Overview: DNA as transcription template
Figure 8-3: Opposite DNA strands can serve as template for RNA
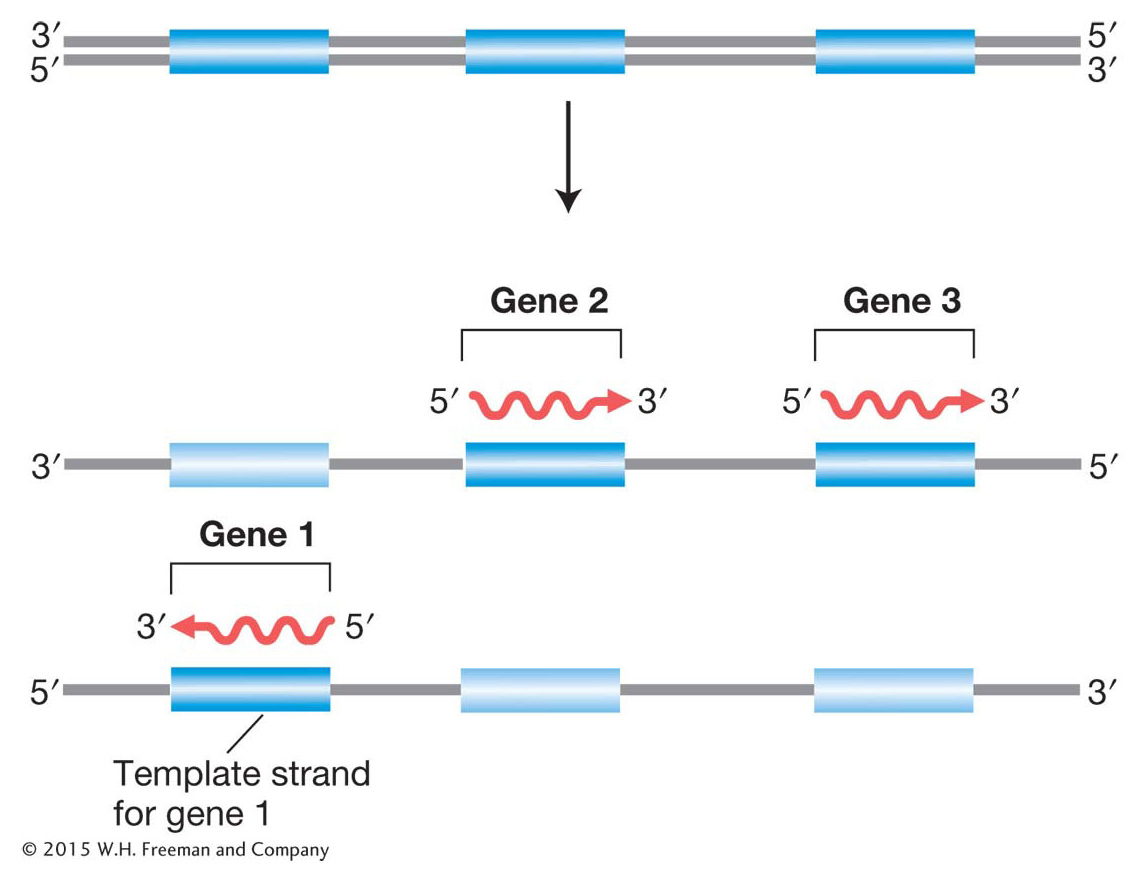
Figure 8-3: Only one strand of DNA is the template for gene transcription, but which strand varies with the gene? The direction of transcription is always the same for any gene and starts from the 3′ end of the DNA template and the 5′ end of the RNA transcript. Hence, genes transcribed in different directions use opposite strands of the DNA as templates.
How is the information encoded in the DNA molecule transferred to the RNA transcript? Transcription relies on the complementary pairing of bases. Consider the transcription of a chromosomal segment that constitutes a gene. First, the two strands of the DNA double helix separate locally, and one of the separated strands acts as a template for RNA synthesis. In the chromosome overall, both DNA strands are used as templates, but, in any one gene, only one strand is used, and, in that gene, it is always the same strand, starting at the 3′ end of the template gene (Figure 8-3). Next, ribonucleotides that have been chemically synthesized elsewhere in the cell form stable pairs with their complementary bases in the template. The ribonucleotide A pairs with T in the DNA, G with C, C with G, and U with A. Each ribonucleotide is positioned opposite its complementary base by the enzyme RNA polymerase. This enzyme attaches to the DNA and moves along it, linking the aligned ribonucleotides to make an ever-growing RNA molecule, as shown in Figure 8-4a. Hence, we already see the two principles of base complementarity and nucleicacid-protein binding in action (in this case, the binding of RNA polymerase).
Page 297
We have seen that RNA has a 5′ end and a 3′ end. During synthesis, RNA growth is always in the 5′-to-3′ direction; in other words, nucleotides are always added at a 3′ growing tip, as shown in Figure 8-4b. Because complementary nucleic acid strands are oppositely oriented, the fact that RNA is synthesized from 5′ to 3′ means that the template strand must be oriented from 3′ to 5′.
Figure 8-4: Overview of transcription
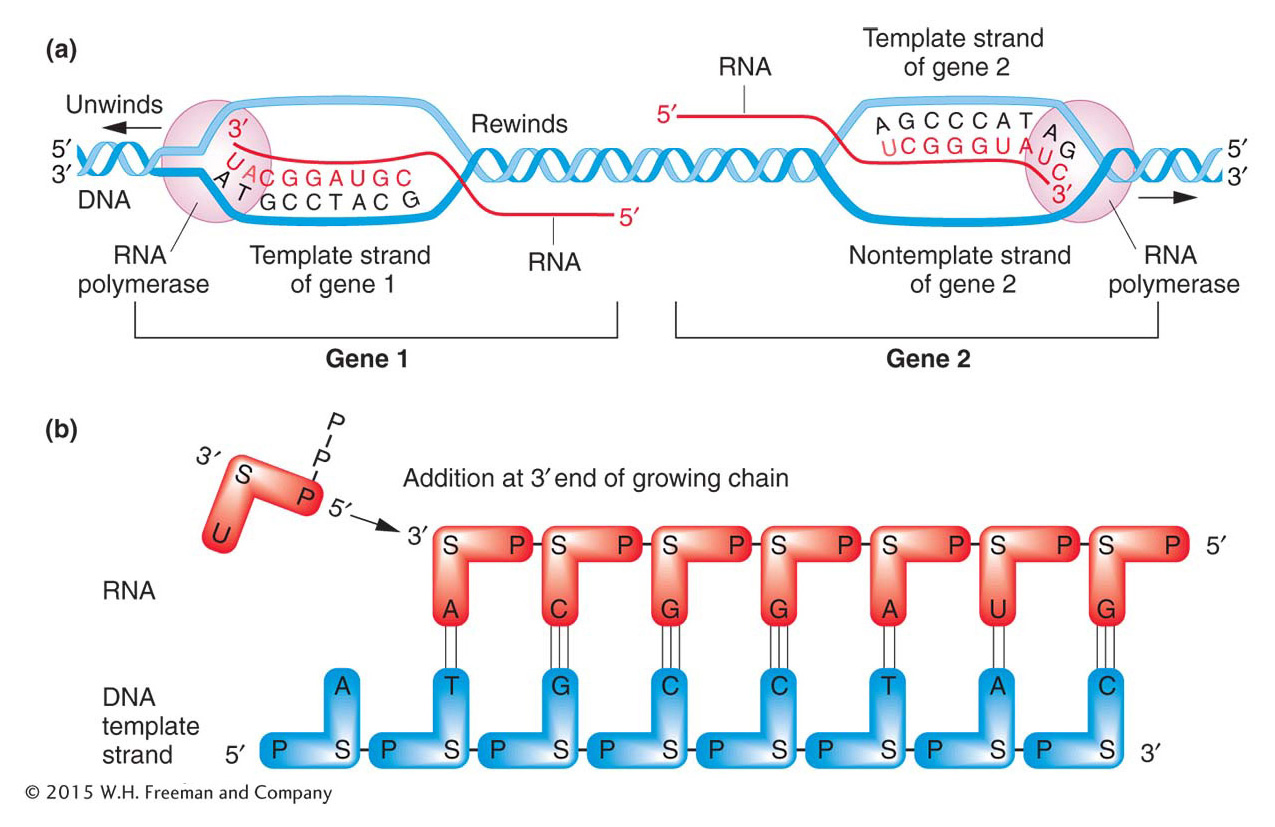
Figure 8-4: (a) Transcription of two genes in opposite directions. Genes 1 and 2 from Figure 8-3 are shown. Gene 1 is transcribed from the bottom strand. The RNA polymerase migrates to the left, reading the template strand in a 3′-to-5′ direction and synthesizing RNA in a 5′-to-3′ direction. Gene 2 is transcribed in the opposite direction, to the right, because the top strand is the template. As transcription proceeds, the 5′ end of the RNA is displaced from the template as the transcription bubble closes behind the polymerase. (b) As gene 1 is transcribed, the phosphate group on the 5′ end of the entering ribonucleotide (U) attaches to the 3′ end of the growing RNA chain. S = sugar. ANIMATED ART: Animated Art Transcription
As an RNA polymerase molecule moves along the gene, it unwinds the DNA double helix ahead of it and rewinds the DNA that has already been transcribed. As the RNA molecule progressively lengthens, the 5′ end of the RNA is displaced from the template and the transcription bubble closes behind the polymerase. “Trains” of RNA polymerases, each synthesizing an RNA molecule, move along the gene (Figure 8-5).
Figure 8-5: Many RNAs can be simultaneously transcribed from a gene
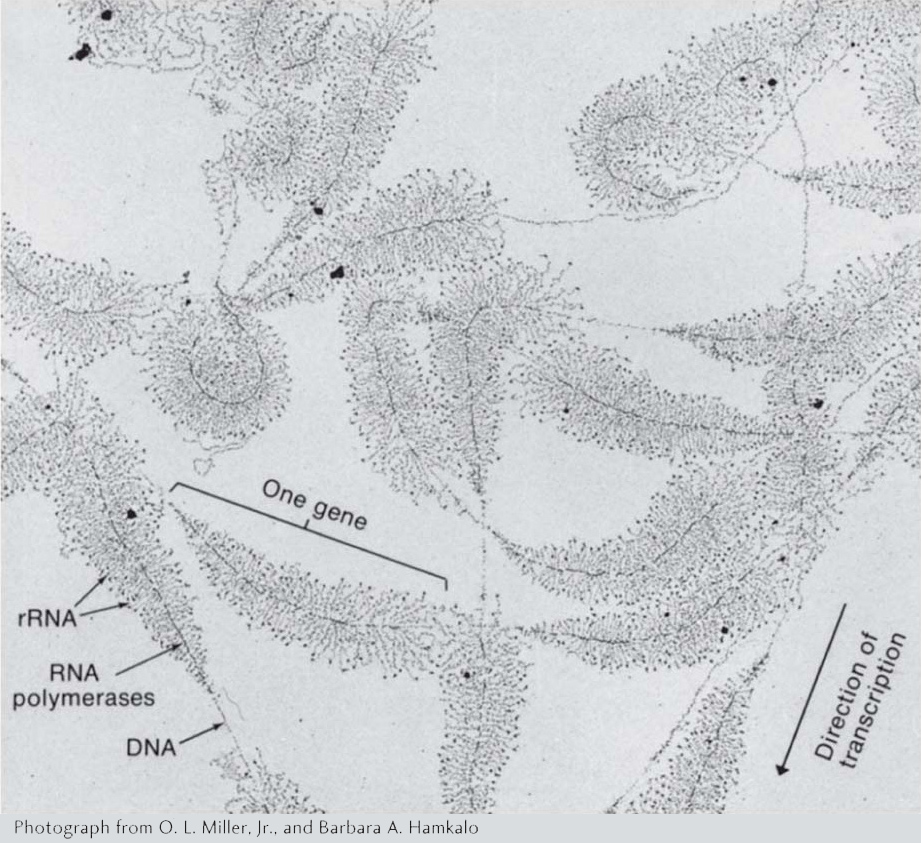
Figure 8-5: This electromicrograph shows the transcription of ribosomal RNA genes repeated in tandem in the nucleus of the amphibian Triturus viridiscens. Along each gene, many RNA polymerases are transcribing in one direction. The growing RNA transcripts appear as threads extending outward from the DNA backbone. The shorter transcripts are close to the start of transcription; the longer ones are near the end of the gene. The “Christmas tree” appearance is the result.
[Photograph from O. L. Miller, Jr., and Barbara A. Hamkalo.]
We have also seen that the bases in transcript and template are complementary. Consequently, the nucleotide sequence in the RNA must be the same as that in the nontemplate strand of the DNA, except that the T’s are replaced by U’s, as shown in Figure 8-6. When DNA base sequences are cited in scientific literature, the sequence of the nontemplate strand is conventionally given because this sequence is the same as that found in the RNA. For this reason, the nontemplate strand of the DNA is referred to as the coding strand. This distinction is extremely important to keep in mind when transcription is discussed.
Figure 8-6: Sequences of DNA and transcribed RNA

Figure 8-6: The mRNA sequence is complementary to the DNA template strand from which it is transcribed and therefore matches the sequence of the nontemplate strand (except that the RNA has U where the DNA has T). This sequence is from the gene for the enzyme β-galactosidase.
Page 298
KEY CONCEPT
Transcription is asymmetrical: only one strand of the DNA of a gene is used as a template for transcription. This strand is in the 3′-to-5′ orientation, and RNA is synthesized in the 5′-to-3′ direction.
Stages of transcription
The protein-encoding sequence in a gene is a relatively small segment of DNA embedded in a much longer DNA molecule (the chromosome). How is the appropriate segment transcribed into a single-stranded RNA molecule of correct length and nucleotide sequence? Because the DNA of a chromosome is a continuous unit, the transcriptional machinery must be directed to the start of a gene to begin transcribing at the right place, continue transcribing the length of the gene, and finally stop transcribing at the other end. These three distinct stages of transcription are called initiation, elongation, and termination. Although the overall process of transcription is remarkably similar in prokaryotes and eukaryotes, there are important differences. For this reason, we will follow the three stages first in prokaryotes (by using the gut bacterium E. coli as an example) and then in eukaryotes.
Initiation in prokaryotes How does RNA polymerase find the correct starting point for transcription? In prokaryotes, RNA polymerase usually binds to a specific DNA sequence called a promoter, located close to the start of the transcribed region. A promoter is an important part of the regulatory region of a gene. Remember that, because the synthesis of an RNA transcript begins at its 5′ end and continues in the 5′-to-3′ direction, the convention is to draw and refer to the orientation of the gene in the 5′-to-3′ direction, too. For this reason, the nontemplate DNA strand is usually shown. Generally, the 5′ end is drawn at the left and the 3′ at the right. With this view, because the promoter must be near the end of the gene where transcription begins, it is said to be at the 5′ end of the gene; thus, the promoter region is also called the 5′ regulatory region (Figure 8-7a).
Figure 8-7: Promoter sequences in E. coli
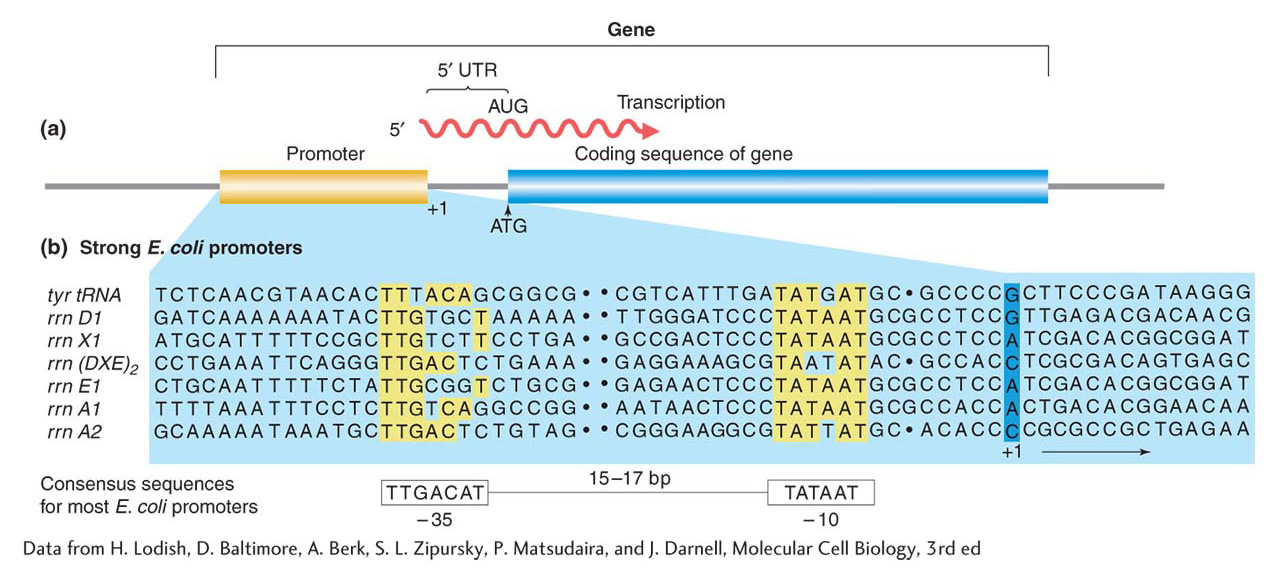
Figure 8-7: (a) The promoter lies “upstream” (toward the 5′ end) of the initiation point and coding sequences. (b) Promoters have regions of similar sequences, as indicated by the yellow shading in seven different promoter sequences in E. coli. Spaces (dots) are inserted in the sequences to optimize the alignment of the common sequences. Numbers refer to the number of bases before (−) or after (+) the RNA synthesis initiation point. The consensus sequence for most E. coli promoters is at the bottom.
The first transcribed base is always at the same location, designated the initiation site. The promoter is referred to as upstream of the initiation site because it is located ahead of the initiation site (5′ of the gene), in the direction opposite the direction of transcription. A downstream site would be located later in the direction of transcription. By convention, the first DNA base to be transcribed is numbered +1. Nucleotide positions upstream of the initiation site are indicated by a negative (−) sign and those downstream by a positive (+) sign.
Page 299
Figure 8-7b shows the promoter sequences of seven different genes in the E. coli genome. Because the same RNA polymerase binds to the promoter sequences of these different genes, the similarities among the promoters are not surprising. In particular, two regions of great similarity appear in virtually every case. These regions have been termed the −35 (minus 35) and −10 regions because they are located 35 base pairs and 10 base pairs, respectively, upstream of the first transcribed base. They are shown in yellow in Figure 8-7b. As you can see, the −35 and −10 regions from different genes do not have to be identical to perform a similar function. Nonetheless, it is possible to arrive at a sequence of nucleotides, called a consensus sequence, that is in agreement with most sequences. The E. coli promoter consensus sequence is shown at the bottom of Figure 8-7b. An RNA polymerase holoenzyme (see next paragraph) binds to the DNA at this point, then unwinds the DNA double helix and begins the synthesis of an RNA molecule. Note in Figure 8-7a that the protein-encoding part of the gene usually begins at an ATG sequence, but the initiation site, where transcription begins, is usually well upstream of this sequence. The intervening part is referred to as the 5′ untranslated region (5′ UTR).
Figure 8-8: Transcription initiation in prokaryotes
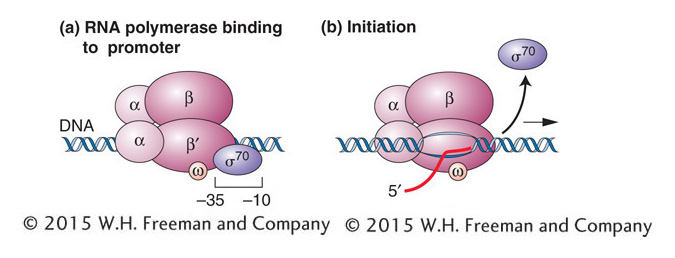
Figure 8-8: The σ subunit positions prokaryotic RNA polymerase for transcription initiation. (a) Binding of the σ subunit to the −10 and −35 regions positions the other subunits for correct initiation. (b) Shortly after RNA synthesis begins, the σ subunit dissociates from the other subunits, which continue transcription.
The bacterial RNA polymerase that scans the DNA for a promoter sequence is called the RNA polymerase holoenzyme (Figure 8-8). This multisubunit complex is composed of the five subunits of the core enzyme (two subunits of α, one of β, one of β’, and one of ω) plus a subunit called sigma factor (σ). The two α subunits help assemble the enzyme and promote interactions with regulatory proteins, the β subunit is active in catalysis, the β’ subunit binds DNA, and the ω subunit has roles in enzyme assembly and the regulation of gene expression. The σ subunit binds to the −10 and −35 regions, thus positioning the holoenzyme to initiate transcription correctly at the start site (see Figure 8-8a). The σ subunit also has a role in separating (melting) the DNA strands around the −10 region so that the core enzyme can bind tightly to the DNA in preparation for RNA synthesis. After the core enzyme is bound, transcription begins and the σ subunit dissociates from the rest of the complex (see Figure 8-8b).
Page 300
E. coli, like most other bacteria, has several different σ factors. One, called σ70 because its mass in kilodaltons is 70, is the primary σ subunit used to initiate the transcription of the vast majority of E. coli genes. Other σ factors recognize different promoter sequences. Thus, by associating with different σ factors, the same core enzyme can recognize different promoter sequences and transcribe different sets of genes.
Elongation As the RNA polymerase moves along the DNA, it unwinds the DNA ahead of it and rewinds the DNA that has already been transcribed. In this way, it maintains a region of single-stranded DNA, called a transcription bubble, within which the template strand is exposed. In the bubble, polymerase monitors the binding of a free ribonucleoside triphosphate to the next exposed base on the DNA template and, if there is a complementary match, adds it to the chain. The energy for the addition of a nucleotide is derived from splitting the high-energy triphosphate and releasing inorganic diphosphate, according to the following general formula:
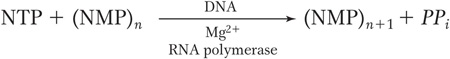
Figure 8-9a gives a physical picture of elongation. Inside the bubble, the last eight or nine nucleotides added to the RNA chain form an RNA–DNA hybrid by complementary base pairing with the template strand. As the RNA chain lengthens at its 3′ end, the 5′ end is further extruded from the polymerase. The complementary base pairs are broken at the point of exit, leaving the extruding strand single stranded.
Figure 8-9: Elongation and termination of transcription
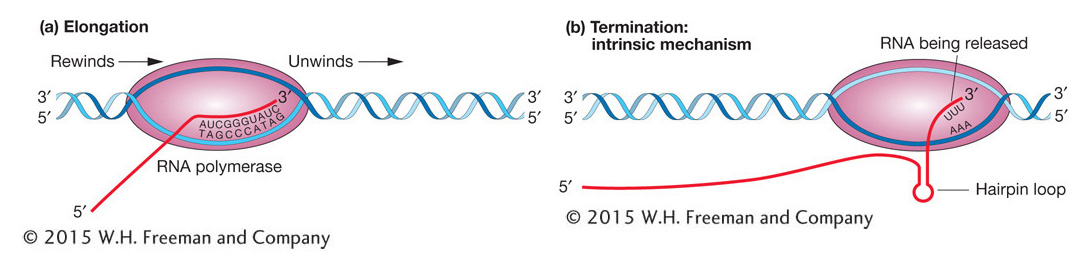
Figure 8-9: The five subunits of RNA polymerase are shown as a single ellipse-like shape surrounding the transcription bubble. (a) Elongation: Synthesis of an RNA strand complementary to the single-strand region of the DNA template strand is in the 5′-to-3′ direction. DNA that is unwound ahead of RNA polymerase is rewound after it has been transcribed. (b) Termination: The intrinsic mechanism shown here is one of two ways used to end RNA synthesis and release the completed RNA transcript and RNA polymerase from the DNA. In this case, the formation of a hairpin loop sets off their release. For both the intrinsic and the rho-mediated mechanism, termination first requires the synthesis of certain RNA sequences.
Termination The transcription of an individual gene continues beyond the protein-encoding segment of the gene, creating a 3′ untranslated region (3′ UTR) at the end of the transcript. Elongation proceeds until RNA polymerase recognizes special nucleotide sequences that act as a signal for chain termination. The encounter with the signal nucleotides initiates the release of the nascent RNA and the enzyme from the template (Figure 8-9b). The two major mechanisms for termination in E. coli (and other bacteria) are called intrinsic and rho dependent.
Page 301
Figure 8-10: A bacterial transcription-termination site
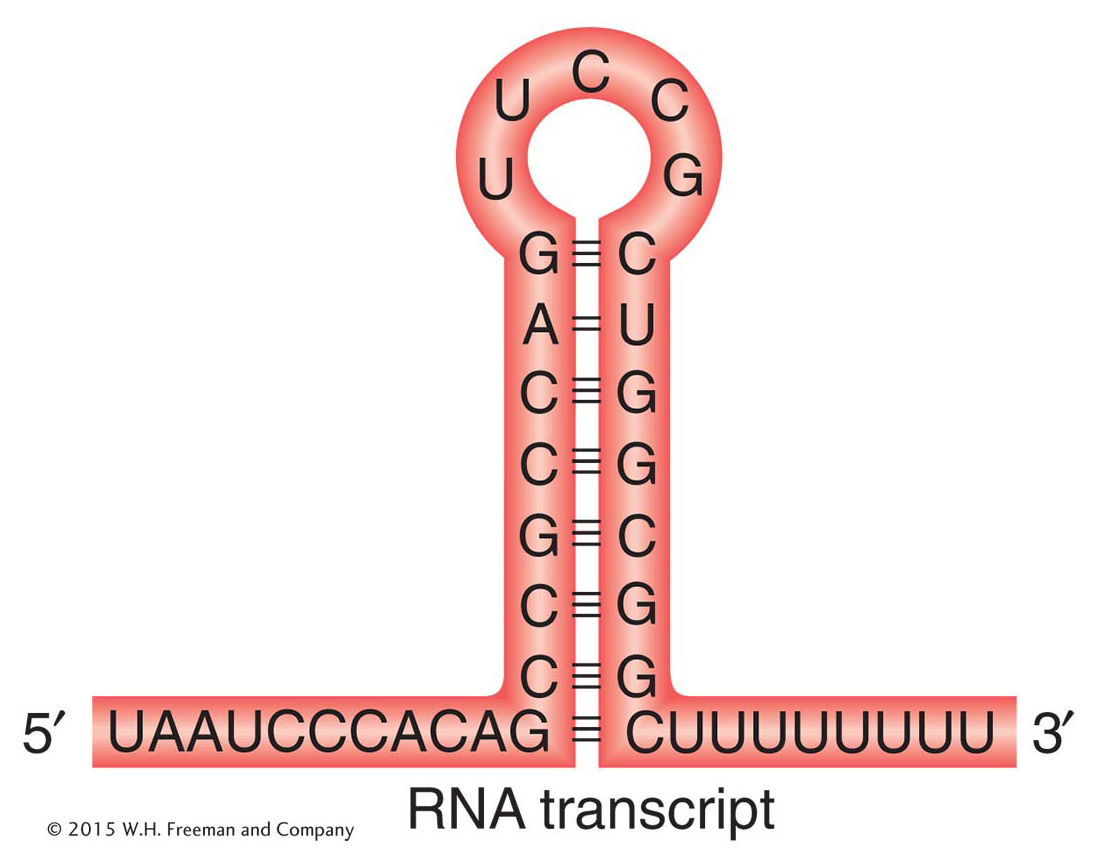
Figure 8-10: The structure of a termination site for RNA polymerase in bacteria. The hairpin structure forms by complementary base pairing within a GC-rich RNA strand. Most of the RNA base pairing is between G and C, but there is one A–U pair.
In the intrinsic mechanism, the termination is direct. The terminator sequences contain about 40 base pairs, ending in a GC-rich stretch that is followed by a string of six or more A’s. Because G and C in the template will give C and G, respectively, in the transcript, the RNA in this region also is GC rich. These C and G bases are able to form complementary hydrogen bonds with each other, resulting in an RNA hairpin stem-loop (Figure 8-10). Recall that the G–C base pair is more stable than the A–T pair because it is hydrogen bonded at three sites, whereas the A–T (or A–U) pair is held together by only two hydrogen bonds. RNA hairpins with stems that are largely G–C pairs are more stable than hairpins with stems that are largely A–U pairs. The hairpin structure is followed by a string of about eight U’s that are complementary to the A residues on the DNA template.
Normally, in the course of transcription elongation, RNA polymerase will pause if the short DNA–RNA hybrid in the transcription bubble is weak and will backtrack to stabilize the hybrid. Like that of hairpins, the strength of the hybrid is determined by the relative number of G–C base pairs compared with A–U base pairs (or A–T base pairs in RNA–DNA hybrids). In the intrinsic mechanism, the polymerase is believed to pause after synthesizing the U’s (A–U forms a weak DNA-RNA hybrid). However, the backtracking polymerase encounters the hairpin loop. This roadblock sets off the release of RNA from the polymerase and the release of the polymerase from the DNA template.
The second type of termination mechanism requires the help of a protein called the rho factor. This protein recognizes the nucleotide sequences that act as termination signals for RNA polymerase. RNAs with rho-dependent termination signals do not have the string of U residues at their 3′ end and usually do not have hairpin loops. Instead, they have a sequence of about 40 to 60 nucleotides that is rich in C residues and poor in G residues and includes an upstream segment called the rut (rho utilization) site. Rho is a hexamer consisting of six identical subunits that bind a nascent RNA chain at the rut site. These sites are located just upstream from (recall that upstream means 5′ of) sequences at which the RNA polymerase tends to pause. After binding, rho facilitates the release of the RNA from RNA polymerase. Thus, rho-dependent termination entails the binding of rho to rut, the pausing of polymerase, and rho-mediated dissociation of the RNA from the RNA polymerase.
KEY CONCEPT
Prokaryotic transcripts are initiated 5′ of the coding region of genes when RNA polymerase binds to a consensus promoter sequence or when it associates with a σ factor that guides it to a non-consensus promoter sequence. Transcription termination occurs at special sequences 3′ of the coding region that are either intrinsic or rho dependent.