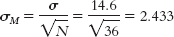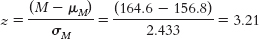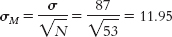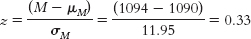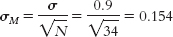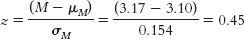7.1 We need to know the mean, μ, and the standard deviation, σ, of the population.
7.2 Raw scores are used to compute z scores, and z scores are used to determine what percentage of scores fall below and above that particular position on the distribution. A z score can also be used to compute a raw score.
7.3 Because the curve is symmetric, the same percentage of scores (41.47%) lies between the mean and a z score of −1.37 as between the mean and a z score of 1.37.
7.4 Fifty percent of scores fall below the mean, and 12.93% fall between the mean and a z score of 0.33. 50% + 12.93% = 62.93%
7.5
a.μM = μ = 156.8 50% below the mean; 49.87% between the mean and this score; 50 + 49.87 = 99.87th percentile
b. 100 − 99.87 = 0.13% of samples of this size scored higher than the students at Baylor.
c. At the 99.87th percentile, these 36 students from Baylor are truly outstanding. If these students are representative of their majors, clearly these results reflect positively on Baylor’s psychology and neuroscience department.
7.6 For most parametric hypothesis tests, we assume that (1) the dependent variable is assessed on a scale measure—that is, equal changes are reflected by equal distances on the measure; (2) the participants are randomly selected, meaning everyone has the same chance of being selected; and (3) the distribution of the population of interest is approximately normal.
7.7 If a test statistic is more extreme than the critical value, then the null hypothesis is rejected. If a test statistic is less extreme than the critical value, then we fail to reject the null hypothesis.
7.8 If the null hypothesis is true, he will reject it 8% of the time.
7.9
a. 0.15
b. 0.03
c. 0.055
7.10
a. (1) The dependent variable—diagnosis (correct versus incorrect)—is nominal, not scale, so this assumption is not met. Based only on this, we should not proceed with a hypothesis test based on a z distribution. (2) The samples include only outpatients seen over 2 specific months and only those at one community mental health center. The sample is not randomly selected, so we must be cautious about generalizing from it. (3) The populations are not normally distributed because the dependent variable is nominal.
b. (1) The dependent variable, health score, is likely scale. (2) The participants were randomly selected; all wild cats in zoos in North America had an equal chance of being selected for this study. (3) The data are not normally distributed; we are told that a few animals had very high scores, so the data are likely positively skewed. Moreover, there are fewer than 30 participants in this study. It is probably not a good idea to proceed with a hypothesis test based on a z distribution.
7.11 A directional test indicates that either a mean increase or a mean decrease in the dependent variable is hypothesized, but not both. A nondirectional test does not indicate a direction of mean difference for the research hypothesis, just that there is a mean difference.
7.12μM = μ = 1090
7.13
7.14Step 1: Population 1 is coffee drinkers who spend the day in coffee shops. Population 2 is all coffee drinkers in the United States. The comparison distribution will be a distribution of means. The hypothesis test will be a z test because we have only one sample and we know the population mean and standard deviation. This study meets two of the three assumptions and may meet the third. The dependent variable, the number of cups coffee drinkers drank, is scale. In addition, there are more than 30 participants in the sample, indicating that the comparison distribution is normal. The data were not randomly selected, however, so we must be cautious when generalizing. Step 2: The null hypothesis is that people who spend the day working in the coffee shop drink the same amount of coffee, on average, as those in the general U.S. population; H0: μ1 = μ2. The research hypothesis is that people who spend the day in coffee shops drink a different amount of coffee, on average, than those in the general U.S. population; H1: μ1 ≠ μ2. Step 3: μM = μ = 3.10 Step 4: The cutoff z statistics are −1.96 and 1.96. Step 5: Step 6: Because the z statistic does not exceed the cutoffs, we fail to reject the null hypothesis. We did not find any evidence that the sample was different from what was expected according to the null hypothesis.