Most Simple-Sequence DNAs Are Concentrated in Specific Chromosomal Locations
Besides duplicated protein-coding genes and tandemly repeated genes, eukaryotic cells contain multiple copies of other DNA sequences, generally referred to as repetitious DNA (see Table 8-1). Of the two main types of repetitious DNA, the less prevalent is simple-sequence DNA, or satellite DNA. This type of DNA, which constitutes about 6 percent of the human genome, is composed of perfect or nearly perfect repeats of relatively short sequences. The second, more common type of repetitious DNA, collectively called interspersed repeats, is composed of much longer sequences. These sequences, consisting of several types of transposable elements, are discussed in Section 8.3.
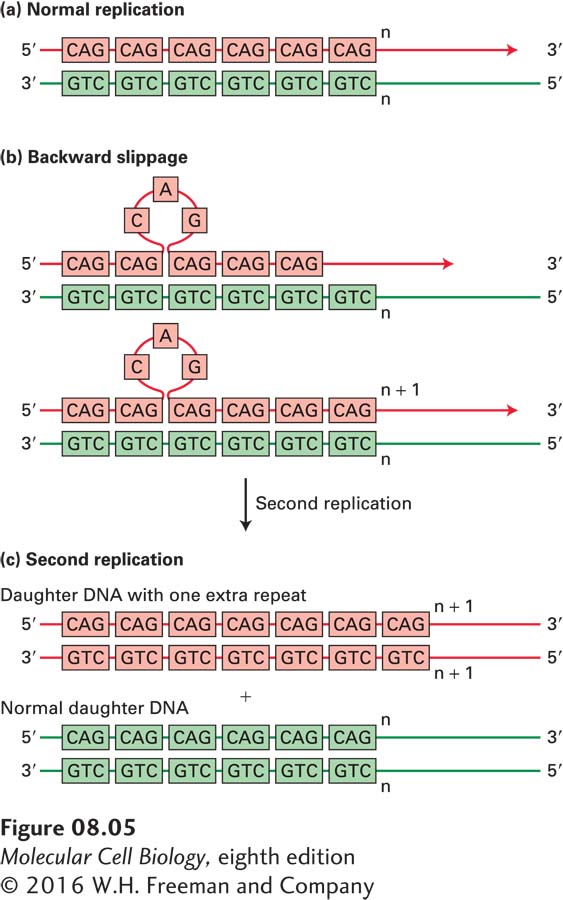
The length of each repeat in simple-sequence DNA can range from 1 to 500 base pairs. DNA sequences in which the repeats each contain 1–13 bp are often called microsatellites. Most microsatellite DNA has a repeat length of 1–4 bp, and the repeats usually occur in tandem sequences of 150 repeats or fewer. Microsatellites are thought to have originated by “backward slippage” of a daughter strand on its template strand during DNA replication so that the same short sequence was copied twice (Figure 8-5).
FIGURE 8-5Generation of microsatellite repeats by backward slippage of the nascent daughter strand during DNA replication. If, during replication (a), the nascent daughter strand “slips” backward relative to the template strand by one repeat, one new copy of the repeat is added to the daughter strand when DNA replication continues (b). An extra copy of the repeat forms a single-stranded loop in the daughter strand of the daughter duplex DNA molecule. If this single-stranded loop is not removed by DNA repair proteins before the next round of DNA replication (c), the extra copy of the repeat is added to one of the double-stranded daughter DNA molecules.
Microsatellites occasionally occur within transcription units. Some individuals are born with a larger number of repeats in specific genes than are observed in the general population, presumably because of daughter-strand slippage during DNA replication in the germ cells from which they and their forebears developed. Such expanded microsatellites have been found to cause at least 14 different types of neuromuscular diseases, depending on the gene in which they occur. In some cases, expanded microsatellites behave like a recessive mutation because they interfere with just the function or expression of the gene in which they occur. But in the more common types of diseases associated with expanded microsatellites, the expanded microsatellites behave like dominant mutations. In some of these diseases, such as Huntington disease, triplet repeats occur within a coding region, resulting in the formation of long polymers of a single amino acid that may aggregate over time in long-lived neuronal cells, eventually interfering with normal cellular function. For example, expansion of a CAG repeat in the first exon of the gene involved in Huntington disease leads to synthesis of long stretches of polyglutamine, which over several decades form toxic aggregates resulting in neuronal cell death in patients with the disease.
Page 311
Pathogenic expanded repeats can also occur in the noncoding regions of some genes, where they are thought to function as dominant mutations because they interfere with the processing of a subset of mRNAs in the muscle cells and neurons where the affected genes are expressed. For example, in patients with myotonic dystrophy type 1, transcripts of the DMPK gene contain between 50 and 1500 repeats of the sequence CUG in the 3′ untranslated region, compared with 5–34 repeats in unaffected individuals. The extended stretch of CUG repeats in affected individuals is thought to form a long RNA hairpin (see Figure 5-9), which binds and sequesters nuclear RNA-binding proteins that normally regulate alternative RNA splicing of a subset of pre-mRNAs essential for muscle and nerve cell function.
[Courtesy of Sabine Mal, Ph.D., Manitoba Institute of Cell Biology, Canada.]
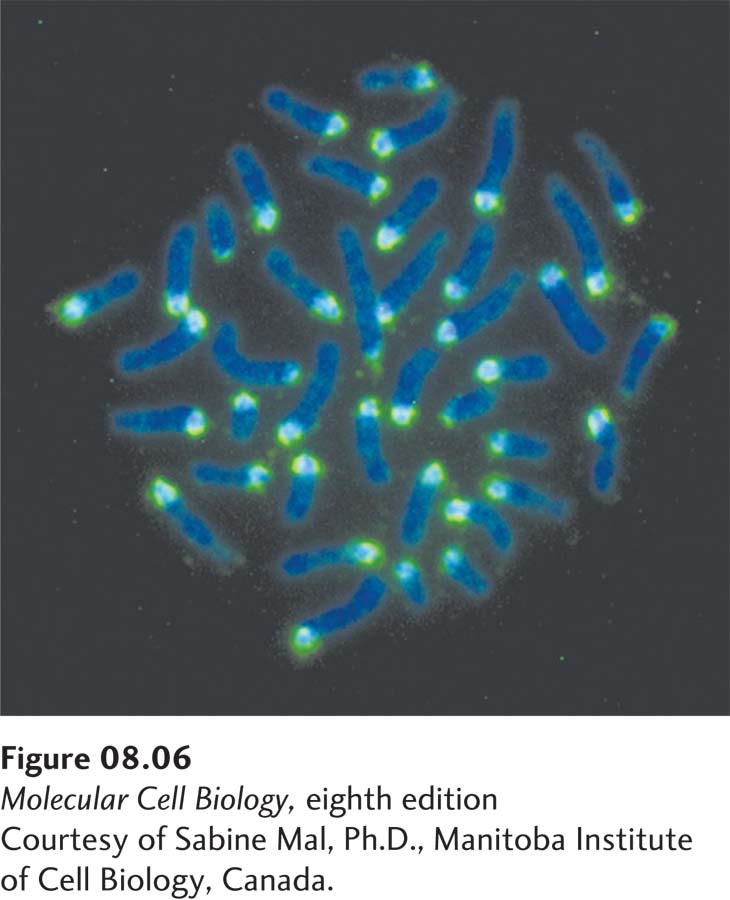
EXPERIMENTAL FIGURE 8-6Simple-sequence DNA is localized at the centromere in mouse chromosomes. Purified simple-sequence DNA from mouse cells was copied in vitro using E. coli DNA polymerase I and fluorescently labeled dNTPs to generate a fluorescently labeled DNA “probe” for mouse simple-sequence DNA. Chromosomes from cultured mouse cells were fixed and denatured on a microscope slide, and the chromosomal DNA was then hybridized in situ to the labeled probe (light blue). The slide was also stained with DAPI, a DNA-binding dye, to visualize the full length of the chromosomes (dark blue). Fluorescence microscopy shows that the simple-sequence probe hybridizes primarily to one end of the telocentric mouse chromosomes (i.e., chromosomes in which the centromeres are located near one end).
[Courtesy of Sabine Mal, Ph.D., Manitoba Institute of Cell Biology, Canada.]
Most simple-sequence satellite DNA is composed of repeats of 14–500 bp in tandem arrays 20–100 kb long. In situ hybridization studies with metaphase chromosomes have localized this simple-sequence DNA to specific chromosomal regions. Much of this DNA lies near centromeres, the discrete chromosomal regions that attach to spindle microtubules during mitosis and meiosis (Figure 8-6). Experiments in the fission yeast S. pombe indicate that these sequences are required to form a specialized chromatin structure called centromeric heterochromatin, necessary for the proper segregation of chromosomes to daughter cells during mitosis. Simple-sequence DNA is also found in long tandem repeats at the ends of chromosomes, the telomeres, where it functions to maintain those chromosome ends and prevent their joining to the ends of other DNA molecules, as discussed further in the last section of this chapter.