17.1 A nonparametric test is a statistical analysis that is not based on a set of assumptions about the population, whereas a parametric test is based on assumptions about the population.
17.2 We use nonparametric tests when the data violate the assumptions about the population that parametric tests make. The three most common situations that call for nonparametric tests are (1) having a nominal dependent variable, (2) having an ordinal dependent variable, and (3) having a small sample size with possible skew.
17.3
a. The independent variable is city, a nominal variable. The dependent variable is whether a woman is pretty or not so pretty, an ordinal variable.
b. The independent variable is city, a nominal variable. The dependent variable is beauty, assessed on a scale of 1–10. This is a scale variable.
c. The independent variable is intelligence, likely a scale variable. The dependent variable is beauty, assessed on a scale of 1–10. This is a scale variable.
d. The independent variable is ranking on intelligence, an ordinal variable. The dependent variable is ranking on beauty, also an ordinal variable.
17.4
a. We’d choose a hypothesis test from category III. We’d use a nonparametric test because the dependent variable is not scale and would not meet the primary assumption of a normally distributed dependent variable, even with a large sample.
b. We’d choose a test from category II because the independent variable is nominal and the dependent variable is scale. (In fact, we’d use a one-way between-groups ANOVA because there is only one independent variable and it has more than two levels.)
c. We’d choose a hypothesis test from category I because we have a scale independent variable and a scale dependent variable. (If we were assessing the relation between these variables, we’d use the Pearson correlation coefficient. If we wondered whether intelligence predicted beauty, we’d use simple linear regression.)
d. We’d choose a hypothesis from category III because both the independent and dependent variables are ordinal. We would not meet the assumption of having a normal distribution of the dependent variable, even if we had a large sample.
17.5 We use chi-square tests when all variables are nominal.
17.6 Observed frequencies indicate how often something actually happens in a given category based on the data we collected. Expected frequencies indicate how often we expect something to happen in a given category based on what is known about the population according to the null hypothesis.
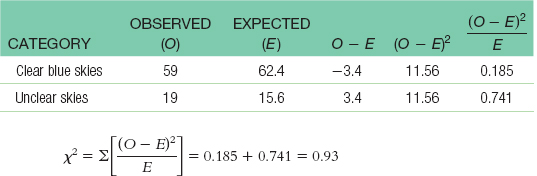
17.7
a.dfx2 = k − 1 = 2 − 1 = 1
b. Observed:
CLEAR BLUE SKIES
UNCLEAR SKIES
59 days
19 days
Expected:
CLEAR BLUE SKIES
UNCLEAR SKIES
(78)(0.80) = 62.4
(78)(0.20) = 15.6 days
c.
17.8
a. The participants are the lineups. The independent variable is type of lineup (simultaneous, sequential), and the dependent variable is outcome of the lineup (suspect identification, other identification, no identification).
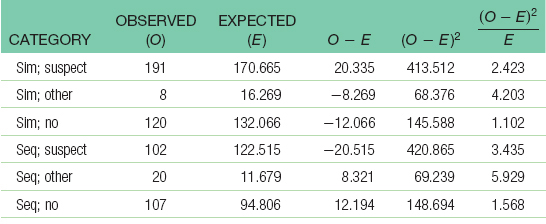
b.Step 1: Population 1 is police lineups like those we observed. Population 2 is police lineups for which type of lineup and outcome are independent. The comparison distribution is a chi-square distribution. The hypothesis test is a chi-square test for independence because we have two nominal variables. This study meets three of the four assumptions. The two variables are nominal; every participant (lineup) is in only one cell; and there are more than five times as many participants as cells (8 participants and 6 cells). Step 2: Null hypothesis: Lineup outcome is independent of type of lineup. Research hypothesis: Lineup outcome depends on type of lineup. Step 3: The comparison distribution is a chi-square distribution with 2 degrees of freedom: Step 4: The cutoff chi-square statistic, based on a p level of 0.05 and 2 degrees of freedom, is 5.992. (Note: It is helpful to include a drawing of the chi-square distribution with the cutoff.) Step 5:
OBSERVED
SUSPECT ID
OTHER ID
NO ID
SIMULTANEOUS
191
8
120
319
SEQUENTIAL
102
20
107
229
293
28
227
548
We can calculate the expected frequencies in one of two ways. First, we can think about it. Out of the total of 548 lineups, 293 led to identification of the suspect, an identification rate of 293/548 = 0.535, or 53.5%. If identification were independent of type of lineup, we would expect the same rate for each type of lineup. For example, for the 319 simultaneous lineups, we would expect: (0.535) (319) = 170.665. For the 229 sequential lineups, we would expect: (0.535)(229) = 122.515. Or we can use the formula; for these same two cells (the column labeled “Suspect ID”), we calculate: For the column labeled “Other ID”: For the column labeled “No ID”:
EXPECTED
SUSPECT ID
OTHER ID
NO ID
SIMULTANEOUS
170.665
16.269
132.066
319
SEQUENTIAL
122.515
11.679
94.806
229
293
28
227
548
Step 6: Reject the null hypothesis. It appears that the outcome of a lineup depends on the type of lineup. In general, simultaneous lineups tend to lead to a higher rate than expected of suspect identification, lower rates than expected of identification of other members of the lineup, and lower rates than expected of no identification at all. (Note: It is helpful to add the test statistic to the drawing that included the cutoff).
c.χ2(1, N = 548) = 18.66, p < 0.05
d. The findings of this study were the opposite of what had been expected by the investigators; the report of results noted that, prior to this study, police departments believed that the sequential lineup led to more accurate identification of suspects. This situation occurs frequently in behavioral research, a reminder of the importance of conducting two-tailed hypothesis tests. (Of course, the fact that this study produced different results doesn’t end the debate. Future researchers should explore why there are different findings in different contexts in an effort to target the best lineup procedures for specific situations.)
17.9 The measure of effect size for chi square is Cramer’s V. It is calculated by first multiplying the total N by the degrees of freedom for either the rows or columns (whichever is smaller) and then dividing the calculated chi-square value by this number. We then take the square root, which is Cramer’s V.
17.10 To calculate the relative likelihood, we first need to calculate two conditional probabilities: the conditional probability of being a Republican given that a person is a business major, which is
, and the conditional probability of being a Republican given that a person is a psychology major, which is
. Now we divide the conditional probability of being a Republican given that a person is a business major by the conditional probability of being a Republican given that a person is a psychology major:
. The relative likelihood of being a Republican given that a person is a business major as opposed to a psychology major is 1.09.
17.11
a.
= 0.184. This is a small-to-medium effect.
b. To create a graph, we must first calculate the conditional proportions by dividing the observed frequency in each cell by the row total. These conditional proportions appear in the table below and are graphed in the figure.
ID SUSPECT
ID OTHER
NO ID
SIMULTANEOUS
0.599
0.025
0.376
SEQUENTIAL
0.445
0.087
0.467
c. We must first calculate two conditional probabilities: the conditional probability of obtaining a suspect identification in the simultaneous lineups, which is
, and the conditional probability of obtaining a suspect identification in the sequential lineups, which is
. We then divide 0.599 by 0.445 to obtain the relative likelihood of 1.35. Suspects are 1.35 times more likely to be identified in simultaneous as opposed to sequential lineups.
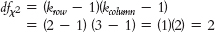
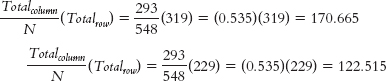
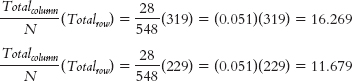
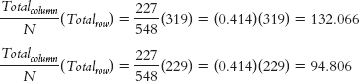
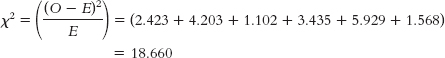
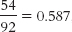 , and the conditional probability of being a Republican given that a person is a psychology major, which is
, and the conditional probability of being a Republican given that a person is a psychology major, which is 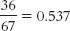 . Now we divide the conditional probability of being a Republican given that a person is a business major by the conditional probability of being a Republican given that a person is a psychology major:
. Now we divide the conditional probability of being a Republican given that a person is a business major by the conditional probability of being a Republican given that a person is a psychology major: 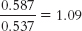 . The relative likelihood of being a Republican given that a person is a business major as opposed to a psychology major is 1.09.
. The relative likelihood of being a Republican given that a person is a business major as opposed to a psychology major is 1.09.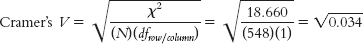 = 0.184. This is a small-
= 0.184. This is a small-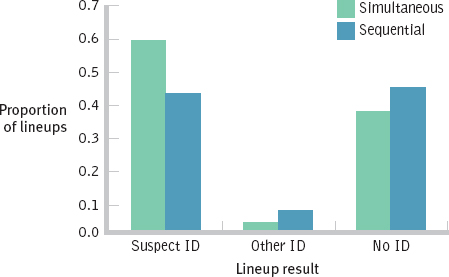
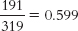 , and the conditional probability of obtaining a suspect identification in the sequential lineups, which is
, and the conditional probability of obtaining a suspect identification in the sequential lineups, which is 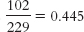 . We then divide 0.599 by 0.445 to obtain the relative likelihood of 1.35. Suspects are 1.35 times more likely to be identified in simultaneous as opposed to sequential lineups.
. We then divide 0.599 by 0.445 to obtain the relative likelihood of 1.35. Suspects are 1.35 times more likely to be identified in simultaneous as opposed to sequential lineups.