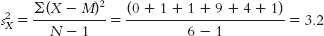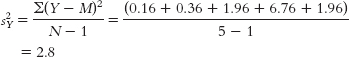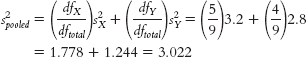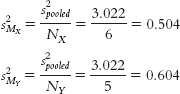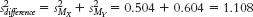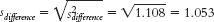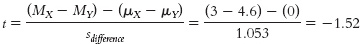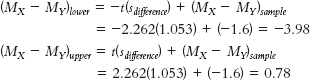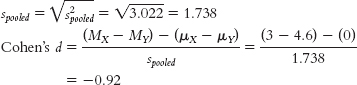11.1 When the data we are comparing were collected using the same participants in both conditions, we would use a paired-samples t test; each participant contributes two values to the analysis. When we are comparing two independent groups and no participant is in more than one condition, we would use an independent-samples t test.
11.2 Pooled variance is a weighted combination of the variability in both groups in an independent-samples t test.
11.3
a. Group 1 is treated as the X variable; its mean is 3.0.
X
X − M
(X − M)2
3
0
0
2
−1
1
4
1
1
6
3
9
1
−2
4
2
−1
1
Group 2 is treated as the Y variable; its mean is 4.6.
c. The variance version of standard error is calculated for each sample as:
d. The variance of the distribution of differences between means is: This can be converted to standard deviation units by taking the square root:
e.
11.4
a. The null hypothesis asserts that there are no average between-group differences; employees with low trust in their leader show the same mean level of agreement with decisions as those with high trust in their leader. Symbolically, this would be written H0: μ1 = μ2. The research hypothesis asserts that mean level of agreement is different between the two groups—H1: μ1 ≠ μ2.
b. The critical values, based on a two-tailed test, a p level of 0.05, and dftotal of 9, are −2.262 and 2.262. The t value we calculated, −1.519, does not exceed the cutoff of −2.262, so we fail to reject the null hypothesis.
c. Based on these results, we did not find evidence that mean level of agreement with a decision is different across the two levels of trust, t(9) = −1.519, p > 0.05.
d. Despite having similar means for the two groups, we failed to reject the null hypothesis, whereas the original researchers rejected the null hypothesis. The failure to reject the null hypothesis is likely due to the low statistical power from the small samples we used.
11.5 We calculate confidence intervals to determine a range of plausible values for the population parameter, based on the data.
11.6 Effect size tells us how large or small the difference we observed is, regardless of sample size. Even when a result is statistically significant, it might not be important. Effect size helps us evaluate practical significance.
11.7
a. The upper and lower bounds of the confidence interval are calculated as: The confidence interval is [−3.98, 0.78].
b. To calculate Cohen’s d, we need to calculate the pooled standard deviation for the data:
11.8 The confidence interval provides us with a range of differences between means in which we could expect the population mean difference to fall 95% of the time, based on samples of this size. Whereas the hypothesis test evaluates the point estimate of the difference between means—(3 − 4.6), or −1.6, in this case—the confidence interval gives us a range, or interval estimate, of [−3.98, 0.78].
11.9 The effect size we calculated, Cohen’s d of −0.92, is a large effect according to Cohen’s guidelines. Beyond the hypothesis test and confidence interval, which both lead us to fail to reject the null hypothesis, the size of the effect indicates that we might be on to a real effect here. We might want to replicate the study with more statistical power in an effort to better test this hypothesis.