14.2 SMALL-SCALE MUTATIONS
At the molecular level, a mutation is a change in the nucleotide sequence of a genome. Such changes can be small, affecting one or a few bases, or large, affecting entire chromosomes. We begin by considering the origin and effects of small-scale changes to the DNA sequence. While mutation provides the raw material that allows evolution to take place, it can play this role only because of an important feature of living systems: Once a mutation has taken place in a gene, the mutant genome is replicated as faithfully as the nonmutant genome.
14.2.1 Point mutations are changes in a single nucleotide.
Most DNA damage or errors in replication are immediately removed or corrected by specialized enzymes in the cell. (Some examples of DNA repair will be discussed in section 14.4.) We have already seen one example of DNA repair, the proofreading function of DNA polymerase, which acts to remove an incorrect nucleotide from the 3 end of growing DNA strand (see Fig. 12.7). Damage that is corrected is not regarded as a mutation because the DNA sequence is immediately restored to its original state.
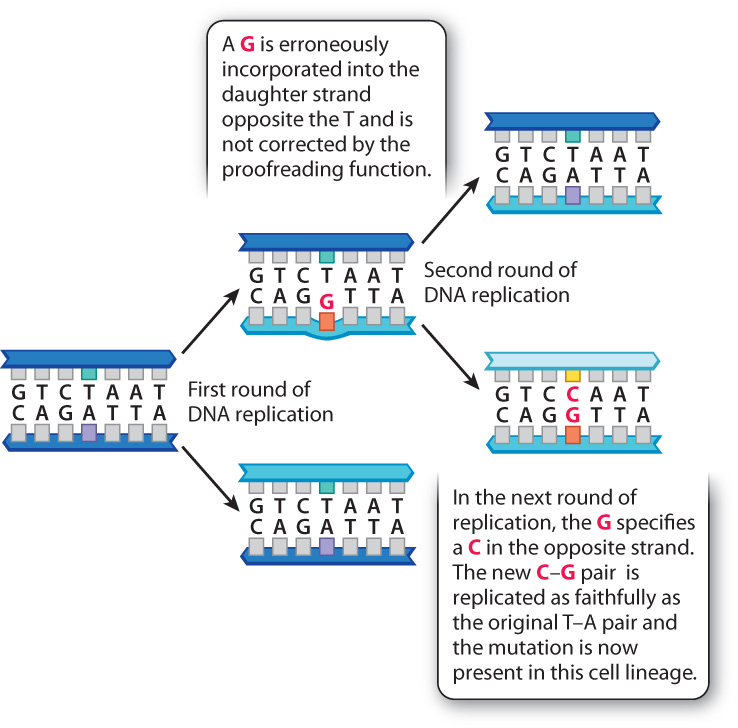
If a change in DNA is to become stable and subsequently inherited through mitotic or meiotic cell divisions, it must escape correction by the DNA repair systems. The example in Fig. 14.6 shows how a mutation incorporated during replication can become a permanent change to the genome. The figure shows the replication of a DNA molecule in which a T–A base pair temporarily becomes a mismatched T–G base pair because DNA polymerase misincorporates a G into the daughter strand opposite the T in the template strand. Ordinarily, this G would be removed immediately after incorporation by the proofreading function of DNA polymerase and replaced with an A. In this example, we assume that the proofreading function failed to catch the mistake. This leaves the T–G mismatch in the double-stranded DNA, and at the next replication the G in the new template strand specifies a C in the daughter strand, with the result that the daughter DNA duplex has a perfectly matched C–G base pair. From this point forward, the DNA molecule containing the mutant C–G base pair will replicate as faithfully as the original molecule bearing the nonmutant T–A base pair. A mutation in which one base pair (in this example, T–A) is replaced by a different base pair (in this example, C–G) is called a nucleotide substitution or point mutation. This is the most frequent type of mutation.
The effect of a point mutation depends in part on where in the genome it occurs. In many multicellular eukaryotes, including humans, the vast majority of DNA in the genome does not code for protein or RNA (Chapter 13). Most of the sequences in noncoding DNA have no known function, which may explain why many mutations in noncoding DNA have no detectable effects on the organism.
On the other hand, mutations in coding sequences do have predictable consequences in an organism. Fig. 14.7 shows an example in the human DNA sequence coding for the amino acid chain of β-(beta-) globin, a subunit of the protein hemoglobin, which carries oxygen in red blood cells. Fig. 14.7a shows a small part of the nonmutant DNA sequence, transcription and translation of which results in incorporation of the amino acids Pro–Glu–Glu in the β-globin polypeptide.
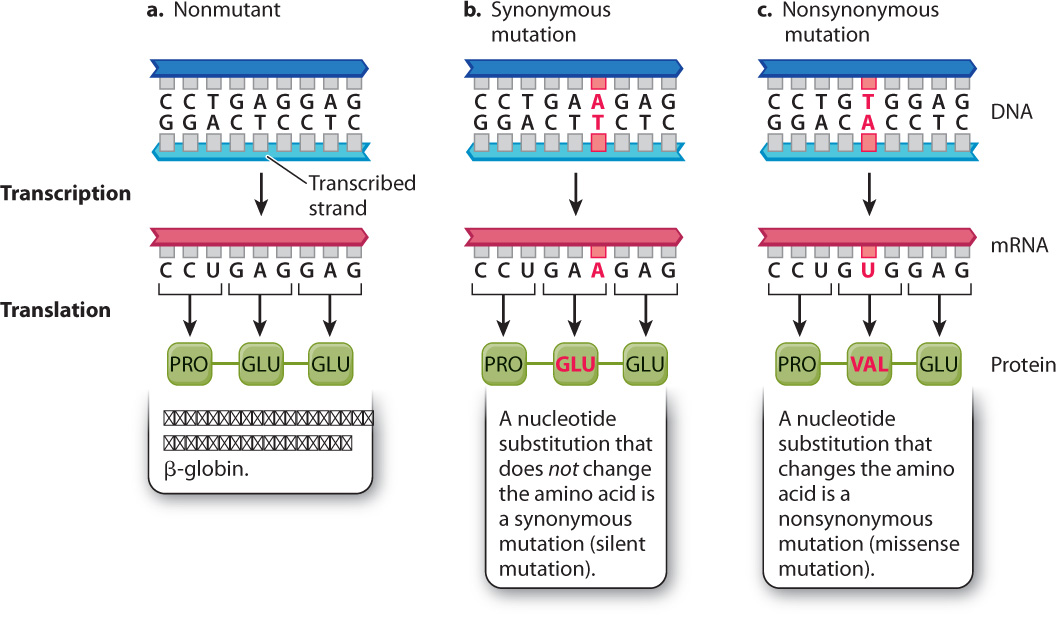
Fig. 14.7b shows an example of a harmless nucleotide substitution in this coding sequence. The mutation consists of the substitution of an A–T base pair for the normal G–C base pair. In the mRNA, the mutation changes the normal GAG codon into the mutant GAA codon. But GAG and GAA both code for the same amino acid, glutamic acid (Glu). In other words, they are synonymous codons, and so the resulting amino acid sequences are the same: Pro–Glu–Glu. Such mutations are called synonymous (silent) mutations. This example is typical in that the synonymous codons differ at their third position (the 3 end of the codon). A quick look at the genetic code (see Table 4.1) shows that most amino acids can be specified by synonymous codons, and that in most cases the synonymous codons differ in the identity of the nucleotide at the third position.
On the other hand, a point mutation in coding sequences can sometimes have a drastic effect on an organism. Fig. 14.7c shows such an example. In this case, a point mutation substitutes the first A–T base pair for a T–A base pair. The result is a change in the mRNA from GAG, which specifies Glu (glutamic acid), into GUG, which specifies Val (valine). The resulting protein therefore contains the amino acids Pro–Val–Glu instead of Pro–Glu–Glu. In other words, the nucleotide substitution results in an amino acid replacement. Point mutations that cause amino acid replacements are called nonsynonymous (missense) mutations.
Since the complete β-globin chain consists of 146 amino acids, it may seem that a change in only one amino acid would have little effect. But the change in even a single amino acid can affect the three-dimensional structure of a protein, and therefore change its ability to function. Individuals who inherit two copies of the mutant β-globin gene that specifies the Glu-to-Val replacement have a disease known as sickle-cell anemia. In this condition, the hemoglobin molecules tend to crystallize when exposed to lower-than-normal levels of oxygen. The crystallization of hemoglobin causes the cell to collapse from its normal ellipsoidal shape into the shape of a half-moon, or “sickle.” In this form, the red blood cell is unable to carry the normal amount of oxygen. More important, the sickled cells tend to block tiny capillary vessels, interrupting the blood supply to vital tissues and organs.
Children with sickle-cell anemia tire easily, may be slow in their physical development, and tend to be susceptible to infections as a result of their general weakened condition brought on by the reduced amount of normal hemoglobin. Occasionally, those affected experience sickle-cell crises marked by fever and severe, incapacitating pains in the joints, particularly in the extremities, and in the chest, back, and abdomen. The pains are caused by the clogging of the blood supply to these vital areas. The painful episodes may last from hours to days to weeks and may be provoked by anything that lowers the oxygen supply: overexertion, high altitude, or respiratory ailments.
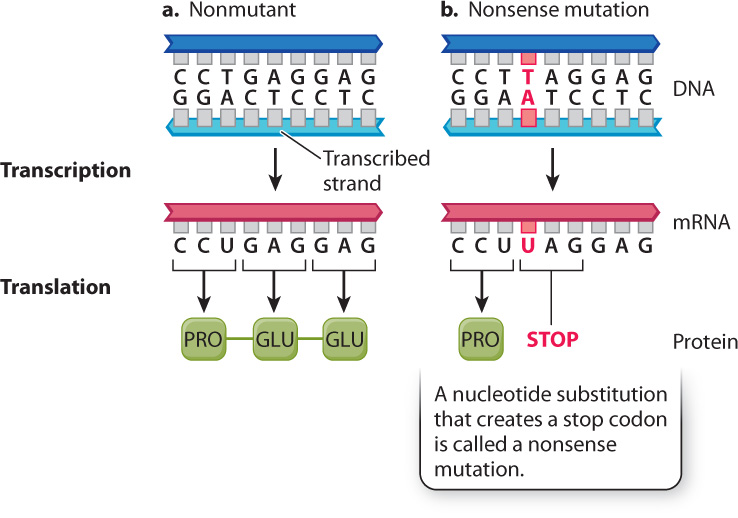
Fig. 14.8 shows a third way that a point mutation can affect a protein, one that nearly always has severe effects. This is a nonsense mutation, which creates a stop codon that terminates translation. In the example in Fig. 14.8, the mutation creates a UAG codon in the mRNA. Because UAG is a translational stop codon, the resulting polypeptide terminates after Pro. Polypeptides that are truncated are nearly always nonfunctional. They are also unstable and are quickly destroyed. Eukaryotic cells have mechanisms to destroy mRNA molecules that contain premature stop codons.
14.2.2 Small insertions and deletions involve several nucleotides.
Another relatively common type of mutation is the deletion or insertion of a small number of nucleotides. In noncoding DNA, such mutations have little or no effect. In protein-coding regions, their effects depend on their size. A small deletion or insertion that is an exact multiple of three nucleotides results in a polypeptide with as many fewer (in the case of a deletion) or more (in the case of an insertion) amino acids as there are codons deleted or inserted. Thus, a deletion of three nucleotides eliminates one amino acid, and an insertion of six adds two amino acids.
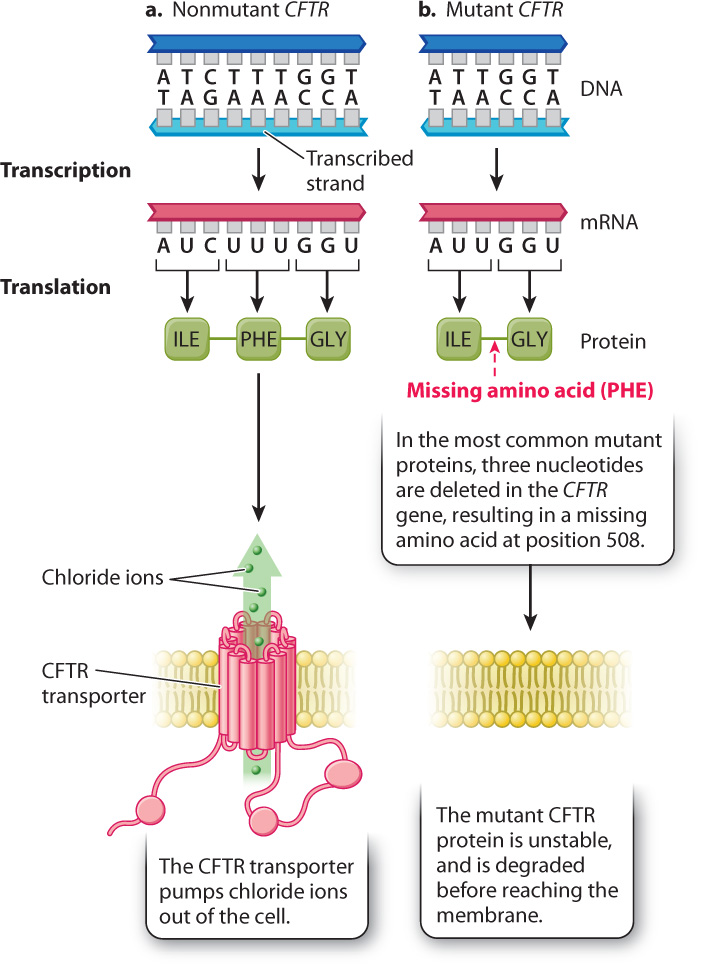
The effects of a deletion of three nucleotides can be seen in cystic fibrosis. This disease is characterized by the production of abnormal secretions in the lungs, liver, and pancreas and other glands. Its chief symptoms are recurrent respiratory infections, malnutrition resulting from incomplete digestion and absorption of fats and proteins, and liver disease. Patients with cystic fibrosis have an accumulation of thick, sticky mucus in their lungs, which often leads to respiratory complications, including recurrent bacterial infections. Untreated, 95% of affected children die before age 5. With proper medical care, including regular physical therapy to clear the lungs, antibiotics, pancreatic enzyme supplements, and good nutrition, the average life expectancy is currently 30 to 40 years.
The mutations responsible for cystic fibrosis are in the gene encoding the cystic fibrosis transmembrane conductance regulator (CFTR) (Fig. 14.9). The CFTR protein is a chloride channel, which acts as a transporter to pump chloride ions out of the cell. Malfunction of CFTR causes ion imbalances that result in abnormal secretions from the many cell types in which the CFTR gene is expressed. About 70% of the mutations associated with cystic fibrosis have a specific mutation known as Δ508 (delta 508), which is a deletion of three nucleotides that eliminates a phenylalanine normally present at position 508 in the protein. The missing amino acid results in a CFTR protein that does not fold properly and is degraded before reaching the membrane. Some researchers hope that future therapy will include drugs that stabilize the mutant protein or even treatments that repair the defective gene in affected cells.
Small deletions or insertions that are not exact multiples of 3 can cause changes in amino acid sequence because they do not insert or delete entire codons. The effect of such a mutation can be appreciated by seeing how deletion of a single letter turns a perfectly sensible sentence of three-letter words into gibberish. Consider the sentence:
THE BIG BOY SAW THE CAT EAT THE BUG
If the red E is deleted, the new reading frame for three-letter words is as follows:
THB IGB OYS AWT HEC ATE ATT HEB UG
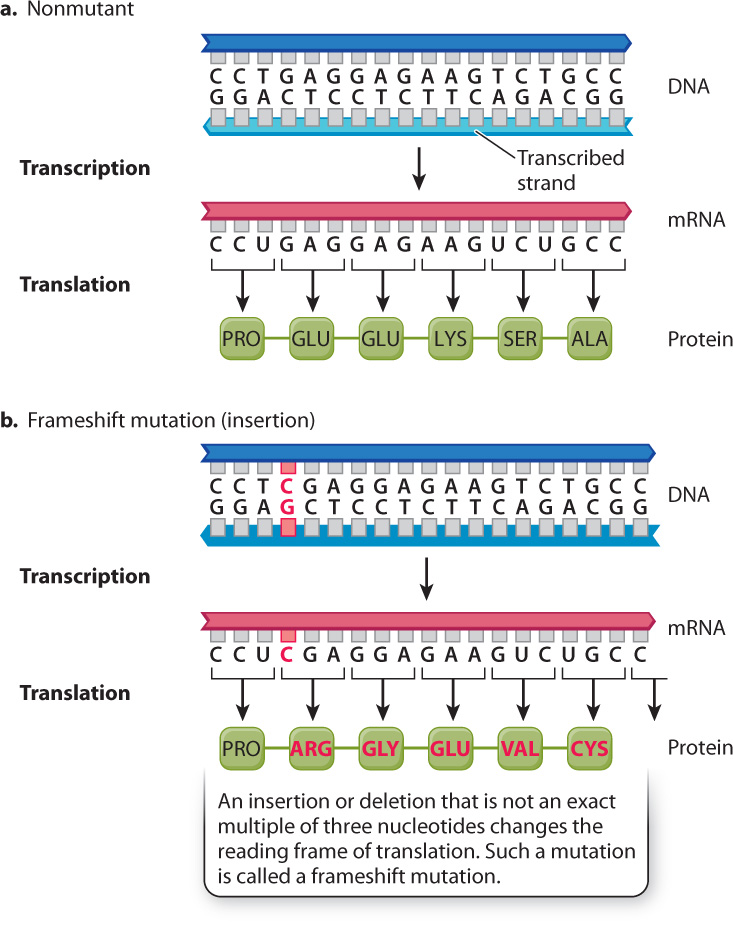
The result is unintelligible. Similarly, an insertion of a single nucleotide causes a one-nucleotide shift in the reading frame of the mRNA, and it changes all codons following the site of insertion. For this reason, such mutations are called frameshift mutations.
Fig. 14.10 shows the consequences of a frameshift mutation in the β-globin gene. The normal sequence in Fig. 14.10a corresponds to amino acids 5–10. The frameshift mutation in Fig. 14.10b is caused by the insertion of a C–G base pair. The mRNA transcript of the DNA therefore also has a single-base insertion. When this mRNA is translated, the one-nucleotide shift in the reading frame results in an amino acid sequence that has no resemblance to the original protein. All amino acids downstream of the site of insertion are changed, resulting in loss of protein function.
Quick Check 2
The coding sequence of genes that specify proteins with the same function in related species sometimes include an insertion or deletion of contiguous nucleotides. The number of nucleotides that are inserted or deleted is almost always an exact multiple of 3. Why is this expected?
14.2.3 Some mutations are due to the insertion of a transposable element.
An important source of new mutations in many organisms is the insertion of movable DNA sequences into or near a gene. Such movable DNA sequences are called transposable elements. As we saw in Chapter 13, the genomes of virtually all organisms contain several types of transposable element, each present in multiple copies per genome.
Transposable elements were discovered by American geneticist Barbara McClintock in the 1940s (Fig. 14.11). She studied corn (maize) because genetic changes that affect pigment formation can be observed directly in the kernels. The normal color of maize kernels is purple. Each kernel consists of many cells, and if no mutations affecting pigmentation occur in a kernel, it will be uniformly purple. The kernel pigments are synthesized by enzymes in a metabolic pathway, and any of these enzymes can be rendered nonfunctional if a transposable element jumps into the gene that codes for them. Since her work, we have learned that most transposable elements are segments of DNA a thousand or more base pairs long. When such a large piece of DNA inserts into a gene, it can interfere with transcription, cause errors in RNA processing, or disrupt the open reading frame. The result in the case of maize is that the cell is unable to produce pigment, and so the kernels will be yellow.
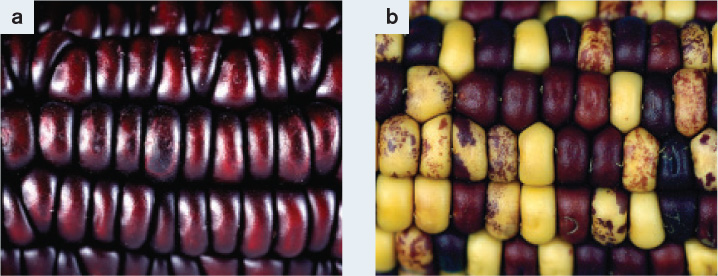
FIG. 14.11What causes sectoring in corn kernels?
BACKGROUND In the late 1940s, Barbara McClintock discovered what are now called transposable elements, DNA sequences that can move from one position to another in the genome. She studied corn (Zea mays). Wild-type corn has purple kernels, resulting from expression of purple anthocyanin pigment (Fig. 14.11a). A mutant with yellow kernels results from lack of purple anthocyanin pigment. McClintock noticed that streaks of purple pigmentation could be seen in many yellow kernels (Fig. 14.11b). This observation indicated that the mutation causing yellow color was unstable and could revert to the normal purple color.
HYPOTHESIS McClintock hypothesized that the yellow mutant color resulted from a transposable element, which she called Dissociator (Ds), jumping into a site near or in the anthocyanin gene and disrupting its function. She attributed the purple streaks to cell lineages in which the transposable element had jumped out again, restoring the anthocyanin gene.
EXPERIMENT AND RESULTS By a series of genetic crosses, McClintock showed that the genetic instability of Ds was due to something on another chromosome that she called Activator (Ac). She set up crosses in which she could track the Ac-bearing chromosome. She observed that in the presence of Ac, mutant yellow kernels reverted to normal purple, resulting in purple sectors in an otherwise yellow kernel. From this observation, she inferred that the Ds element had jumped out of the anthocyanin gene, restoring its function. She also demonstrated that restoration of the original purple color was associated with mutations elsewhere in the genome. From this observation, she inferred that the Ds element had integrated elsewhere in the genome, where it disrupted the function of another gene.
CONCLUSION McClintock’s conclusion is illustrated in Fig. 14.11c: Transposable elements can be excised from their original position in the genome and inserted into another position.
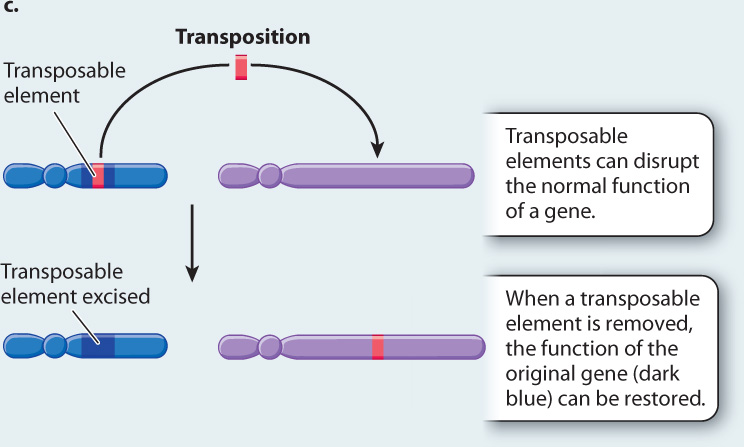
FOLLOW-UP WORK McClintock won the Nobel Prize in Physiology or Medicine in 1983. Later experiments showed that Ds is a transposable element that lacks a functional gene for transposase, the protein needed for the element to move, and Ac is a transposable element that encodes transposase. Presence of Ac produces active transposase that allows Ds to move. Much additional work showed that there are many different types of transposable element and that they are ubiquitous among organisms.
SOURCE McClintock, B. 1950. “The Origin and Behavior of Mutable Loci in Maize.” Proceedings of the National Academy of Sciences of the United States of America. 36:344–355.
McClintock observed that, while the kernels in the mutant corn were mostly yellow, most of them had purple sectors. Each colored sector consists of a lineage of progeny cells from a single progenitor cell in which pigment synthesis had been restored. McClintock realized that, just as the inability of the kernel cells to produce pigment was caused by a transposable element jumping into a gene, restoration of that ability could be caused by the transposable element jumping out again. Her hypothesis that transposable elements are responsible for the pigment mutations was confirmed when she found that in cells where pigment had been restored, mutations affecting other genes had also occurred. She deduced that these other mutations were due to a transposable element jumping out of a pigment gene and into a different gene in the same cell.
The movement or transposition of transposable elements, including those McClintock studied, requires specialized enzymes, different for each type of element, which are often encoded in the sequence of the element itself. These enzymes recognize specific sequences in the ends of the transposable element, cut it out of the DNA molecule it is in, and insert it somewhere else in the genome. In some cases, the excised transposable element leaves a copy of itself in its original position, resulting in multiple identical sequences throughout the genome as the transposable element jumps around. In other cases, the transposable element is removed entirely, leading to restoration of gene function, and the sectoring shown in Fig. 14.11b. Unstable mutations due to transposable elements can occur in almost any organism, including the Japanese morning glory, whose sectored flowers are shown in Fig. 14.3.