Point mutations are changes in a single nucleotide.
Most DNA damage or errors in replication are immediately removed or corrected by specialized enzymes in the cell. (Some examples of DNA repair will be discussed in section 14.4.) We have already seen one example of DNA repair, the proofreading function of DNA polymerase during the process of replication, which acts to remove an incorrect nucleotide from the 3′ end of growing DNA strand (see Fig. 12.7). Damage that is corrected is not regarded as a mutation because the DNA sequence is immediately restored to its original state.
If a change in DNA is to become stable and subsequently inherited through mitotic or meiotic cell divisions, it must escape correction by the DNA repair systems. The example in Fig. 14.6 shows how a mutation incorporated during replication can become a permanent change to the genome. If, during replication, DNA polymerase mistakenly adds a G (instead of a T) to a growing strand across from an A and its proofreading function does not catch the error, the result is a T–G mismatch in the double-stranded DNA. At the next replication the G in the new template strand specifies a C in the daughter strand, with the result that the daughter DNA duplex has a perfectly matched C–G base pair. From this point forward, the DNA molecule containing the mutant C–G base pair will replicate as faithfully as the original molecule bearing the nonmutant T–A base pair. A mutation in which one base pair (in this example, T–A) is replaced by a different base pair (in this example, C–G) is called a nucleotide substitution or point mutation. This is the most frequent type of mutation.
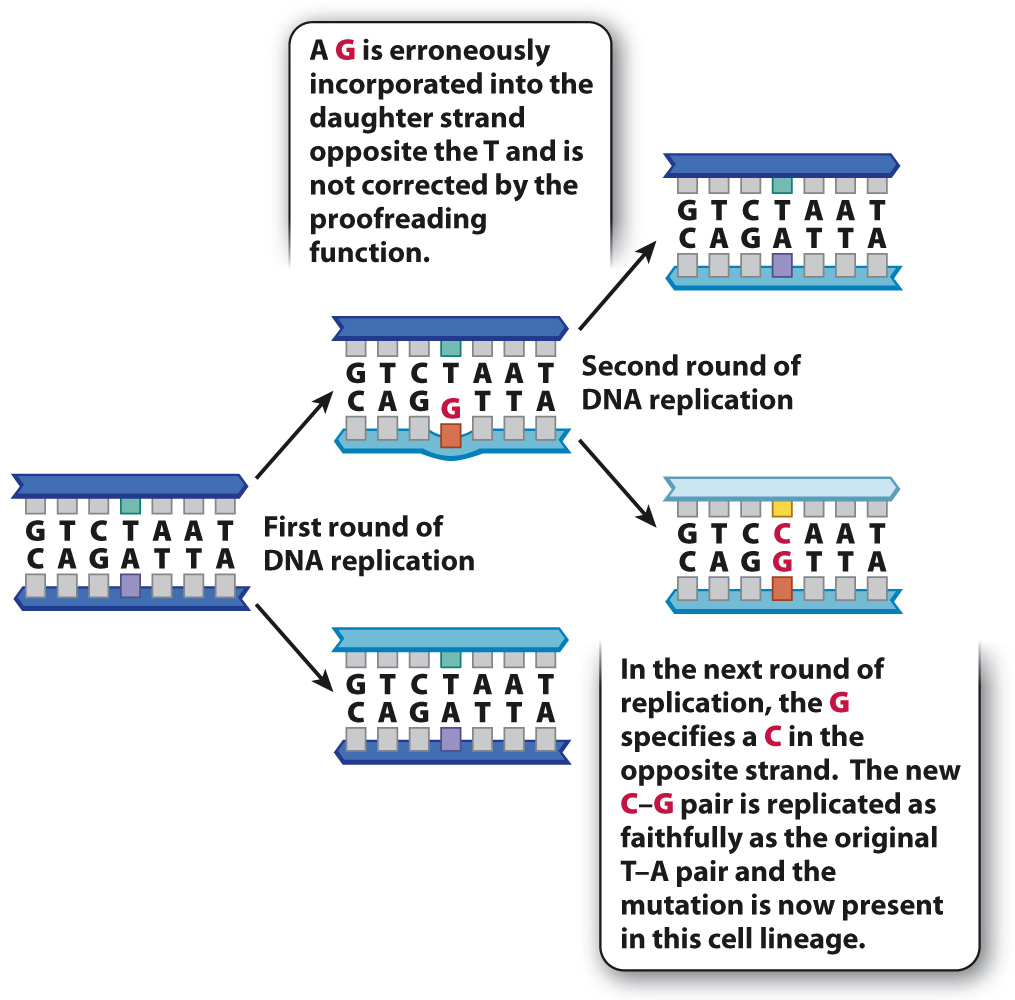
FIG. 14.6 A point mutation. A point mutation is a change in a single nucleotide.
The effect of a point mutation depends in part on where in the genome it occurs. In many multicellular eukaryotes, including humans, the vast majority of DNA in the genome does not code for protein or RNA (Chapter 13). Most of the sequences in noncoding DNA have no known function, which may explain why many mutations in noncoding DNA have no detectable effects on the organism.
On the other hand, mutations in coding sequences do have predictable consequences in an organism. Fig. 14.7 shows an example in the human DNA sequence coding for the amino acid chain of β-(beta-)globin, a subunit of the protein hemoglobin, which carries oxygen in red blood cells. Fig. 14.7a shows a small part of the nonmutant DNA sequence, transcription and translation of which results in incorporation of the amino acids Pro–Glu–Glu in the β-globin polypeptide.
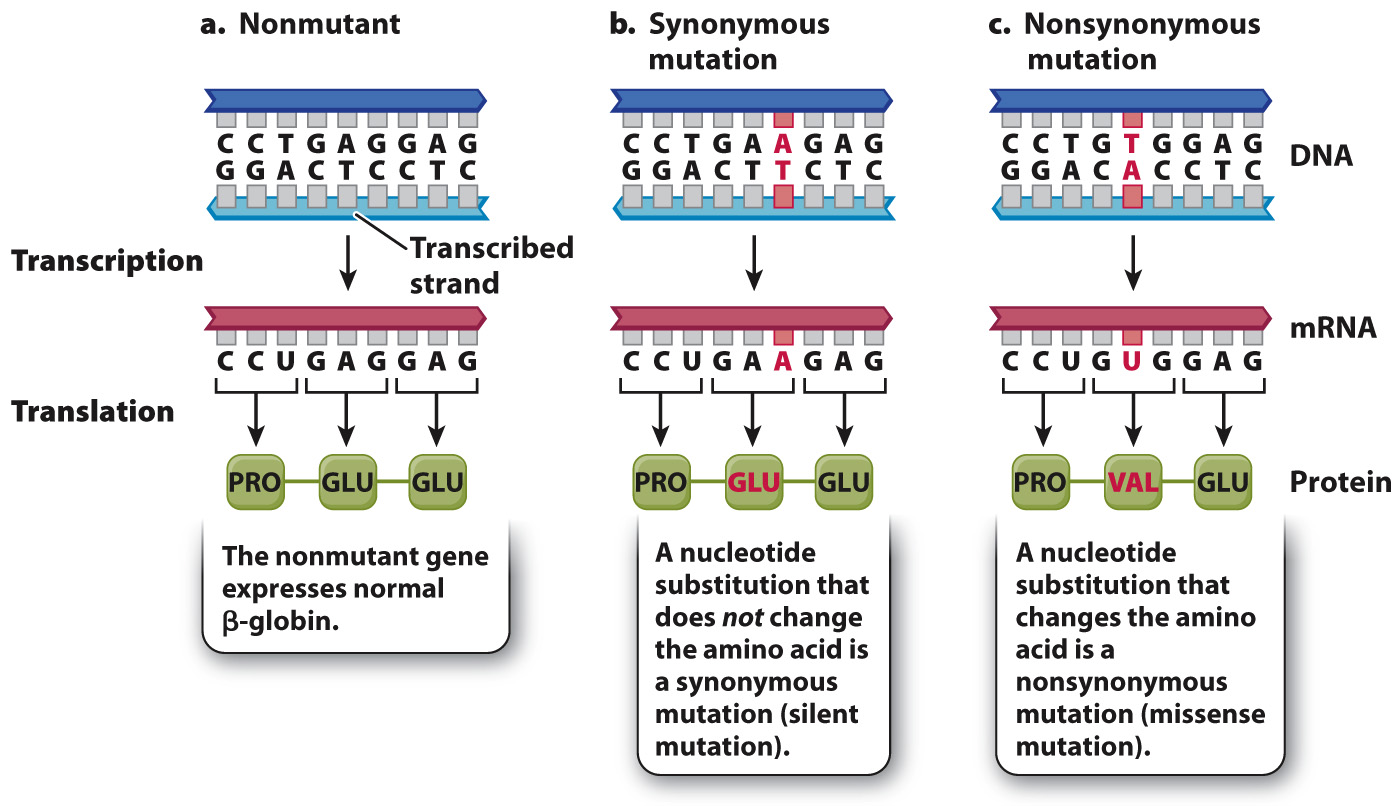
FIG. 14.7 Synonymous and nonsynonymous mutations. Synonymous mutations do not change the amino acid sequence of the resulting protein. Nonsynonymous mutations change the amino acid sequence.
Page 298
Fig. 14.7b shows an example of a harmless nucleotide substitution in this coding sequence. The mutation consists of the substitution of an A–T base pair for the normal G–C base pair. In the mRNA, the mutation changes the normal GAG codon into the mutant GAA codon. But GAG and GAA both code for the same amino acid, glutamic acid (Glu). In other words, they are synonymous codons, and so the resulting amino acid sequences are the same: Pro–Glu–Glu. Such mutations are called synonymous (silent) mutations. This example is typical in that the synonymous codons differ at their third position (the 3′ end of the codon). A quick look at the genetic code (see Table 4.1) shows that most amino acids can be specified by synonymous codons, and that in most cases the synonymous codons differ in the identity of the nucleotide at the third position.
On the other hand, a point mutation in coding sequences can sometimes have a drastic effect on an organism. Fig. 14.7c shows such an example. In this case, a point mutation substitutes the first A–T base pair for a T–A base pair. The result is a change in the mRNA from GAG, which specifies Glu (glutamic acid), into GUG, which specifies Val (valine). The resulting protein therefore contains the amino acids Pro–Val–Glu instead of Pro–Glu–Glu. In other words, the nucleotide substitution results in an amino acid replacement. Point mutations that cause amino acid replacements are called nonsynonymous (missense) mutations.
Since the complete β-globin chain consists of 146 amino acids, it may seem that a change in only one amino acid would have little effect. But the change in even a single amino acid can affect the three-dimensional structure of a protein, and therefore change its ability to function. Individuals who inherit two copies of the mutant β-globin gene that specifies the Glu-to-Val replacement have a disease known as sickle-cell anemia. In this condition, the hemoglobin molecules tend to crystallize when exposed to lower than normal levels of oxygen. The crystallization of hemoglobin causes the cell to collapse from its normal ellipsoidal shape into the shape of a half-moon, or “sickle.” In this form, the red blood cell is unable to carry the normal amount of oxygen. More important, the sickled cells tend to block tiny capillary vessels, interrupting the blood supply to vital tissues and organs and resulting in severe pain and fever.
Fig. 14.8 shows a third way that a point mutation can affect a protein, one that nearly always has severe effects. This is a nonsense mutation, which creates a stop codon that terminates translation. In the example in Fig. 14.8, the mutation creates a UAG codon in the mRNA. Because UAG is a translational stop codon, the resulting polypeptide terminates after Pro. Polypeptides that are truncated are nearly always nonfunctional. They are also unstable and are quickly destroyed. Eukaryotic cells have mechanisms to destroy mRNA molecules that contain premature stop codons.
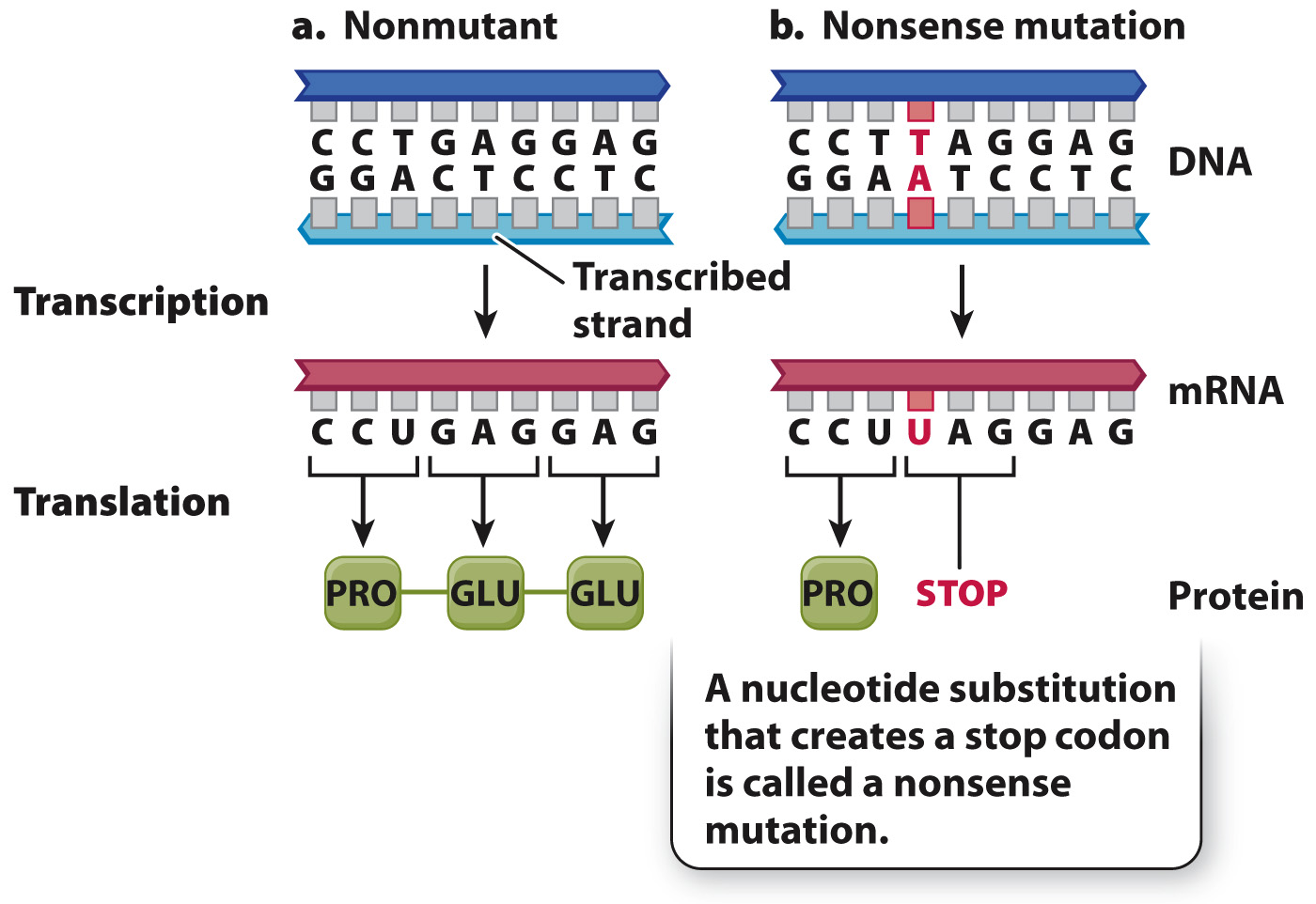
FIG. 14.8 A nonsense mutation. A nonsense mutation can change an amino acid to a stop codon, resulting in a shortened and unstable protein.