CHAPTER 9 EXERCISES
Question 9.38
9.38 Translate each problem into a r×c table. In each of the following scenarios, translate the problem into one that can be analyzed using a r×c table. Give the values of r and c, the table, and its entries.
(a) Three website designs are being compared. Sixty students have agreed to be subjects for the study, and they are randomly assigned to watch one of the designs for as long as they like. For each student, the study directors record whether or not the website is watched for more than a minute. For the first design, 16 students watched for more than a minute; for the second, 5 watched for more than a minute; and for the third, 10 students watched for more than a minute.
(b) A sample of undergraduate students were asked whether or not they were in favor of a new proposed core curriculum. For the first-
year students, 95 said Yes and 286 said No. For the fourth- year students 127 said Yes and 114 said No.
Question 9.39
9.39 Sexual harassment online or in person. In the study described in Exercise 9.25, the students were also asked whether or not they were harassed in person and whether or not they were harassed online. Here are the data for the girls:
| Harassed online | ||
|---|---|---|
| Harassed in person | Yes | No |
| Yes | 321 | 200 |
| No | 40 | 441 |
(b) Analyze these data using the method presented in this chapter for examining a relationship between two categorical variables in a 2×2 table.
(c) Use this example to explain the relationship between the chi-
square test and the z test for comparing two proportions.(d) The number of girls reported in this exercise is not the same as the number reported for Exercise 9.25. Suggest a possible reason for this difference.
9.39 (a) H0: p1 = p2, Ha: p1 ≠ p2; ˆp1=0.8892, ˆp2=0.3120, ˆp=0.5200, z = 17.556, P-value ≈ 0. (b) H0: There is no association between being harassed online and in person, Ha: There is a relationship; X 2 = 308.23, df = 1, P-value ≈ 0. (c) 17.5562 = 308.21, which agrees with X 2. (d) Perhaps one girl wouldn’t answer these questions.
Question 9.40
9.40 Data for the boys. Refer to the previous exercise. Here are the corresponding data for boys:
| Harassed online | ||
|---|---|---|
| Harassed in person | Yes | No |
| Yes | 183 | 154 |
| No | 48 | 578 |
Using these data, repeat the analyses that you performed for the girls in Exercise 9.39. How do the results for the boys differ from those that you found for girls?
Question 9.41
9.41 Repeat your analysis. In part (a) of Exercise 9.39, you had to decide which variable was explanatory and which variable was response when you computed the proportions to be compared.
(a) Did you use harassed online or harassed in person as the explanatory variable? Explain the reasons for your choice.
(b) Repeat the analysis that you performed in Exercise 9.39 with the other choice for the explanatory variable.
(c) Summarize what you have learned from comparing the results of using the different choices for analyzing these data.
9.41 (a) The solution to Exercise 9.39 used “harassed online” as the explanatory variable. (b) Changing to use “harassed in person” for the two-proportions z test gives ˆp1=0.6161, ˆp2=0.0832, ˆp=0.3603. We again compute z = 17.556, P-value ≈ 0. No changes will occur in the chi-square test. (c) The test statistic will be the same regardless of which is viewed as explanatory.
Question 9.42
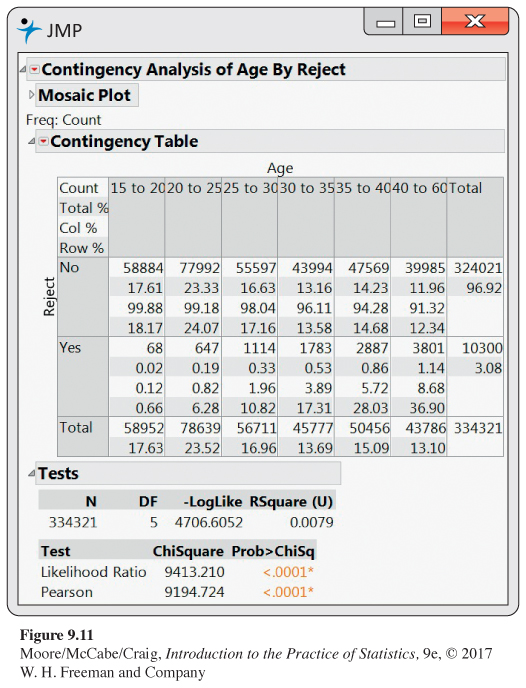
9.42 Read the output for teeth. Exercise 8.62 (page 520) gives data on individuals rejected for military service in the Cuban War of Independence in 1898 because they did not have enough teeth. In that exercise, you compared the rejection rate for those under the age of 20 with the rejection rate for those over 40. Figure 9.11 gives software output for the table that classifies the recruits into six age categories. Use the output to find the joint distribution, the marginal distributions, and the conditional distributions for these data.
Question 9.43
9.43 Is the die fair? You suspect that a die has been altered so that the outcomes of a roll, the numbers 1 to 6, are not equally likely. You toss the die 600 times and obtain the following results:
| Outcome | 1 | 2 | 3 | 4 | 5 | 6 |
| Count | 87 | 80 | 125 | 117 | 100 | 91 |
Compute the expected counts that you would need to use in a goodness-
9.43 100 for each face of the die.
Question 9.44
9.44 Perform the significance test Refer to the previous exercise. Find the chi-
Question 9.45
9.45 Health care fraud. Most errors in billing insurance providers for health care services involve honest mistakes by patients, physicians, or others involved in the health care system. However, fraud is a serious problem. The National Health Care Anti-
| Stratum | Sampled claims | Number not allowed |
| Small | 57 | 6 |
| Medium | 17 | 5 |
| Large | 5 | 1 |
(a) Construct the 3×2 table of counts for these data that includes the marginal totals.
(b) Find the percent of claims that were not allowed in each of the three strata.
(c) To perform a significance test, combine the medium and large strata. Explain why we do this.
(d) State an appropriate null hypothesis to be tested for these data.
(e) Perform the significance test and report your test statistic with degrees of freedom and the P-value. State your conclusion.
9.45 (a) Marginal totals are Small: 57; Medium: 17; Large: 5. Allowed: 67; Not allowed: 12. (b) 10.53% of Small, 29.41% of Medium, and 20% of Large were not allowed. (c) The expected count for Large/Not allowed is too small. (d) H0: There is no association between the size of the claim and whether or not it is allowed; Hα: There is an association between the size of the claim and whether or not it is allowed. (e) X 2 = 3.456, df = 1, 0.05 < P-value < 0.10.
Question 9.46
![]() 9.46 Population estimates. Refer to the previous exercise. One reason to do an audit such as this is to estimate the number of claims that would not be allowed if all claims in a population were examined by experts. We have an estimate of the proportion of unallowed claims from each stratum based on our sample. We know the corresponding population proportion for each stratum. Therefore, if we take the sample proportions of unallowed claims and multiply by the population sizes, we would have the estimates that we need. Here are the population sizes for the three strata:
9.46 Population estimates. Refer to the previous exercise. One reason to do an audit such as this is to estimate the number of claims that would not be allowed if all claims in a population were examined by experts. We have an estimate of the proportion of unallowed claims from each stratum based on our sample. We know the corresponding population proportion for each stratum. Therefore, if we take the sample proportions of unallowed claims and multiply by the population sizes, we would have the estimates that we need. Here are the population sizes for the three strata:
| Stratum | Claims in strata |
| Small | 3342 |
| Medium | 246 |
| Large | 58 |
(a) For each stratum, estimate the total number of claims that would not be allowed if all claims in the strata had been audited.
(b) Give margins of error for your estimates. ([Hint: you first need to find standard errors for your sample estimates using material presented in Chapter 8 (page 486). Then you need to use the rules for variances from Chapter 4 (page 258) to find the standard errors for the population estimates. Finally, you need to multiply by z* to determine the margins of error.])
Question 9.47
9.47 DFW rates. One measure of student success for colleges and universities is the percent of admitted students who graduate. Studies indicate that a key issue in retaining students is their performance in so-
| Year | DFW rate | Number of students taking course |
| Year 1 | 42.3% | 2408 |
| Year 2 | 24.9% | 2325 |
| Year 3 | 19.9% | 2126 |
Do you think that the changes in this gateway course had an impact on the DFW rate? Write a report giving your answer to this question. Support your answer by an analysis of the data.
9.47 H0: the DFW rate has not changed; X2 = 308.3, df = 2, P < 0.0001.
Question 9.48
9.48 Lying to a teacher. One of the questions in a survey of high school students asked about lying to teachers.15 The following table gives the numbers of students who said that they lied to a teacher at least once during the past year, classified by sex:
| Sex | ||
| Lied at least once | Male | Female |
| Yes | 3,228 | 10,295 |
| No | 9,659 | 4,620 |
(a) Add the marginal totals to the table.
(b) Calculate appropriate percents to describe the results of this question.
(c) Summarize your findings in a short paragraph.
(d) Test the null hypothesis that there is no association between sex and lying to teachers. Give the test statistic and the P-value (with a sketch similar to the one on p. 535) and summarize your conclusion. Be sure to include numerical and graphical summaries.
(e) The survey asked students if they lied, but we do not know if they answered the question truthfully. How does this fact affect the conclusions that you can draw from these data?
Question 9.49
9.49 When do Canadian students enter private career colleges? A survey of 13,364 Canadian students who enrolled in private career colleges was conducted to understand student participation in the private, postsecondary educational system.16 In one part of the survey, students were asked about their field of study and about when they entered college. Here are the results:
| Time of entry | |||
| Field of study |
Number of students |
Right after high school | Later |
| Trades | 942 | 34% | 66% |
| Design | 584 | 47% | 53% |
| Health | 5085 | 40% | 60% |
| Media/IT | 3148 | 31% | 69% |
| Service | 1350 | 36% | 64% |
| Other | 2255 | 52% | 48% |
In this table, the second column gives the number of students in each field of study. The next two columns give the marginal distribution of time of entry for each field of study.
(a) Use the data provided to make the 6×2 table of counts for this problem.
(b) Analyze the data.
(c) Write a summary of your conclusions. Be sure to include the results of your significance testing as well as a graphical summary.
9.49 (a) For example, among those students in trades, 320.28 enrolled right after high school, and 621.72 enrolled later. (b) For example, 39.4% of these students enrolled right after high school. Health is the most popular field with 38%. (c) X2 = 276.1, df = 5, P-value < 0.0001.
Question 9.50
9.50 Government loans for Canadian students in private career colleges. Refer to the previous exercise. The survey also asked about how these college students paid for their education. A major source of funding was government loans. Here are the survey percents of Canadian private students who use government loans to finance their education by field of study:
| Field of study |
Number of students |
Percent using government loans |
| Trades | 942 | 45% |
| Design | 599 | 53% |
| Health | 5234 | 55% |
| Media/IT | 3238 | 55% |
| Service | 1378 | 60% |
| Other | 2300 | 47% |
(a) Construct the 6 × 2 table of counts for this exercise.
(b) Test the null hypothesis that the percent of students using government loans to finance their education does not vary with field of study. Be sure to provide all the details of your significance test.
(c) Summarize your analysis and conclusions. Be sure to include a graphical summary.
(d) The number of students reported in this exercise is not the same as the number reported in Exercise 9.49. Suggest a possible reason for this difference.
Question 9.51
9.51 Are Mexican Americans less likely to be selected as jurors? Refer to Exercise 8.97 (page 524) concerning Castaneda v. Partida, the case where the Supreme Court review used the phrase “two or three standard deviations” as a criterion for statistical significance. Recall that there were 181,535 persons eligible for jury duty, of whom 143,611 were Mexican Americans. Of the 870 people selected for jury duty, 339 were Mexican Americans. We are interested in finding out if there is an association between being a Mexican American and being selected as a juror. Formulate this problem using a two-
9.51 X 2 = 852.4330, df = 1, P-value < 0.0001, z2 = ( − 29.2)2 = 852.64 = X 2 with rounding error.
Question 9.52
9.52 Goodness of fit to the uniform distribution. Computer software generated 500 random numbers that should look as if they are from the uniform distribution on the interval 0 to 1 (see p. 240). They are categorized into five groups: (1) less than or equal to 0.2, (2) greater than 0.2 and less than or equal to 0.4, (3) greater than 0.4 and less than or equal to 0.6, (4) greater than 0.6 and less than or equal to 0.8, and (5) greater than 0.8. The counts in the five groups are 114, 92, 108, 101, and 85, respectively. The probabilities for these five intervals are all the same. What is this probability? Compute the expected number for each interval for a sample of 500. Finally, perform the goodness of fit test and summarize your results.
Question 9.53
9.53 More on goodness of fit to the uniform distribution. Refer to the previous exercise. Use software to generate your own sample of 800 uniform random variables on the interval from 0 to 1, and perform the goodness of fit test. Choose a different set of intervals than the ones used in the previous exercise.
9.53 Most results will give a fairly decent randomization and should fail to reject the null hypothesis. Changing the interval likely will not change the result and should still fail to reject the null hypothesis.
Question 9.54
![]() 9.54 Suspicious results? An instructor who assigned an exercise similar to the one described in the previous exercise received homework from a student who reported a P-value of 0.999. The instructor suspected that the student did not use the computer for the assignment but just made up some numbers for the homework. Why was the instructor suspicious? How would this scenario change if there were 2000 students in the class?
9.54 Suspicious results? An instructor who assigned an exercise similar to the one described in the previous exercise received homework from a student who reported a P-value of 0.999. The instructor suspected that the student did not use the computer for the assignment but just made up some numbers for the homework. Why was the instructor suspicious? How would this scenario change if there were 2000 students in the class?
Question 9.55
9.55 Is there a random distribution of trees? In Example 6.1 (page 342), we examined data concerning the longleaf pine trees in the Wade Tract and concluded that the distribution of trees in the tract was not random. Here is another way to examine the same question. First, we divide the tract into four equal parts, or quadrants, in the east–
| Quadrant | Q1 | Q2 | Q3 | Q4 |
| Count | 18 | 22 | 39 | 21 |
(a) If the trees are randomly distributed, we expect to find 25 trees in each quadrant. Why? Explain your answer.
(b) We do not really expect to get exactly 25 trees in each quadrant. Why? Explain your answer.
(c) Perform the goodness-
of- fit test for these data to determine if these trees are randomly scattered. Write a short report giving the details of your analysis and your conclusion.
9.55 (a) Each quadrant accounts for one-fourth of the area, so we expect it to contain one-fourth of the 100 trees. (b) Some random variation would not surprise us; we no more expect exactly 25 trees per quadrant than we would expect to see exactly 50 heads when flipping a fair coin 100 times. (c) χ2 = 10.8, df = 3, and P-value = 0.0129.
Question 9.56
9.56 McNemar’s test. In Exercise 9.39 (page 551), you examined the relationship between being harassed online and being harassed in person for a sample of 1002 girls. An additional question can be asked about these data. Suppose we wanted to compare the proportions of girls who were harassed online and the proportion who were harassed in person. This is very much like the type of question that we studied in Section 8.2 (page 505). There, however, we used the assumption that the two samples used to calculate the proportions were independent. This assumption is not valid for our harassment data because the proportions are calculated from data provided by the same girls. McNemar’s test is the recommended procedure. The null hypothesis is that the two population proportions are equal and the alternative is two-