The TATA Box, Initiators, and CpG Islands Function as Promoters in Eukaryotic DNA
Several different types of DNA sequences can function as promoters for RNA polymerase II, telling the polymerase where to initiate transcription of an RNA complementary to the template strand of a double-stranded DNA molecule. These sequences include TATA boxes, initiators, and CpG islands.
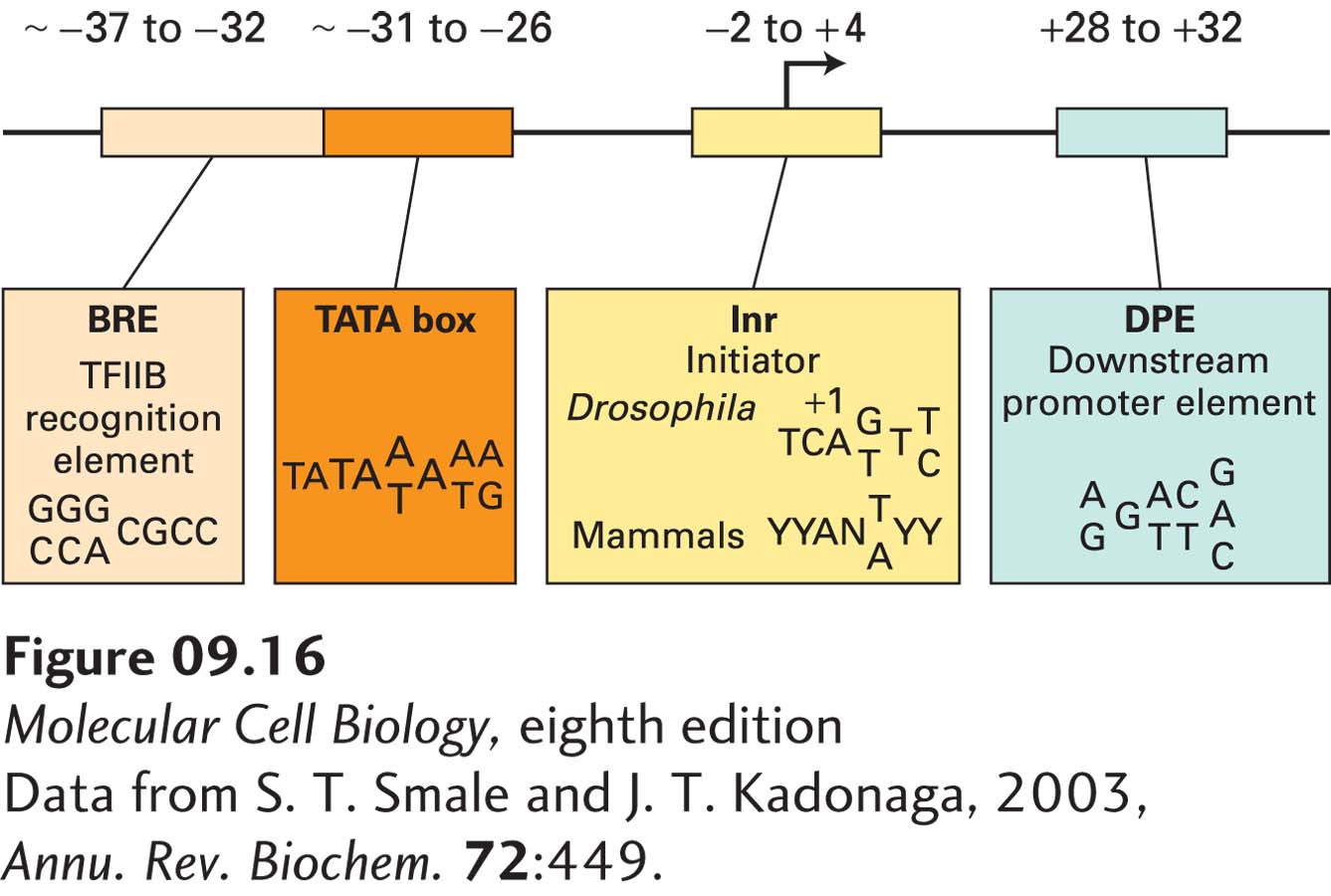
TATA Boxes The first genes to be sequenced and studied through in vitro transcription systems were viral genes and cellular protein-coding genes that are very actively transcribed, either at particular times of the cell cycle or in specific differentiated cell types. In all these highly transcribed genes, a conserved sequence called the TATA box was found about 26–31 bp upstream of the transcription start site (Figure 9-16). Mutagenesis studies have shown that a single-base change in this nucleotide sequence drastically decreases in vitro transcription of the gene adjacent to it. If the base pairs between the TATA box and the normal transcription start site are deleted, transcription of the altered, shortened template begins at a new site about 25 bp downstream from the TATA box. Consequently, the TATA box acts similarly to an E. coli promoter to position RNA polymerase II for transcription initiation (see Figure 5-12).
[Data from S. T. Smale and J. T. Kadonaga, 2003, Annu. Rev. Biochem.72:449.]
FIGURE 9-16Core promoter elements of non-CpG island promoters in metazoans. The sequence of each element is shown with the 5′ end at the left and the 3′ end at the right. The most frequently observed bases in TATA box promoters are shown in larger font. A+1 is the base at which transcription starts, Y is a pyrimidine (C or T), N is any of the four bases.
[Data from S. T. Smale and J. T. Kadonaga, 2003, Annu. Rev. Biochem.72:449.]
Page 372
Initiator Sequences Instead of a TATA box, some eukaryotic genes contain an alternative promoter element called an initiator. Most naturally occurring initiator elements have a cytosine (C) at the −1 position and an adenine (A) residue at the transcription start site (+1). Directed mutagenesis of mammalian genes with an initiator-containing promoter revealed that the nucleotide sequence immediately surrounding the start site determines the strength of such promoters. In contrast to the conserved TATA box sequence, however, only an extremely degenerate initiator consensus sequence has been defined:
(5′) Y-Y-A+1-N-T/A-Y-Y-Y (3′)
where A+1 is the base at which transcription starts, Y is a pyrimidine (C or T), N is any of the four bases, and T/A is T or A at position +3. As we will see, other promoter elements, designated BRE and DPE (see Figure 9-16), can be bound by general transcription factors and influence promoter strength.
CpG Islands Transcription of genes with promoters containing a TATA box or initiator element begins at a well-defined initiation site. However, the transcription of most protein-coding genes in mammals (~70 percent) occurs at a lower rate than at TATA box–containing and initiator-containing promoters and begins at any of several alternative start sites within regions of about 100–1000 bp that have an unusually high frequency of CG sequences. Many such genes encode proteins that are not required in large amounts (e.g., genes encoding enzymes involved in basic metabolic processes required in all cells, often called “housekeeping genes”). These promoter regions are called CpG islands (where “p” represents the phosphate between the C and G nucleotides) because they occur relatively rarely in the genome sequences of mammals.
In mammals, most Cs followed by a G that are not associated with CpG island promoters are methylated at position 5 of the pyrimidine ring (5-methyl C, represented CMe; see Figure 2-17). CG sequences are thought to be underrepresented in mammalian genomes because spontaneous deamination of 5-methyl C generates thymidine. Over the time scale of mammalian evolution, this is thought to have led to the conversion of most CGs to TG by DNA-repair mechanisms. As a consequence, the frequency of CG in the human genome is only 21 percent of that expected if Cs were randomly followed by any base. However, the Cs in active CpG island promoters are unmethylated. Consequently, when they deaminate spontaneously, they are converted to U, a base that is recognized by DNA-repair enzymes and converted back to C. As a result, the frequency of CG sequences within CpG island promoters is close to that expected if C were followed by any of the other three nucleotides randomly.
CG-rich sequences are bound by histone octamers more weakly than CG-poor sequences because more energy is required to bend them into the small-diameter loops required to wrap around the histone octamer forming a nucleosome (see Figure 8-24). As a consequence, CpG islands coincide with nucleosome-free regions of DNA. Much remains to be learned about the molecular mechanisms that control transcription from CpG island promoters, but a current hypothesis is that the general transcription factors discussed in the next section can bind to them because CpG islands exclude nucleosomes.
Divergent Transcription from CpG Island Promoters Another remarkable feature of CpG islands is that transcription from these elements is initiated in both directions, even though only transcription of the sense strand yields an mRNA. By a mechanism(s) that remains to be fully elucidated, most RNA polymerase II molecules transcribing in the “wrong” direction—that is, transcribing the antisense strand—pause or terminate transcription about 1–3 kb from the transcription start site. This phenomenon was discovered by taking advantage of the stability conferred on the elongation complex by the RNA polymerase II clamp domain when an RNA-DNA hybrid is bound near the active site (see Figure 9-14b, c).
Nuclei were isolated from cultured human fibroblasts and incubated in a buffered solution containing salt and mild detergent, which removes RNA polymerases except for those in the process of elongation because of their stable association with template DNA. Nucleotide triphosphates were then added, with UTP replaced by bromo-UTP, containing uracil with a Br atom at position 5 on the pyrimidine ring (see Figure 2-17). The nuclei were then incubated at 30 °C long enough for about 100 nucleotides to be polymerized by the RNA polymerase II (Pol II) molecules that were in the process of elongation at the time the nuclei were isolated. RNA was then isolated, and RNA containing bromo-U was immunoprecipitated with an antibody specific for BrU-labeled RNA. Thirty-three nucleotides at the 5′ ends of these RNAs were then sequenced by massively parallel DNA sequencing (see Chapter 6) of reverse transcripts, and the sequences were mapped on the human genome.
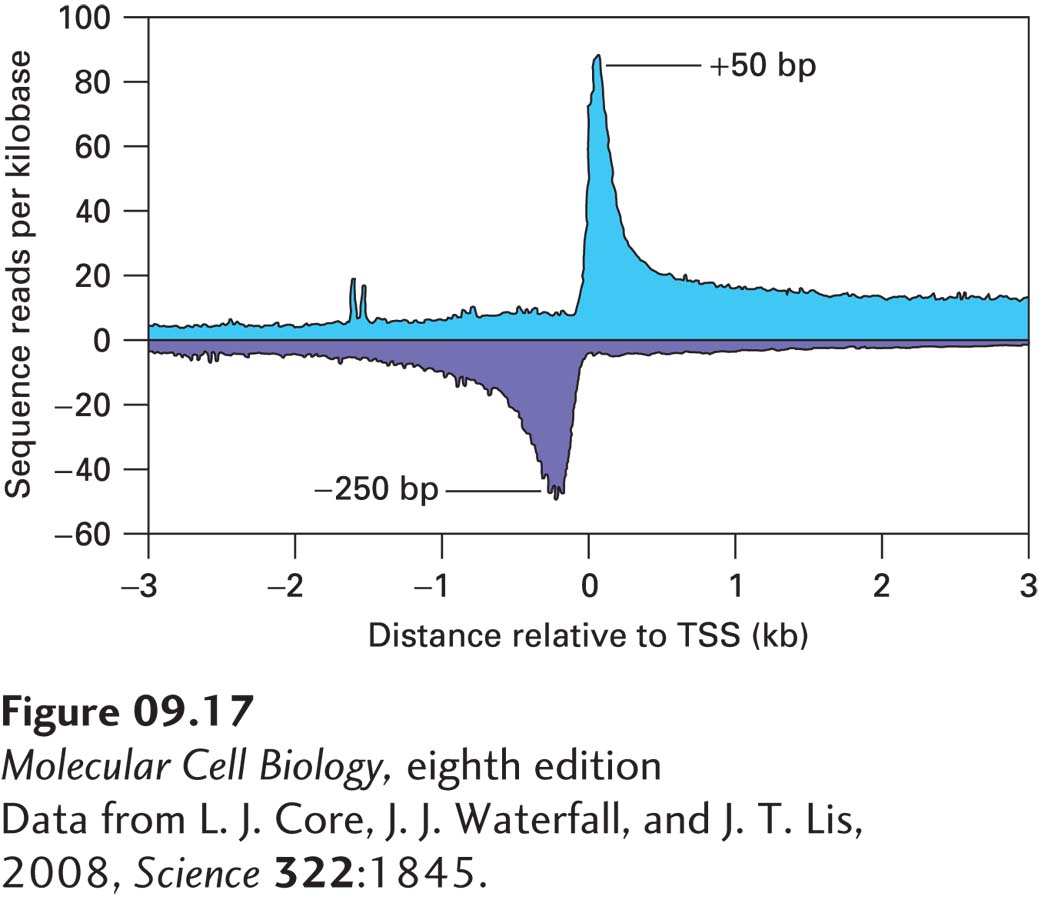
Figure 9-17 shows a plot of the number of sequence reads per kilobase of total BrU-labeled RNA relative to the major transcription start sites (TSS) of all currently known human protein-coding genes. The results show that approximately equal numbers of RNA polymerase molecules transcribed most promoters (mostly CpG island promoters) in the sense direction, toward the gene (blue, plotted upward to indicate transcription in the sense direction), and in the antisense direction, away from the gene (purple, plotted downward to represent transcription of the complementary DNA strand in the opposite, antisense direction). A peak of sense transcripts was observed at about +50 relative to the major transcription start site (TSS), indicating that Pol II pauses in the +50 to +200 region before elongating further. A peak at −250 to −500 relative to the major transcription start site of Pol II transcribing in the opposite direction was also observed, revealing paused RNA polymerase II molecules at the other ends of the nucleosome-free regions in CpG island promoters. Note that the number of sequence reads, and therefore the number of elongating polymerases, is lower for polymerases transcribing in the antisense direction more than 1 kb from the transcription start site compared with polymerases transcribing more than 1 kb from the transcription start site in the sense direction. The molecular mechanism(s) potentially accounting for this difference is presented in Figure 10-15, in which transcription termination is discussed. Note that a low number of sequence reads was also observed resulting from transcription upstream of the major transcription start sites (blue sequence reads to the left of 0 and purple sequence reads to the right of 0), indicating that there is a low level of transcription from seemingly random sites throughout the genome. These recent discoveries of divergent transcription from CpG island promoters and low-level transcription of most of the genomes of eukaryotes have been a great surprise to most researchers.
[Data from L. J. Core, J. J. Waterfall, and J. T. Lis, 2008, Science322:1845.]
EXPERIMENTAL FIGURE 9-17Analysis of elongating RNA polymerase II molecules in human fibroblasts. Nuclei from cultured fibroblasts were isolated and incubated in a buffer with a non-ionic detergent that prevents RNA polymerase II from initiating transcription. Treated nuclei were then incubated with ATP, CTP, GTP, and Br-UTP for 5 minutes at 30 °C, a time sufficient to incorporate about 100 nucleotides. RNA was then isolated and broken into fragments of about 100 nucleotides each by controlled incubation at high pH. Specific RNA oligonucleotides were ligated to the 5′ and 3′ ends of the RNA fragments, which were then subjected to reverse transcription. The resulting DNA was amplified by the polymerase chain reaction and subjected to massively parallel DNA sequencing. The sequences determined were aligned to the transcription start sites (TSS) of all known human genes, and the number of sequence reads per kilobase of total sequenced DNA was plotted for 10-bp intervals of sense transcripts (blue) and antisense transcripts (purple). See text for discussion.
[Data from L. J. Core, J. J. Waterfall, and J. T. Lis, 2008, Science322:1845.]
Page 373
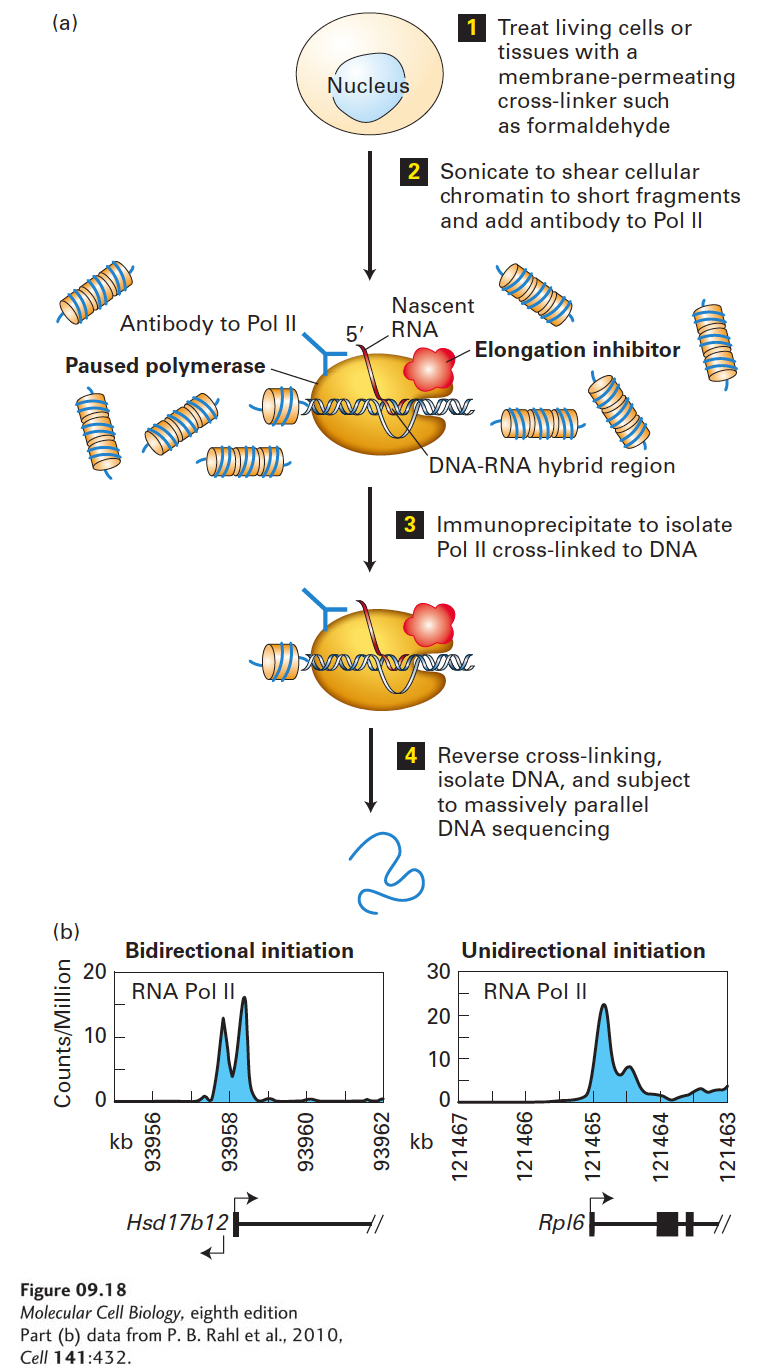
Chromatin Immunoprecipitation The technique of chromatin immunoprecipitation outlined in Figure 9-18a, using an antibody to RNA polymerase II, provided additional data supporting the occurrence of divergent transcription from most CpG island promoters in mammals. The data from this analysis are reported as the number of times a specific sequence from this region of the genome was identified per million total sequences analyzed (Figure 9-18b). At divergently transcribed genes, such as the Hsd17b12 gene encoding an enzyme involved in intermediary metabolism, two peaks of immunoprecipitated DNA were detected, corresponding to Pol II transcribing in the sense and antisense directions and then pausing. However, Pol II was detected more than 1 kb from the start site only in the sense direction. The number of counts per million from this region of the genome was very low because the gene is transcribed at low frequency. However, the number of counts per million at the transcription start site regions for both sense and antisense transcription was much higher, reflecting the fact that Pol II molecules had initiated transcription in both directions at this promoter, but paused before transcribing farther than 500 bp from the start sites in each direction. In contrast, the Rpl6 gene, encoding a large ribosomal subunit protein that was abundantly transcribed in the proliferating mouse embryonic stem cells used in the study, was transcribed almost exclusively in the sense direction. The peak in counts per million less than 250 bp from the transcription start site again results from a long pause in transcription in the promoter-proximal region before the polymerase is released to transcribe into the gene. The number of sequence counts per million more than 1 kb downstream from the transcription start site was much higher than for sense-direction transcription of the Hsd17b12 gene, reflecting the high rate of transcription of the Rpl6 gene.
[Part (b) data from P. B. Rahl et al., 2010, Cell141:432.]
EXPERIMENTAL FIGURE 9-18The chromatin immunoprecipitation technique localizes where a protein of interest associates with the genome. (a) step 1: Live cultured cells or tissues are incubated in 1 percent formaldehyde to covalently cross-link proteins to DNA and proteins to proteins. Step 2: The preparation is then subjected to sonication to solubilize chromatin and shear it into fragments of 200–500 bp of DNA. Step 3: An antibody to a protein of interest, here RNA polymerase II, is added, and DNA covalently linked to the protein of interest is immunoprecipitated. Step 4: The covalent cross-linking is then reversed and the DNA is isolated. The isolated DNA can be analyzed by PCR with primers for a sequence of interest. Alternatively, total recovered DNA can be amplified, labeled by incorporation of a fluorescently labeled nucleotide, and hybridized to a microarray (see Figure 6-27) or subjected to massively parallel DNA sequencing. See A. Hecht and M. Grunstein, 1999, Method. Enzymol.304:399. (b) Results from DNA sequencing of chromatin from mouse embryonic stem cells immunoprecipitated with antibody to RNA polymerase II are shown for a gene that is divergently transcribed (left) and a gene that is transcribed only in the sense direction (right). Data are plotted as the number of times a DNA sequence in a 50-bp interval was observed per million base pairs sequenced. The region encoding the 5′ end of the gene is shown below, with exons shown as rectangles and introns as lines.
[Part (b) data from P. B. Rahl et al., 2010, Cell141:432.]