Concept 12.3: Eukaryotic Genomes Are Large and Complex
As genomes have been sequenced and described, a number of major differences have emerged between eukaryotic and prokaryotic genomes:
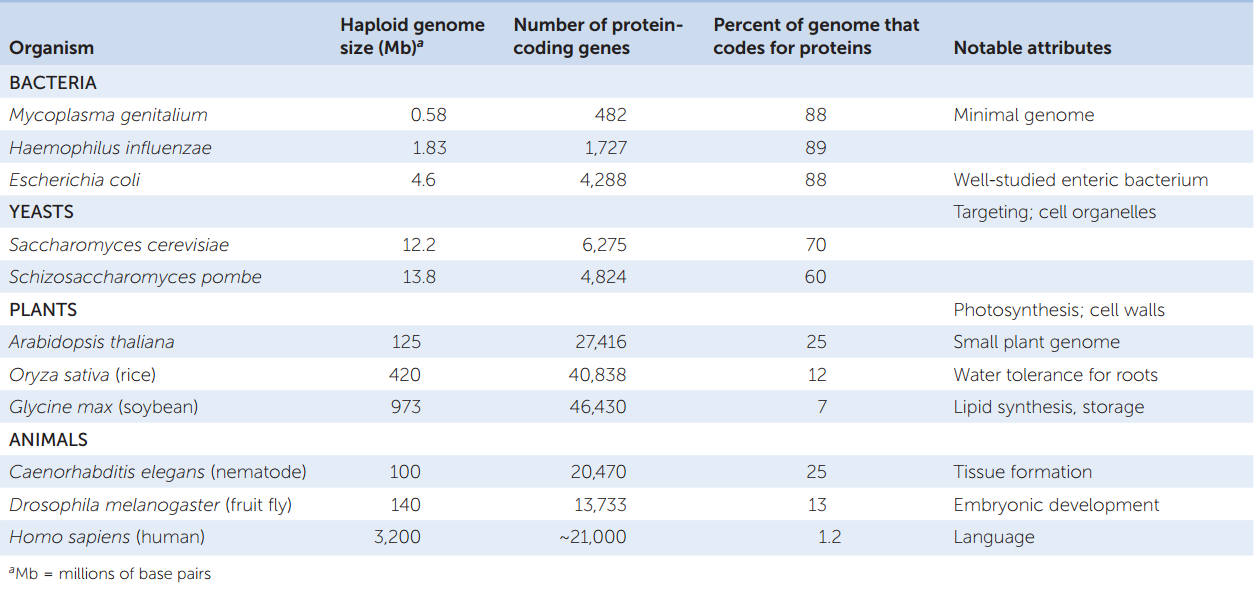
- Eukaryotic genomes are larger than those of prokaryotes, and they have more protein-coding genes. This difference is not surprising given that multicellular organisms have many cell types with specialized functions. As we saw above, one of the simplest prokaryotes, Mycoplasma, has several hundred protein-coding genes in a genome of about 0.5 million bp. A rice plant, in contrast, has about 40,383 protein-coding genes.
- Eukaryotic genomes have more regulatory sequences—and many more regulatory proteins—than prokaryotic genomes. The greater complexity of eukaryotes requires much more regulation, which is evident in the many points of control associated with the expression of eukaryotic genes (see Concept 11.2, Concept 11.3, Concept 11.4 and Figure 11.1).
- Much of eukaryotic DNA does not encode proteins. Distributed throughout many eukaryotic genomes are various kinds of DNA sequences that are not transcribed into mRNA. Some of these sequences are genes for functional RNAs, such as rRNA, tRNA, and miRNA. Others are introns or regulatory sequences. In addition, eukaryotic genomes contain various kinds of repeated sequences.
Model organisms reveal many characteristics of eukaryotic genomes
Most of our information about eukaryotic genomes has come from model organisms that have been studied extensively. These include the yeast Saccharomyces cerevisiae, the nematode (roundworm) Caenorhabditis elegans, the fruit fly Drosophila melanogaster, and the plant Arabidopsis thaliana (thale cress). Model organisms have been chosen because they are relatively easy to grow and study in a laboratory, their genetics are well studied, and they exhibit characteristics that represent a larger group of organisms. TABLE 12.2 shows some characteristics of the genomes of these organisms.
244
APPLY THE CONCEPT: Eukaryotic genomes are large and complex
Repetitive DNA sequences can be classified by nucleic acid hybridization (see Figure 10.7). A genome is initially cut into 300-bp fragments, and these are heated to denature the DNA. If the solution is cooled, the DNA strands will form hydrogen bonds and reassociate into double-stranded structures. If there are many copies of a DNA sequence in the solution (repetitive DNA), it will find its complementary sequence and reassociate faster than if there are only a few copies. The table shows typical results from equal amounts of DNA from three species.
- Why do yeast and mouse DNAs reassociate faster than E. coli DNA?
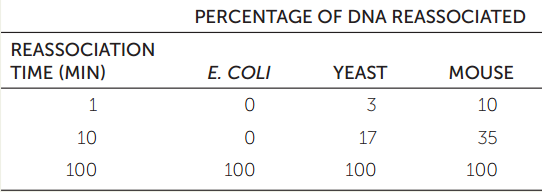
- Would you expect human DNA to reassociate faster or slower than yeast DNA?
Yeast: The Basic Eukaryotic Cell Model
Yeasts are single-celled eukaryotes. Like other eukaryotes, they have membrane-enclosed organelles. They can live as either haploid or diploid organisms, and this is usually determined by environmental conditions: under adverse conditions the diploid cells will undergo meiosis and make spores. Whereas the prokaryote E. coli has a single circular chromosome and 4,288 protein-coding genes, Saccharomyces cerevisiae has 16 linear chromosomes and 6,275 protein-coding genes. The most striking difference between the yeast genome and that of E. coli is in the number of genes involved in secretion or targeting proteins to specific locations within the cell: yeast has 430 such genes; E. coli has only 35. Both of these single-celled organisms appear to use about the same number of genes to perform the basic functions of cell survival. It is the compartmentalization of the eukaryotic yeast cell into organelles that requires it to have many more genes. This finding is direct, quantitative confirmation of something we have known for a century: the eukaryotic cell is structurally and functionally more complex than the prokaryotic cell.
The Nematode: Understanding Cell Differentiation

The 1-millimeter-long nematode Caenorhabditis elegans normally lives in the soil. It can also live in the laboratory, where it has become a favorite model organism of developmental biologists (see Chapter 14). The nematode has a transparent body of about 1,000 somatic cells. It develops over 3 days from a fertilized egg to an adult worm that has a nervous system, digests food, and reproduces sexually. Its genome is 8 times larger than that of yeast and has about 3.3 times as many protein-coding genes. Many of these extra genes encode proteins needed for cell differentiation, for intercellular communication, and for holding cells together to form tissues.
245
{em}Drosophila Melanogaster{/em}: Understanding Genetics And Development

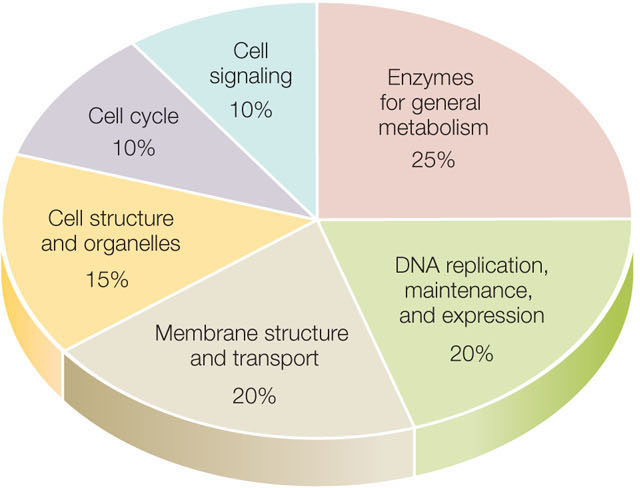
The fruit fly Drosophila melanogaster is a famous model organism. Studies of fruit fly genetics resulted in the formulation of many basic principles of genetics (see Concept 8.3). The fruit fly is a much larger organism than C. elegans (it has ten times as many cells), and it is much more complex: it undergoes complicated developmental transformations from egg to larva to pupa to adult. These differences are reflected in the fruit fly genome, which has many genes encoding transcription factors needed for complex embryonic development (you will study some of these in Chapter 14). In general, the fruit fly genome has a distribution of coding sequence functions quite similar to those of many other complex eukaryotes (FIGURE 12.9).
{em}Arabidopsis{/em}: Studying The Genomes of Plants

About 250,000 species of flowering plants dominate the land and fresh water. Although there is generally more interest in the plants we use for food and fiber, scientists first sequenced the genome of a simpler flowering plant with a relatively small genome. Arabidopsis thaliana, thale cress, is a member of the mustard family and has long been a favorite model organism of plant biologists. It is small (hundreds could grow and reproduce in the space occupied by this page) and easy to manipulate. Its genome has about 27,400 protein-coding genes, but many of these are duplicates and probably originated by chromosomal rearrangements. When these duplicate genes are subtracted from the total, about 15,000 unique genes are left—similar to the gene numbers found in fruit flies and nematodes. Indeed, many of the genes found in these animals have orthologs—genes that are derived from a common ancestral gene—in Arabidopsis and other plants, supporting the idea that plants and animals have a common ancestor.
Arabidopsis has some genes, however, that are unique to plants. These include genes involved in photosynthesis, in the transport of water throughout the plant, in the assembly of the cell wall, in the uptake and metabolism of inorganic substances from the environment, and in the synthesis of specific molecules used for defense against microbes and herbivores. These plant defense molecules may be a major reason why the numbers of protein-coding genes in some plants are higher than in many animals. Plants cannot escape their enemies or other adverse conditions as animals can, and they must cope with situations where they are. So they make tens of thousands of molecules to help them fight their enemies and adapt to their changing environments (see Chapter 28).
These plant-specific genes are also found in the genomes of other plants, including rice (Oryza sativa), the first major crop plant to be fully sequenced. Rice is the world’s most important crop—it is a staple in the diets of 3 billion people. The larger genome of rice has a set of genes remarkably similar to that of Arabidopsis. The genome of the poplar tree Populus trichocarpa was also sequenced, to gain insight into the potential for this rapidly growing tree to be used as a source of fuel. Several more plant genomes have now been sequenced. Comparisons among diverse flowering plant species (including Arabidopsis, rice, poplar, and sorghum) suggest that about 12,000 protein-coding genes are shared among all flowering plants (FIGURE 12.10). These may comprise the basic plant genome.
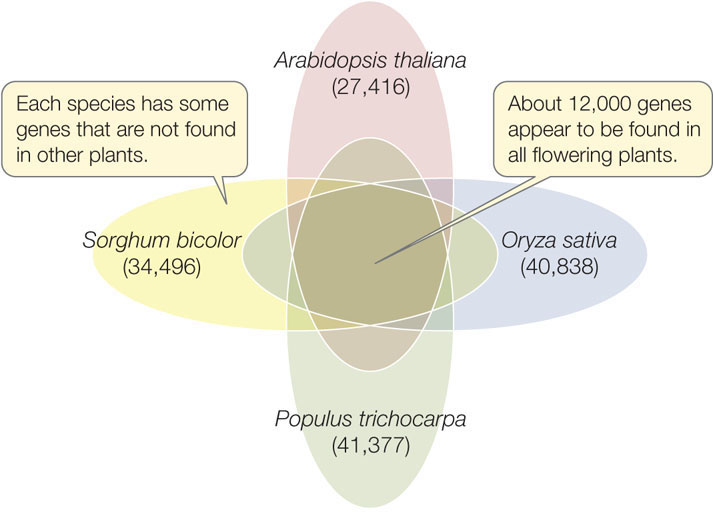
246
Gene families exist within individual eukaryotic organisms
About half of all eukaryotic protein-coding genes exist as only one copy in the haploid genome (with two alleles in diploid somatic cells). The other half are present in multiple copies that arose from gene duplications. Over evolutionary time, different copies of the genes have undergone separate mutations, giving rise to groups of closely related genes called gene families. Some gene families, such as those encoding the globin proteins that make up hemoglobin, contain only a few members in a single organism. Other families, such as the genes encoding the immunoglobulins that make up antibodies, have hundreds of members.
Within a single organism, the genes in a family are usually slightly different from one another. As long as at least one member encodes a functional protein, the other members may mutate in ways that change the functions of the proteins they encode. For evolution, the availability of multiple copies of a gene allows for selection of mutations that provide advantages under certain circumstances. If a mutated gene is useful, it may be selected for in succeeding generations. If the mutated gene is a total loss, the functional copy is still there to carry out its role.
As an example, let’s look at the gene family encoding the globins in vertebrates. These proteins are found in hemoglobin and myoglobin (an oxygen-binding protein present in muscle). The globin genes all arose long ago from a single common ancestral gene (see Figure 15.23). In humans there are three functional members of the α-globin cluster and five in the β-globin cluster (FIGURE 12.11). Each hemoglobin molecule in an adult human is a tetramer containing two identical α-globin subunits, two identical β-globin subunits, and four heme pigments (see Chapter 3).
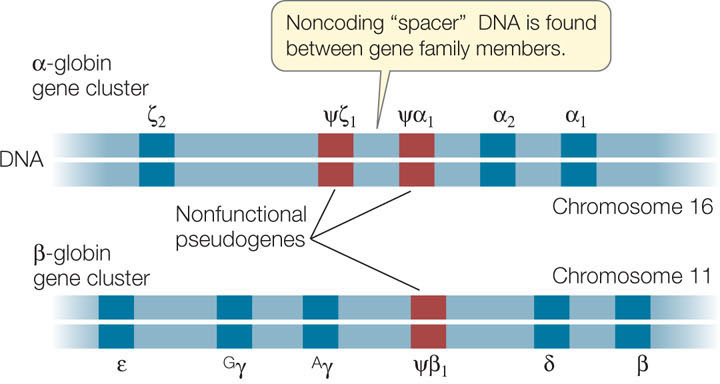
During human development, different genes of the globin gene cluster are expressed at different times and in different tissues. This differential gene expression has great physiological significance. For example, the hemoglobin in the human fetus contains γ-globin, which binds O2 more tightly than adult hemoglobin does. This specialized form of hemoglobin ensures that in the placenta, O2 is transferred from the mother’s blood to the developing fetus’s blood. Just before birth the liver stops synthesizing fetal hemoglobin and the bone marrow cells take over, making the adult forms (two α and two β). Thus hemoglobins with different binding affinities for O2 are provided at different stages of human development.
LINK
Gene duplication plays a role in the evolution of new protein functions, as described in Concept 15.6
In addition to genes that encode functional proteins, many gene families include nonfunctional pseudogenes, which are designated with the Greek letter psi (ψ; see Figure 12.11). These pseudogenes result from mutations that cause a loss of function rather than an enhanced or new function. The DNA sequence of a pseudogene may not differ greatly from that of other family members. It may simply lack a promoter, for example, and thus fail to be transcribed. Or it may lack a recognition site needed for the removal of an intron, so that the transcript it makes is not correctly processed into a useful mature mRNA. In some gene families pseudogenes outnumber functional genes. Because some members of the family are functional, there appears to be little selection pressure to preserve the functions of these pseudogenes.
Eukaryotic genomes contain many repetitive sequences
Eukaryotic genomes contain numerous repetitive DNA sequences that do not code for polypeptides. There are highly repetitive sequences and moderately repetitive sequences, which include rRNA genes, tRNA genes, and transposons (TABLE 12.3).
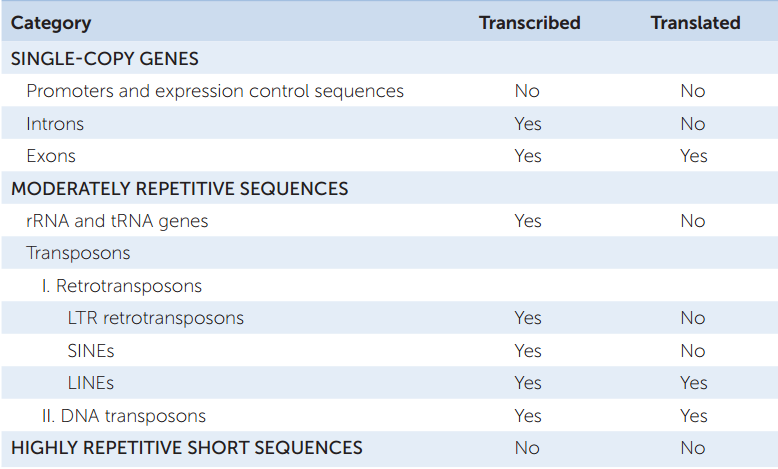
Highly repetitive sequences are short (less than 100 bp) sequences that are repeated thousands of times in tandem (side-by-side) arrangements in the genome. They are not transcribed. Their proportion in eukaryotic genomes varies, from 10 percent in humans to about half the genome in some species of fruit flies. Often they are associated with heterochromatin, the densely packed, largely transcriptionally inactive part of the genome (see Concept 11.3). Other highly repetitive sequences are scattered around the genome. For example, short tandem repeats (STRs) of 1–5 bp can be repeated up to 100 times at a particular chromosomal location. The copy number of an STR at a particular location varies among individuals and is inherited.
247
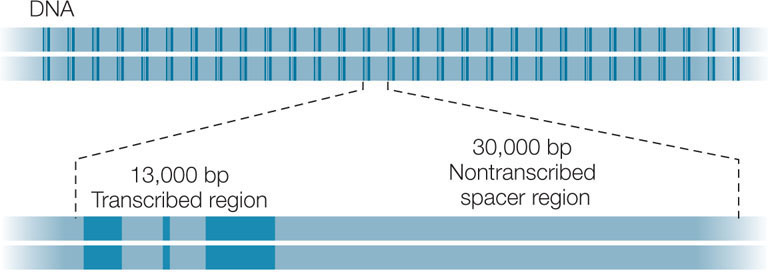
Moderately repetitive sequences are repeated 10–1,000 times in the eukaryotic genome. These sequences include the genes that are transcribed to produce tRNAs and rRNAs, which are used in protein synthesis. The cell makes tRNAs and rRNAs constantly, but even at the maximum rate of transcription, single copies of the tRNA and rRNA genes would be inadequate to supply the large amounts of these molecules needed by most cells. Thus the genome has multiple copies of these genes, in clusters containing transcribed regions (with introns) and non-transcribed “spacers” between the genes. Here, for example, is a region that encodes multiple sets of rRNA genes (in dark blue):
Most moderately repetitive sequences are not stably integrated into the genome but instead are transposons (see Figure 12.7). Transposons make up more than 40 percent of the human genome. There are two main types of transposons in eukaryotes: retrotransposons (Class I transposons) and DNA transposons (Class II; see Table 12.3).
Retrotransposons make RNA copies of themselves, which are then copied back into DNA before insertion at new locations in the genome. They are divided into two categories:
- LTR retrotransposons have long terminal repeats (LTRs) of DNA sequence (100–5,000 bp) at each end. LTR retrotransposons constitute about 8 percent of the human genome.
- Non-LTR retrotransposons do not have LTR sequences at their ends. They are further divided into two subcategories: SINEs and LINEs. SINEs (short interspersed elements) are up to 500 bp long and are transcribed but not translated. There are about 1.5 million of them scattered over the human genome, making up about 15 percent of the total DNA content. A single type, the 300-bp Alu element, accounts for 11 percent of the human genome; it is present in a million copies. LINEs (long interspersed elements) are up to 7,000 bp long, and some are transcribed and translated into proteins. They constitute about 17 percent of the human genome.
DNA transposons do not use RNA intermediates. Like some prokaryotic transposons, they are excised from the original location and become inserted at a new location without being replicated.
With so much of the genome made up of transposons, they must have a role in addition to just replicating themselves (“selfish DNA”). One possibly important function occurs when such a sequence moves to a new location within the coding region of a gene and causes mutation by disrupting it. Mutations are the raw material of evolution by natural selection. In most cases, the ability to move about the genome has been suppressed, so transposons are stable and do not move. Some occur within introns, where they may affect alternative splicing of pre-mRNA, causing phenotypic diversity. Others are at or near gene regulatory sequences such as promoters, where they can also affect gene expression.
CHECKpoint CONCEPT 12.3
- Compare the general properties of the genomes of prokaryotes and eukaryotes.
- Does the size of a genome determine how much information it contains? Explain in terms of repetitive sequences and protein-coding genes.
- What is the evolutionary role of eukaryotic gene families?
- During transposition, an adjacent gene is sometimes transposed along with a retrotransposon. What would be the consequence of making a new copy of this gene at a new location in the genome?
The analysis of eukaryotic genomes has resulted in an enormous amount of useful information, as we have seen. In the next concept we will look more closely at the human genome.