedges removed from them and three unconnected black angles, all oriented with their openings aimed at a common center. According to this unconscious-inference explanation, the perceptual system uses the initial stimulus input to infer that a white triangle must be present (because that makes the most sense), and then it creates the white triangle, by influencing contourdetection processes in the brain in such a way as to produce a border where one does not physically exist in the stimulus.
Illusory contours cannot be explained in simple stimulus terms, having to do, for example, with the amount of actual lined-up contour existing in the figure. Many experiments have shown that people are more likely to see illusory contours in cases where they are needed to make sense of the figure than in cases where they are not, even when the amount of actual dark-light border is constant (Gillam & Chan, 2002; Hoffman, 1998). For an example, look at Figure 8.20. Most people see an illusory contour, outlining a white square, more clearly in pattern b than in pattern a, even though the actual black–white borders at the corners of the imagined white square are identical in the two figures. The unconscious-inference explanation of this is that the white square is more needed in b than in a to make sense of the stimulus input. The arrangement of four black angular objects is more likely to occur in everyday experience than is the arrangement of four disks with wedges cut out in b.

(b) Adapted from Hoffman, 1998.
300
Unconscious Inference Involves Top-Down Control Within the Brain
18
How is unconscious inference described as top-down control within the brain? What is the difference between top-down and bottom-up control?
When psychologists explain perceptual phenomena in terms of unconscious inference, they do not mean to imply that these phenomena result from anything other than neural processes in the brain. All reasoning, unconscious or conscious, is a product of neural activity. Unconscious-inference theories imply that the phenomena in question result from neural activity in higher brain areas, which are able to bring together the pieces of sensory information and make complex calculations concerning them.
Neuroscientists have learned that the connections between the primary visual area and higher visual areas in the brain are not one-way. The higher areas receive essential input from the primary visual area, but they also feed back to that area and influence neural activity there. Thus, complex calculations made in perceptual portions of the temporal, parietal, and frontal lobes (discussed later) can feed back to the primary visual area in the occipital lobe and influence the activity of feature detectors there. For example, visual stimuli that produce illusory contours activate edge-detector neurons, in the primary visual cortex, that are receiving input from precisely that part of the stimulus where the illusory contour is seen (Albert, 2007; Lee, 2002). In this case, the activity of the edge detector is not the direct result of input from the optic nerve to the edge detector, but, rather, is the result of descending connections from higher visual centers that have determined that there should be an edge at that location.
Brain scientists and perceptual psychologists refer to control that comes from higher up in the brain as top-down control, and they refer to control that comes more directly from the sensory input as bottom-up control. Perception always involves interplay between bottom-up and top-down control (also called bottom-up and top-down processing) in the brain. Bottom-up processes bring in the sensory information that is actually present in the stimulus. Top-down processes bring to bear the results of calculations based on that sensory information plus other information, such as that derived from previous experience and from the larger context in which the stimulus appears. Remember, all these calculations are being conducted by a calculating machine—the human brain—that is vastly more complex and powerful than any nonbiological computer that humans have developed.
Recognizing Objects
To recognize an object is to categorize it: “It’s a bird, it’s a plane, it’s Superman!” To recognize an object visually, we must form a visual perception of it that we can match to our stored definition, or understanding, of the appropriate object category. We normally do this so naturally and easily that we fail to think of the extraordinary complexity of the task. To date, computer scientists have been unable to develop artificial visual systems that come anywhere close to our ability to recognize objects.
In a famous essay entitled “The Man Who Mistook His Wife for a Hat,” the neurologist Oliver Sacks (1985) described the plight of one of his patients, who, as a result of brain damage caused by a stroke, could no longer recognize objects by sight. He could still see colors, textures, lines, and shapes; he could describe in exquisite detail the shapes he saw; and he could recognize objects using other senses, such as touch and smell. But the step that normally leads so naturally from seeing shapes to seeing familiar, recognizable objects was completely missing in him.
When Sacks showed the man a rose and asked him to identify it, the man responded by trying to figure out, aloud, what it was from the shapes and colors he saw: “About six inches in length,” he said. “A convoluted red form with a linear green attachment. It lacks the simple symmetry of the Platonic solids, although it may have a higher symmetry of its own….” After several minutes of such erudite discourse about the object’s parts, the man finally guessed, uncertainly, that it might be some kind of flower. Then Sacks asked him to smell it. “Beautiful!” he exclaimed. “An early rose. What a heavenly smell!” He could tell a rose by smell but not by sight, even though he could see and describe each of its parts in terms of geometry and color.
301
Perceptual researchers don’t know how the normal brain sees and identifies a rose or any other object so easily, but many are working on that problem. Here we will describe some of that research and some ideas that have emerged from it.
Piecing Together the Parts to See the Whole
Logically, for us to see and recognize an object such as a rose, the brain must somehow pick up, from the optic nerves’ input, the relevant features of the object and integrate those features into a perceptual whole, which can be matched with stored representations of familiar object categories. Some years ago, Irving Biederman developed the recognition-by-components theory of object perception. The theory did not specify how the brain does what it does, but did specify what the brain must do in order to recognize objects. Although developed more than 20 years ago, the theory still underlies much research on object recognition (Peissig & Tarr, 2007).
Biederman’s Recognition-by-Components Theory
19
What problem was Biederman’s recognition-by-components theory designed to explain? What is the theory, and how is it supported by experiments on object recognition?
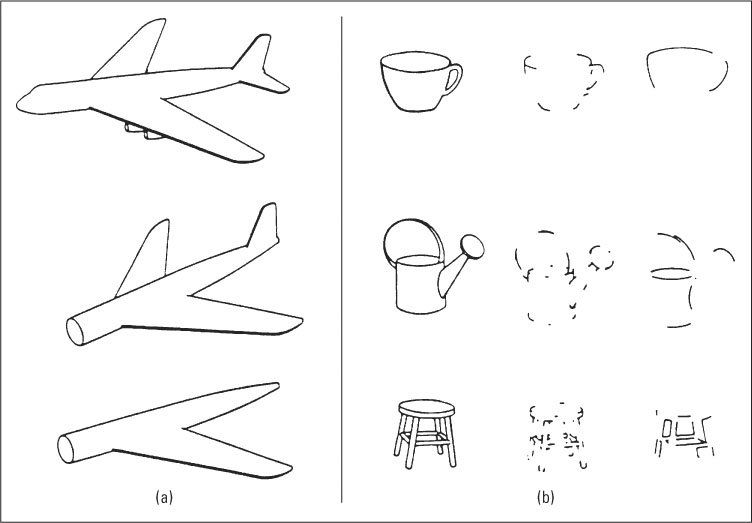
A basic problem in object perception lies in the fact that the image an object projects onto our retinas varies greatly depending on the object’s orientation with respect to our line of sight. An airplane, for example, projects very different images depending on whether we view it from the side, top, or front (see Figure 8.21); yet, in every case we recognize it as an airplane. Biederman’s recognition-by-components theory is an attempt to explain how we see an object as the same object regardless of its orientation.

302
According to the theory, to recognize an object our visual system first organizes the stimulus information into a set of basic, three-dimensional components, which Biederman referred to as geons, and then it uses the arrangement of those components to recognize the object. An airplane, no matter how it is positioned relative to our eyes, always consists of the same set of geons, arranged in the same manner with respect to one another. If we can see the geons and their arrangement, then, according to Biederman, we have the information necessary for identifying the object. On the basis of fundamental properties of three-dimensional geometry, Biederman proposed that there are 36 different geons, some of which are illustrated in Figure 8.22. By smoothing the edges and ignoring the details, according to Biederman, we can depict any object as a small subset of such geons organized in a certain way. You may already be familiar with this general idea from experience with learn-to-draw books that recommend sketching any object as a set of three-dimensional geometric shapes before fleshing it out with details. To see an object, according to Biederman, the visual system first integrates the elementary stimulus features in such a way as to detect the geons, then integrates the geons in such a way as to identify the object. These integrative processes occur unconsciously. We consciously perceive the object, seemingly immediately and effortlessly, blissfully unaware of the complex mental calculations that permit us to do so.

You might think of Biederman’s geons as analogous to letters of the alphabet. Just as a finite number of letters can be arranged in different ways to form an infinite number of words, a finite number of geons can be arranged in different ways to form an infinite number of objects. When you read words, your brain must unconsciously identify the letters and their arrangement for you to identify each word. When you “read” the world of visual objects, your brain must unconsciously identify the geons and their arrangement for you to identify each object.
Some of Biederman’s evidence for the theory comes from studies showing that object recognition depends on the ability to detect at least some of the object’s geons and their arrangement. In one series of experiments, Biederman (1987) asked people to identify objects in pictures that were flashed briefly on a screen. He found that the speed and accuracy of recognizing any given object depended very much on the intactness and arrangement of an object’s geons and very little on other aspects of the stimulus, such as the amount of detail occurring within the geons or the exterior outline of the object as a whole. Figure 8.23 shows some of the stimuli that Biederman used. The airplane in Figure 8.23a was recognized as an airplane even when some of its geons were removed, thereby changing its overall outline, as long as the geons still present were intact and properly arranged. The various objects in Figure 8.23b were recognized when the lines were degraded in ways that preserved the recognizability of individual geons and their connections to one another (middle column), but not when the same amount of line degradation occurred in ways that obscured the geons and their connections (right-hand column).
Evidence from People Who Suffer from Visual Agnosias
20
How is the recognition-by-components theory supported by the existence of two types of visual deficits caused by brain damage?
Further support for Biederman’s theory comes from observations of people who, after a stroke or other source of brain damage, can still see but can no longer make sense of what they see, a condition called visual agnosia. It’s interesting to note that the term agnosia was coined in the late nineteenth century by Sigmund Freud, who then was a young, little-known neurologist (Goodale & Milner, 2004). Freud derived the term from the Greek words a, meaning not, and gnosia, meaning knowledge. People with visual agnosia can see, but they do not know what they are seeing.
303
Visual agnosias have been classified into a number of general types (Farah, 1989; Milner & Goodale, 1995), of which two are most relevant here. People with visual form agnosia can see that something is present and can identify some of its elements, such as its color and brightness, but cannot perceive its shape. They are unable to describe or draw the outlines of objects or patterns that they are shown. In contrast, people with visual object agnosia can describe and draw the shapes of objects that they are shown, but still cannot identify the objects—such as the patient Oliver Sacks described who was unable to identify a rose, although he could see and describe its parts. When shown an apple and asked to draw it, a person with visual agnosia might produce a drawing that you and I would recognize as an apple, but they would still be unable to say what it was. As another example, a patient with visual object agnosia described a bicycle that he was shown as a pole and two circles, but he could not identify it as a bicycle or guess what purpose it serves (Hécaen & Albert, 1978).
The existence of these two types of agnosia, as distinct disorders, is consistent with Biederman’s recognition-by-components theory and thereby lends support to the theory. The theory posits that recognition of an object occurs through the following sequence:
pick-up of sensory features → detection of geons → recognition of object
The two arrows represent two different steps of integration. People with visual form agnosia are unable to carry out the step indicated by the first arrow. They can see elementary sensory features but can’t integrate them into larger shapes (geons). People with visual object agnosia, in contrast, can carry out the first step but not the second. They can see the three-dimensional components of objects but can’t integrate them to identify the objects.
Two Streams of Visual Processing in the Brain
21
What are the anatomical and functional distinctions between two different visual pathways in the cerebral cortex?
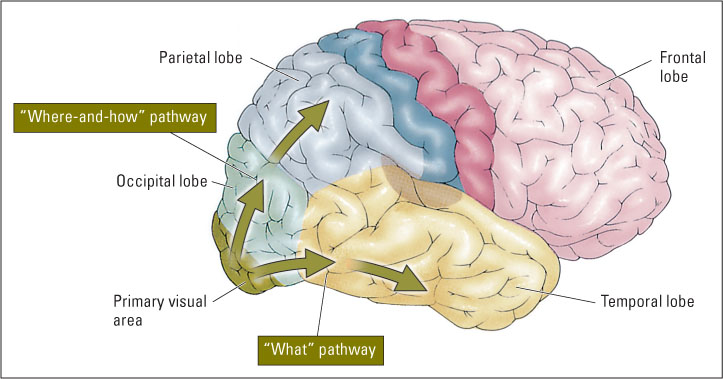
In recent years researchers have learned a great deal about the neural mechanisms that are involved in higher-order visual processing. The primary visual cortex, which occupies the rearmost part of the occipital lobe, sends its output to (and receives feedback from) many other visual-processing areas, which occupy the rest of the occipital lobe and extend forward into much of the temporal and parietal lobes. The visual areas beyond the primary area exist in two relatively distinct cortical pathways, or “streams,” which serve different functions (Konen & Kastner, 2008). As shown in Figure 8.24, one stream runs into the lower portion of the temporal lobe and the other runs upward into the parietal lobe.
304
The lower, temporal stream, often referred to as the “what” pathway, is specialized for identifying objects. Damage in this stream, on both sides of the brain, can result in the types of visual agnosias that we have just been discussing, in which people cannot tell what they are looking at. Experiments involving singlecell recording in monkeys and fMRI in humans have shown that neurons in this pathway typically respond best to complex geometric shapes and to whole objects, in ways that are quite consistent with the recognition-by-components theory (Grill-Spector & Sayres, 2008; Yamane et al., 2008).
The upper, parietal stream is commonly referred to as the “where” pathway, because it is specialized for maintaining a map of three-dimensional space and localizing objects within that space. More recently, researchers have found that this pathway is also crucial for the use of visual information to guide a person’s movements (Goodale, 2007). Neurons in this pathway are concerned not just with where the object is located, but also with how the person must move in order to pick up the object, or move around it, or interact with it in some other way. For this reason, we use the label “where-and-how,” rather than just “where,” to refer to the parietal pathway. (Look again at Figure 8.24.)
Effects of Damage in the “What” Pathway
22
What abilities are preserved in people with damage to the “what” pathway but lost in people with damage to the “where-and-how” pathway?
People with damage in specific portions of the “what” pathway on both sides of the brain generally suffer from deficits in ability to make conscious sense of what they see, depending on just where the damage is. The examples of visual agnosias that we already described resulted from damage in this pathway. An interesting further observation concerning such patients is that they retain the ability to reach accurately for objects and act on them in coordinated ways, guided by vision, even if they can’t consciously see the objects.
A dramatic example is the case of a woman known as D. F., who has been extensively studied by Melvyn Goodale (2007) and his colleagues. This woman suffers from very severe visual form agnosia, stemming from carbon monoxide poisoning that destroyed portions of the “what” pathway close to the primary visual area on both sides of her brain. Despite her complete inability to perceive consciously the shapes of objects, D. F. responds to objects in ways that take into account shape as well as size, position, and movement. When she walks, she moves around obstacles with ease. She is good at catching objects that are thrown to her, even though she can’t consciously see the object coming toward her. When asked to pick up a novel object placed in front of her, she moves her hand in just the correct way to grasp the object efficiently.
305
In one experiment, D. F. was shown an upright disk with a slot cut through it (Goodale & Milner, 2004). She claimed to be unable to see the orientation of the slot and, indeed, when she was asked to hold a card at the same angle as the slot, her accuracy (over several trials with the slot at varying orientations) was no better than chance. But when she was asked to slip the card into the slot as if mailing a letter, she did so quickly and accurately on every trial, holding the card at just the right orientation before it reached the slot. She could not use conscious perception to guide her hand, but her hand moved correctly when she wasn’t trying to use conscious perception to guide it. Apparently the “where-and-how” pathway, which was intact in this woman, is capable of calculating the sizes and shapes of objects, as well as their places, but does not make that information available to the conscious mind.
Effects of Damage in the “Where-and-How” Pathway
Damage in the “where-and-how” pathway—in the upper parts of the occipital and parietal lobes of the cortex—interferes most strongly with people’s abilities to use vision to guide their actions. People with damage here have relatively little or no difficulty identifying objects that they see, and often they can describe verbally where the object is located, but they have great difficulty using visual input to coordinate their movements. They lose much of their ability to follow moving objects with their eyes or hands, to move around obstacles, or to reach out and pick up objects in an efficient manner (Goodale & Milner, 2004; Schindler et al., 2004). Even though they can consciously see and describe an object verbally and report its general location, they reach for it gropingly, much as a blind person does. They frequently miss the object by a few inches, then move their hand around until they touch it (see Figure 8.25). Only when they have touched the object do they begin to close their fingers around it to pick it up.

Complementary Functions of the Two Visual Pathways in the Intact Brain
23
In sum, what are the distinct functions of the “what” and “where-and-how” visual pathways?
The two just-described visual pathways apparently evolved to serve different but complementary functions. The “what” pathway provides most of our conscious vision. It provides the input that allows us to see and identify objects consciously, to talk about those objects, to make conscious plans concerning them, and to form conscious memories of them. In contrast, the “where-and-how” pathway provides the input that is needed for the automatic, rapid, and largely unconscious visual control of our movements with respect to objects. This pathway is able to register the shape of an object to the degree that shape is necessary for effectively reaching for and picking up the object, but it does not register shape in a manner that enters consciousness.
306
SECTION REVIEW
A central purpose of the human visual system is to identify objects. To identify an object, we must perceive it well enough to match it to a stored representation.
Integration of Features
- Neurons in the primary visual cortex and nearby areas are maximally responsive to specific visual features, such as particular line orientations, movements, and colors.
- Behavioral evidence suggests that features are detected through rapid parallel processing and then are integrated spatially through serial processing.
Gestalt Principles
- Gestalt psychologists asserted that whole objects are not merely the sums of their parts and that wholes take precedence in conscious perception.
- The Gestalt principles of grouping describe rules by which we automatically organize stimulus elements into wholes.
- We also automatically separate figure from ground.
Top-Down Processes
- Wholes influence our perception of parts through unconscious inference, as illustrated by illusory contours and illusory lightness differences.
- The effects of unconscious inference occur through top-down control mechanisms in the brain.
Recognition by Components
- Objects can be understood visually as sets of geons (basic three-dimensional shapes) arranged in specific ways.
- Biederman’s theory holds that the visual system integrates features to detect geons and integrates geons to identify objects.
- The theory is supported by recognition experiments with normal subjects and through observations of people with visual form agnosia and visual object agnosia.
Two Streams of Visual Processing
- Visual processing beyond the primary visual cortex in the occipital lobe takes place along two independent streams (pathways)—a “what” stream leading into the temporal lobe, and a “where-and-how” stream leading into the parietal lobe.
- Bilateral damage to parts of the “what” stream impairs conscious object recognition but preserves the ability to use vision to direct physical actions with respect to objects, such as grasping or moving around objects. Bilateral damage to the “where-and-how” stream has the opposite effect.