2.5 ORGANIC MOLECULES
The chemistry of carbon creates diverse geometries, which in turn lead to molecules with different structures and functions. These molecules perform essential tasks of the cell, including the establishment of a boundary to separate the inside of the cell from the environment, the storage and transmission of genetic information, and the capture, storage, and utilization of energy from the environment. These processes depend on just a few classes of carbon-based molecules. Proteins provide structural support and act as catalysts that facilitate chemical reactions. Nucleic acids encode and transmit genetic information. Carbohydrates provide a source of energy and make up the cell wall in bacteria, plants, and algae. Lipids make up cell membranes, store energy, and act as signaling molecules.
These molecules are all relatively large, and most are polymers, complex molecules made up of repeated simpler units connected by covalent bonds. Proteins are polymers of amino acids, nucleic acids are made up of nucleotides, and carbohydrates such as starch are built from simple sugars. Lipids are a bit different, as we will see—they are defined by a property rather than by their chemical structure. The lipid membranes that define cell boundaries consist of fatty acids bonded to other organic molecules.
Building macromolecules from simple, repeating units provides a means of generating virtually limitless chemical diversity. Indeed, in macromolecules, the building blocks of polymers play a role much like that of the letters in words. In written language, a change in the content or order of letters changes the meaning of the word (or renders it meaningless). For example, by reordering the letters of the word “SILENT” you can write “LISTEN,” a word with a different meaning. Similarly, rearranging the building blocks that make up macromolecules provides an important way to make a large number of diverse macromolecules.
In the following section, we focus on the building blocks of these four key molecules of life, reserving a discussion of the structure and function of the macromolecules for later chapters.
2.5.1 Proteins are composed of amino acids.
Proteins do much of the cell’s work. Some function as catalysts that accelerate the rates of chemical reactions (in which case they are called enzymes), and some act as structural components necessary for cell shape and movement. Your body contains many thousands of proteins that perform a wide range of functions. Since proteins consist of amino acids linked covalently to form a chain, we need to examine the chemical features of amino acids to understand the diversity and versatility of proteins.
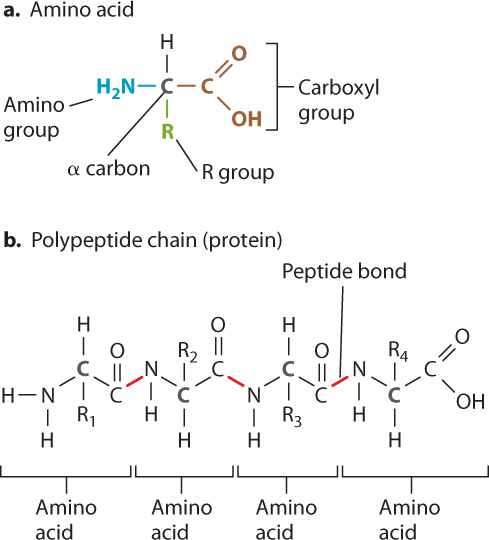
The general structure of an amino acid is shown in Fig. 2.17a. Each amino acid contains a central carbon atom, called the α (alpha) carbon, covalently linked to four groups: a carboxyl group (COOH; red), an amino group (NH2; blue), a hydrogen atom (H), and an R group, or side chain, (green) that differs from one amino acid to the next. The identity of each amino acid is determined by the structure and composition of the side chain. The side chain of the amino acid glycine is simply H, for example, and that of alanine is CH3. In most amino acids, the α-carbon is covalently linked to four different groups. Glycine is the exception, since its R group is a hydrogen atom.
Amino acids are linked in a chain to form a protein (Fig. 2.17b). The carbon atom in the carboxyl group of one amino acid is joined to the nitrogen atom in the amino group of the next by a covalent linkage called a peptide bond. In Fig. 2.17b, the chain of amino acids includes four amino acids, and the peptide bonds are indicated in red. The formation of a peptide bond involves the loss of a water molecule since in order to form a C–N bond, the carbon atom must release an oxygen atom and the nitrogen must release two hydrogen atoms. These can then combine to form a water molecule (H2O). The loss of a water molecule is a consistent feature in the linking of subunits to form polymers such as nucleic acids and complex carbohydrates.
Cellular proteins are composed of 20 amino acids, which can be classified according to the chemical properties of their side chains. The particular sequence, or order, in which amino acids are present in a protein determines how it folds into its three-dimensional structure. The three-dimensional structure, in turn, determines the protein’s function. In Chapter 4, we will examine how the sequence of amino acids in a particular protein is specified and discuss how proteins fold into their three-dimensional configuration.
2.5.2 Nucleic acids encode genetic information in their nucleotide sequence.
Nucleic acids are examples of informational molecules—that is, they are large molecules that carry information in the sequence of nucleotides that make them up. This molecular information is much like the information carried by the letters in an alphabet, but in the case of nucleic acids, the information is in chemical form.
The nucleic acid deoxyribonucleic acid (DNA) is the genetic material in all organisms. It is transmitted from parents to offspring, and it contains the information needed to specify the amino acid sequence of all the proteins synthesized in an organism. The nucleic acid ribonucleic acid (RNA) has multiple functions; it is a key player in protein synthesis and the regulation of gene expression.
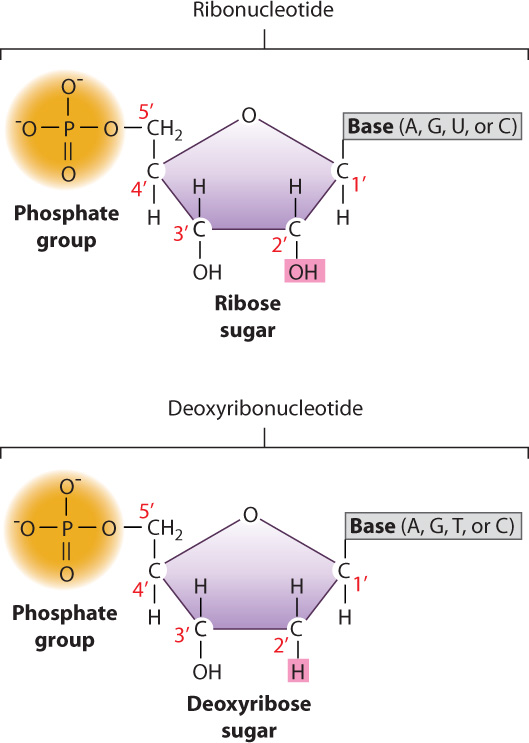
DNA and RNA are long molecules consisting of nucleotides bonded covalently one to the next. Nucleotides, in turn, are composed of three components: a 5-carbon sugar, a nitrogen-containing compound called a base, and one or more phosphate groups (Fig. 2.18). The sugar in RNA is ribose, and the sugar in DNA is deoxyribose. The sugars differ in that ribose has a hydroxyl (OH) group on the second carbon (designated the 2′ carbon), while deoxyribose has a hydrogen atom at this position (hence, deoxyribose). (By convention, the carbons in the sugar are numbered with primes—1′, 2′, etc.—to distinguish them from carbons in the base—1, 2, etc.)
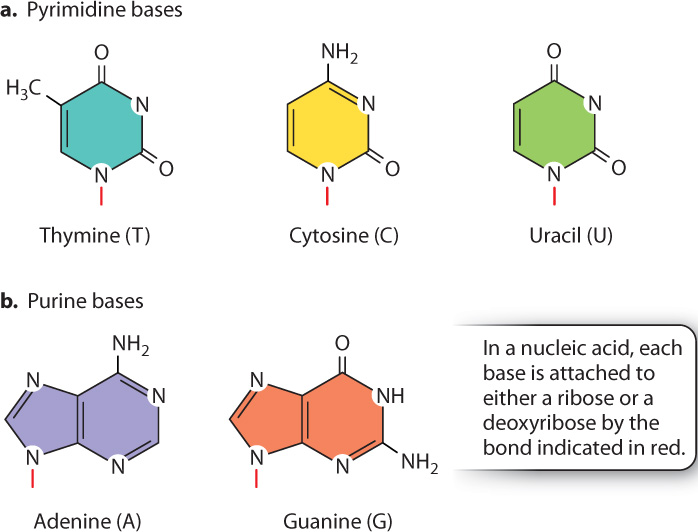
The bases are built from nitrogen-containing rings and are of two types. The pyrimidine bases (Fig. 2.19a) have a single ring and include thymine (T), cytosine (C), and uracil (U). The purine bases (Fig. 2.19b) have a double-ring structure and include adenine (A) and guanine (G). DNA contains the bases A, T, G, and C, and RNA contains the bases A, U, G, and C. Just as the order of amino acids provides the unique information carried in proteins, so, too, does the sequence of nucleotides determine the information in DNA and RNA molecules.
In DNA and RNA, each adjacent pair of nucleotides is connected by a phosphodiester bond, which forms when a phosphate group in one nucleotide is covalently joined to the sugar unit in another nucleotide (Fig. 2.20). As in the formation of a peptide bond, the formation of a phosphodiester bond involves the loss of a water molecule.
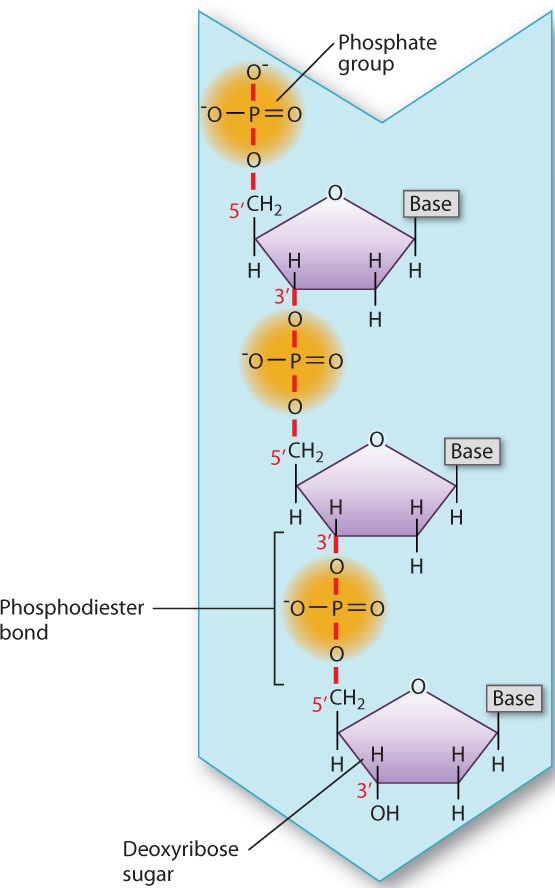
DNA in cells usually consists of two strands of nucleotides twisted around each other in the form of a double helix (Fig. 2.21a). The sugar–phosphate backbones of the strands wrap like a ribbon around the outside of the double helix, and the bases are pointed inward. The bases form specific purine–pyrimidine pairs that are said to be complementary: Where one strand carries an A, the other carries a T; and where one strand carries a G, the other carries a C (Fig. 2.21b). Base pairing results from hydrogen bonding between the bases (Fig. 2.21c).
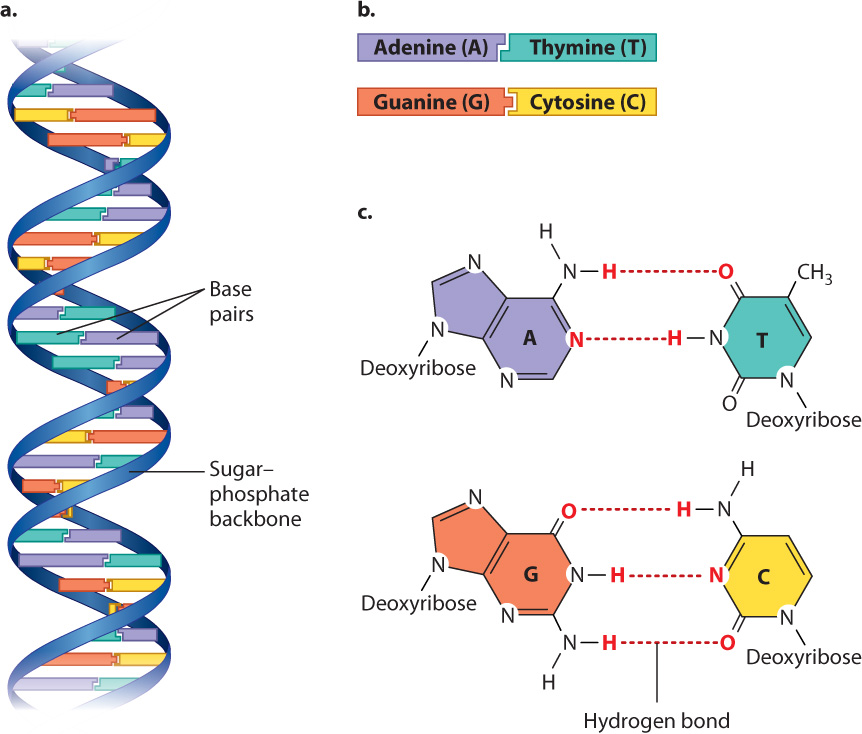
Genetic information in DNA is contained in the sequence, or order, in which successive nucleotides occur along the molecule. Successive nucleotides along a DNA strand can occur in any order, and hence a long molecule could contain any of an immense number of possible nucleotide sequences. This is one reason why DNA is an efficient carrier of genetic information. In Chapter 3, we consider the structure and function of DNA and RNA in greater detail.
2.5.3 Complex carbohydrates are made up of simple sugars.
Many of us, when we feel tired, reach for a candy bar for a quick energy boost. The quick energy in a candy bar comes from sugars, which are quickly broken down to release energy. Sugars belong to a class of molecules called carbohydrates, distinctive molecules composed of C, H, and O atoms, usually in the ratio 1:2:1. Carbohydrates provide a principal source of energy for metabolism.
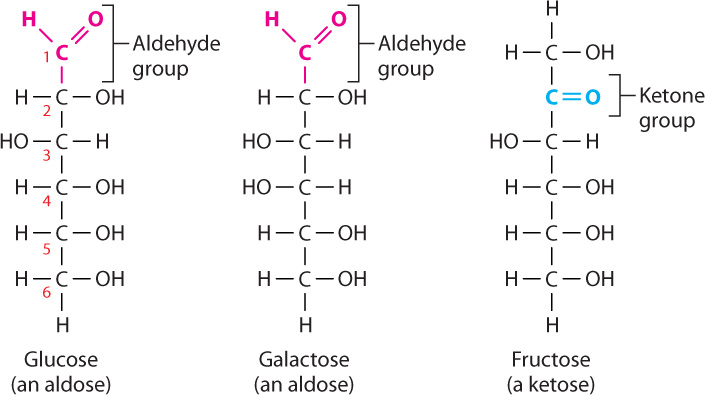
The simplest carbohydrates are sugars (also called saccharides). Simple sugars are linear or, far more commonly, cyclic molecules containing five or six carbon atoms. All six-carbon sugars have the same chemical formula (C6H12O6) and differ only in configuration. Glucose (the product of photosynthesis), galactose (found in dairy products), and fructose (a commercial sweetener) are examples; they share the same formula (C6H12O6) but differ in the arrangement of their atoms (Fig. 2.22).
Quick Check 4
Take a close look at Fig. 2.22. How is glucose different from galactose?
A simple sugar is also called a monosaccharide (mono means “one”), and two simple sugars linked together by a covalent bond is called a disaccharide (di means “two”). Sucrose (C12H22O11), or table sugar, is a disaccharide that combines one molecule each of glucose and fructose. As noted above, nucleotides contain a 5-carbon sugar, either ribose (in RNA) or deoyxribose (in DNA). Simple sugars combine in many ways to form polymers called polysaccharides (poly means “many”) that provide long-term energy storage (starch and glycogen) or structural support (cellulose in plant cell walls). Long, branched chains of monosaccharides are called complex carbohydrates.
Let’s take a closer look at monosaccharides, the simplest sugars. Monosaccharides are unbranched carbon chains with either an aldehyde (HC O) or a ketone (CO) group (Fig. 2.22). Monosaccharides with an aldehyde group are called aldoses and those with a ketone group are known as ketoses. In both types of monosaccharides, the other carbons each carry one hydroxyl (OH) group and one hydrogen (H) atom. When the linear structure of a monosaccharide is written with the aldehyde or ketone group at the top, the carbons are numbered from top to bottom.
O) or a ketone (CO) group (Fig. 2.22). Monosaccharides with an aldehyde group are called aldoses and those with a ketone group are known as ketoses. In both types of monosaccharides, the other carbons each carry one hydroxyl (OH) group and one hydrogen (H) atom. When the linear structure of a monosaccharide is written with the aldehyde or ketone group at the top, the carbons are numbered from top to bottom.
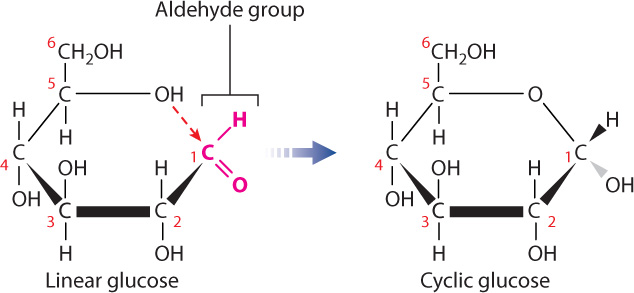
Virtually all of the monosaccharides in cells are in ring form (Fig. 2.23), not linear structures. To form a ring, the carbon in the aldehyde or ketone group forms a covalent bond with the oxygen of a hydroxyl group carried by another carbon in the same molecule. For example, cyclic glucose is formed when the oxygen atom of the hydroxyl group on carbon 5 forms a covalent bond with carbon 1, which is part of an aldehyde group. The cyclic structure is approximately flat, and you can visualize it perpendicular to the plane of the paper with the covalent bonds indicated by the thick lines in the foreground. The groups attached to any carbon therefore project either above or below the ring. When the ring is formed, the aldehyde oxygen becomes a hydroxyl group.
Monosaccharides, especially 6-carbon sugars, are the building blocks of complex carbohydrates. Monosaccharides are attached to each other by covalent bonds called glycosidic bonds (Fig. 2.24). As with peptide bonds, the formation of glycosidic bonds involves the loss of a water molecule. A glycosidic bond is formed between carbon 1 of one monosaccharide and a hydroxyl group carried by a carbon atom in a different monosaccharide molecule.
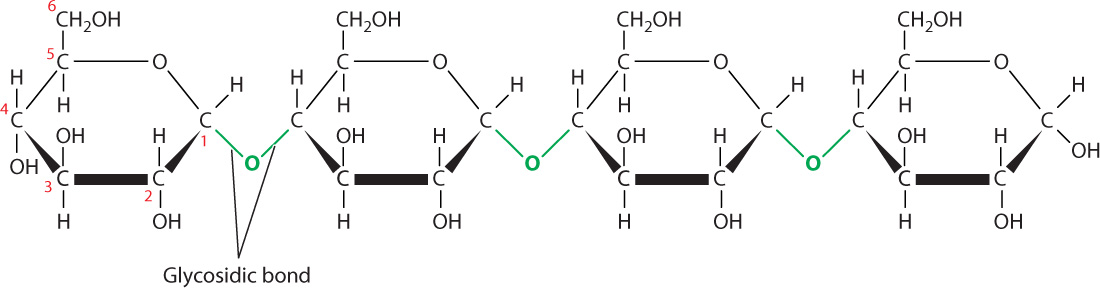
Carbohydrate diversity stems in part from the monosaccharides that make them up, similar to the way that protein and nucleic acid diversity stems from the sequence of their subunits. Some complex carbohydrates are composed of a single type of monosaccharide, while others are a mix of different kinds of monosaccharide. Starch, for example, is a sugar storage molecule in plants composed completely of glucose molecules, whereas pectin, a component of the cell wall, contains up to five different monosaccharides.
2.5.4 Lipids are hydrophobic molecules.
Proteins, nucleic acids, and carbohydrates all are polymers made up of smaller, repeating units with a defined structure. Lipids are different. Instead of being defined by a chemical structure, they share a particular property: Lipids are all hydrophobic. Because they share a property and not a structure, lipids are a chemically diverse group of molecules. They include familiar fats that make up part of our diet, components of cell membranes, and signaling molecules. Let’s briefly consider each in turn.
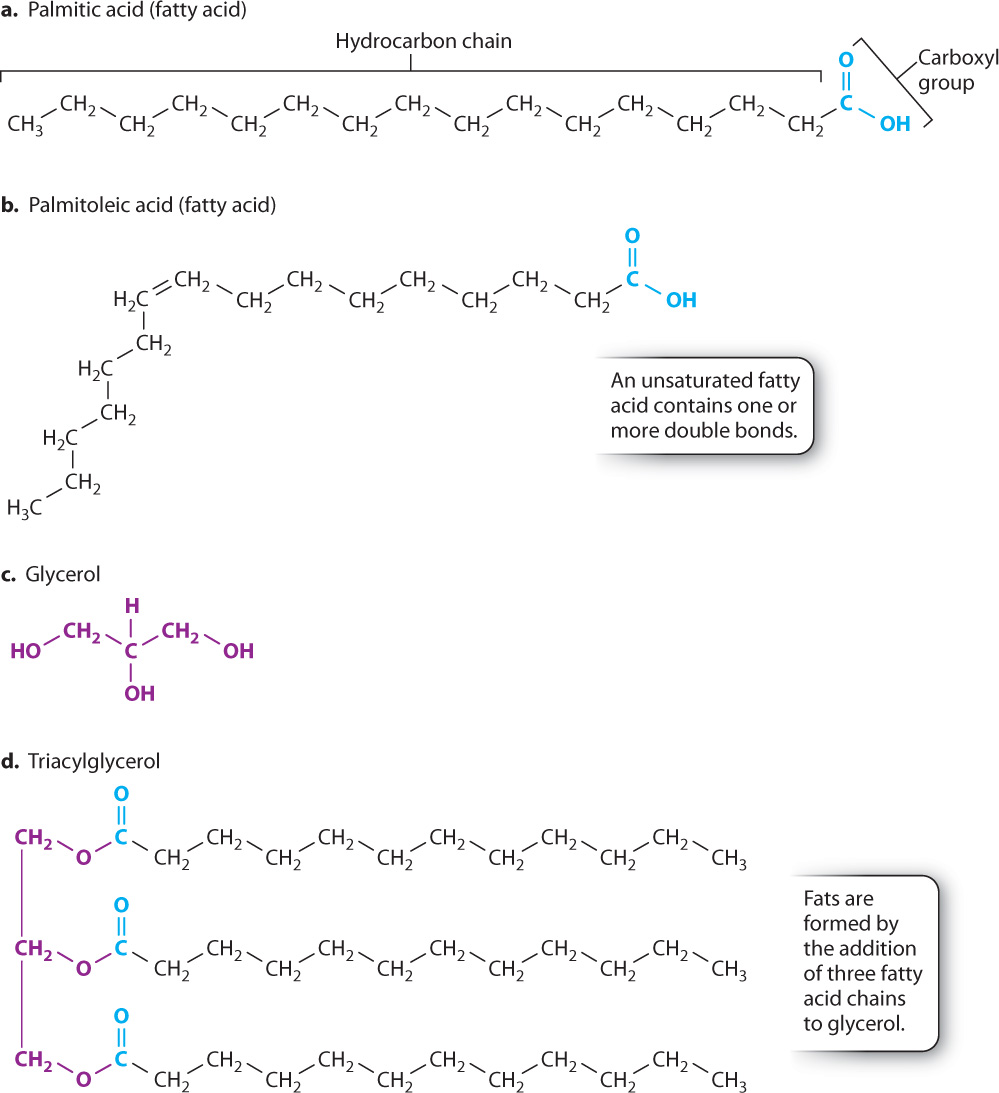
Triacylglycerol is an example of a lipid that is used for energy storage. It is the major component of animal fat and vegetable oil. A triacylglycerol molecule is made up of three fatty acids joined to glycerol (Fig. 2.25). A fatty acid is a long chain of carbons attached to a carboxyl group (COOH) at one end (Figs. 2.25a and 2.25b). Glycerol is a 3-carbon molecule with OH groups attached to each carbon (Fig. 2.25c).
Fatty acids differ in the length (that is, in the number of carbons) of their hydrocarbon chain. Most fatty acids in cells contain an even number of carbons because they are synthesized by the stepwise addition of 2-carbon units. Some fatty acids have one or more carbon–carbon double bonds; these double bonds can differ in number and location. Fatty acids that do not contain double bonds are described as saturated. Because there are no double bonds, the maximum number of hydrogen atoms is attached to each carbon atom, so all of the carbons are said to be “saturated” with hydrogen atoms (Fig. 2.25a). Fatty acids that contain carbon–carbon double bonds are unsaturated (Fig. 2.25b). The chains of saturated fatty acids are straight, while the chains of unsaturated fatty acids have a kink at each double bond.
Triacylglycerols can contain different types of fatty acids attached to the glycerol backbone. They are all extremely hydrophobic and, therefore, triacylglycerols form oil droplets inside the cell. Triacylglycerols are an efficient form of energy storage because by excluding water molecules a large number can be packed into a small volume.
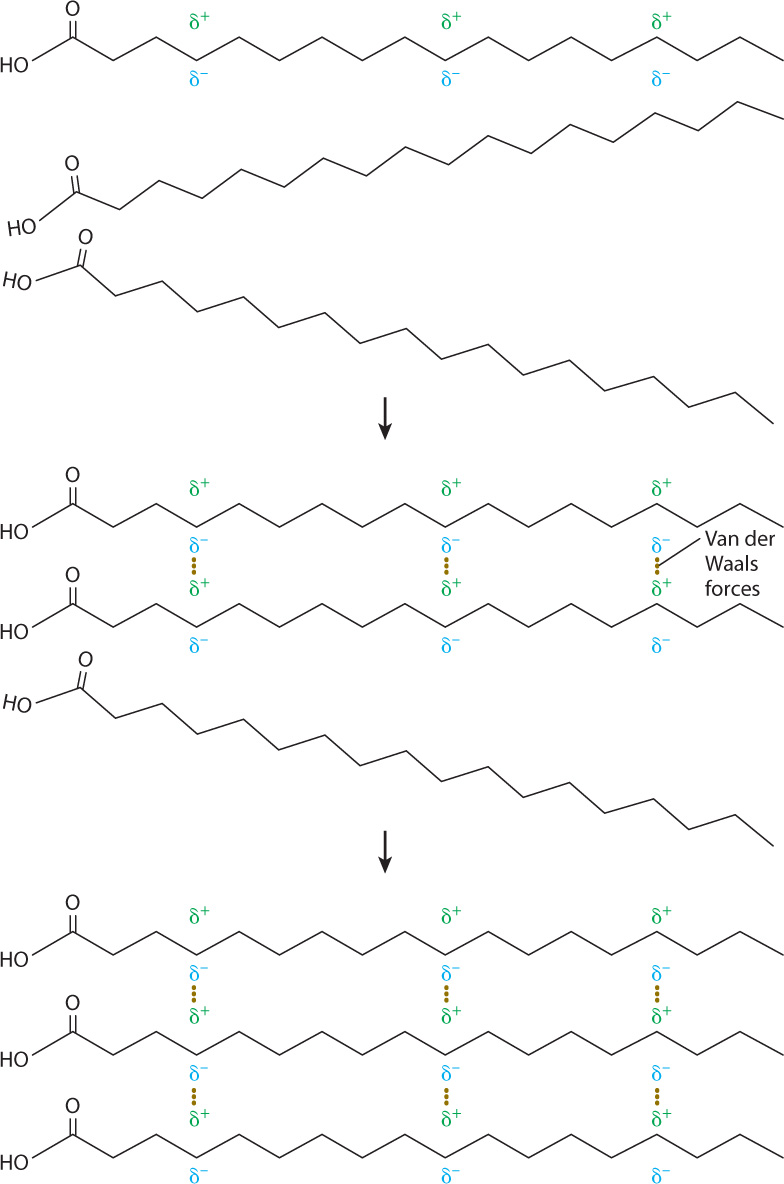
The hydrocarbon chains of fatty acids do not contain polar covalent bonds like those in a water molecule. Their electrons are distributed uniformly over the whole molecule and thus these molecules are uncharged. However, the constant motion of electrons leads to regions of slight positive and negative charges (Fig. 2.26). These charges in turn attract or repel electrons in neighboring molecules, setting up areas of positive and negative charge in those molecules as well. The temporarily polarized molecules weakly bind to one another because of the attraction of opposite charges. These interactions are known as van der Waals forces. The van der Waals forces are weaker than hydrogen bonds, but many of them acting together help to stabilize molecules.
Because of van der Waals forces, the melting points of fatty acids depend on their length and level of saturation. As the length of the hydrocarbon chains increases, the number of van der Waals bonds between the chains also increases, and this in turn increases the melting temperature. Kinks introduced by double bonds reduce the tightness of the molecular packing and lead to fewer intermolecular interactions and a lower melting temperature. Therefore, an unsaturated fatty acid has a lower melting point than a saturated fatty acid of the same length. Animal fats such as butter are composed of triacylglycerols with saturated fatty acids and are solid at room temperature, whereas plant fats and fish oils are composed of triacylglycerols with unsaturated fatty acids and are liquid at room temperature.
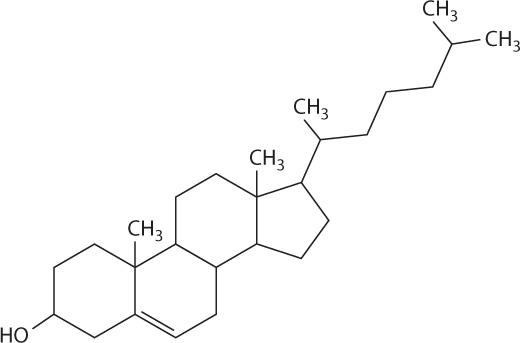
Steroids such as cholesterol are a second type of lipid (Fig. 2.27). Like other steroids, cholesterol has a core composed of 20 carbon atoms bonded to form four fused rings, and it is hydrophobic. Cholesterol is a component of animal cell membranes (Chapter 5) and serves as a precursor for the synthesis of steroid hormones such as estrogen and testosterone (Chapter 38).
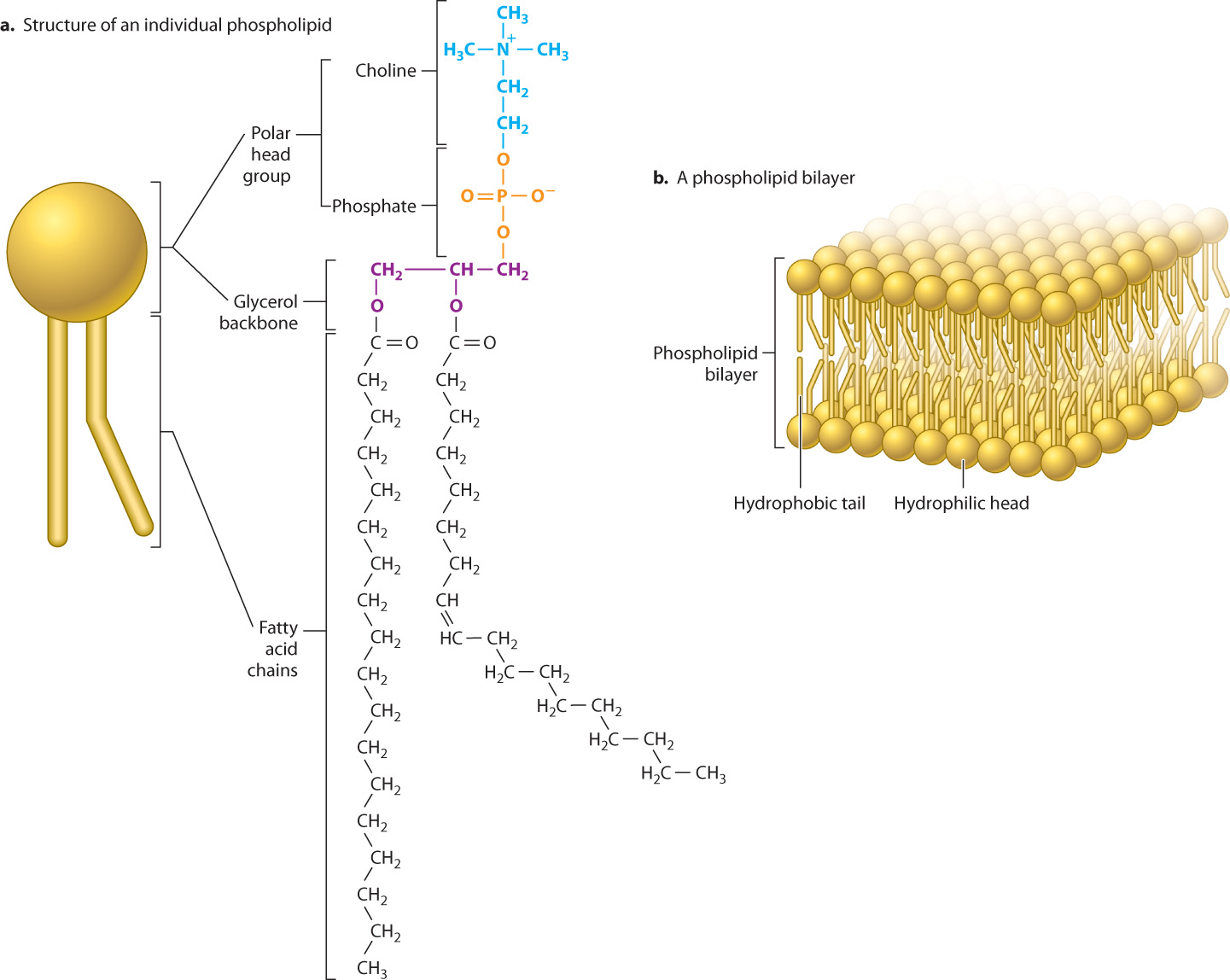
Phospholipids are a third type of lipid and a major component of the cell membrane. Whereas triacylglycerol is made up of glycerol attached to three fatty acids, most phospholipids are made up of glycerol attached to two fatty acids and a third molecule that contains a phosphate group (Fig. 2.28a). The phosphate “head” group is hydrophilic, while the fatty acid “tails” are hydrophobic. As a result, phospholipids have hydrophobic and hydrophilic groups in the same molecule, giving them an interesting property when placed in water: They form a variety of structures all of which limit the exposure of the hydrophobic tails to water. One important structure is a bilayer, a two-layered structure with the hydrophilic heads pointing outward toward the aqueous environment and the hydrophobic tails oriented inward, away from water (Fig. 2.28b). The formation of lipid bilayers is discussed more fully in the next chapter.