DNA-Binding Domains Can Be Classified into Numerous Structural Types
[Data from A. K. Aggarwal et al., 1988, Science242:899, PDB ID 2ori.]
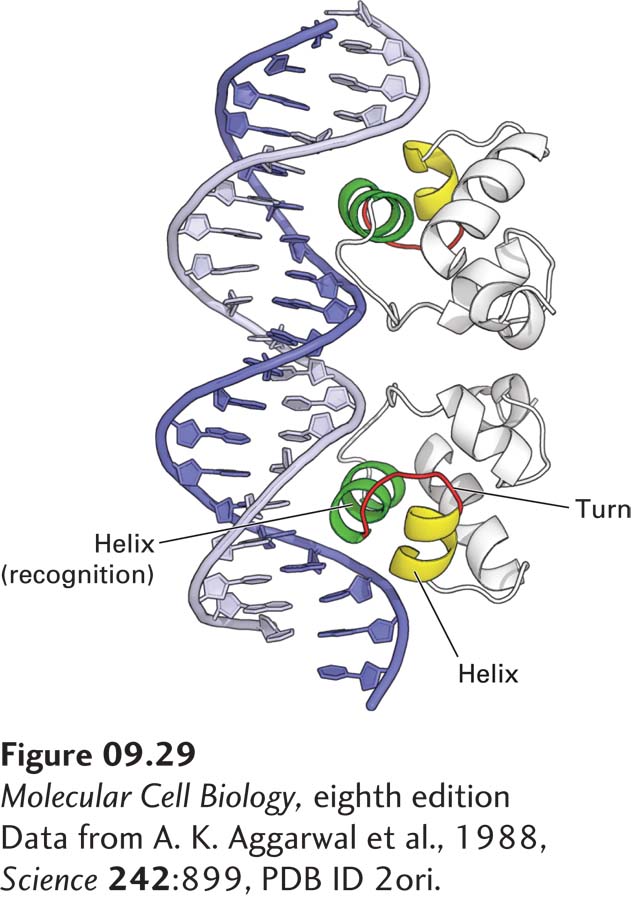
FIGURE 9-29Interaction of bacteriophage 434 repressor with DNA. Ribbon diagram of 434 repressor bound to its specific operator DNA. The recognition helices are shown in green. The α helices N-terminal to the recognition helix and the turn in the polypeptide backbone between the helices in the helix-turn-helix structural motif are shown in yellow and red, respectively. The protein interacts intimately with one side of the DNA molecule over a length of 1.5 turns.
[Data from A. K. Aggarwal et al., 1988, Science242:899, PDB ID 2ori.]
The DNA-binding domains of eukaryotic transcription factors contain a variety of structural motifs that bind specific DNA sequences. The ability of DNA-binding proteins to bind to specific DNA sequences commonly results from noncovalent interactions between atoms in an α helix in the DNA-binding domain and atoms on the edges of the bases within the major groove in the DNA. Ionic interactions between positively charged residues arginine and lysine and negatively charged phosphates in the sugar-phosphate backbone, and in some cases, interactions with atoms in the DNA minor groove, also contribute to binding.
The principles of specific protein-DNA interactions were first discovered during the study of bacterial repressors. Many bacterial repressors are dimeric proteins in which an α helix from each monomer inserts into the major groove in the DNA helix and makes multiple, specific interactions with the atoms there (Figure 9-29). This α helix is referred to as the recognition helix or sequence-reading helix because most of the amino acid side chains that contact bases in the DNA extend from this helix. The recognition helix, which protrudes from the surface of a bacterial repressor, is usually supported in the protein structure in part by hydrophobic interactions with a second α helix just N-terminal to it. This entire structural element, which is present in many bacterial repressors, is called a helix-turn-helix motif.
Many additional structural motifs that can present an α helix to the major groove of DNA are found in eukaryotic transcription factors, which are often classified according to the type of DNA-binding domain they contain. Because most of these motifs have characteristic consensus amino acid sequences, potential transcription factors can be recognized among the cDNA sequences from various tissues that have been characterized in humans and other species. Here we introduce several common classes of DNA-binding proteins whose three-dimensional structures have been determined. In all these examples, and in many other transcription factors, at least one α helix is inserted into the major groove of DNA. However, some transcription factors contain alternative structural motifs (e.g., β strands and loops; see NFAT in Figure 9-33 as an example) that interact with DNA.
Page 385
Homeodomain Proteins Many eukaryotic transcription factors that function during development contain a conserved 60-residue DNA-binding motif, called a homeodomain, that is similar to the helix-turn-helix motif of bacterial repressors. These transcription factors were first identified in Drosophila mutants in which one body part was transformed into another during development (see Figure 9-2b). The conserved homeodomain sequence has also been found in vertebrate transcription factors, including those that have similar master-control functions in human development.
Zinc-Finger Proteins A number of different eukaryotic proteins have regions that fold around a central Zn2+ ion, producing a compact domain from a relatively short length of polypeptide chain. Termed a zinc finger, this structural motif was first recognized in DNA-binding domains, but is now known to occur in other proteins that do not bind to DNA. Here we describe two of the several classes of zinc-finger motifs that have been identified in eukaryotic transcription factors.
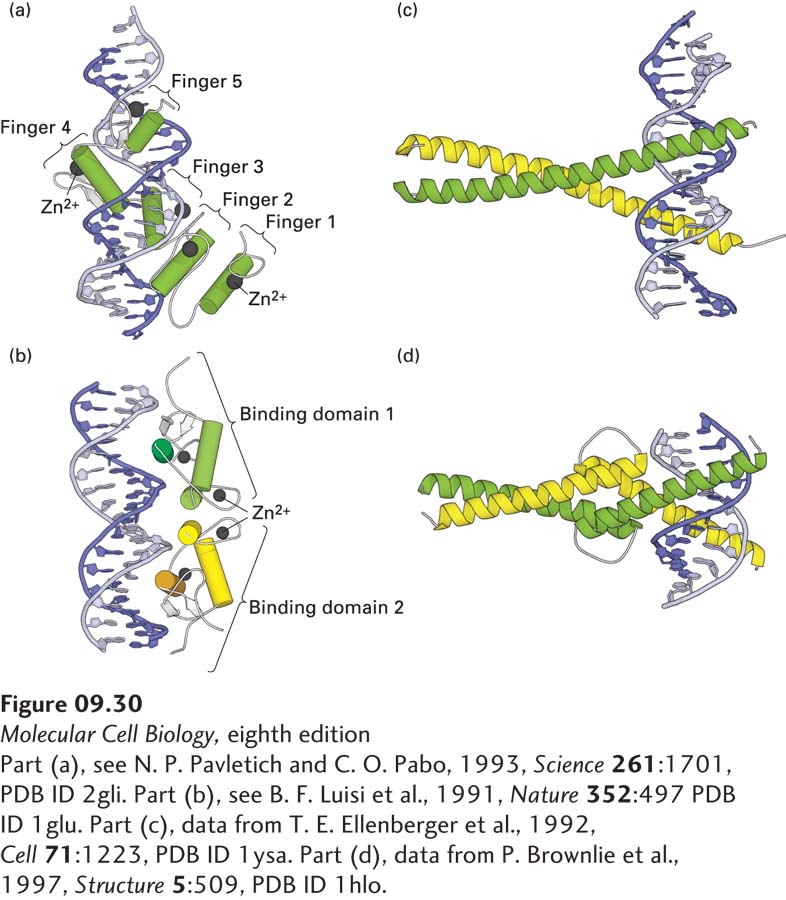
The C2H2zinc finger is the most common DNA-binding motif encoded in the human genome and the genomes of other mammals. It is also common in multicellular plants, but is not the dominant type of DNA-binding domain in plants, as it is in animals. This motif has a 23–26-residue consensus sequence containing two conserved cysteine (C) and two conserved histidine (H) residues, whose side chains bind one Zn2+ ion (see Figure 3-10c). The name “zinc finger” was coined because a two-dimensional diagram of the structure resembles a finger. When the three-dimensional structure was solved, it became clear that the binding of the Zn2+ ion by the two cysteine and two histidine residues folds the relatively short polypeptide sequence into a compact domain, which can insert its α helix into the major groove of DNA. Many transcription factors contain multiple C2H2 zinc fingers, which interact with successive groups of base pairs, within the major groove, as the protein wraps around the DNA double helix (Figure 9-30a).
[Part (a), see N. P. Pavletich and C. O. Pabo, 1993, Science261:1701, PDB ID 2gli. Part (b), see B. F. Luisi et al., 1991, Nature352:497 PDB ID 1glu. Part (c), data from T. E. Ellenberger et al., 1992, Cell71:1223, PDB ID 1ysa. Part (d), data from P. Brownlie et al., 1997, Structure5:509, PDB ID 1hlo.]
FIGURE 9-30Eukaryotic DNA-binding domains that use an α helix to interact with the major groove of specific DNA sequences. (a) The GL1 DNA-binding domain is monomeric and contains five C2H2 zinc fingers. The α helices are shown as cylinders, the Zn2+ ions as spheres. Finger 1 does not interact with DNA, whereas the other four fingers do. (b) The glucocorticoid receptor is a homodimeric C4 zinc-finger protein, one monomer in green, one in yellow. The α helices are shown as cylinders, the β strands as white arrows, the Zn2+ ions as spheres. Two α helices (darker shade), one in each monomer, interact with the DNA. Like all C4 zinc-finger homodimers, this transcription factor has twofold rotational symmetry. (c) In leucine-zipper proteins, basic residues in the extended α-helical regions of the monomers interact with the DNA backbone at adjacent sites in the major groove. The coiled-coil dimerization domain is stabilized by hydrophobic interactions between the monomers. (d) In bHLH proteins, the DNA-binding helices at the right (N-termini of the monomers) are separated by nonhelical loops from a leucine zipper–like region containing a coiled-coil dimerization domain.
[Part (a), see N. P. Pavletich and C. O. Pabo, 1993, Science261:1701, PDB ID 2gli. Part (b), see B. F. Luisi et al., 1991, Nature352:497 PDB ID 1glu. Part (c), data from T. E. Ellenberger et al., 1992, Cell71:1223, PDB ID 1ysa. Part (d), data from P. Brownlie et al., 1997, Structure5:509, PDB ID 1hlo.]
A second type of zinc-finger structure, designated the C4zinc finger (because it has four conserved cysteines in contact with the Zn2+), is found in some 50 human transcription factors. The first members of this class were identified as specific intracellular high-affinity binding proteins, or “receptors,” for steroid hormones, which led to the name steroid receptor superfamily. Because similar intracellular receptors for nonsteroid hormones were subsequently found, these transcription factors are now commonly called nuclear receptors. The characteristic feature of C4 zinc fingers is the presence of two groups of four critical cysteines, one toward each end of the 55–56-residue domain. Although the C4 zinc finger was initially named by analogy with the C2H2 zinc finger, the three-dimensional structures of proteins containing these DNA-binding motifs were later found to be quite distinct. A particularly important difference between the two is that C2H2 zinc-finger proteins generally contain three or more repeating finger units and bind as monomers, whereas C4 zinc-finger proteins generally contain only two finger units and generally bind to DNA as homodimers or heterodimers. Homodimers of C4 zinc-finger DNA-binding domains have twofold rotational symmetry (Figure 9-30b). Consequently, homodimeric nuclear receptors bind to consensus DNA sequences that are inverted repeats.
Page 386
Leucine-Zipper Proteins Another structural motif present in the DNA-binding domains of a large class of transcription factors contains the hydrophobic amino acid leucine at every seventh position in the sequence. These proteins bind to DNA as dimers, and mutagenesis of the leucines showed that they were required for dimerization. Consequently, the name leucine zipper was coined to denote this structural motif of a coiled coil of two α helixes.
The DNA-binding domain of the yeast Gcn4 transcription factor mentioned earlier is a leucine-zipper domain. X-ray crystallographic analysis of complexes between DNA and the Gcn4 DNA-binding domain has shown that the dimeric protein contains two extended α helices that “grip” the DNA molecule, much like a pair of scissors, at two adjacent sites in the major groove separated by about half a turn of the double helix (Figure 9-30c). The portions of the α helices contacting the DNA include positively charged (basic) residues that interact with phosphates in the DNA backbone and additional residues that interact with specific bases in the major groove.
Gcn4 forms dimers via hydrophobic interactions between the C-terminal regions of the α helices, forming a coiled-coil structure. This structure is common in proteins containing amphipathic α helices in which hydrophobic amino acid residues are regularly spaced alternately three or four positions apart in the sequence, forming a stripe down one side of the α helix. These hydrophobic stripes make up the interacting surfaces between the α-helical monomers in a coiled-coil dimer (see Figure 3-10a).
Although the first leucine-zipper transcription factors to be analyzed contained leucine residues at every seventh position in the dimerization region, additional DNA-binding proteins containing other hydrophobic amino acids in these positions were subsequently identified. Like leucine-zipper proteins, they form dimers containing a C-terminal coiled-coil dimerization region and an N-terminal DNA-binding domain. The term basic zipper (bZIP) is now frequently used to refer to all proteins with these common structural features. Many basic-zipper transcription factors are heterodimers of two different polypeptide chains, each containing one basic-zipper domain.
Basic Helix-Loop-Helix (bHLH) Proteins The DNA-binding domain of another class of dimeric transcription factors contains a structural motif that is very similar to the basic-zipper motif except that a nonhelical loop of the polypeptide chain separates two α-helical regions in each monomer (Figure 9-30d). Termed a basic helix-loop-helix (bHLH), this motif was predicted from the amino acid sequences of these proteins, which contain an N-terminal α helix with basic residues that interact with DNA, a middle loop region, and a C-terminal region, with hydrophobic amino acids spaced at intervals characteristic of an amphipathic α helix, that dimerizes into a coiled coil. As with basic-zipper proteins, different bHLH proteins can form heterodimers.