How It Works
9.1 CONDUCTING A SINGLE-
In How It Works 7.2, we conducted a z test for data from the Consideration of Future Consequences (CFC) scale (Adams, 2012). How can we conduct all six steps of hypothesis testing for a single-
Step 1: Population 1: All students in career discussion groups. Population 2: All students who did not participate in career discussion groups.
The comparison distribution will be a distribution of means. The hypothesis test will be a single-
Step 2: Null hypothesis: Students who participated in career discussion groups had the same CFC scores, on average, as students who did not participate—
Step 3: 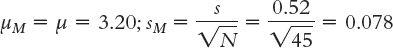
Step 4: df = N − 1 = 45 − 1 = 44
The critical values, based on 44 degrees of freedom (because 44 is not in the table, we look up the more conservative degrees of freedom of 40), a p level of 0.05, and a two-
Step 5: 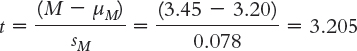
Step 6: Reject the null hypothesis. It appears that students who participate in career discussion groups have higher CFC scores, on average, than do students who do not participate.
The statistics, as presented in a journal article, would read:
t(44) = 3.21, p < 0.05
(Note: If we had used software, we would report the actual p value instead of just whether the p value is larger or smaller than the critical p value.)
9.2 CONDUCTING A PAIRED-SAMPLES t TEST
9.2 CONDUCTING A PAIRED-
Salary Wizard is an online tool that allows you to look up incomes for specific jobs for cities in the United States. We looked up the 25th percentile for income for six jobs in two cities: Boise, Idaho, and Los Angeles, California. The data are below.
| Boise | Los Angeles | |
| Executive chef | $53,047.00 | $62,490.00 |
| Genetics counselor | $49,958.00 | $58,850.00 |
| Grants/proposal writer | $41,974.00 | $49,445.00 |
| Librarian | $44,366.00 | $52,263.00 |
| Public schoolteacher | $40,470.00 | $47,674.00 |
| Social worker (with bachelor’s degree) | $36,963.00 | $43,542.00 |
How can we conduct a paired-
Step 1: Population 1: Job types in Boise, Idaho. Population 2: Job types in Los Angeles, California.
The comparison distribution will be a distribution of mean differences. The hypothesis test will be a paired-
This study meets the first of the three assumptions and may meet the third. The dependent variable, income, is scale. We do not know whether the population is normally distributed, there are not at least 30 participants, and there is not much variability in the data in the samples, so we should proceed with caution. The data were not randomly selected, so we should be cautious when generalizing beyond this sample of job types.
Step 2: Null hypothesis: Jobs in Boise pay the same, on average, as jobs in Los Angeles—
Step 3: µM = µ = 0; sM = 438.919
| Boise | Los Angeles | Difference (D) | (D − Mdifference) | (D − Mdifference)2 |
| $53,047.00 | $62,490.00 | 9443 | 1528.667 | 2,336,822.797 |
| $49,958.00 | $58,850.00 | 8892 | 977.667 | 955,832.763 |
| $41,974.00 | $49,445.00 | 7471 | −443.333 | 196,544.149 |
| $44,366.00 | $52,263.00 | 7897 | −17.333 | 300.433 |
| $40,470.00 | $47,674.00 | 7204 | −710.333 | 504,572.971 |
| $36,963.00 | $43,542.00 | 6579 | −1335.333 | 1,783,114.221 |
Mdifference = 7914.333
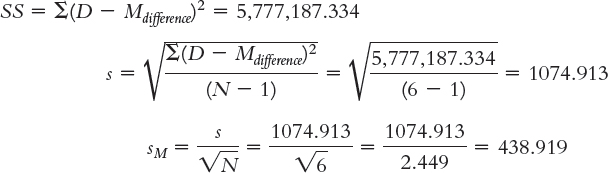
Step 4: df = N − 1 = 6 − 1 = 5
The critical values, based on 5 degrees of freedom, a p level of 0.05, and a two-
Step 5: 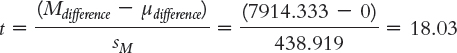
Step 6: Reject the null hypothesis. It appears that jobs in Los Angeles pay more, on average, than do jobs in Boise.
The statistics, as they would be presented in a journal article, are:
t(5) = 18.03, p < 0.05