13.3 GENE NUMBER, GENOME SIZE, AND ORGANISMAL COMPLEXITY
Before whole-genome sequencing, molecular biology and evolution research tended to focus on single genes. Researchers studied how individual genes are turned on and off, and how a gene in one organism is related to a gene in another organism. Now, with the availability of genome sequences from multiple species, it is possible to make comparisons across full genomes. Some of the results have been striking.
13.3.1 Gene number is not a good predictor of biological complexity.
The complete genome sequences of many organisms allow us to make comparisons among them. One of the surprising results is the relatively low number of genes in humans relative to the number in other species sequenced (Table 13.1). Because humans are so much more complex in cell number and type, and in behavior, it was expected that we would have many more genes than we do.
| Table 13.1: Gene Numbers of Several Organisms | ||
|---|---|---|
| COMMON NAME | SPECIES NAME | APPROXIMATE NUMBER OF GENES |
| Mustard plant | Arabidopsis thaliana | 27,000 |
| Human | Homo sapiens | 25,000 |
| Nematode worm | Caenorhabditis elegans | 20,000 |
| Fruit fly | Drosophila melanogaster | 14,000 |
| Baker's yeast | Saccharomyces cerevisiae | 6000 |
| Gut bacterium | Escherichia coli | 4000 |
Humans have more genes than fruit flies and nematode worms, but not as many as might be expected on the basis of complexity.
Humans have about 25,000 genes. Surprisingly, the mustard plant Arabidopsis, a common weed and model organism in plant biology, has 27,000, about the same number. Perhaps the most sobering comparison is with the nematode worm Caenorhabditis elegans, another model organism, which has only 959 cells (we have an estimated 100 trillion), of which 302 are nerve cells that form the worm’s brain (our brain has 100 billion nerve cells). Despite having 100 million times as many cells, we have roughly the same number of genes as the worm. How can we account for the disconnect between levels of complexity and gene number?
One hypothesis is that human cells are able to do many more things with the genes they have. A number of mechanisms are likely to be important. The expression of our relatively few genes can be regulated in many subtle ways, causing different gene products to be made in different amounts in different cells at different times (Chapters 19 and 20). This differential gene expression contributes to the large number of different cell types. Human proteins interact with one another so that, even though there are relatively few actual proteins, they are capable of combining in many different ways to perform different functions. And we know that a single gene may yield multiple proteins, either because different exons are spliced together to make different proteins (Chapter 3) or because the proteins undergo biochemical changes after they have been translated.
Overall, the discovery of the relatively low human gene number poses many tantalizing evolutionary questions and suggests that major evolutionary changes can be accomplished not only by the acquisition of whole new genes, but also by modifying existing genes and their regulation in subtle ways.
13.3.2 Viruses, bacteria, and archaeons have small, compact genomes.
As well as comparing numbers of genes, we can also compare sizes of genomes in different organisms. Before making such comparisons, we need to understand how genome size is measured. Genomes are measured in numbers of base pairs, and the yardsticks of genome size are a thousand base pairs (a kilobase, kb), a million base pairs (a megabase, Mb), and a billion base pairs (a gigabase, Gb).
Most viral genomes range in size from 3 kb to 300 kb, but a few are very large. The largest viral genome, found in a virus that infects the amoeba Acanthamoeba polyphaga, is 1.2 Mb. This viral genome contains almost 1000 protein-coding genes, including some for sugar, lipid, and amino acid metabolism not found in any other viruses.
The largest viral genome is twice as large as that of the bacterium Mycoplasma genitalium. At 580 kb and encoding only 471 genes, the genome of M. genitalium is the smallest known among free-living bacteria, those capable of living entirely on their own. The complete sequence of small bacterial genomes has allowed researchers to define the smallest, or minimal, genome (and therefore the minimal set of proteins) necessary to sustain life. Current findings suggest that the small M. genitalium is about two times larger than the minimal genome size thought to be necessary to encode all the functions essential to life.
The genomes of bacteria and archaeons are information dense, meaning that most of the genome has a defined function. Roughly speaking, 90% or more of their genomes consists of protein-coding genes. Bacterial genomes range in size from 0.5 to 10 Mb. The bigger genomes have more genes, allowing these bacteria to synthesize small molecules that other bacteria have to scrounge for, or to use chemical energy in the covalent bonds of substances that other bacteria cannot. Archaeons, whose genomes range in size from 0.5 to 5.7 Mb, have similar capabilities.
13.3.3 Among eukaryotes, there is no relationship between genome size and organismal complexity.
In eukaryotes, just as the number of genes does not correlate well with organismal complexity, the size of the genome is unrelated to the metabolic, developmental, and behavioral complexity of the organism (Table 13.2). The range of genome sizes is huge, even among similar organisms (Fig. 13.8). The largest eukaryotic genome exceeds the size of the smallest by a factor of more than 500,000—and both the smallest and the largest are found among protozoa. The range among flowering plants (angiosperms) is about three orders of magnitude, and the range among animals is about seven orders of magnitude. One species of lungfish has a genome size more than 45 times larger than the human genome (Table 13.2). Clearly, there is no relationship between the size of the genome and the complexity of the organism.
| Table 13.2: Genome Sizes of Several Organisms | ||
|---|---|---|
| COMMON NAME | SPECIES NAME | APPROXIMATE GENOME SIZE (MB) |
| Fruit fly | Drosophila melanogaster | 180 |
| Fugu fish | Fugu rubripes | 400 |
| Boa constrictor | Boa constrictor | 2100 |
| Human | Homo sapiens | 3100 |
| Locust | Schistocerca gregaria | 9300 |
| Onion | Allium cepa | 18,000 |
| Newt | Amphiuma means | 84,000 |
| Lungfish | Protopterus aethiopicus | 140,000 |
| Fern | Ophioglossum petiolatum | 160,000 |
| Amoeba | Amoeba dubia | 670,000 |
Genome size varies tremendously among eukaryotic organisms, and there is no correlation between genome size and the complexity of an organism.
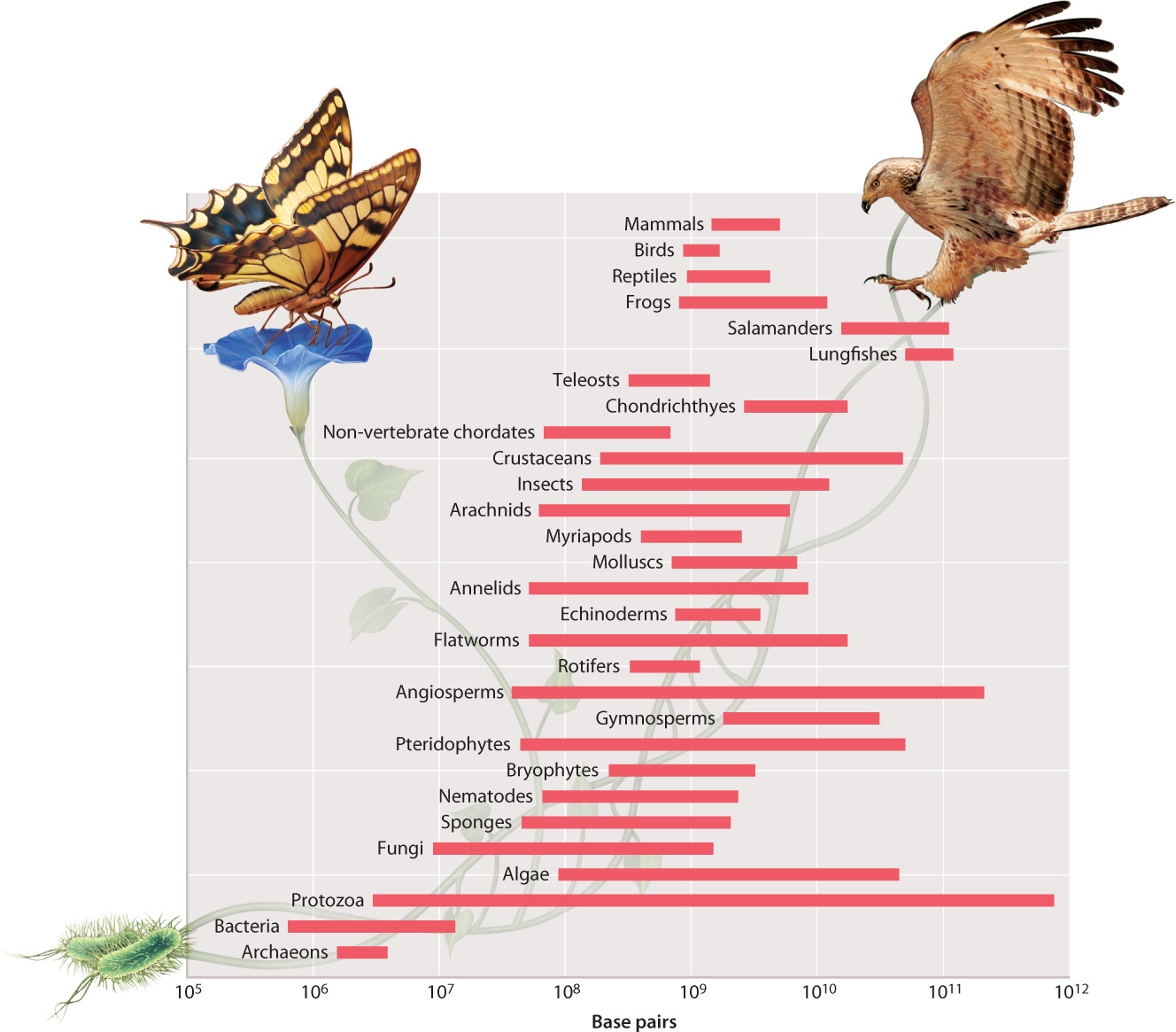
The disconnect between genome size and organismal complexity is called the C-value paradox. The C-value is the amount of DNA in a reproductive cell, and the “paradox” is the apparent contradiction between genome size and organismal complexity, and hence the difficulty of predicting one from the other.
If organismal complexity is not a good predictor of genome size, what is? In eukaryotic organisms, large genomes can differ from small ones for a number of reasons. One reason is polyploidy, or having more than two sets of chromosomes in the genome. Polyploidy is especially prominent in many groups of plants. Humans have two sets of 23 chromosomes, giving us 46 chromosomes in total. But the polyploid bread wheat Triticum aestivum, for example, has six sets of seven chromosomes.
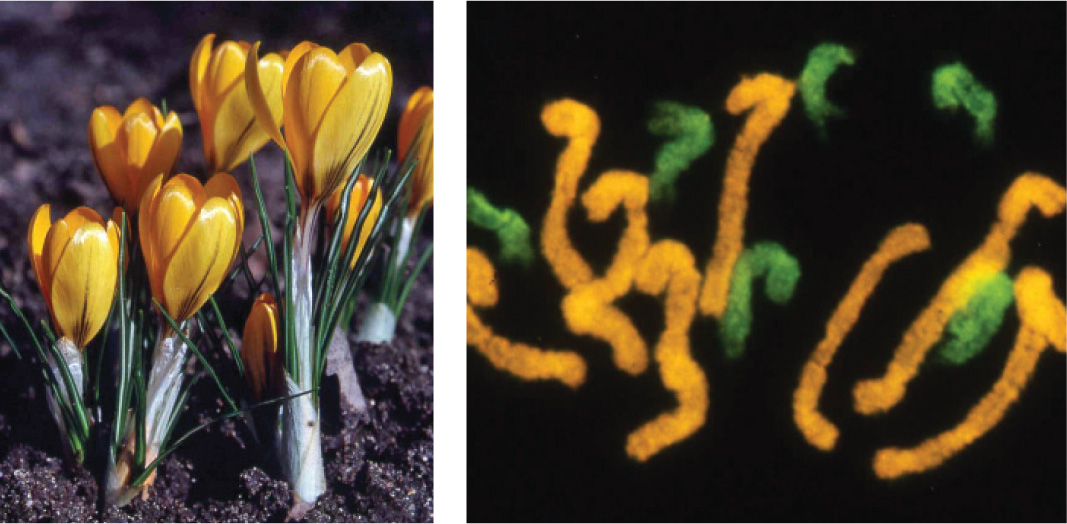
Polyploidy, which is widespread, has played an important role in plant evolution. Many agricultural crops are polyploid, including wheat, potato, olive, banana, sugarcane, and coffee. Among flowering plants, it is estimated that 30% to 80% of existing species have polyploidy in their evolutionary history, either because of the duplication of the complete set of chromosomes in a single species, or because of hybridization, or crossing, between related species followed by duplication of the chromosome sets in the hybrid (Fig. 13.9). Some ferns take polyploidy to an extreme: One species has 84 copies of a set of 15 chromosomes—1260 chromosomes altogether.
Another important reason for large differences in genome size among species is that most eukaryotic genomes contain large amounts of noncoding DNA. Over the course of evolutionary time, the amount of noncoding DNA in a genome can change drastically. In some species, the amount of noncoding DNA vastly increases over time, partly because some sequences within the genome increase and multiply. In other species the amount of noncoding DNA decreases because of deletion and other processes.
Most large eukaryotic genomes contain two main types of noncoding DNA. One type, called highly repetitive DNA, consists of sequences present in more than 100,000 copies per genome. Much of the highly repetitive DNA corresponds to short sequence repeats such as we saw earlier (see Fig. 13.2c). The other main type of noncoding DNA, present in 100–10,000 copies per genome, is called moderately repetitive DNA, and it consists of dispersed repeated sequences (see Fig. 13.2b).
Different species can have vastly different quantities of highly repetitive and moderately repetitive DNA. Since these types of sequence are almost exclusively noncoding DNA, it is the differing amounts of these noncoding sequences among the genomes of different species that in large part accounts for the C-value paradox.
Quick Check 4
Given our knowledge of genome sizes in different organisms, would you predict that humans or amoebas (a single-celled eukaryote) have a larger genome?
13.3.4 About half of the human genome consists of repetitive DNA and transposable elements.
Complete genome sequencing has allowed the different types of noncoding DNA to be specified more precisely in a variety of organisms. It came as a great surprise to learn that in the human genome only about 2.5% of the genome actually codes for proteins. The other 97.5% includes sequences we have encountered earlier, including sequences that specify noncoding RNA, repetitive DNA, and noncoding regions of genes, such as introns.
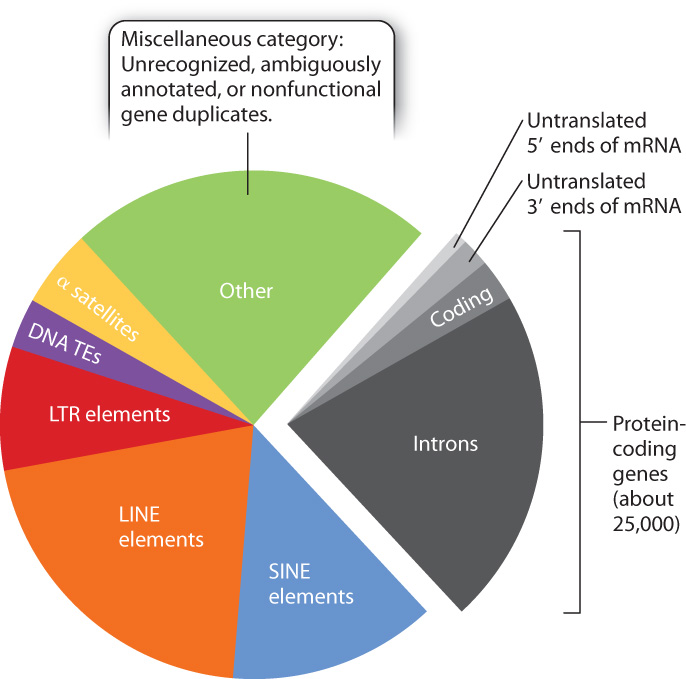
In Fig. 13.10, we see the principal repetitive sequences in the human genome. Among the highly repetitive sequences is α (alpha) satellite DNA, which consists of tandem copies of a 171-bp sequence repeated near each centromere an average of 18,000 times. The α satellite DNA is essential for attachment of spindle fibers to the centromeres during cell division (Chapter 11).
Fig. 13.10 also shows the proportions of several types of sequence collectively known as transposable elements, which are DNA sequences that can replicate and insert themselves into new positions in the genome. As a result, they have the potential to increase their copy number in the genome over time. Transposable elements are sometimes referred to as “selfish” DNA because it seems that their only function is to duplicate themselves and proliferate in the genome, making them the ultimate parasite.
Transposable elements make up about 45% of the DNA in the human genome. They can be classified into two groups based on the way they replicate. One class consists of DNA transposable elements (DNA TEs), which replicate and transpose via DNA replication and repair. The other class consists of elements that transpose by means of an RNA intermediate. Among these are LTR elements, which are characterized by long repeated sequences, called long terminal repeats (LTRs), at their ends. Also in this class are two types that are distinguished by their length: the LINEs (long interspersed nuclear elements), of about 1000 base pairs, and the SINEs (short interspersed nuclear elements), with about 300 base pairs.