RNA processing is also important in gene regulation.
A great deal happens in the nucleus after transcription takes place. The initial transcript, called the primary transcript, undergoes several types of modification, collectively called RNA processing (Chapter 3), that includes the 5′ end and a string of tens to hundreds of adenosine nucleotides to the 3′ end to form the poly(A) tail. These modifications are necessary for the RNA molecule to be transported to the cytoplasm and recognized by the translational machinery. The poly(A) tail also helps to determine how long the RNA will persist in the cytoplasm before being degraded. RNA processing is therefore an important point where gene regulation can occur (see Fig. 19.1c).
In eukaryotes, the primary transcript of many protein-
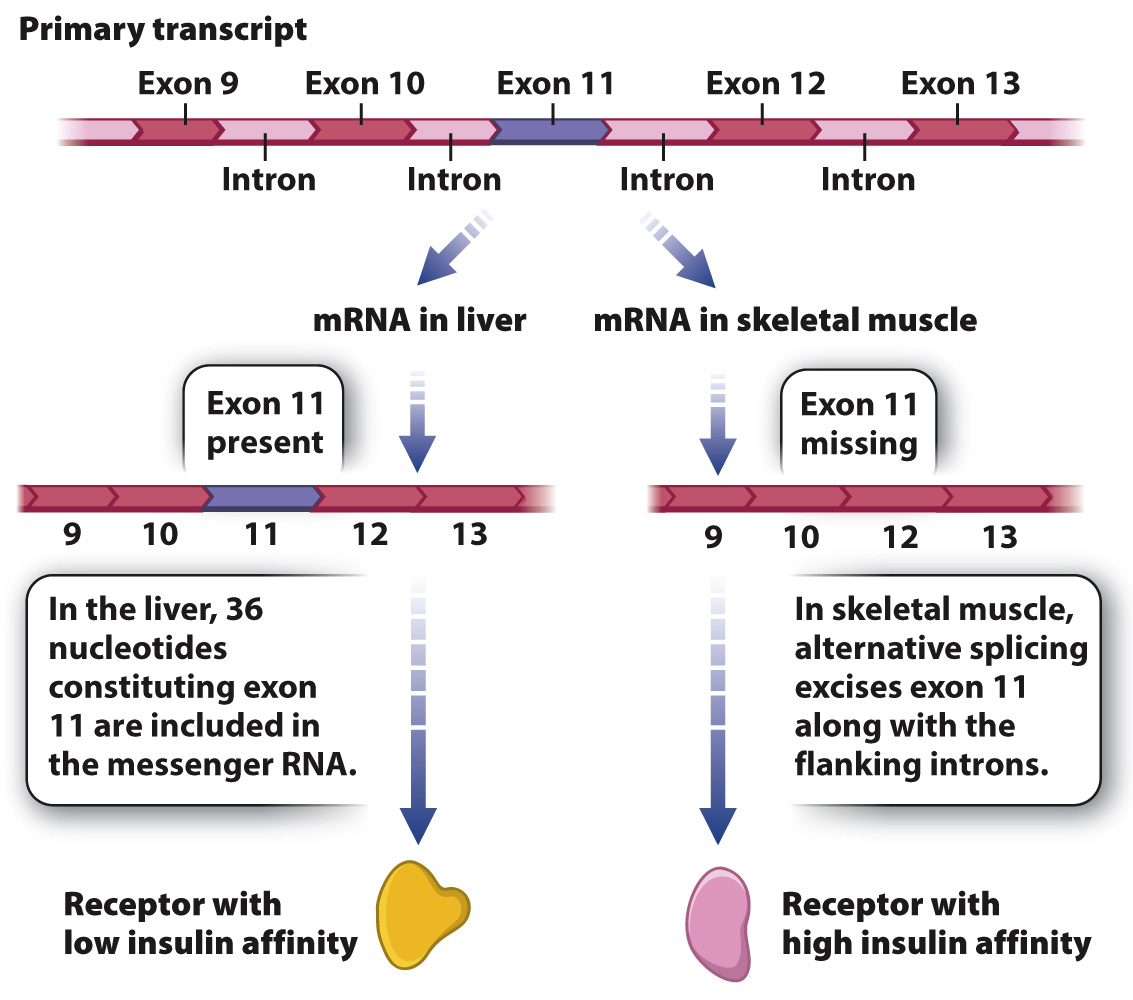
RNA splicing provides an opportunity for regulating gene expression because the same primary transcript can be spliced in different ways to yield different proteins in a process called alternative splicing. This process takes place because what the spliceosome—
Fig. 19.7 shows the primary transcript of a gene encoding an insulin receptor found in humans and other mammals. During RNA splicing in liver cells, exon 11 is included in the messenger RNA, and the insulin receptor produced from this messenger RNA has low affinity for insulin. In contrast, in cells of skeletal muscle, the 36 nucleotides of exon 11 are spliced out of the primary transcript along with the flanking introns. The resulting protein is 12 amino acids shorter, and this form of the insulin receptor has high affinity for insulin. The different forms of the protein are important: The higher sensitivity of muscle cells to insulin enables them to absorb enough glucose to fulfill their energy needs.
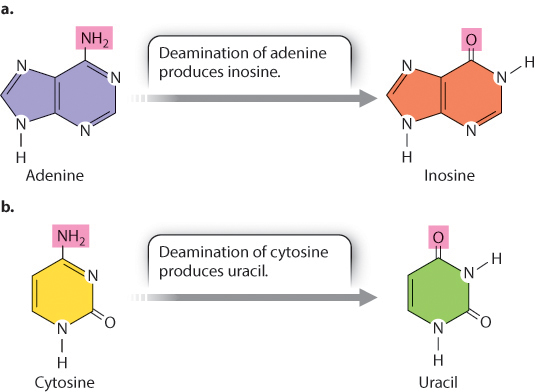
Some RNA molecules can become a substrate for enzymes that modify particular bases in the RNA, thereby changing its sequence and what it codes for. This process is known as RNA editing (Fig. 19.8). One type of editing enzyme (Fig. 19.8a) removes the amino group (–NH2) from adenosine and converts it to inosine, a base that in translation functions like guanosine. Another enzyme (Fig. 19.8b) removes the amino group from cytosine and converts it to uracil. In the human genome, hundreds if not thousands of transcripts undergo RNA editing. In many cases, not all copies of the transcript are edited, and some copies may be edited more extensively than others. The result is that transcripts from the same gene can produce multiple types of proteins even in a single cell.
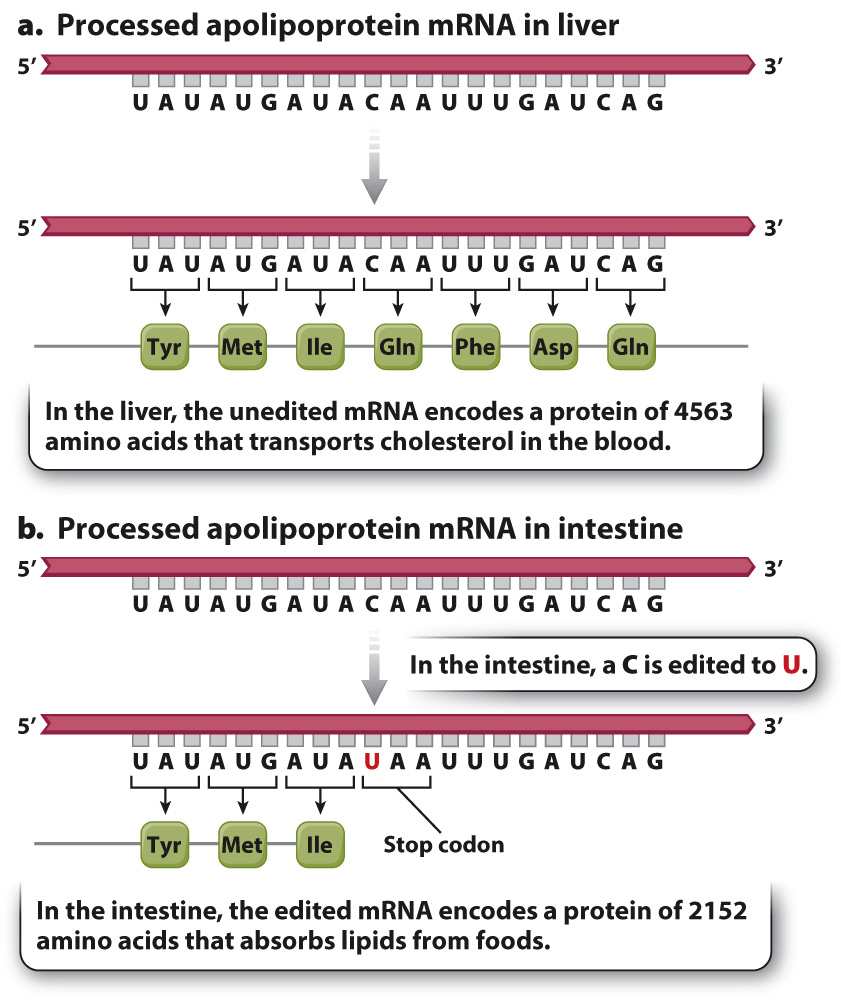
Transcripts from the same gene may undergo different editing in different cell types. An example of tissue-