Chapter 2. Analyzing Enzymes and Enzyme Kinetics III
Learning Objectives
LEARNING OBJECTIVES
General Purpose
Conceptual
- Gain experience presenting the results and conclusions of an experiment to other individuals.
Now that you have completed the data collection for your experiment involving the impact of your chosen treatment on the rate of catechol oxidase, you need to analyze your data. What does it mean for your data to be accurate or precise? Although the words accuracy and precision are often used as though they are synonymous, they are not. Accuracy refers to the closeness of a measured or calculated value to its “true” value. A solution with a known concentration of benzoquinone will have a single, exact absorbance. If your absorbance reading was near this value, it was very accurate. An accurate reading can be the result of good experimental technique or it could be the result of random chance. You could have measured the wrong amount of the reaction solution, but then also read the spectrophotometer incorrectly, with these two errors canceling each other out and therefore producing a very accurate reading. Precision is the closeness of repeated measurements to one another. Precise measurements are not necessarily accurate, but in general a series of very precise measurements will also be very accurate because it is less likely for random events to occur in exactly the same way multiple times. This is partially the reason experiments are usually repeated many times. It allows the investigator to obtain a precise estimate of the “true” value.
Data from replicates does present a problem for an investigator because it is rare for data to have such great precision that all of the values for a single type of treatment are exactly the same. This may simply be due to factors that either were not controlled or factors that could not be controlled. So if the values for the data vary (even just a small amount), which one is the “true” value? In a real investigation there is likely no way to know what value is the true value and there is no “right” answer. Instead, the experimental results have to be analyzed statistically. This will provide a method for exactly describing the numerical results. It will also provide a way to compare the results of different treatments to determine if the treatments have any meaningful effect on the reaction.
Another aspect of the post-experiment phase of the investigation is determining the best way to present the results so that conclusions can be reached in an easy and direct manner. The choices involved in the data presentation include:
- how the data should be presented (table, figure, both)
- where tables are used, is it clearer to use multiple tables or combine information into a single table?
- is a table that summarizes the results needed or helpful?
- are graphs combining different treatments better for comparison than many separate graphs?
Using a spreadsheet program like Microsoft Excel can be a valuable tool for the organization and presentation of experimental results. These same programs can also be used for creating graphs of your results.
Use an Excel spreadsheet to organize your raw data from your experiment.
In Excel, columns are named as A, B, C… etc. and rows are named as 1, 2, 3… etc. We can use the same naming convention for referring to a particular cell. Take, for example, a hypothetical set of data for the enzyme reaction run at pH 3. For a set of 3 replicates of this experiment the data in an Excel spreadsheet might be arranged to look like this:
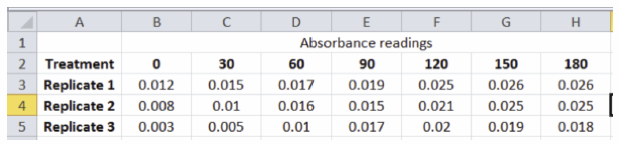
The absorbance value of Treatment 1-time 0 is in cell B3, which means “B” is the column and “3” is the row.
An alternative arrangement of the same data would be:
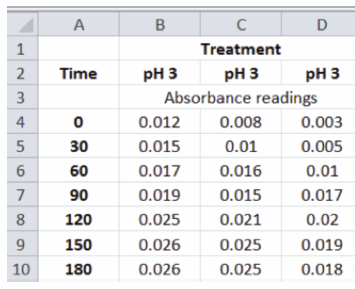
Either of these arrangements (or others) can present the data in a table that is easy to use. Once you have the data organized in a spreadsheet, then you can use this arrangement to easily and accurately make calculations based on the data. In the post-lab portion of part II of this lab series you used a graph or the resulting equation of the best-fit line for a standard curve to determine the concentration of benzoquinone that correlated with the absorbance readings you made during that laboratory. There are two potential drawbacks to the method you used: it’s laborious and it can result in mistakes (either in reading the graph or in making the calculations). The same information can be generated using the spreadsheet. In the spreadsheet adjacent to the absorbance values set up a table for concentrations:
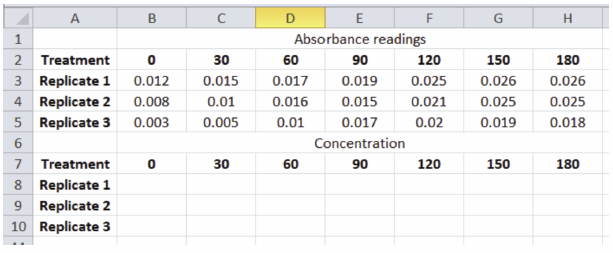
The formula that relates absorbance to concentration of benzoquinone was shown in the post-lab portion of part II of this lab series as (Absorbance − 0.0014)/1.0905 = mMolar concentration. This formula can be used in the spreadsheet to calculate the concentrations. For example, in cell B8 of the spreadsheet shown, the equation +(B3 − .0014)/1.0905 can be entered and the value 0.00972 will appear. That is the mMolar concentration of benzoquinone (the product) that is present at time 0 in the reaction.
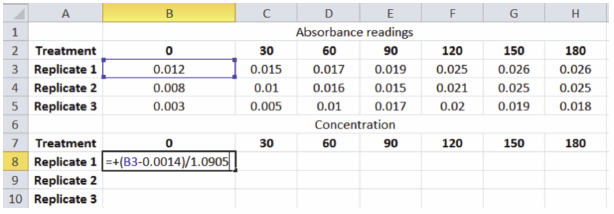
That equation could be reentered for every cell in the concentration portion of the spreadsheet, changing only the reference to the correct cell in the absorbance portion of the spreadsheet. The easier way would be to copy (Ctrl + c) cell B8 and paste (Ctrl + v) it to the remaining cells in the concentration portion of the spreadsheet. Since the absorbance portion of the spreadsheet and concentration portion are laid out the same, the relative positions will allow the correct cell in the absorbance portion of the spreadsheet to be used in each formula of each cell in the concentration portion of the spreadsheet. Very quickly this allows all the concentrations to be calculated correctly (assuming the correct formula is used for the first concentration cell) and the spreadsheet to look like the example below.
For a presentation of the data in the form of a graph you could present three separate graphs:

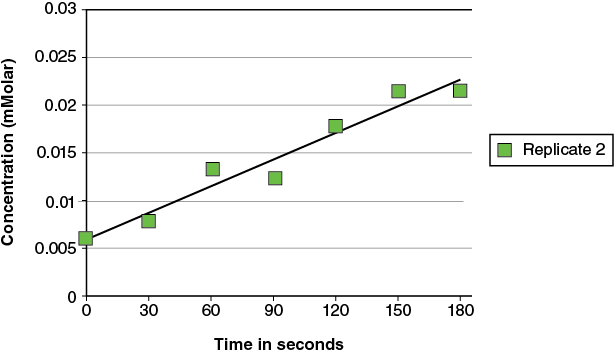

However, that type of presentation makes the direct comparison of the replicates more difficult. An alternative is to place all the replicates on the same graph:
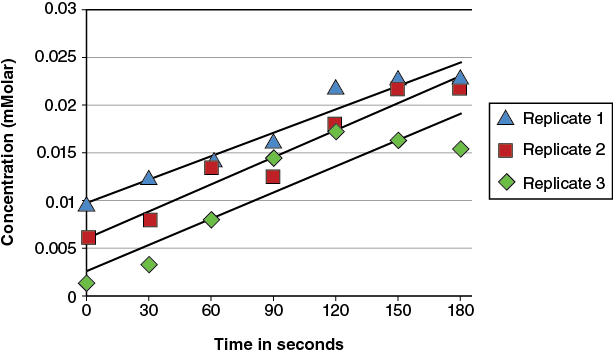
This creates an overly cluttered graph. To get the best graphic representation of the results a statistical averaging of the data will be used. This will be discussed in the next pre-lab section.
Lastly, but perhaps most importantly, how the results of the experiment relate to the original hypotheses and predictions must be addressed. Did your experiment allow you to accept one of your hypotheses and reject the other? Were the predictions you made correct, and if there were problems that occurred that prevented you from reaching a conclusion, can those problems be identified and dealt with if the experiment is to be repeated?
Pre-Lab Quiz
Proceed to the Pre-Lab Quiz