DNA Polymorphisms Are Used as Markers for Linkage Mapping of Human Mutations
Once the mode of inheritance has been determined, the next step in finding a disease allele is to map its position with respect to known genetic markers using the basic principle of genetic linkage, as described in Section 6.1. The presence of many different already mapped genetic traits, or markers, distributed along the length of a chromosome facilitates the mapping of a new mutation. The more markers that are available, the more precisely a mutation can be mapped. The density of genetic markers needed for a high-resolution human genetic map is about one marker every 5 centimorgans (cM) (as discussed previously, one genetic map unit, or centimorgan, is defined as the distance between two positions along a chromosome that results in 1 recombinant individual in 100 progeny). Thus a high-resolution genetic map requires 25 or so genetic markers of known position distributed along the length of each human chromosome.
In the experimental organisms commonly used in genetic studies, numerous markers with easily detectable phenotypes are available for genetic mapping of mutations. For humans, there are not nearly enough phenotypic markers to carry out genetic mapping studies. Instead, recombinant DNA technology has made available a wealth of useful DNA-based molecular markers. Because most of the human genome does not encode proteins, a large amount of phenotypically inconsequential sequence variation exists between individuals. Indeed, it has been estimated that nucleotide differences between unrelated individuals occur on an average of 1 of every 103 nucleotides. Since variations in DNA sequence, referred to as DNA polymorphisms, can be followed from one generation to the next by sequencing the DNA of individuals, they can serve as ideal genetic markers for linkage studies. Currently, a panel of as many as 104 different known polymorphisms whose locations have been mapped in the human genome is used for genetic linkage studies in humans.
Page 256
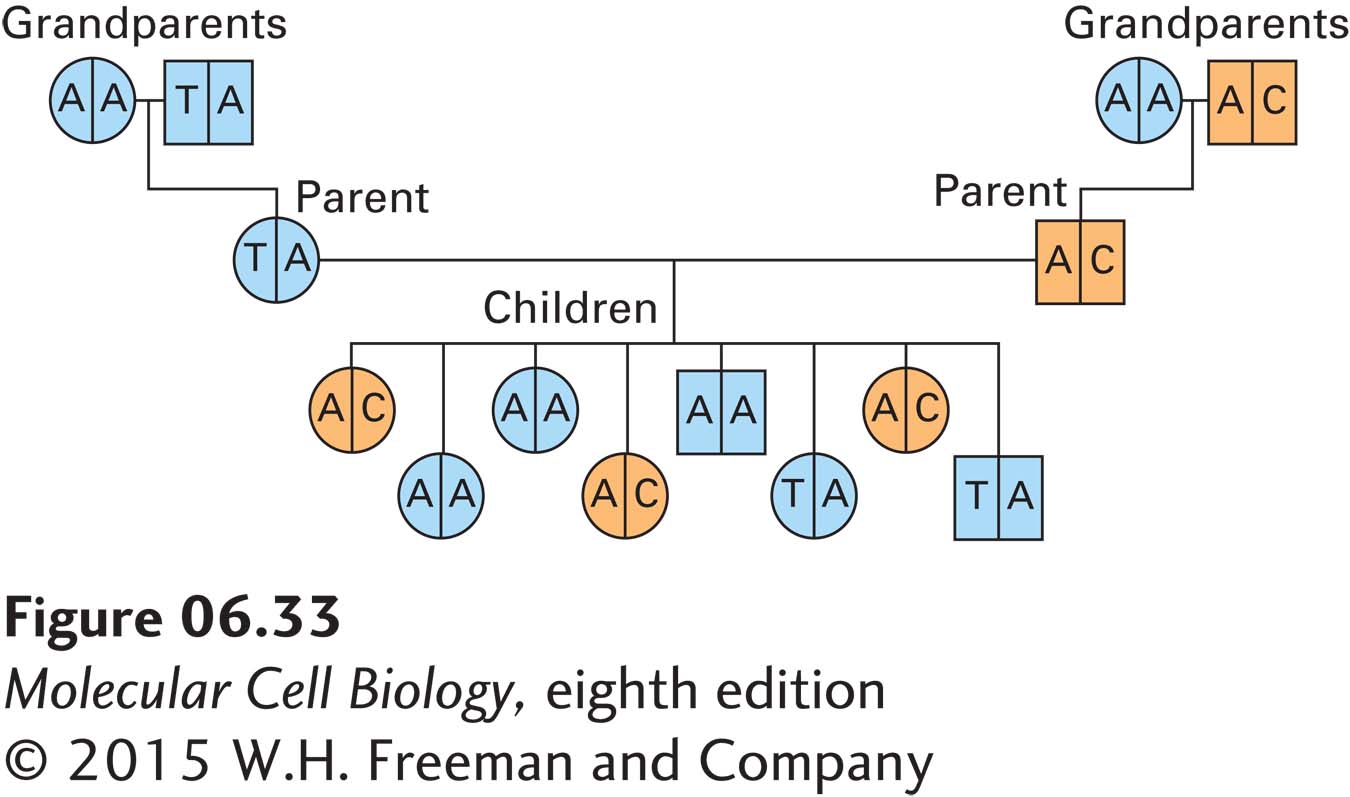
Single-nucleotide polymorphisms (SNPs) constitute the most abundant type of DNA polymorphism and are therefore useful for constructing genetic maps of maximum resolution (Figure 6-33). Another useful type of DNA polymorphism consists of a variable number of repetitions of a two-, three-, or four-base sequence. Such polymorphisms, known as short tandem repeats (STRs) or microsatellites, presumably are formed by recombination or by slippage of either the template or newly synthesized strand during DNA replication. A useful property of STRs is that different individuals often have different numbers of repeats. The existence of multiple versions of an STR makes it more likely to produce an informative segregation pattern in a given pedigree and therefore to be of more general use in mapping the positions of disease genes. These polymorphisms can be detected by PCR amplification and DNA sequencing.
EXPERIMENTAL FIGURE 6-33Single-nucleotide polymorphisms (SNPs) can be followed like genetic markers. A hypothetical pedigree based on SNP analysis of the DNA from a region of a chromosome. In this family, the SNP exists as an A, T, or C nucleotide. Each individual has two alleles: some contain an A on both chromosomes, and others are heterozygous at this site. Circles indicate females; squares indicate males. Blue indicates unaffected individuals; orange indicates individuals with the trait of interest. Analysis reveals that the trait segregates with a C at the SNP.