13.5 VIRUSES AND VIRAL GENOMES
The first genome sequenced was not the human genome, nor did it come from any of the three domains of life—Bacteria, Archaea, or Eukarya. It was a viral genome. As we discussed, viral genomes are small and compact, so they are easier to sequence than the larger genomes of cellular organisms.
We mostly think of viruses as causing disease, and indeed they do. Familiar examples include influenza (“flu”), polio, and HIV. In some cases, they cause cancer (Case 2: Cancer). In fact, the term “virus” comes from the Latin for “poison.” But viruses play other roles as well. Some viruses transfer genetic material from one cell to another. This process is called horizontal gene transfer to distinguish it from parent-to-offspring (vertical) gene transfer. Horizontal gene transfer has played a major role in the evolution of bacterial and archaeal genomes, as well as in the origin and spread of antibiotic-resistance genes (Chapter 26). Molecular biologists have learned to make use of this ability of viruses to deliver genes into cells. Viruses also play vital roles in ecosystems: Scientists estimate that 1 to 100 million viruses can be found in a teaspoon of seawater. They are not only abundant, but also have important functions, infecting and limiting the number of bacteria and other microorganisms in soil and water.
In this section, we focus on viral diversity with an emphasis on viral genomes. Thousands of viruses have been described in detail, and probably millions more have yet to be discovered.
13.5.1 The host range of a virus is determined by viral and host surface proteins.
Recall that a virus consists simply of nucleic acid, a protein coat called a capsid, and sometimes a lipid envelope (Chapter 1). Viruses can reproduce only by infecting living cells and subverting cellular metabolism and protein synthesis to produce more viruses. Most viruses are tiny, some hardly larger than a eukaryotic ribosome, 25–30 nm in diameter. Roughly speaking, the average size of a virus, relative to that of the host cell it infects, may be compared to the size of an average person relative to that of a commercial airliner.
All known cells and organisms are susceptible to viral infection, including bacteria, archaeons, and eukaryotes. A cell in which viral reproduction occurs is called a host cell. Some viruses kill the host cell; others do not. Although viruses can infect all types of living organism, a given virus can infect only certain species or types of cell. At one extreme, a virus can infect just a single species. Smallpox, which infects only humans, is a good example. In this case, we say that the virus has a narrow host range. For other viruses, the host range can be broad. For example, rabies infects many different types of mammal, including squirrels, dogs, and humans. Similarly, tobacco mosaic virus, a plant virus, infects more than 100 different species of plants (Fig. 13.16). No matter how broad the host range, however, plant viruses cannot infect bacteria or animals, for example, and viruses that infect bacteria cannot infect plants or animals.

Host specificity relates to the way that viruses gain entry into cells. Proteins on the surface of the capsid or envelope (if present) bind to proteins on the surface of host cells. These proteins interact in a specific manner, so the presence of the host protein on the cell surface determines which host cells a virus can infect. For example, a protein on the surface of the HIV envelope called gp120 (encoded by the env gene; see Fig. 13.7) binds to a protein called CD4 on the surface of certain immune cells (Chapter 43), so HIV infects these cells but not other human cells.
Following attachment, the virus gains entry into the cell, where it can replicate by using the host cell machinery to make new viruses. In some cases, the viral genome integrates into the host cell genome (Chapter 19).
The host range of a virus can change because of mutation and other mechanisms (Chapter 43). For example, avian, or bird, flu is a type of influenza virus that was once restricted primarily to birds but now can infect humans. The first reported case in humans was in 1996, and the disease has since spread widely. Similarly, HIV once infected nonhuman primates, but its host range expanded in the twentieth century to include humans. Canine distemper virus, which infects dogs, expanded its host range in the early 1990s, leading to infection and death of lions in Tanzania.
13.5.2 Viruses can be classified by their genomes.
The genomes of viruses are diverse. Some genomes are composed of RNA and others of DNA. Some are single stranded, others are double stranded, and still others have both single- and doublestranded regions. Some are circular and others are made up of a single piece or multiple linear pieces of DNA (called linear and segmented genomes, respectively).
Unlike forms of cellular life, there is no evidence that all viruses share a single common ancestor. Different types of virus may have evolved independently more than once. Since classification of viruses based on evolutionary relatedness is not possible, other criteria are necessary. One of the most useful classifications is based on the type of nucleic acid the virus contains and how the messenger RNA, which produces viral proteins, is synthesized (Fig. 13.17). The classification is called the Baltimore system after David Baltimore, who shared the Nobel Prize in Physiology or Medicine in 1975 for the discovery of the enzyme reverse transcriptase.
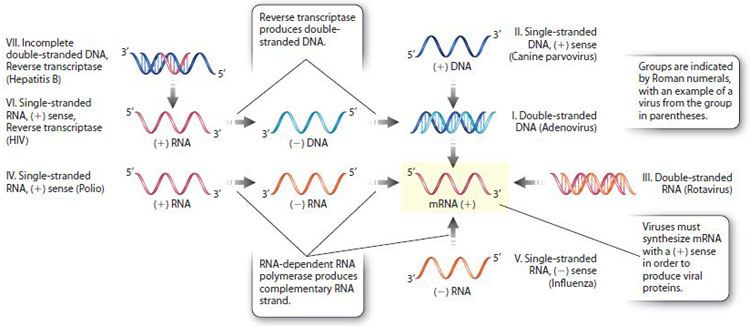
According to the Baltimore system, there are seven major groups of viruses, designated I–VII, as shown in Fig. 13.17. These groups are largely based on whether their nucleic acid is double-stranded DNA, double-stranded RNA, partially doublestranded and partially single-stranded, or single-stranded RNA or DNA with a positive (+) or negative (–) sense. The sense of a nucleic acid molecule is positive if its sequence is the same as the sequence of the mRNA that is used for protein synthesis, and negative if it is the complementary sequence. For example, a (+)RNA strand has the same nucleotide sequence as the mRNA, whereas a (–)RNA strand has the complementary sequence. Similarly, a (+)DNA strand has the same sequence as the mRNA, and a (–)DNA strand has the complementary sequence (except that U in RNA is replaced with T in DNA). Because mRNA is synthesized from a DNA template, it is the (–)DNA strand that is used for mRNA synthesis (Chapter 3).
Two groups synthesize mRNA by the enzyme reverse transcriptase, and therefore are placed into their own groups (VI and VII). Reverse transcriptase synthesizes DNA from an RNA template (Fig. 13.17), and therefore reverses the usual flow of genetic information from DNA to RNA (see Fig. 4.20).
As we saw earlier, genome size varies greatly among different viruses. RNA viral genomes tend to be smaller than DNA viral genomes. Most eukaryotic viruses that have RNA genomes of one type or another, and most plant viruses including tobacco mosaic virus are in group IV. Among bacterial and archaeal viruses, most genomes consist of double-stranded DNA.
13.5.3 Viruses have diverse sizes and shapes.
Viruses show a wide variety of shapes and sizes. Three examples are shown in Fig. 13.18. The T4 virus (Fig. 13.18a) infects cells of the bacterium Escherichia coli. Viruses that infect bacterial cells are often called bacteriophages, which literally means “bacteria eaters.” The T4 bacteriophage has a complex structure that includes a head composed of protein surrounding a molecule of double-stranded DNA, a tail, and tail fibers. In infecting a host cell, the T4 tail fibers attach to the surface, and the DNA and some proteins are injected into the cell through the tail.

Most viruses are not structurally so complex. Consider the tobacco mosaic virus, which infects plants (see Fig. 13.16). It has a helical shape formed by the arrangement of protein subunits entwined with a molecule of single-stranded RNA (Fig. 13.18b). Tobacco mosaic virus was the first virus to be discovered, revealed in experiments showing that the infectious agent causing brown spots and discoloration of tobacco leaves was so small that it could pass through the pores of filters that could trap even the smallest bacterial cells.
Many viruses have an approximately spherical shape formed from polygons of protein subunits that come together at their edges to form a polyhedral capsid. Among the most common polyhedral shapes is an icosahedron, which has 20 identical triangular faces. The example in Fig. 13.18c is adenovirus, a common cause of upper respiratory infections in humans. Many viruses that infect eukaryotic cells, such as adenovirus, are surrounded by a glycoprotein envelope composed of a lipid bilayer with embedded proteins and glycoproteins that recognize and attach to host cell receptors.
13.5.4 Viruses are capable of self-assembly.
The nucleic acid contained in a virus particle contains the genetic information needed to specify all the structural components of the virus. Progeny particles are formed according to a principle of molecular self-assembly: When the viral components are present in the proper relative amounts and under the right conditions, the components interact spontaneously to assemble themselves into the mature virus particle.
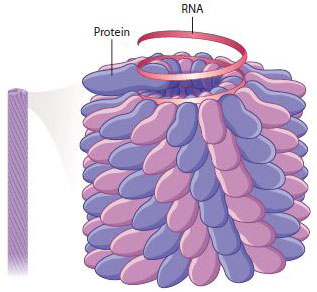
Tobacco mosaic virus illustrates the process of self-assembly. In the earliest stages, the coat-protein monomers assemble into two circular layers forming a cylindrical disk. This disk binds with the RNA, and the combined structure forms the substrate for polymerization of all the other protein monomers into a helical filament that incorporates the rest of the RNA as the filament grows (Fig. 13.19). The mature virus particle consists of 2130 protein monomers and 1 single-stranded RNA molecule of 6400 ribonucleotides.