19.3 Perceptual Organization
19-
It’s one thing to understand how we see colors and shapes. But how do we organize and interpret those sights so that they become meaningful perceptions—
Early in the twentieth century, a group of German psychologists noticed that when given a cluster of sensations, people tend to organize them into a gestalt, a German word meaning a “form” or a “whole.” As we look straight ahead, we cannot separate the perceived scene into our left and right fields of view. It is, at every moment, one whole, seamless scene. Our conscious perception is an integrated whole.
Consider FIGURE 19.13: The individual elements of this figure, called a Necker cube, are really nothing but eight blue circles, each containing three converging white lines. When we view these elements all together, however, we see a cube that sometimes reverses direction. This phenomenon nicely illustrates a favorite saying of Gestalt psychologists: In perception, the whole may exceed the sum of its parts, rather as water differs from its hydrogen and oxygen parts.

A Necker cube What do you see: circles with white lines, or a cube? If you stare at the cube, you may notice that it reverses location, moving the tiny X in the center from the front edge to the back. At times, the cube may seem to float forward, with circles behind it. At other times, the circles may become holes through which the cube appears, as though it were floating behind them. There is far more to perception than meets the eye. (From Bradley et al., 1976.)
Over the years, the Gestalt psychologists demonstrated many principles we use to organize our sensations into perceptions (Wagemans et al., 2012a,b). Underlying all of them is a fundamental truth: Our brain does more than register information about the world. Perception is not just opening a shutter and letting a picture print itself on the brain. We filter incoming information and construct perceptions. Mind matters.
Form Perception
Imagine designing a video-
Figure and GroundTo start with, the video-

Reversible figure and ground
248
GroupingHaving discriminated figure from ground, we (and our video-
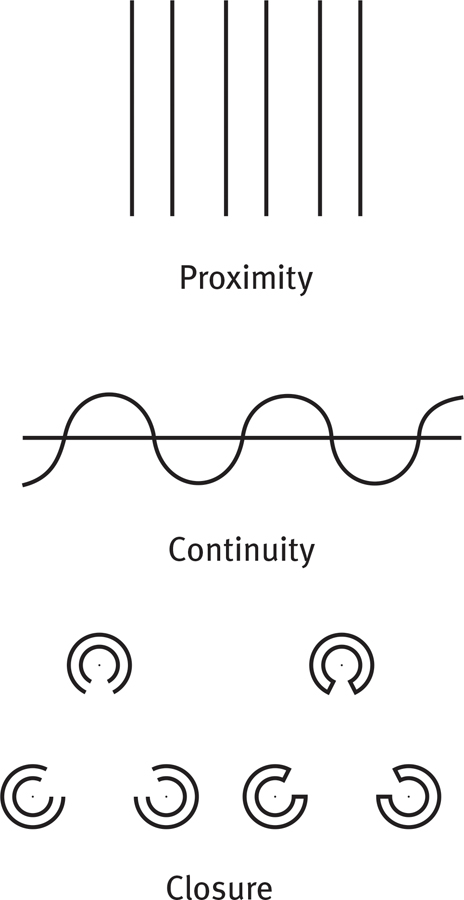
- Proximity We group nearby figures together. We see not six separate lines, but three sets of two lines.
- Continuity We perceive smooth, continuous patterns rather than discontinuous ones. This pattern could be a series of alternating semicircles, but we perceive it as two continuous lines—
one wavy, one straight. - Closure We fill in gaps to create a complete, whole object. Thus we assume that the circles on the left are complete but partially blocked by the (illusory) triangle. Add nothing more than little line segments to close off the circles and your brain stops constructing a triangle.
Such principles usually help us construct reality. Sometimes, however, they lead us astray, as when we look at the doghouse in FIGURE 19.15.

Grouping principles What’s the secret to this impossible doghouse? You probably perceive this doghouse as a gestalt—
RETRIEVAL PRACTICE
- In terms of perception, a band’s lead singer would be considered _____________ (figure/ground), and the other musicians would be considered ____________ (figure/ground).
figure; ground
- What do we mean when we say that, in perception, the whole may exceed the sum of its parts?
Gestalt psychologists used this saying to describe our perceptual tendency to organize clusters of sensations into meaningful forms or coherent groups.
249
Depth Perception
19-
From the two-
Back in their Cornell University laboratory, Gibson and Walk placed 6-

Visual cliff Eleanor Gibson and Richard Walk devised this miniature cliff with a glass-
Had they learned to perceive depth? Learning seems to be part of the answer because crawling, no matter when it begins, seems to increase infants’ wariness of heights (Campos et al., 1992). As infants become mobile, their experience leads them to fear heights (Adolph et al., 2014).

How do we do it? How do we transform two differing two-
Binocular CuesTry this: With both eyes open, hold two pens or pencils in front of you and touch their tips together. Now do so with one eye closed. With one eye, the task becomes noticeably more difficult, demonstrating the importance of binocular cues in judging the distance of nearby objects. Two eyes are better than one.
Because your eyes are about 2½ inches apart, your retinas receive slightly different images of the world. By comparing these two images, your brain can judge how close an object is to you. The greater the retinal disparity, or difference between the two images, the closer the object. Try it. Hold your two index fingers, with the tips about half an inch apart, directly in front of your nose, and your retinas will receive quite different views. If you close one eye and then the other, you can see the difference. (Bring your fingers close and you can create a finger sausage, as in FIGURE 19.17.) At a greater distance—
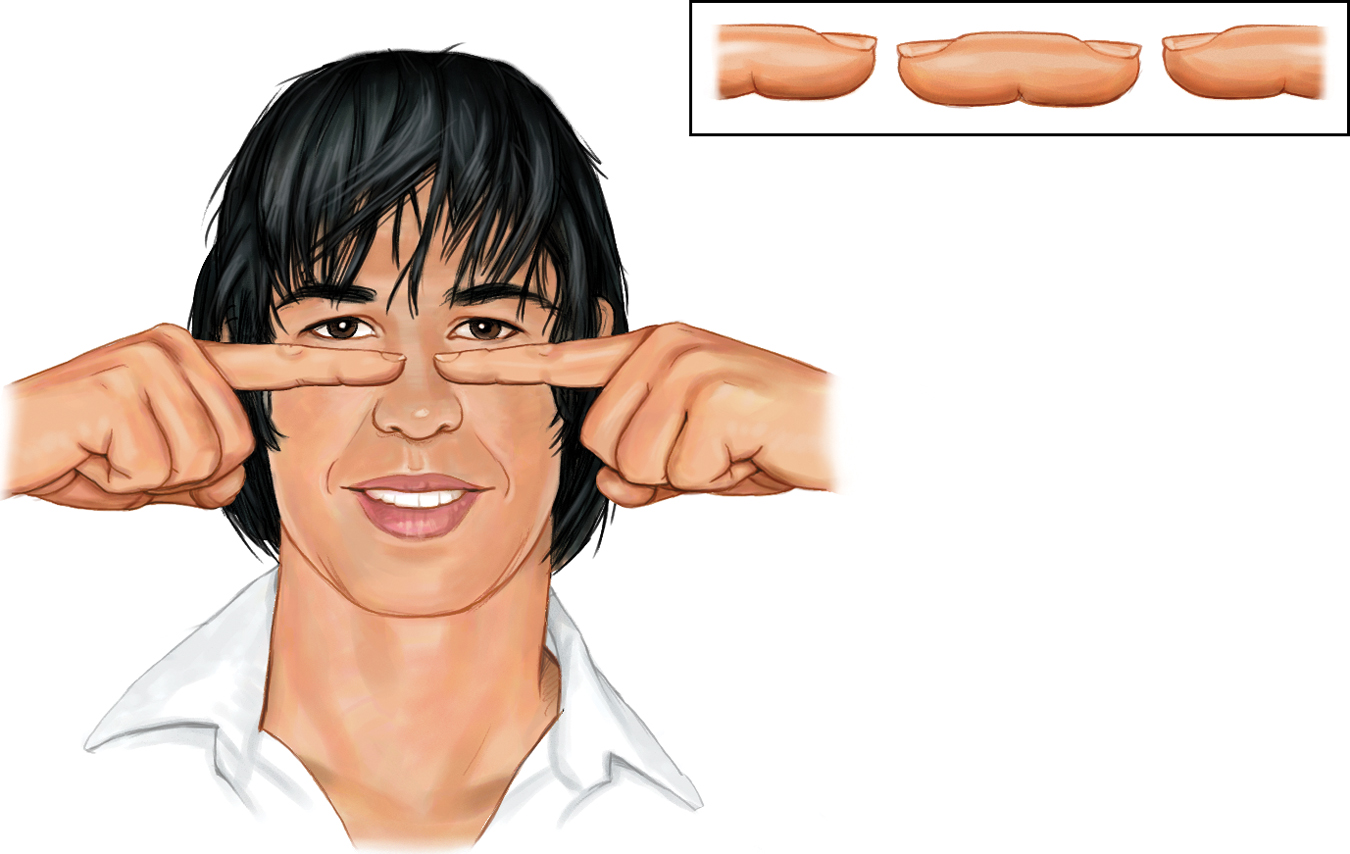
The floating finger sausage Hold your two index fingers about 5 inches in front of your eyes, with their tips half an inch apart. Now look beyond them and note the weird result. Move your fingers out farther and the retinal disparity—
250
Carnivorous animals, including humans, have eyes that enable forward focus on prey and offer binocular vision-enhanced depth perception. Grazing herbivores, such as horses and sheep, typically have eyes on the sides of their skull. Although lacking binocular depth perception, they have sweeping peripheral vision.
We could easily build this feature into our video-
 For animated demonstrations and explanations of these cues, visit LaunchPad’s Concept Practice: Depth Cues.
For animated demonstrations and explanations of these cues, visit LaunchPad’s Concept Practice: Depth Cues.
Monocular CuesHow do we judge whether a person is 10 or 100 meters away? Retinal disparity won’t help us here, because there won’t be much difference between the images cast on our right and left retinas. At such distances, we depend on monocular cues (depth cues available to each eye separately). See FIGURE 19.18 for some examples.

Monocular depth cues
RETRIEVAL PRACTICE
- How do we normally perceive depth?
We are normally able to perceive depth thanks to (1) binocular cues (which are based on our retinal disparity), and (2) monocular cues (which include relative height, relative size, interposition, linear perspective, light and shadow, and relative motion).
251
Motion Perception
Imagine that you could perceive the world as having color, form, and depth but that you could not see motion. Not only would you be unable to bike or drive, you would have trouble writing, eating, and walking.
Normally your brain computes motion based partly on its assumption that shrinking objects are retreating (not getting smaller) and enlarging objects are approaching. But you are imperfect at motion perception. In young children, this ability to correctly perceive approaching (and enlarging) vehicles is not yet fully developed, which puts them at risk for pedestrian accidents (Wann et al., 2011). But it’s not just children who have occasional difficulties with motion perception. Our adult brains are sometimes tricked into believing what they are not seeing. When large and small objects move at the same speed, the large objects appear to move more slowly. Thus, trains seem to move slower than cars, and jumbo jets seem to land more slowly than little jets.
“From there to here, from here to there, funny things are everywhere.”
Dr. Seuss, One Fish, Two Fish, Red Fish, Blue Fish, 1960
Our brain also perceives a rapid series of slightly varying images as continuous movement (a phenomenon called stroboscopic movement). As film animators know well, a superfast slide show of 24 still pictures a second will create an illusion of movement. We construct that motion in our heads, just as we construct movement in blinking marquees and holiday lights. We perceive two adjacent stationary lights blinking on and off in quick succession as one single light moving back and forth. Lighted signs exploit this phi phenomenon with a succession of lights that creates the impression of, say, a moving arrow.
Perceptual Constancy
19-
So far, we have noted that our video-
“Sometimes I wonder: Why is that Frisbee getting bigger? And then it hits me.”
Anonymous
Color and Brightness ConstanciesOur experience of color depends on an object’s context. This would be clear if you viewed an isolated tomato through a paper tube over the course of a day. The tomato’s color would seem to change as the light—
Though we take color constancy for granted, this ability is truly remarkable. A blue poker chip under indoor lighting reflects wavelengths that match those reflected by a sunlit gold chip (Jameson, 1985). Yet bring a bluebird indoors and it won’t look like a goldfinch. The color is not in the bird’s feathers. You and I see color thanks to our brain’s computations of the light reflected by an object relative to the objects surrounding it.
FIGURE 19.20 dramatically illustrates the ability of a blue object to appear very different in three different contexts. Yet we have no trouble seeing these disks as blue. Nor does knowing the truth—

The solution Another view of the impossible doghouse in Figure 19.15 reveals the secrets of this illusion. From the photo angle in Figure 19.15, the grouping principle of closure leads us to perceive the boards as continuous.
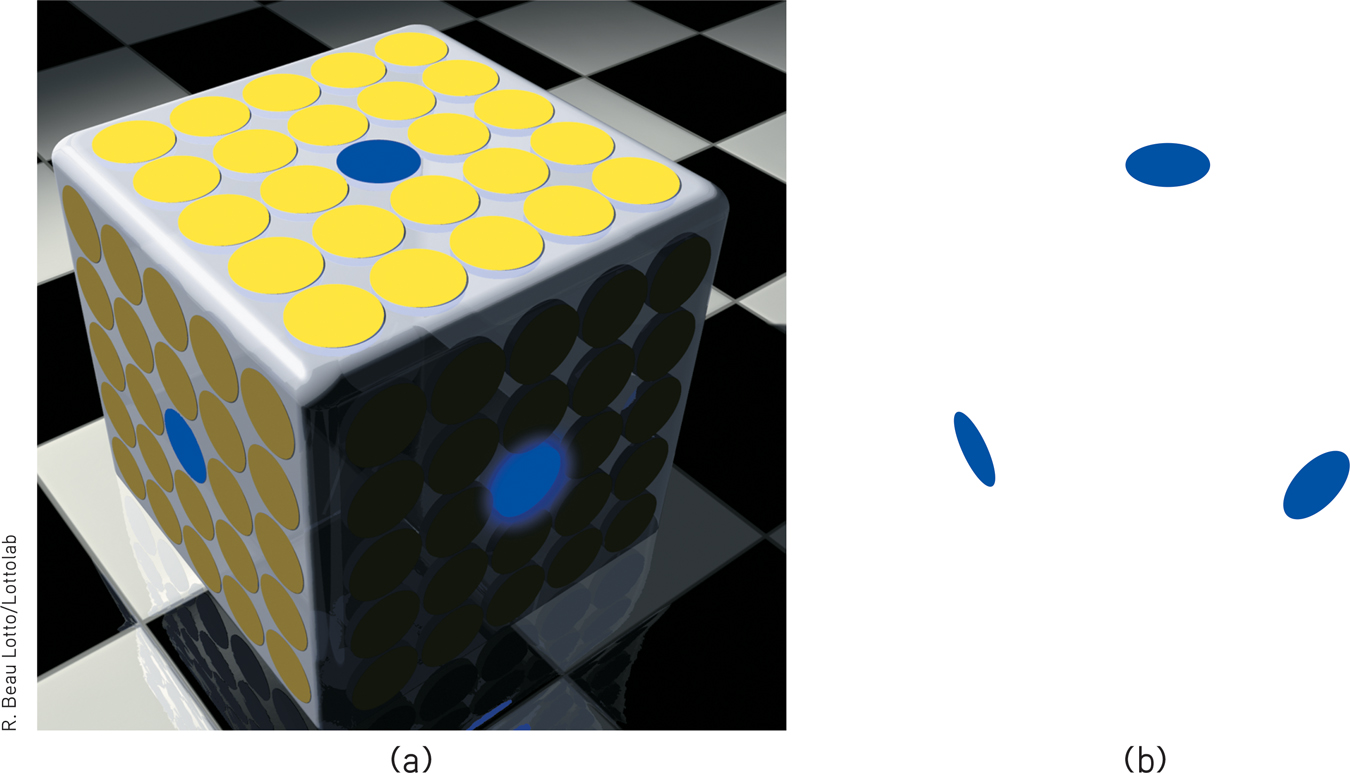
Color depends on context (a) Believe it or not, these three blue disks are identical in color. (b) Remove the surrounding context and see what results.
Brightness constancy (also called lightness constancy) similarly depends on context. We perceive an object as having a constant brightness even while its illumination varies. This perception of constancy depends on relative luminance—the amount of light an object reflects relative to its surroundings (FIGURE 19.21). White paper reflects 90 percent of the light falling on it; black paper, only 10 percent. Although a black paper viewed in sunlight may reflect 100 times more light than does a white paper viewed indoors, it will still look black (McBurney & Collings, 1984). But if you view sunlit black paper through a narrow tube so nothing else is visible, it may look gray, because in bright sunshine it reflects a fair amount of light. View it without the tube and it is again black, because it reflects much less light than the objects around it.

Relative luminance Because of its surrounding context, we perceive Square A as lighter than Square B. But believe it or not, they are identical. To channel comedian Richard Pryor, “Who you gonna believe: me, or your lying eyes?” If you believe your lying eyes—
252
This principle—
Shape and Size ConstanciesSometimes an object whose actual shape cannot change seems to change shape with the angle of our view (FIGURE 19.22). More often, thanks to shape constancy, we perceive the form of familiar objects, such as the door in FIGURE 19.23, as constant even while our retinas receive changing images of them. Our brain manages this feat thanks to visual cortex neurons that rapidly learn to associate different views of an object (Li & DiCarlo, 2008).

Perceiving shape Do the tops of these tables have different dimensions? They appear to. But—
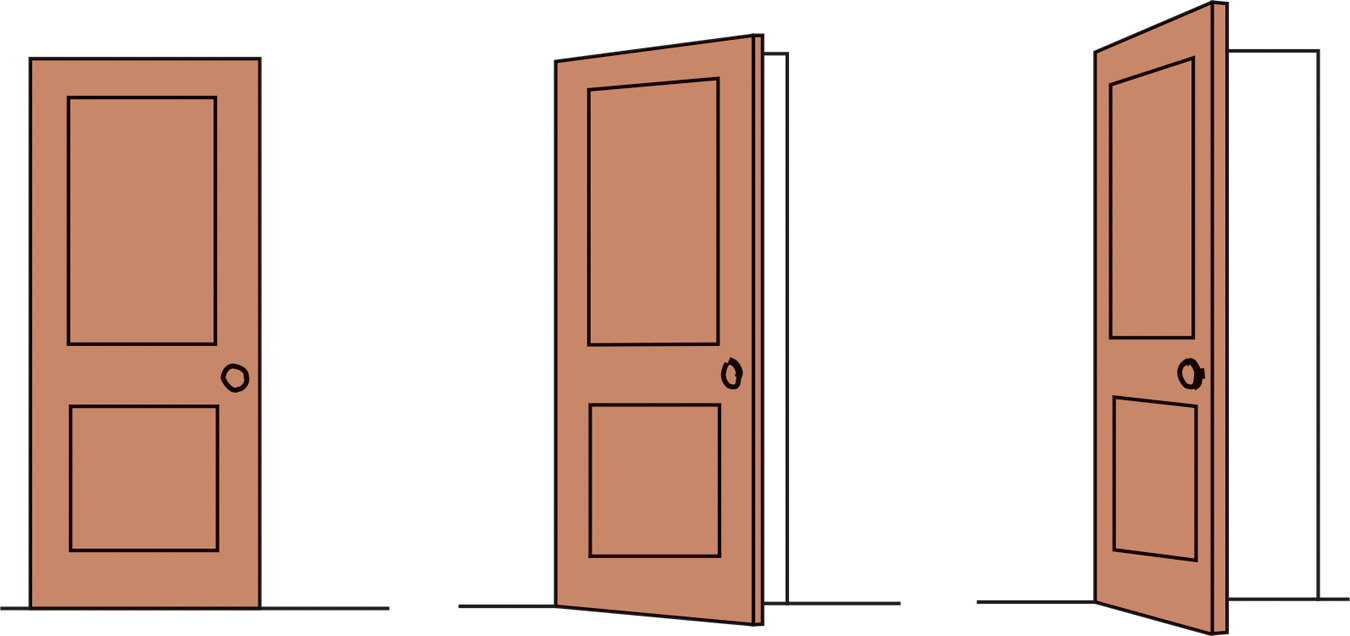
Shape constancy A door casts an increasingly trapezoidal image on our retinas as it opens. Yet we still perceive it as rectangular.
Thanks to size constancy, we perceive objects as having a constant size, even while our distance from them varies. We assume a car is large enough to carry people, even when we see its tiny image from two blocks away. This assumption also illustrates the close connection between perceived distance and perceived size. Perceiving an object’s distance gives us cues to its size. Likewise, knowing its general size—
Even in size-
253
For at least 22 centuries, scholars have wondered (Hershenson, 1989). One reason is that monocular cues to objects’ distances make the horizon Moon seem farther away. If it’s farther away, our brain assumes, it must be larger than the Moon high in the night sky (Kaufman & Kaufman, 2000). Take away the distance cue, by looking at the horizon Moon through a paper tube, and the object will immediately shrink.
Size-
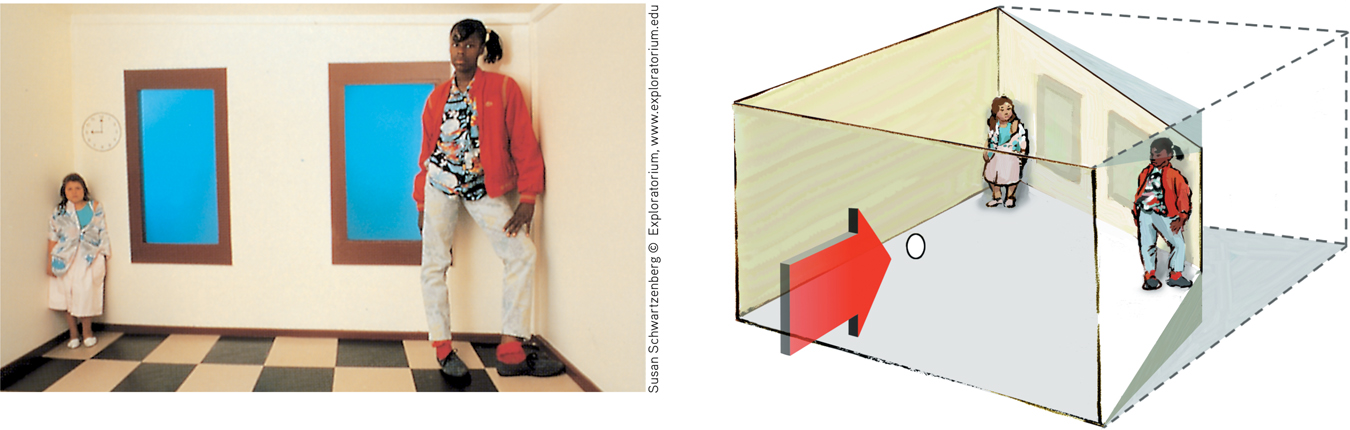
The illusion of the shrinking and growing girls This distorted room, designed by Adelbert Ames, appears to have a normal rectangular shape when viewed through a peephole with one eye. The girl in the right corner appears disproportionately large because we judge her size based on the false assumption that she is the same distance away as the girl in the far corner.
Perceptual illusions reinforce a fundamental lesson: Perception is not merely a projection of the world onto our brain. Rather, our sensations are disassembled into information bits that our brain then reassembles into its own functional model of the external world. During this reassembly process, our assumptions—
To experience more visual illusions, and to understand what they reveal about how you perceive the world, visit LaunchPad’s PsychSim 6: Visual Illusions.
***
Form perception, depth perception, motion perception, and perceptual constancies illuminate how we organize our visual experiences. Perceptual organization applies to our other senses, too. Listening to an unfamiliar language, we have trouble hearing where one word stops and the next one begins. Listening to our own language, we automatically hear distinct words. This, too, reflects perceptual organization. But it is more, for we even organize a string of letters—