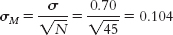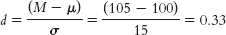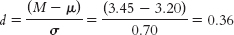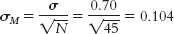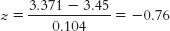8.1 Interval estimates provide a range of scores in which we have some confidence the population statistic will fall, whereas point estimates use just a single value to describe the population.
8.2 The interval estimate is 17% to 25% (21% − 4% = 17% and 21% + 4% = 25%); the point estimate is 21%.
8.3
a. First, we draw a normal curve with the sample mean, 3.20, in the center. Then we put the bounds of the 95% confidence interval on either end, writing the appropriate percentages under the segments of the curve: 2.5% beyond the cutoffs on either end and 47.5% between the mean and each cutoff. Now we look up the z statistics for these cutoffs; the z statistic associated with 47.5%, the percentage between the mean and the z statistic, is 1.96. Thus, the cutoffs are −1.96 and 1.96. Next, we calculate standard error so that we can convert these z statistics to raw means: Mlower = −z(σM) + Msample = −1.96(0.104) + 3.45 = 3.25 Mupper = z(σM) + Msample = 1.96(0.104) + 3.45 = 3.65 Finally, we check to be sure the answer makes sense by demonstrating that each end of the confidence interval is the same distance from the mean: 3.25 − 3.45 = −0.20 and 3.65 − 3.45 = 0.20. The confidence interval is [3.25, 3.65].
b. If we were to conduct this study over and over, with the same sample size, we would expect the population mean to fall in that interval 95% of the time. Thus, it provides a range of plausible values for the population mean. Because the null-hypothesized population mean of 3.20 is not a plausible value, we can conclude that those who attended the discussion group seem to have higher mean CFC scores than those who did not. This conclusion matches that of the hypothesis test, in which we rejected the null hypothesis.
c. The confidence interval is superior to the hypothesis test because not only does it lead to the same conclusion but it also gives us an interval estimate, rather than a point estimate, of the population mean.
8.4 Statistical significance means that the observation meets the standard for special events, typically something that occurs less than 5% of the time. Practical importance means that the outcome really matters.
8.5 Effect size is a standardized value that indicates the size of a difference with respect to a measure of spread but is not affected by sample size.
8.6 Cohen’s
8.7
a. We calculate Cohen’s d, the effect size appropriate for data analyzed with a z test. We use standard deviation in the denominator, rather than standard error, because effect sizes are for distributions of scores rather than distributions of means. Cohen’s
b. Cohen’s conventions indicate that 0.2 is a small effect and 0.5 is a medium effect. This effect size, therefore, would be considered a small-to-medium effect.
c. If the career discussion group is easily implemented in terms of time and money, the small-to-medium effect might be worth the effort. For university students, a higher mean level of Consideration of Future Consequences might translate into a higher mean level of readiness for life after graduation, a premise that we could study.
8.8 Three ways to increase power are to increase alpha, to conduct a one-tailed test rather than a two-tailed test, and to increase N. All three of these techniques serve to increase the chance of rejecting the null hypothesis. (We could also increase the difference between means, or decrease variability, but these are more difficult.)
8.9Step 1: We know the following about population 2: μ = 3.20, σ = 0.70. We assume the following about population 1 based on the information from the sample: N = 45, M = 3.45. We need to calculate standard error based on the standard deviation for population 2 and the size of the sample: Step 2: Because the sample mean is higher than the population mean, we will conduct this one-tailed test by examining only the high end of the distribution. We need to find the cutoff that marks where 5% of the data fall in the tail. We know that the z cutoff for a one-tailed test is 1.64. Using that z statistic, we can calculate a raw score. M = z(σM) + μM = 1.64(0.104) + 3.20 = 3.371 This mean of 3.371 marks the point beyond which 5% of all means based on samples of 45 observations will fall. Step 3: For the distribution based on population 1, centered around 3.45, we need to calculate how often means of 3.371 (the cutoff) and greater occur. We do this by calculating the z statistic for the raw mean of 3.371 with respect to the sample mean of 3.45. We now look up this z statistic on the table and find that 22.36% falls toward the tail and 27.64% falls between this z statistic and the mean. We calculate power as the proportion of observations between this z statistic and the tail of interest, which is at the high end. So we would add 27.64% and 50% to get statistical power of 77.64%.
8.10
a. The statistical power calculation means that, if population 1 really does exist, we have a 77.64% chance of observing a sample mean, based on 45 observations, that will allow us to reject the null hypothesis. We fall just short of the desired 80% statistical power.
b. We can increase statistical power by increasing the sample size, extending or enhancing the career discussion group such that we create a bigger effect, or by changing alpha.