16.1 The Phenotypic Consequences of DNA Mutations
The term point mutation typically refers to the alteration of a single base pair of DNA or of a small number of adjacent base pairs. In this section, we will consider the effects of such changes at the phenotypic level. Point mutations are classified in molecular terms in Figure 16-2, which shows the main types of DNA changes and their effects on protein function when they occur within the protein-coding region of a gene.
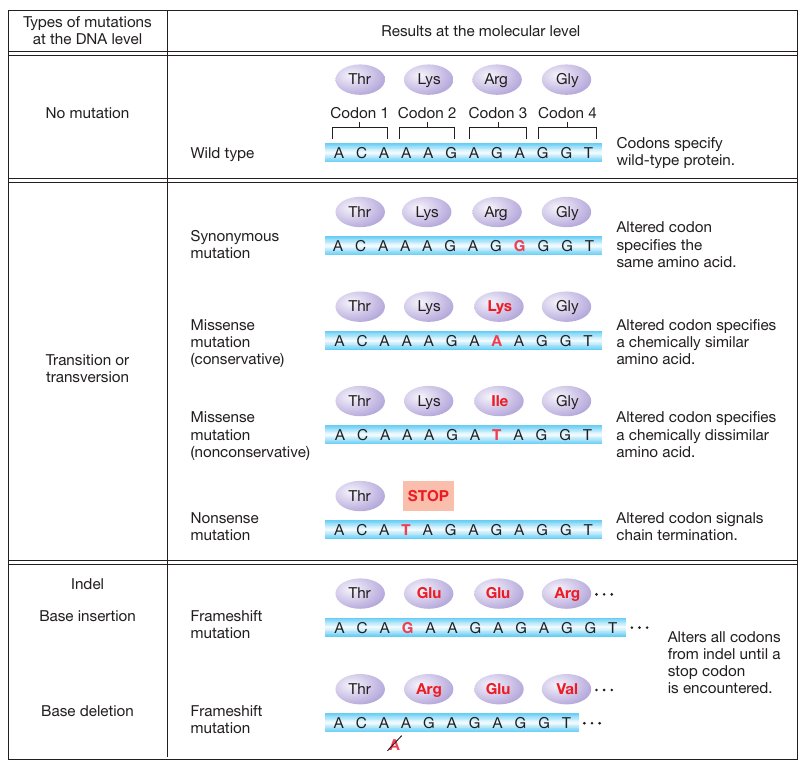
Figure 16-2: Consequences of point mutations within genes
Figure 16-2: Point mutations within the coding region of a gene vary in their effects on protein function. Proteins with synonymous and missense mutations are usually still functional.
Types of point mutation
The two main types of point mutation in DNA are base substitutions and base insertions or deletions. Base substitutions are mutations in which one base pair is replaced by another. Base substitutions can be divided into two subtypes: transitions and transversions. To describe these subtypes, we consider how a mutation alters the sequence on one DNA strand (the complementary change will take place on the other strand). A transition is the replacement of a base by the other base of the same chemical category. Either a purine is replaced by a purine (from A to G or from G to A) or a pyrimidine is replaced by a pyrimidine (from C to T or from T to C). A transversion is the opposite—the replacement of a base of one chemical category by a base of the other. Either a pyrimidine is replaced by a purine (from C to A, C to G, T to A, or T to G) or a purine is replaced by a pyrimidine (from A to C, A to T, G to C, or G to T). In describing the same changes at the double-stranded level of DNA, we must represent both members of a base pair in the same relative location. Thus, an example of a transition is G · C → A · T; that of a transversion is G · C → T · A. Insertion or deletion mutations are actually insertions or deletions of nucleotide pairs; nevertheless, the convention is to call them base-pair insertions or deletions. Collectively, they are termed indel mutations (for insertion-deletion). The simplest of these mutations is the addition or deletion of a single base pair. Mutations sometimes arise through the simultaneous addition or deletion of multiple base pairs at once. As we will see later in this chapter, mechanisms that selectively produce certain kinds of multiple-base-pair additions or deletions are the cause of certain human genetic diseases.
The molecular consequences of point mutations in a coding region
What are the functional consequences of these different types of point mutations? First, consider what happens when a mutation arises in a polypeptide-coding part of a gene. For single-base substitutions, there are several possible outcomes, but all are direct consequences of two aspects of the genetic code: degeneracy of the code and the existence of translation-termination codons (see Figure 16-2).
Synonymous mutations. The mutation changes one codon for an amino acid into another codon for that same amino acid. Synonymous mutations in exons are also referred to as silent mutations.
Missense mutations. The codon for one amino acid is changed into a codon for another amino acid. Missense mutations are sometimes called nonsynonymous mutations.
Nonsense mutations. The codon for one amino acid is changed into a translation-termination (stop) codon.
Synonymous substitutions never alter the amino acid sequence of the polypeptide chain. The severity of the effect of missense and nonsense mutations on the polypeptide differs from case to case. For example, a missense mutation may replace one amino acid with a chemically similar amino acid, called a conservative substitution. In this case, the alteration is less likely to affect the protein’s structure and function severely. Alternatively, one amino acid may be replaced by a chemically different amino acid in a nonconservative substitution. This type of alteration is more likely to produce a severe change in protein structure and function. Nonsense mutations will lead to the premature termination of translation. Thus, they have a considerable effect on protein function. The closer a nonsense mutation is to the 3′ end of the open reading frame (ORF), the more plausible it is that the resulting protein might possess some biological activity. However, many nonsense mutations produce completely inactive protein products.
Single-base-pair changes that inactivate proteins are often due to splice site mutations. As seen in Figure 16-3, such changes can dramatically change the mRNA transcript by leading to large insertions or deletions that may or may not be in frame.
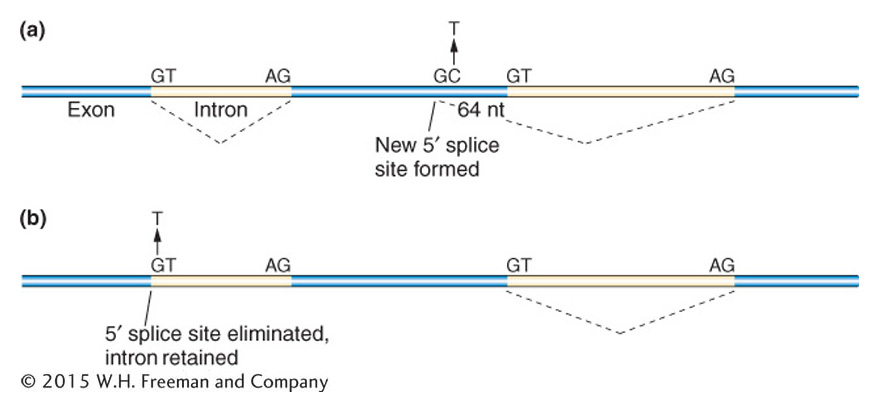
Figure 16-3: Point mutations can alter mRNA splicing
Figure 16-3: Two examples show the consequences of point mutations at splice sites. (a) A C to T transition mutation leads to a GT dinucleotide in the exon, forming a new 5′ splice site. As a result, 64 nucleotides at the end of an exon are spliced out. (b) A G to T transversion mutation would eliminate the 5′ splice site so the intron would be retained in the mRNA.
Like nonsense mutations, indel mutations may have consequences on polypeptide sequence that extend far beyond the site of the mutation itself (see Figure 16-2). Recall that the sequence of mRNA is “read” by the translational apparatus in register (“in frame”), three bases (one codon) at a time. The addition or deletion of a single base pair of DNA changes the reading frame for the remainder of the translation process, from the site of the base-pair mutation to the next stop codon in the new reading frame. Hence, these lesions are called frameshift mutations. These mutations cause the entire amino acid sequence translationally downstream of the mutant site to bear no relation to the original amino acid sequence. Thus, frameshift mutations typically result in complete loss of normal protein structure and function (Figure 16-4).
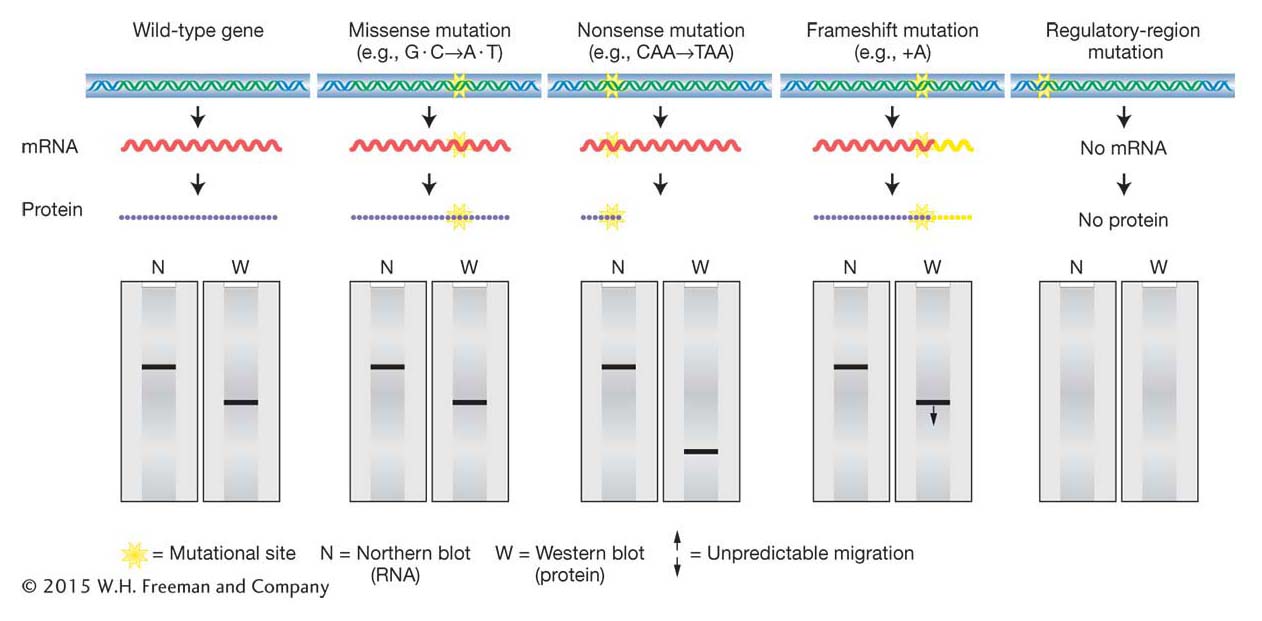
Figure 16-4: Consequences of point mutations on gene products
Figure 16-4: Point mutations in coding regions can alter protein structure with or without altering mRNA size. Point mutations in regulatory regions can prevent the synthesis of mRNA (and protein).
The molecular consequences of point mutations in a noncoding region
Now let’s turn to mutations that occur in regulatory and other noncoding sequences. Those parts of a gene that do not directly encode a protein contain many crucial DNA binding sites for proteins interspersed among sequences that are nonessential to gene expression or gene activity. At the DNA level, the binding sites include the sites to which RNA polymerase and its associated factors bind, as well as sites to which specific transcription-regulating proteins bind. At the RNA level, additional important binding sites include the ribosome-binding sites of bacterial mRNAs, the 5′ and 3′ splice sites for exon joining in eukaryotic mRNAs, and sites that regulate translation and localize the mRNA to particular areas and compartments within the cell.
The ramifications of mutations in parts of a gene other than the polypeptide-coding segments are harder to predict than are those of mutations in coding segments. In general, the functional consequences of any point mutation in such a region depend on whether the mutation disrupts (or creates) a binding site. Mutations that disrupt these sites have the potential to change the expression pattern of a gene by altering the amount of product expressed at a certain time or in a certain tissue or by altering the response to certain environmental cues. Such regulatory mutations will alter the amount of the protein product produced but not the structure of the protein. Alternatively, some binding-site mutations might completely obliterate a required step in normal gene expression (such as the binding of RNA polymerase or splicing factors) and hence totally inactivate the gene product or block its formation. Figure 16-4 shows some examples of how different types of mutations, inside and outside the coding region, can affect mRNA and protein.
It is important to keep in mind the distinction between the occurrence of a gene mutation—that is, a change in the DNA sequence of a given gene—and the detection of such an event at the phenotypic level. Many point mutations within noncoding sequences elicit little or no phenotypic change; these mutations are located between DNA binding sites for regulatory proteins. Such sites may be functionally irrelevant, or other sites within the gene may duplicate their function.