Concept 9.2: DNA Replicates Semiconservatively
An important requirement for the genetic material is that it replicates both completely and accurately during the cell cycle. The double-helix model of DNA suggested to Watson and Crick how this might be accomplished. Semiconservative replication means that each strand of the parental DNA acts as a template for a new strand, which is added by base pairing:

There is abundant evidence supporting this mechanism. In a typical experiment, the parental DNA (represented by the blue strands above) is labeled in some fashion (for example, with a radioactive isotope) and then allowed to replicate in cells for a generation. As the new DNA strands (red in the diagram) are made, they are unlabeled. A conservative mode of replication would show the parental DNA intact with both strands labeled, and the new DNA with both strands unlabeled. This does not occur. Instead, the resulting DNA molecules are always “hybrids” (one labeled strand and one unlabeled strand), supporting the semiconservative model of replication.

Go to ANIMATED TUTORIAL 9.1 The Hershey-Chase Experiment
PoL2e.com/at9.1

Go to ANIMATED TUTORIAL 9.2 Experimental Evidence for Semiconservative DNA Replication
PoL2e.com/at9.2
DNA replication (FIGURE 9.7) involves several different enzymes and other proteins. It takes place in two general steps:
- The DNA double helix is unwound to separate the two template strands and make them available for new base pairing.
- As newly added nucleotides form complementary (A with T and G with C) base pairs with template DNA, they are covalently linked together by phosphodiester bonds (see Figure 3.2), forming a polymer whose base sequence is complementary to the bases in the template strand. Replication enzymes read the template DNA in the 3′-to-5′ direction.

180
APPLY THE CONCEPT: DNA replicates semiconservatively
Each eukaryotic chromosome is composed of a double-stranded DNA molecule. It is possible to use a microscope to distinguish between a chromosome that has been labeled with radioactivity and one that is unlabeled. Plant cells were grown in the lab in the presence of radioactive thymidine for many generations. The cells were then grown for three cell doublings in nonradio-active thymidine so that any new DNA strands would be unlabeled. These cultured cells had synchronized cell cycles. They were examined when they were in anaphase of mitosis.a

- Use diagrams of double-stranded DNA to explain these data.
- What would the data and diagrams look like if DNA replicated conservatively?
a Based on J. H. Taylor et al. 1957. Proceedings of the National Academy of Sciences 43: 122-127.
During DNA synthesis, nucleotides are added to the 3 end of the growing new strand—the end at which the DNA strand has a free hydroxyl (—OH) group on the 3′ carbon of its terminal deoxyribose. In summary, the DNA template is read 3′ to 5′, while the new strand of DNA is generated 5′ to 3′, forming an antiparallel double helix.
As we noted in Concept 3.1, a free nucleotide can have one, two, or three phosphate groups attached to its pentose sugar. The raw materials for DNA synthesis are the nucleotides deoxyadenosine triphosphate (dATP), deoxythymidine triphosphate (dTTP), deoxycytidine triphosphate (dCTP), and deoxyguanosine triphosphate (dGTP)—collectively referred to as deoxyribonucleoside triphosphates (dNTPs) or deoxyribonucleotides. As their names imply, deoxyribonucleoside triphosphates each carry three phosphate groups. During DNA synthesis, the two outer phosphate groups are released in an exergonic reaction, so that the final nucleotide is a monophosphate (adenine, thymine, cytosine, or guanine; see Figure 9.7). The release of the two outer phosphate groups provides energy for the formation of a phosphodiester bond between the single remaining phosphate group of the incoming nucleotide and the 3′ carbon on the sugar at the end of the DNA chain (see Figure 3.2).

Go to ANIMATED TUTORIAL 9.3 DNA Replication Part I: Replication of a Chromosome and DNA Polymerization
PoL2e.com/at9.3
DNA polymerases add nucleotides to the growing chain
DNA replication begins with the binding of a large protein complex (the pre-replication complex) to a specific site on the DNA molecule. This complex contains several different proteins, among them the enzyme DNA polymerase, which catalyzes the addition of nucleotides as the new DNA chain grows. All chromosomes have at least one region called the origin of replication (ori), to which the pre-replication complex binds. Binding occurs when proteins in the complex recognize specific DNA sequences within the ori.
Origins Of Replication
The single circular chromosome of the bacterium Escherichia coli has 4 × 106 base pairs (bp) of DNA. The chromosome has a single 245 bp ori sequence. Once the pre-replication complex binds to it, the DNA unwinds and replication proceeds in both directions around the circle, forming two replication forks (FIGURE 9.8A). The opening of each fork is catalyzed by an enzyme called DNA helicase, which uses free energy from ATP hydrolysis to change shape and wedge into the DNA, locally breaking hydrogen bonds between bases on the two strands and separating them.

The replication rate in E. coli is approximately 1,000 bp per second, so it takes about 40 minutes to fully replicate the chromosome (with two replication forks). Rapidly dividing E. coli cells divide every 20 minutes. In these cells, new rounds of replication begin at the ori of each new chromosome before the first chromosome has fully replicated. In this way the cells can divide in less time than the time needed to finish replicating the original chromosome.
Eukaryotic chromosomes are much longer than those of prokaryotes—up to a billion bp—and are linear, not circular. If replication occurred from a single ori, it would take weeks to fully replicate a chromosome. So eukaryotic chromosomes have multiple origins of replication, scattered at intervals of 10,000–40,000 bp (FIGURE 9.8B).
DNA Replication Is Initiated With A Primer
DNA polymerase elongates a polynucleotide strand by covalently linking new nucleotides to a preexisting strand. However, it cannot begin this process without a short “starter” strand, called a primer. In most organisms this primer is a short single strand of RNA (FIGURE 9.9), but in some viruses it is DNA. The primer is complementary to the DNA template and is synthesized one nucleotide at a time by an enzyme called a primase. The DNA polymerase then adds nucleotides to the 3′ end of the primer and continues until the replication of that section of DNA has been completed. Then the RNA primer is degraded, DNA is added in its place, and the resulting DNA fragments are connected by the action of another enzyme. When DNA replication is complete, each new strand consists only of DNA.

181
DNA Polymerases Are Large
DNA polymerases are much larger than their substrates, the dNTPs, and the template DNA, which is very thin (FIGURE 9.10A). Molecular models of the enzyme–substrate–template complex show that the enzyme is shaped like a right hand with a palm, a thumb, and fingers (FIGURE 9.10B). Within the “palm” is the active site of the enzyme, which binds the template DNA strand and the new, growing DNA strand. The “fingers” region has precise pockets that can only fit the specific shapes of correct A-T and G-C base pairs. When an incoming nucleotide correctly pairs with a nucleotide on the template strand at the active site of the enzyme, the base pair is recognized by the fingers region. When this occurs, the enzyme undergoes a conformational change (a change in shape), and then catalyzes the condensation reaction that results in the formation of a new phosphodiester bond (see Figures 3.2 and 9.7).
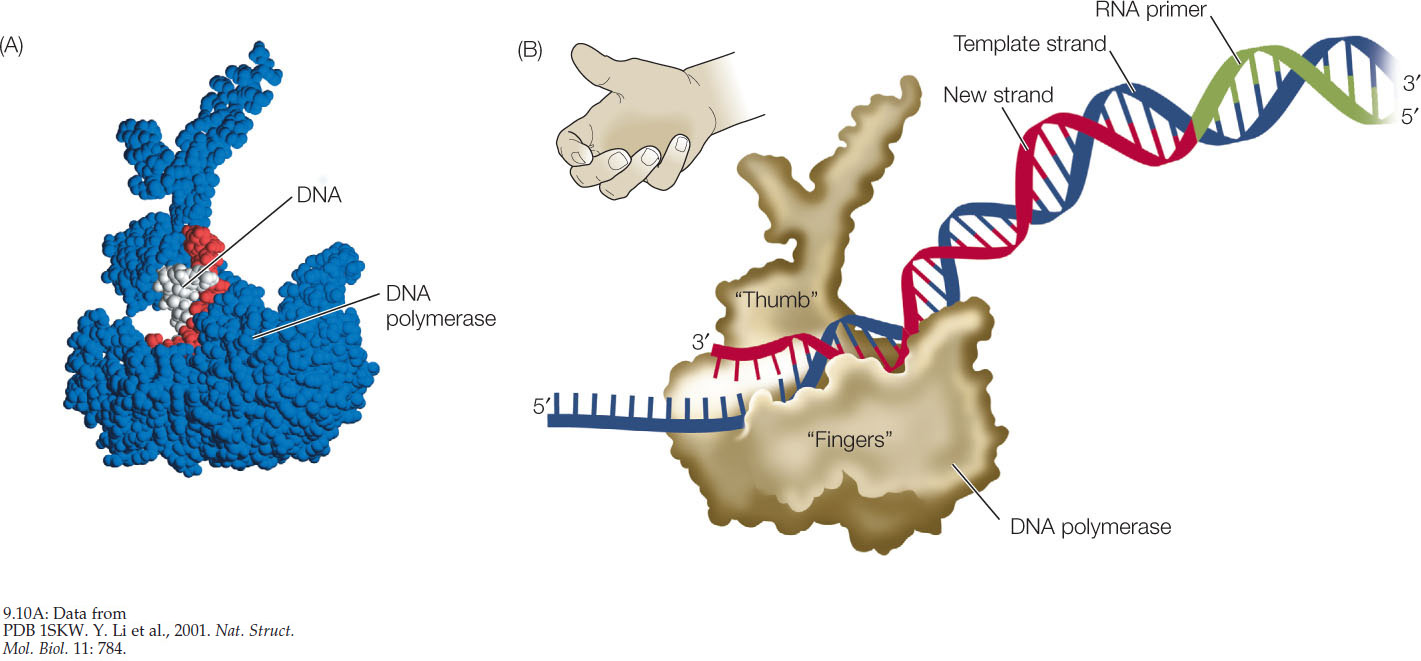
Go to ACTIVITY 9.1 DNA Polymerase
PoL2e.com/ac9.1
Most cells contain more than one kind of DNA polymerase, but only one of them is responsible for chromosomal DNA replication. The others are involved in primer removal and DNA repair. Fifteen DNA polymerases have been identified in humans; the bacterium E. coli has five DNA polymerases.
182
The Two DNA Strands Grow Differently at the Replication Fork
A single replication fork opens up in one direction. Study FIGURE 9.11 and try to imagine what is happening over a short period of time. For the purpose of understanding the process, imagine that the DNA opens from one end like a zipper (even though, as we have seen, it actually opens up from within the molecule and replication extends in both directions). Remember two things:
- The two DNA strands are antiparallel—that is, the 3′ end of one strand is paired with the 5′ end of the other.
- DNA polymerase replicates DNA by adding nucleotides only to the 3′end of each growing strand.

Go to ANIMATED TUTORIAL 9.4 DNA Replication, Part 2: Coordination of Leading and Lagging Strand Synthesis
PoL2e.com/at9.4
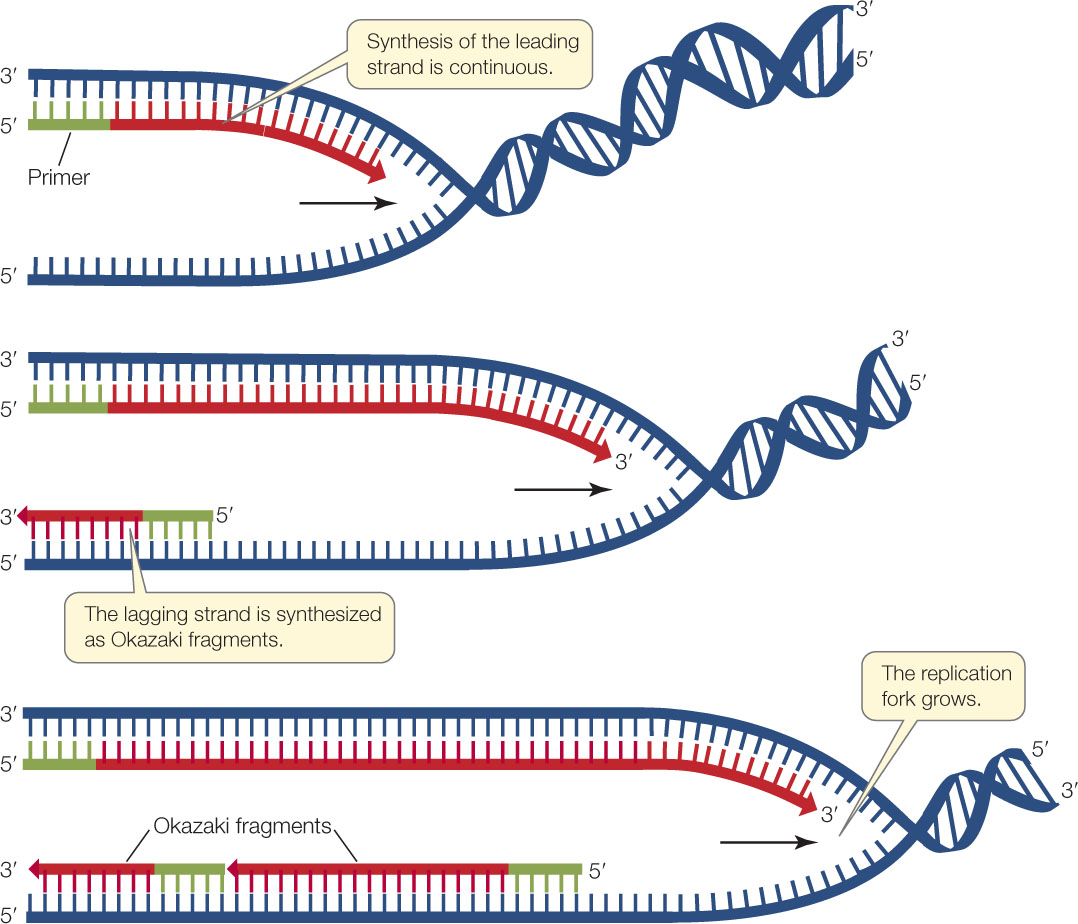
One newly synthesized growing strand—the leading strand—is oriented so that it can grow continuously at its 3′ end as the fork opens up. The other new strand—the lagging strand—must be synthesized differently because it grows in the direction away from the replication fork.
183
Synthesis of the lagging strand requires the synthesis of relatively short, discontinuous stretches of sequence (100–200 nucleotides in eukaryotes; 1,000–2,000 nucleotides in prokaryotes). These discontinuous stretches are synthesized just as the leading strand is, by the addition of new nucleotides one at a time to the 3′ end, but the new strand grows away from the replication fork. These stretches of new DNA are called Okazaki fragments after their discoverer, the Japanese biochemist Reiji Okazaki. To summarize, while the leading strand grows continuously “forward,” the lagging strand grows in shorter, “backward” stretches with gaps between them.
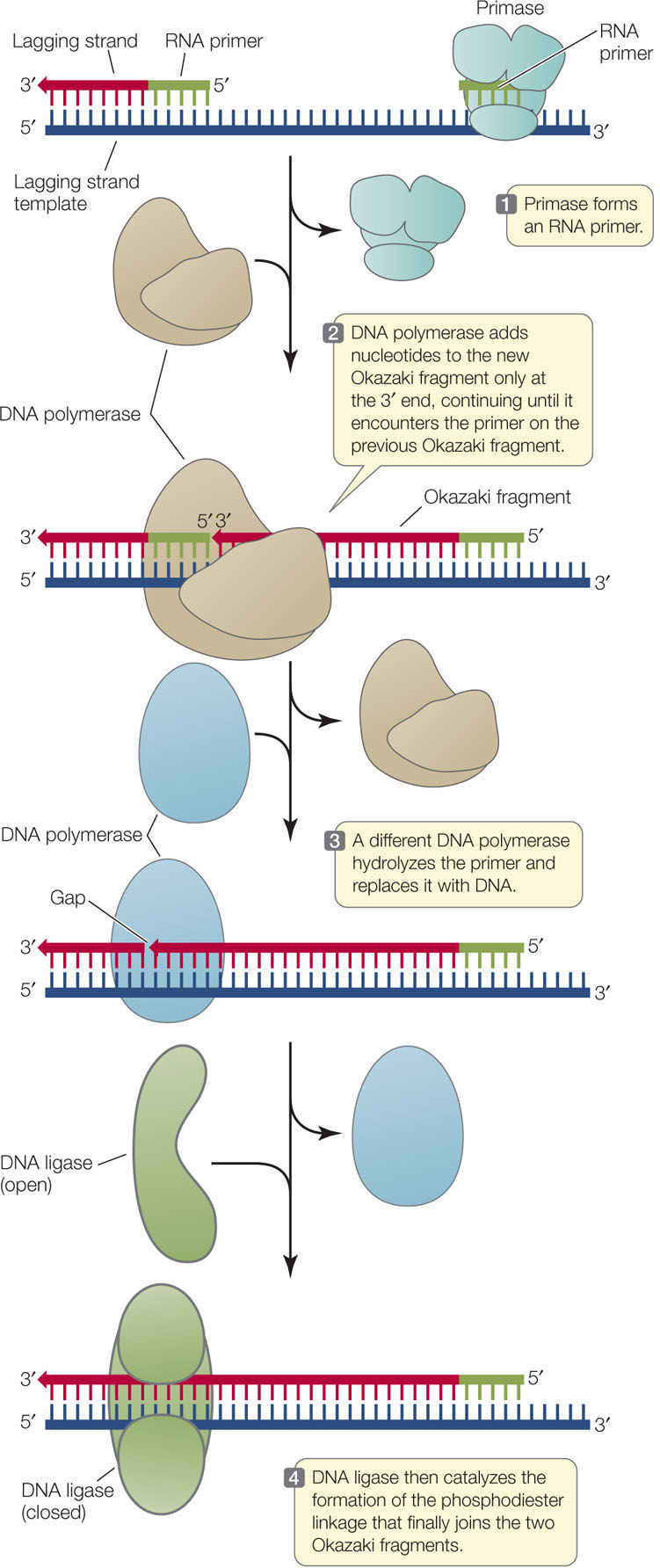
A single primer is needed to initiate synthesis of the leading strand, but each Okazaki fragment requires its own primer to be synthesized by the primase. DNA polymerase then synthesizes an Okazaki fragment by adding nucleotides to one primer until it reaches the primer of the previous fragment. At this point, a different DNA polymerase removes the old primer and replaces it with DNA. Left behind is a tiny nick—the final phosphodiester linkage between the adjacent Okazaki fragments is missing. The enzyme DNA ligase catalyzes the formation of that bond, linking the fragments and making the lagging strand whole (FIGURE 9.12).
DNA replication may appear complex (we have simplified it considerably), but it occurs with astonishing speed and accuracy. As we mentioned earlier, the rate of replication in E. coli is about 1,000 base pairs per second, yet the polymerase commits very few errors—less than 1 base in a million. How do DNA polymerases work so fast? We saw in Concept 3.3 that an enzyme catalyzes a chemical reaction through a series of events:
Substrate binds to enzyme → one product is formed → enzyme is released → cycle repeats
DNA replication would not proceed as rapidly as it does if DNA polymerase went through such a cycle for each nucleotide. Instead, DNA polymerase is processive—that is, it catalyzes many sequential polymerization reactions each time it binds to a DNA molecule:
Substrates bind to enzyme → many products are formed → enzyme is released → cycle repeats
Typically, a DNA polymerase can add thousands of nucleotides before it detaches from DNA.
Telomeres are not fully replicated in most eukaryotic cells
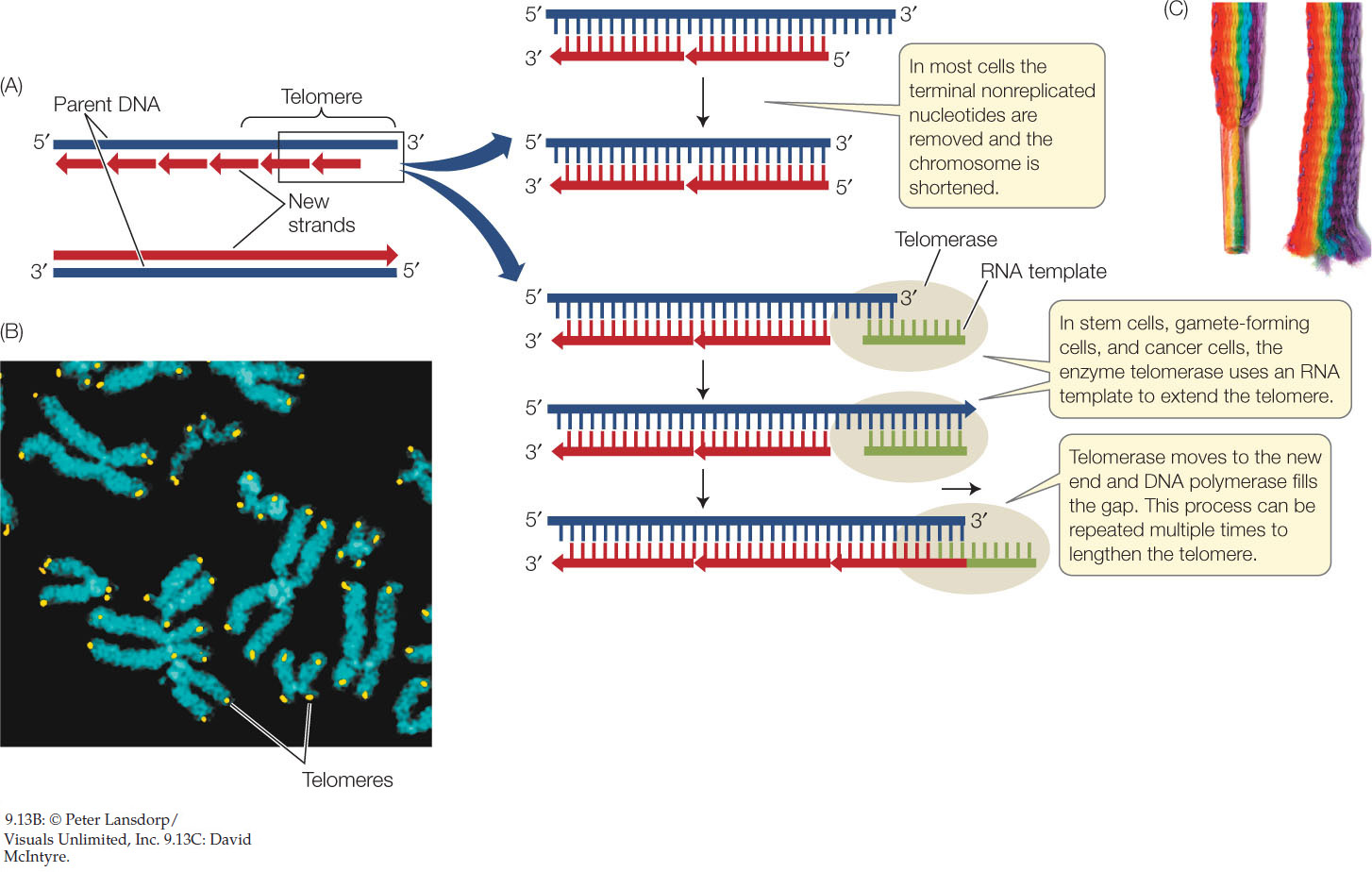
As we have just seen, replication of the lagging strand occurs by the addition of Okazaki fragments to RNA primers. When the terminal RNA primer is removed from the replicating end of a linear eukaryotic chromosome, no DNA can be synthesized to replace it because there is no 3′ end to extend. So the new chromosome has a bit of single-stranded DNA at each end. This situation activates a mechanism for cutting off the single-stranded region, along with some of the intact double-stranded DNA. Thus the chromosome becomes slightly shorter with each cell division (FIGURE 9.13A).
184
Another problem with chromosome ends is that they must be protected from being joined to other chromosomes by the DNA repair system. When DNA is damaged by external or internal agents (e.g., radiation), it is repaired by a combination of DNA polymerase and DNA ligase activities. This system might mistakenly recognize chromosome ends as breaks and join two chromosomes together. This would create havoc with genomic integrity.
To prevent chromosomes from joining, many eukaryotes have strings of repetitive sequences at the ends of their chromosomes called telomeres (FIGURE 9.13B). In humans and other vertebrates, the repeated sequence is TTAGGG, and in humans it is repeated about 2,500 times. These repeats bind a protein complex, appropriately named the shelterin complex, which protects the ends from being joined together by the DNA repair system. In addition, the repeats form loops that have a similar protective role. So telomeres act like the plastic tips of shoelaces to prevent fraying (FIGURE 9.13C).
Each human chromosome can lose 50–200 bp of telomeric DNA after each round of DNA replication and cell division. After 20–30 cell divisions, the chromosome ends become short enough to lose their protective role, and the chromosomes lose their integrity. Apoptosis (programmed cell death) ensues, and the cell dies. This phenomenon explains, in part, why many cell lineages do not last the entire lifetime of the organism: their telomeres are lost. Yet continuously dividing cells, such as bone marrow stem cells and gamete-producing cells, maintain their telomeric DNA. An enzyme called telomerase catalyzes the addition of any lost telomeric sequences in these cells. Telomerase contains an RNA sequence that acts as a template for the telomeric DNA repeat sequence.
There is a relationship between telomere length and aging: the average telomere length is shorter in older individuals. Furthermore, when a gene expressing high levels of telomerase is added to human cells in culture, their telomeres do not shorten. Instead of living 20–30 cell generations and then dying, the cells become immortal. This phenomenon is also seen in mice that overexpress (make more than the usual amount of) telomerase—they live longer. Moreover, cancer cells also overexpress telomerase and can stay alive for longer periods than normal cells. Not surprisingly, drugs that affect telomerase activity are being developed, with the hope of both treating cancer and preventing aging.
Errors in DNA replication can be repaired
We have stressed that DNA must be accurately replicated; the accurate transmission of genetic information is essential for the proper functioning and even the life of a single cell or multi-cellular organism. Yet the replication of DNA is not perfectly accurate. DNA polymerases sometimes insert a base that is not complementary to the template (for example, putting an A in the new DNA strand opposite a C in the template strand). In eukaryotes, the error rate is about 1 incorrect base in 100,000 (a 10−5 error rate). With a genome size of 3 × 109 bp, this would produce 60,000 errors after every cell division. This is an intolerable mutation rate for survival in the long term. However, if eukaryotic DNA sequences are studied before and after a cell cycle, the actual frequency of DNA errors is 10−10 per cell cycle. This means that most of the errors are repaired. There are two major repair mechanisms:
185
- Proofreading occurs right after DNA polymerase inserts a nucleotide (FIGURE 9.14A). When a DNA polymerase recognizes a mispairing of bases, it removes the improperly introduced nucleotide and tries again.
 Figure 9.14: DNA Repair Mechanisms (A) During replication, the DNA polymerase checks for incorrect bases in the new DNA strand and immediately replaces them with correct ones. This process is called proofreading. (B) After replication, mismatch repair proteins search for incorrect bases that were missed by DNA polymerase and replaces them.
Figure 9.14: DNA Repair Mechanisms (A) During replication, the DNA polymerase checks for incorrect bases in the new DNA strand and immediately replaces them with correct ones. This process is called proofreading. (B) After replication, mismatch repair proteins search for incorrect bases that were missed by DNA polymerase and replaces them. - Mismatch repair occurs after DNA has been replicated (FIGURE 9.14B). A second set of proteins surveys the newly replicated molecule and looks for mismatched base pairs that were missed in proofreading. A portion of the DNA including the incorrect nucleotide is removed, and then a DNA polymerase inserts the correct sequence.
The basic mechanisms of DNA replication can be used to amplify DNA in a test tube
The principles underlying DNA replication in cells have been used to develop a laboratory technique that has been vital in analyzing DNA, genes, and genomes. The polymerase chain reaction, or PCR, allows researchers to make multiple copies of short DNA sequences in a test tube—a process referred to as DNA amplification. The PCR technique uses:
- a sample of double-stranded DNA to act as the template
- two short, artificially synthesized primers that are complementary to the ends of the sequence to be amplified
- the four dNTPs (dATP, dTTP, dCTP, and dGTP)
- a DNA polymerase that can tolerate high temperatures without becoming denatured
- salts and a buffer to maintain a near-neutral pH.
PCR is a cyclic process in which a sequence of steps is repeated over and over again (FIGURE 9.15). Since DNA replication is fast even in a test tube, it takes only a short time to go from two to four to millions of short segments of DNA. The PCR technique requires that the base sequences at each end of the amplified fragment be known ahead of time, so that complementary primers, usually 15–30 bases long, can be made in the laboratory. Because of the uniqueness of DNA sequences, a pair of primers this length will usually bind to only a single region of DNA in an organism’s genome. This specificity is a key to the power of PCR to amplify just a small part of a larger DNA molecule. Some of the most striking applications of PCR will be described in Chapters 12 and 13. These applications range from the identification of individuals by their DNA to the detection of diseases.
RESEARCH TOOLS


Go to ANIMATED TUTORIAL 9.5 Polymerase Chain Reaction Simulation
PoL2e.com/at9.5
186
CHECKpoint CONCEPT 9.2
- What is semiconservative DNA replication?
- Why does the leading strand in DNA replicate continuously and the lagging strand discontinuously?
- Cells from older people have shorter telomeres than cells from younger people. How might this relate to aging?
- If you have a small amount of a large chromosome of 20 million bp and want to amplify a short sequence of 1,000 bp, how would you do it? Explain the role of primers in this process.
We have now described (1) the lines of evidence for DNA as the genetic material and (2) the precise replication of DNA during cell division. A less obvious requirement for DNA as the genetic material is its ability to mutate. Mutation creates variability in DNA, which is the raw material for evolution.