Vision
 Your eyes receive light energy and transform it into neural messages that your brain then processes into what you consciously see. How does such a taken-for-granted yet remarkable thing happen?
Your eyes receive light energy and transform it into neural messages that your brain then processes into what you consciously see. How does such a taken-for-granted yet remarkable thing happen?
Light Energy: From the Environment Into the Brain
5-7 What are the characteristics of the energy we see as light?
When you look at a bright red tomato, what strikes your eyes are not bits of the color red but pulses of energy that your visual system perceives as red. What we see as visible light is but a thin slice of the wide spectrum of electromagnetic energy shown in FIGURE 5.9. On one end of this spectrum are the short gamma waves, no longer than the diameter of an atom. On the spectrum’s other end are the mile-long waves of radio transmission. In between is the narrow band most of us can see as visible light. Other portions are visible to other animals. Bees, for instance, cannot see what we perceive as red but can see ultraviolet light.
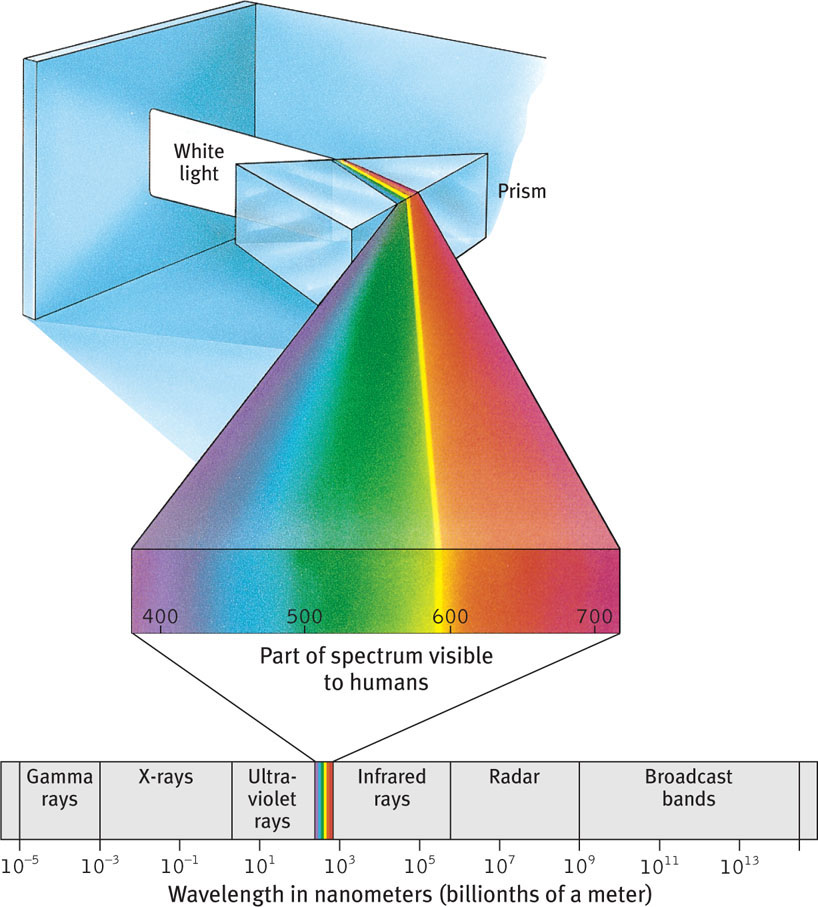
140
Light travels in waves, and the shape of those waves influences what we see. Light’s wavelength—the distance from one wave peak to the next (FIGURE 5.10a)—determines its hue (the color we experience, such as a tomato’s red skin). A light wave’s amplitude, or height, determines its intensity—the amount of energy it contains. Intensity influences brightness (FIGURE 5.10b).
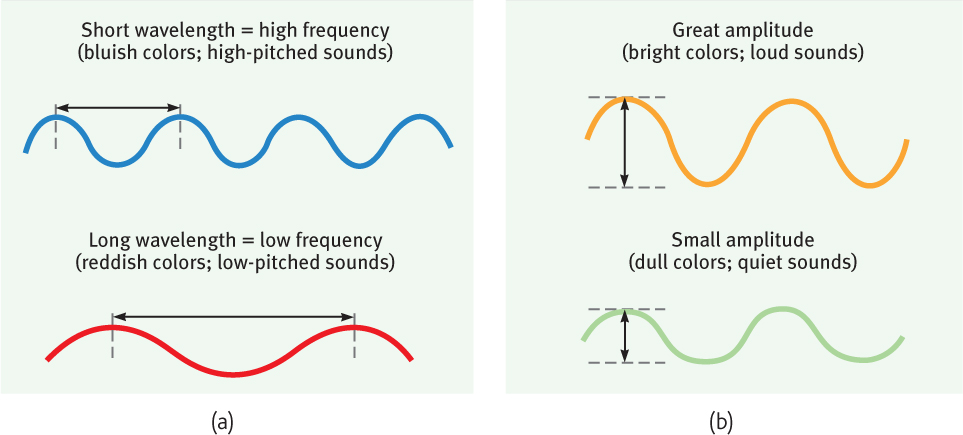
Understanding the characteristics of the physical energy we see as light is one part of understanding vision. But to appreciate how we transform that energy into color and meaning, we need to know more about vision’s window, the eye.
The Eye
5-8 How does the eye transform light energy into neural messages?
What color are your eyes? Asked this question, most people describe the color of their irises. This doughnut-shaped ring of muscle adjusts the size of your pupil, the small opening that controls the amount of light entering your eye. After passing through your cornea (the eyeball’s protective covering) and pupil, light hits the lens in your eye. The lens then focuses the light rays into an image on your eyeball’s inner surface, the retina.
For centuries, scientists knew that when an image of a candle passes through a small opening, it casts an upside-down mirror image on a dark wall behind. They wondered how, if the eye’s structure casts this sort of image on the retina (as in FIGURE 5.11), can we see the world right side up?
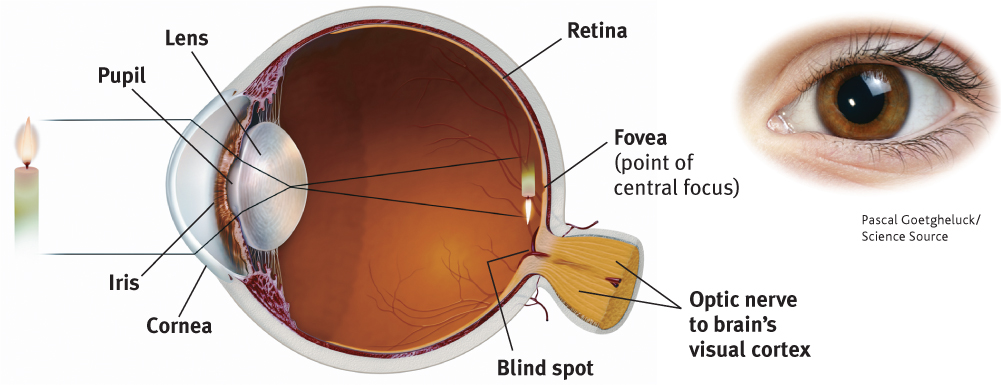
141
Eventually the answer became clear: The retina doesn’t “see” a whole image. Rather, its millions of receptor cells behave like the prankster engineering students who make news by taking a car apart and rebuilding it in a friend’s third-floor bedroom. The retina’s millions of cells convert the particles of light energy into neural impulses and forward those to the brain. The brain reassembles them into what we perceive as an upright object.
The Retina
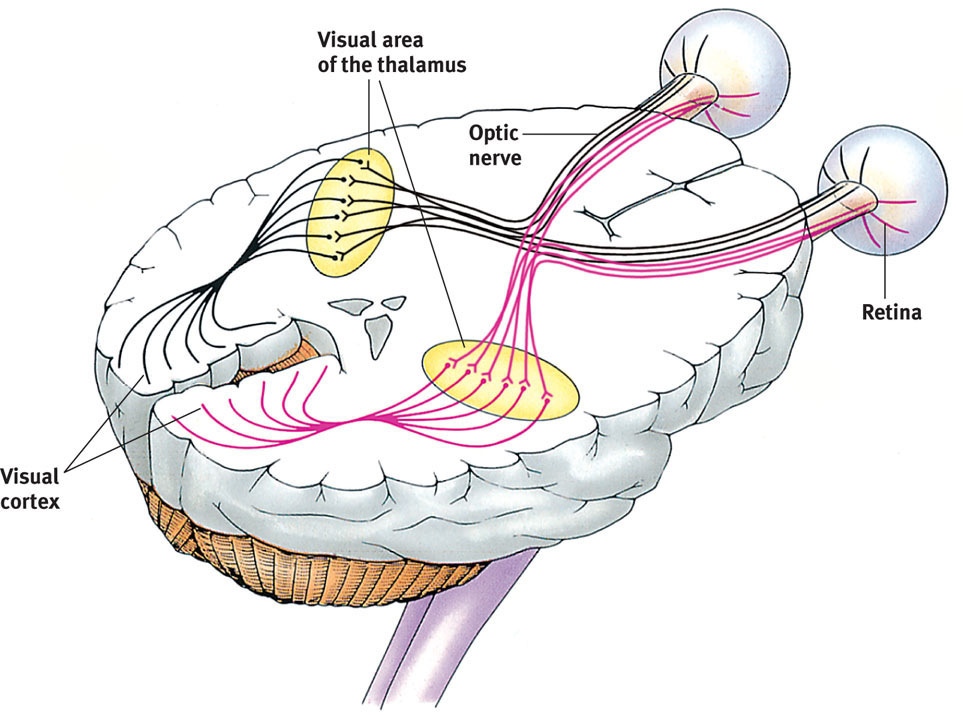
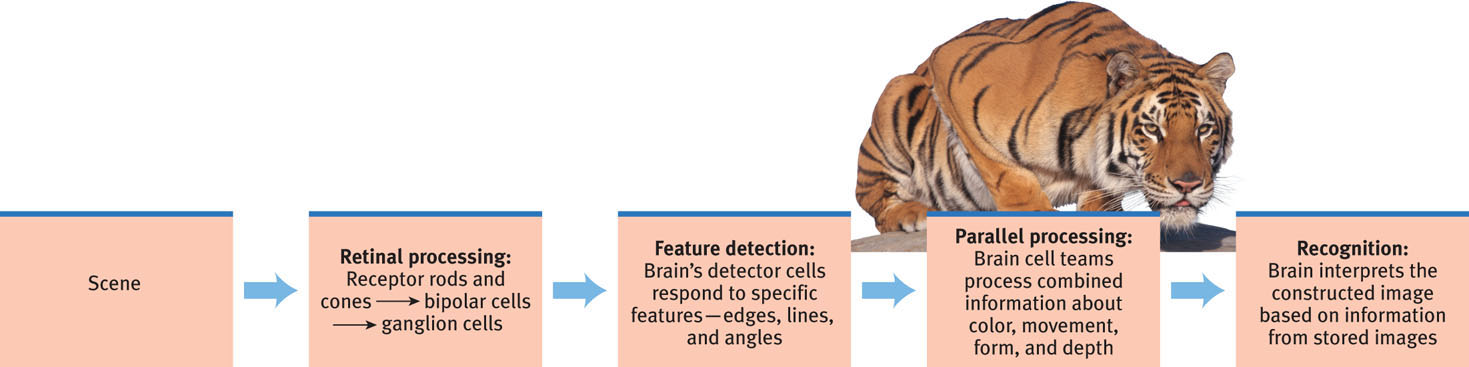
Let’s follow a single light-energy particle as it makes its way to the back of your eye. Having traveled through your eye’s cornea, pupil, and lens, the particle passes through your retina’s outer layer of cells. As the particle reaches the retina’s buried receptor cells, the rods and cones, the light energy triggers chemical changes (FIGURE 5.12). Those changes activate nearby bipolar cells, causing them to send out neural signals. These signals in turn activate neighboring ganglion cells. The ganglion cells’ axons twine together like strands of a rope to form the optic nerve that will carry the information from your eye to your brain. After a momentary stopover at the thalamus, rather like changing planes in Chicago, the information flies on to its final destination, your visual cortex, at the back of your brain.
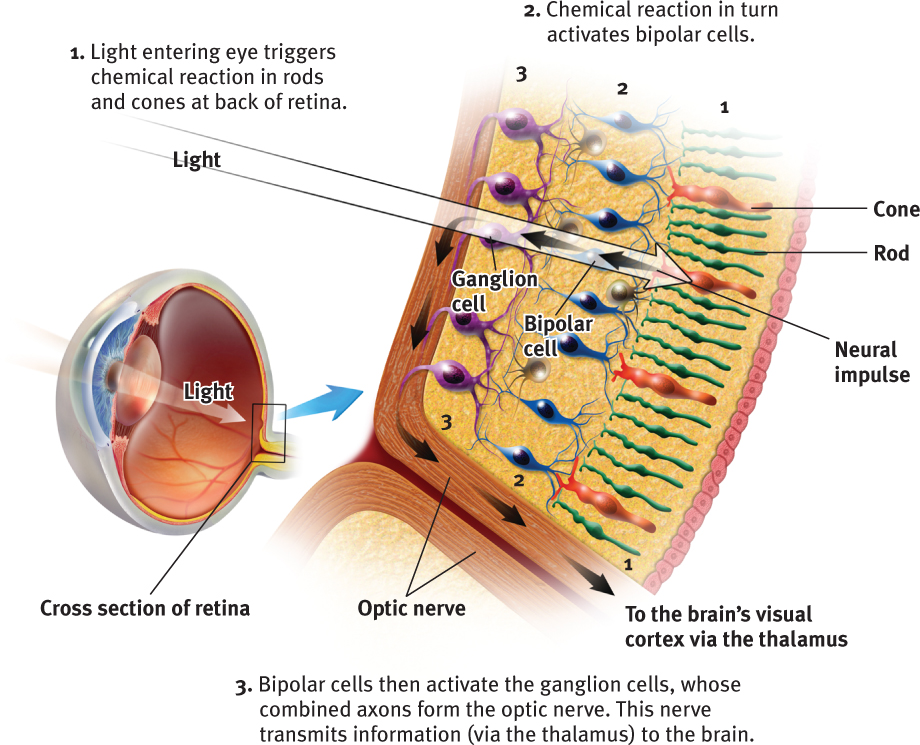
The optic nerve can send nearly 1 million messages at once through its nearly 1 million ganglion fibers. We pay a small price for this high-speed eye-to-brain highway. Where the optic nerve leaves the eye, there are no receptor cells—creating a blind spot (FIGURE 5.13). Close one eye and you won’t see a black hole on your TV screen, however. Without seeking your approval, your brain fills in the hole. 
142

RETRIEVE + REMEMBER
Question 5.6
There are no receptor cells where the optic nerve leaves the eye. This creates a blind spot in your vision. To demonstrate, first close your left eye, look at the spot n FIGURE 5.13, and move your face away from the page to a distance at which one of the cars disappears. (Which one do you predict it will be?) Repeat with your right eye closed—and note that now the other car disappears. Can you explain why?
Your blind spot is on the nose side of each retina, which means that objects to your right may fall onto the right eye’s blind spot. Objects to your left may fall on the left eye’s blind spot. The blind spot does not normally impair your vision, because with but one eye open, your brain still fills in the blank spot.
Rods and cones differ in what they do and where they’re found (TABLE 5.1). Cones enable you to see fine details and to perceive color. In dim light, cones don’t function well, which is why the world looks colorless at night. Cones cluster around the retina’s area of central focus (the fovea). Many have their own hotline to the brain. Each of those cones transmits to a single bipolar cell that helps relay that cone’s individual message to the visual cortex. These direct connections preserve the cones’ precise information, which is why cones are better at detecting fine details.
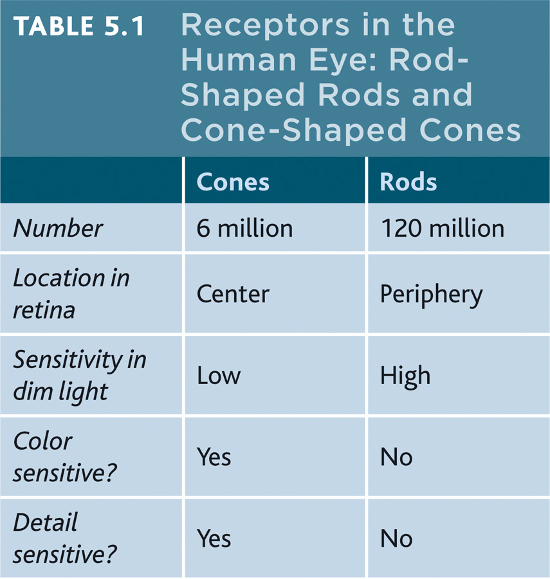
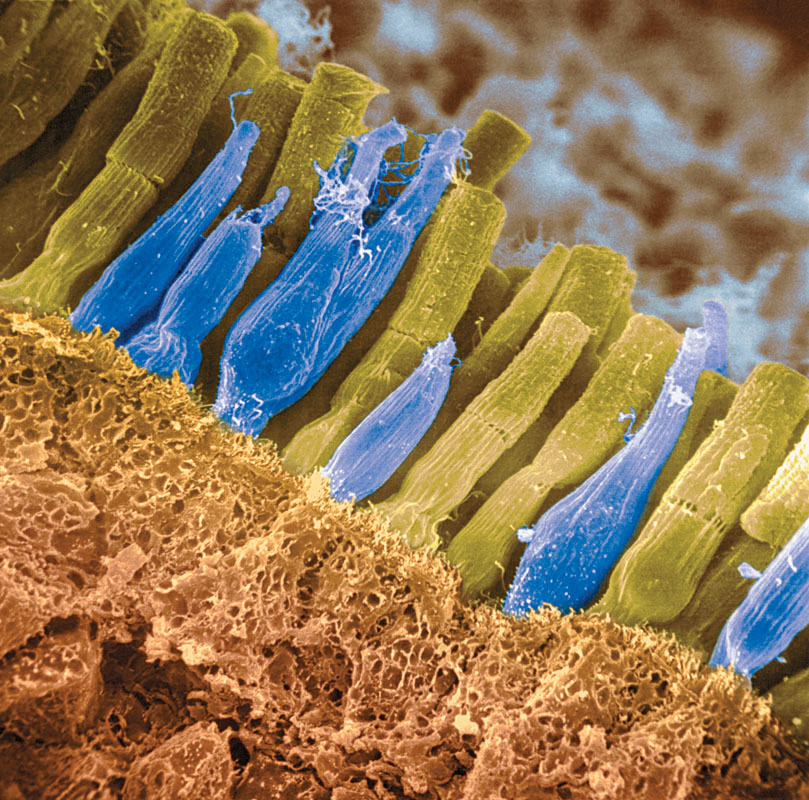
Rods are located around the outer regions (the periphery) of your retina. Rods enable black-and-white vision, and they remain sensitive in dim light. Rods have no hotlines to the brain. Several rods pool their faint energy output and funnel it onto a single bipolar cell.
Thus, cones and rods each provide a special sensitivity:
- Cones are sensitive to detail and color.
- Rods are sensitive to faint light.
Stop for a minute and experience the rod-cone difference in sensitivity to details. Pick a word in this sentence and stare directly at it, focusing its image on the cones in the center of your eye. Notice that words a few inches off to the side appear blurred? Their image lacks details because it is striking your retina’s outer regions, where most rods are found.
RETRIEVE + REMEMBER

Question 5.7
Some night-loving animals, such as toads, mice, rats, and bats, have impressive night vision thanks to having many more __________ (rods/cones) than (rods/cones) in their retinas. These creatures probably have very poor __________(color/black-and white) vision.
rods; cones; color
Question 5.8
Cats are able to open their __________much wider than we can, which allows more light into their eyes so they can see better at night.
pupils
Visual Information Processing
5-9 What roles do feature detection and parallel processing play in the brain’s visual information processing?
The retina’s receptor cells don’t just pass along electrical impulses. They begin processing sensory information by coding and analyzing it. By the time visual information travels up your optic nerve to your brain, it is on a pathway headed toward a specific location in your visual cortex, in the back of your brain. In an important stop on that journey, the optic nerve links up with neurons in the thalamus (FIGURE 5.14).
Feature Detection
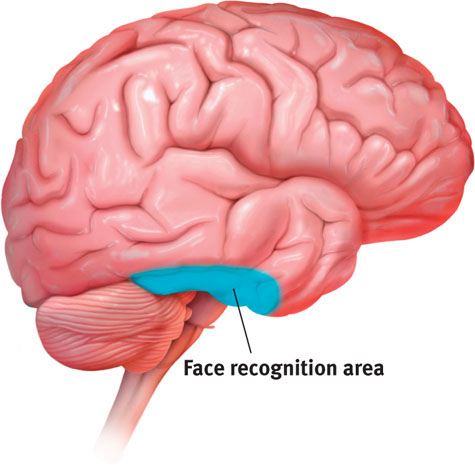
In your brain’s visual cortex, specialized nerve cells receive the information sent by individual ganglion cells in your retina. These specialized cells are called feature detectors. David Hubel and Torsten Wiesel (1979) received a Nobel Prize for their discovery that these cells respond to a scene’s specific features—to particular edges, lines, and angles. Feature detector cells pass this information to other cortical areas, where teams of cells respond to more complex patterns, such as recognizing faces. The resulting brain activity varies depending on what’s viewed. Thus, with the help of brain scans, “we can tell if a person is looking at a shoe, a chair, or a face,” noted one researcher (Haxby, 2001).
One temporal lobe area by your right ear (FIGURE 5.15) enables you to perceive faces and, thanks to a specialized neural network, to recognize them from many viewpoints (Connor, 2010). If this region is damaged, people still may recognize other forms and objects, but, like Heather Sellers, they cannot recognize familiar faces. How do we know this? In part because in laboratory experiments, researchers have used magnetic pulses to disrupt that brain area, producing a temporary loss of face recognition.
143
Parallel Processing
One of the most amazing aspects of visual information processing is the brain’s ability to divide a scene into its parts. Using parallel processing, your brain assigns different teams of nerve cells the separate tasks of simultaneously processing a scene’s movement, form, depth, and color (FIGURE 5.16). You then construct your perceptions by integrating the work of these different visual teams (Livingstone & Hubel, 1988).
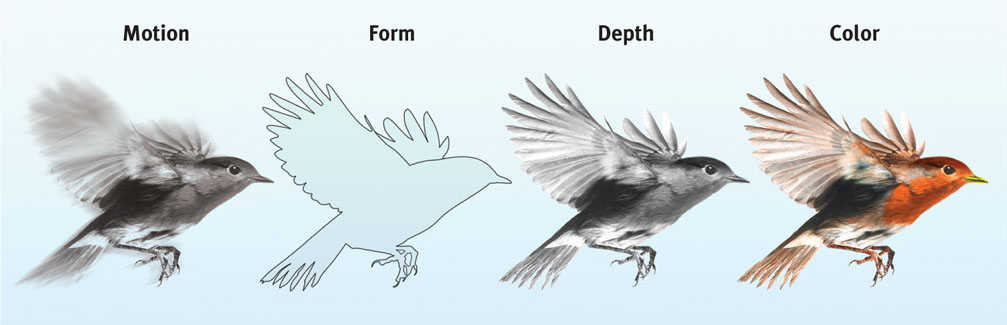
Destroy or disable the neural workstation for a visual subtask, and something peculiar results, as happened to “Mrs. M.” (Hoffman, 1998). Since a stroke damaged areas near the rear of both sides of her brain, she has been unable to perceive movement. People in a room seem “suddenly here or there but I have not seen them moving.” Pouring tea into a cup is a challenge because the fluid appears frozen—she cannot perceive it rising in the cup.
Color Vision
5-10 What theories help us understand color vision?
We talk as though objects possess color: “A tomato is red.” Perhaps you have heard the old question, “If a tree falls in the forest and no one hears it, does it make a sound?” We can ask the same of color: If no one sees the tomato, is it red?
The answer is No. First, the tomato is everything but red, because it rejects (reflects) the long wavelengths of red. Second, the tomato’s color is our mental construction. As the famous physicist Sir Isaac Newton (1704) observed more than three centuries ago, “The [light] rays are not colored.” Color, like all aspects of vision, resides not in the object but in the theater of our brain. Even while dreaming, we may perceive things in color.
One of vision’s most basic and intriguing mysteries is how we see the world in color. How, from the light energy striking your retina, does your brain manufacture your experience of color—and of so many colors? By one estimate, we can see differences among more than 1 million color variations (Neitz et al., 2001). At least most of us can. About 1 in 50 of us is “color-blind.” That person is usually male, because the defect is genetically sex linked. Most people with this condition are not actually blind to all colors. They simply have trouble perceiving the difference between red and green. To understand why, we need to understand how normal color vision works.
144
Modern detective work on the mystery of color vision began in the nineteenth century, when Hermann von Helmholtz built on the insights of an English physicist, Thomas Young. The clue that led to their breakthrough was the knowledge that any color can be created by combining the light waves of three primary colors—red, green, and blue. Young and von Helmholtz inferred that the eye must have three types of receptors, one for each color.
“Only mind has sight and hearing; all things else are deaf and blind.”
Epicharmus, Fragments, 550 b.c.e.
Years later, researchers measured the response of various cones to different color stimuli. Their results confirmed the Young-Helmholtz trichromatic (three-color) theory: The eye’s receptors do their color magic in teams of three. Indeed, the retina has three types of color receptors, each especially sensitive to the wavelengths of one of three colors. And those colors are, in fact, red, green, and blue. When light stimulates combinations of these cones, we see other colors. For example, when red and green wavelengths stimulate both red-sensitive and green-sensitive cones, we see yellow. The retina has no separate receptors especially sensitive to yellow. In most people with color-deficient vision, the red- and/or green-sensitive cones do not function properly. They do not have three-color vision.
Why, then, does yellow appear to be a pure color, not a mixture of red and green, the way purple is of red and blue? As Ewald Hering soon noted, trichromatic theory leaves some parts of the color vision mystery unsolved.
Hering, a physiologist, had found a clue in afterimages. Stare at a green square for a while and then look at a white sheet of paper, and you will see red, green’s opponent color. Stare at a yellow square and its opponent color, blue, will appear on the white paper. (To experience this, try the flag demonstration in FIGURE 5.17.) Hering proposed that there must be two other color processes: One must be responsible for red-versus-green perception, and the other for blue-versus-yellow.

A century later, researchers confirmed Hering’s proposal, which is now called the opponent-process theory. They found that color vision depends on three sets of opponent retinal processes—red-green, yellow-blue, and white-black. Recall that impulses from the retina are relayed to the thalamus on their way to the visual cortex. In both the retina and the thalamus, some neurons are “turned on” by red but “turned off” by green. Others are turned on by green but off by red (DeValois & DeValois, 1975). Like red and green marbles sent down a narrow tube, “red” and “green” messages cannot both travel at once. Red and green are thus opponents, which explains why we don’t experience mixed red and green light stimuli as a reddish green. But red and blue travel in separate channels, so we can see a reddish-blue, or purple.
How does opponent-process theory help us understand afterimages, such as in the flag demonstration? Here’s the answer (for the green changing to red):
- First, you stared at green bars, which tired the green part of the green-red pairing in your eyes.
- Then you stared at a white area. White contains all colors, including red.
- Because you had tired your green response, only the red part of the green-red pairing fired normally.
The present solution to the mystery of color vision is therefore roughly this: Color processing occurs in two stages.
- The retina’s red, green, and blue cones respond in varying degrees to different color stimuli, as the Young-Helmholtz trichromatic theory suggested.
- The cones’ responses are then processed by opponent-process cells, as Hering’s theory proposed.
RETRIEVE + REMEMBER
Question 5.9
What are two key theories of color vision? Do they contradict each other, or do they make sense together? Explain.
The Young-Helmholtz trichromatic theory shows that the retina contains color receptors for red, green, and blue. The opponent-process theory shows that we have opponent-process cells in the retina and thalamus for red-green, yellow-blue, and white-black. These theories make sense together. They outline the two stages of color vision: (1) The retina’s receptors for red, green, and blue respond to different color stimuli. (2) The receptors’ signals are then processed by the opponent-process cells on their way to the visual cortex in the brain.
145
Think about the wonders of visual processing. As you look at that tiger in the zoo, information enters your eyes, where it is taken apart and turned into millions of neural impulses sent to your brain. As your brain buzzes with activity, various areas focus on different aspects of the tiger’s image. Finally, in some mysterious yet magnificent way, these separate teams pool their work to produce a meaningful image. You compare this with previously stored images and recognize it—a crouching tiger (FIGURE 5.18).
Think, too, about what is happening as you read this page. The letters are reflecting light rays into your retina, which is sending formless nerve impulses to several areas of your brain, which integrates the information and discovers meaning. And that is how we transfer information across time and space from my mind to yours. That all of this happens instantly, effortlessly, and continuously is awe-inspiring.
RETRIEVE + REMEMBER
Question 5.10
What is the rapid sequence of events that occurs when you see and recognize a friend?
Light waves reflect off the person and travel into your eye, where the receptor cells in your retina convert the light waves’ energy into neural impulses sent to your brain. Your brain processes the different parts of this visual input—including color, depth, movement, and form—separately but simultaneously. It interprets this information based on previously stored information and your expectations into a conscious perception of your friend.
Visual Organization
5-11 What was the main message of Gestalt psychology, and how do figure-ground and grouping principles help us perceive forms?

It’s one thing to understand how we see shapes and colors. But how do we organize and interpret those sights (or sounds or tastes or smells) so that they become meaningful perceptions—a rose in bloom, a familiar face, a sunset? First, let’s explore how we perceive form and depth, and how in changing conditions our perceptions remain stable.
“I am fearfully and wonderfully made.”
King David, Psalm 139:14
Early in the twentieth century, a group of German psychologists noticed that people who are given a cluster of sensations tend to organize them into a gestalt, a German word meaning a “form” or a “whole.” For example, look at FIGURE 5.19. Note that the individual elements of this figure, called a Necker cube, are really nothing but eight blue circles, with three white lines meeting near the center. When we view these elements all together, however, we see a cube that sometimes reverses direction. The Necker cube nicely illustrates a favorite saying of Gestalt psychologists: In perception, the whole may exceed the sum of its parts.
Over the years, the Gestalt psychologists demonstrated some principles we use to organize our sensations into perceptions. Underlying all of them is a basic truth: Our brain does more than register information about the world. Perception is not just opening a camera’s shutter and letting a picture print itself on the brain. We filter incoming information and we construct perceptions. Mind matters.
146
Form Perception
Imagine designing a video-computer system that, like your eye-brain system, could recognize faces at a glance. What abilities would it need?
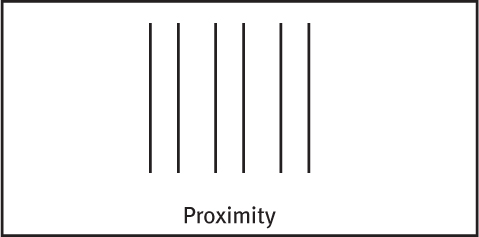
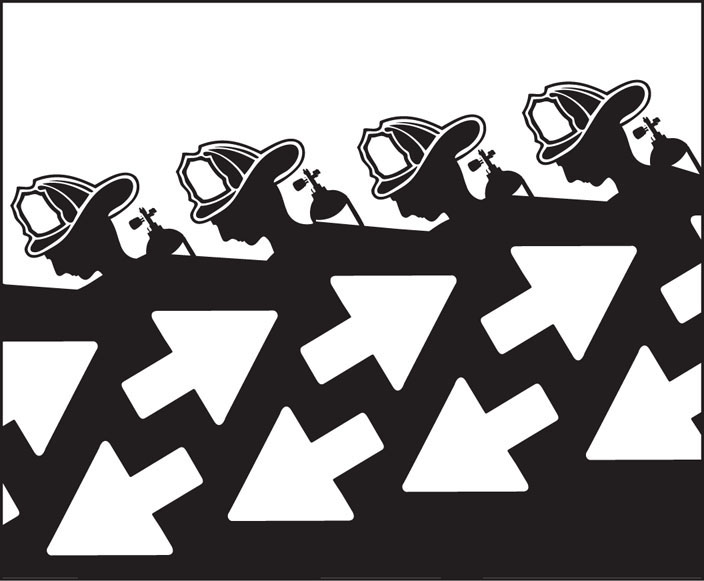
FIGURE AND GROUND To start with, the video-computer system would need to separate faces from their backgrounds. Likewise, in our eye-brain system, our first perceptual task is to perceive any object (the figure) as distinct from its surroundings (the ground). As you hear voices at a party, the one you attend to becomes the figure; all others are part of the ground. As you read, the words are the figure; the surrounding white space is the ground. Sometimes, the same stimulus can trigger more than one perception. In FIGURE 5.20, for example, the figure-ground relationship continually reverses as we see the arrows, then the firefighters running. But always we perceive a figure standing out from a ground.
GROUPING While telling figure from ground, we (and our video-computer system) also organize the figure into a meaningful form. Some basic features of a scene—such as color, movement, and light-dark contrast—we process instantly and automatically (Treisman, 1987). Our mind brings order and form to stimuli by following certain rules for grouping. These rules, identified by the Gestalt psychologists, and applied even by infants, illustrate how the perceived whole differs from the sum of its parts (Quinn et al., 2002; Rock & Palmer, 1990). Three examples:
Proximity We group nearby figures together. We see not six separate lines, but three sets of two lines.
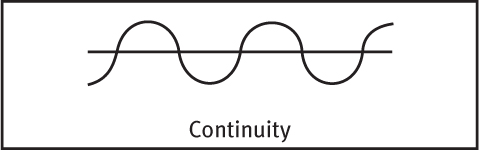
Continuity We perceive smooth, continuous patterns rather than discontinuous ones. This pattern could be a series of alternating semicircles, but we perceive it as two continuous lines—one wavy, one straight.
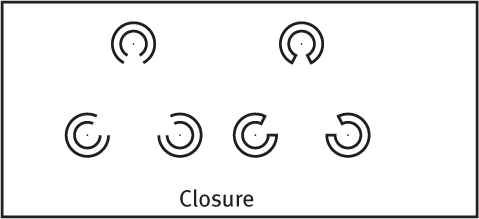
Closure We fill in gaps to create a complete, whole object. Thus, we assume that the circles on the left are complete but partially blocked by the (illusory) triangle. Add nothing more than little lines to close off the circles, and your brain stops constructing a triangle.
RETRIEVE + REMEMBER
Question 5.11
In terms of perception, a band’s lead singer would be considered _________(figure/ground), and the other musicians would be considered___________(figure/ground).
figure; ground
Question 5.12
What do we mean when we say that, in perception, “the whole is greater than the sum of its parts”?
Gestalt psychologists used this saying to describe our perceptual tendency to organize clusters of sensations into meaningful forms or groups.
Depth Perception
5-12 How do we use binocular and monocular cues to see the world in three dimensions?
From the two-dimensional images falling on our retinas, our amazing brain creates three-dimensional perceptions. Depth perception lets us estimate an object’s distance from us. At a glance, we can estimate the distance of an oncoming car or the height of a house. This ability is partly present at birth. Eleanor Gibson and Richard Walk (1960) discovered this using a model of a cliff with a drop-off area (which was covered by sturdy glass). These experiments were a product of Gibson’s scientific curiosity, which kicked in while she was picnicking on the rim of the Grand Canyon. She wondered: Would a toddler peering over the rim perceive the dangerous drop-off and draw back?

Back in their laboratory, Gibson and Walk placed 6- to 14-month-old infants on the edge of a safe canyon—a visual cliff (FIGURE 5.21). Their mothers then coaxed them to crawl out onto the glass. Most infants refused to do so, indicating that they could perceive depth.
Had they learned to perceive depth? Learning seems to be part of the answer, because crawling, no matter when it begins, seems to increase an infant’s fear of heights (Campos et al., 1992). Yet, as the researchers observed, mobile newborn animals come prepared to perceive depth. Even those with no visual experience—including young kittens, a day-old goat, and newly hatched chicks—will not venture across the visual cliff. Thus, it seems that biology prepares us to be wary of heights, and experience amplifies that fear.
147
How do we do it? How do we perceive depth—transforming two differing two-dimensional retinal images into a single three-dimensional perception? Our brain constructs these perceptions using information supplied by one or both eyes.
BINOCULAR CUES People who see with two eyes perceive depth thanks partly to binocular cues. Here’s an example. With both eyes open, hold two pens or pencils in front of you and touch their tips together. Now do so with one eye closed. A more difficult task, yes?
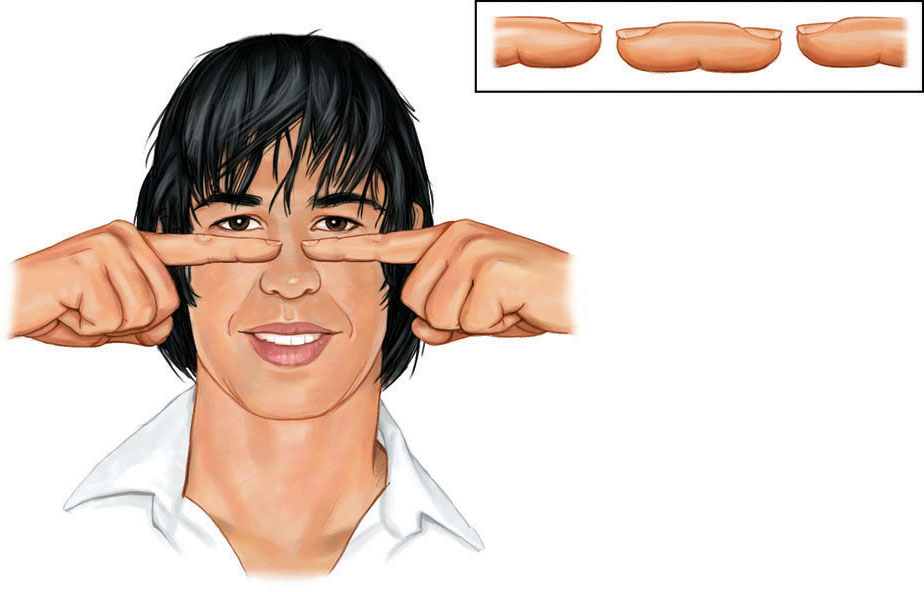
We use binocular cues to judge the distance of nearby objects. One such cue is retinal disparity. Because your eyes are about 2½ inches apart, your retinas receive slightly different images of the world. By comparing these two images, your brain can judge how close an object is to you. The greater the disparity (the difference) between the two retinal images, the closer the object. Try it. Hold your two index fingers, with the tips about half an inch apart, directly in front of your nose, and your retinas will receive quite different views. If you close one eye and then the other, you can see the difference. (You may also create a finger sausage, as in FIGURE 5.22.) At a greater distance—say, when you hold your fingers at arm’s length—the disparity is smaller.
We could very easily build this feature into our video-computer system. Moviemakers can exaggerate retinal disparity by filming a scene with two cameras placed a few inches apart. Viewers then wear glasses that allow the left eye to see only the image from the left camera, and the right eye to see only the image from the right camera. The resulting 3-D effect, as 3-D movie fans know, mimics or exaggerates normal retinal disparity.
MONOCULAR CUES How do we judge whether a person is 10 or 100 yards away? Retinal disparity won’t help us here, because there won’t be much difference between the images cast on our right and left retinas. At such distances, we depend on monocular cues (depth cues available to each eye separately). See FIGURE 5.23 for some examples.

148
RETRIEVE + REMEMBER
Question 5.13
How do we normally perceive depth?
We are normally able to perceive depth thanks to (1) binocular cues (that are based on our retinal disparity), and (2) monocular cues (that include relative height, relative size, interposition, linear perspective, light and shadow, and relative motion).
Perceptual Constancy
5-13 How do perceptual constancies help us construct meaningful perceptions?
So far, we have noted that our video-computer system must perceive objects as we do—as having a distinct form and location. Its next task is to recognize objects without being deceived by changes in their color, shape, or size. We call this top-down process perceptual constancy. This feat would be an enormous challenge for a video-computer system.
COLOR CONSTANCY Our experience of color depends on an object’s context. This would be clear if you viewed an isolated tomato through a paper tube. As the light—and thus the tomato’s reflected wavelengths—changed over the course of the day, the tomato’s color would also seem to change. But if you viewed that tomato without the tube, as one item in a bowl of fresh fruit and vegetables, its color would remain roughly constant as the lighting shifts. This perception of consistent color is known as color constancy.
149
“From there to here, from here to there, funny things are everywhere.”
Dr. Seuss, One Fish, Two Fish, Red Fish, Blue Fish, 1960
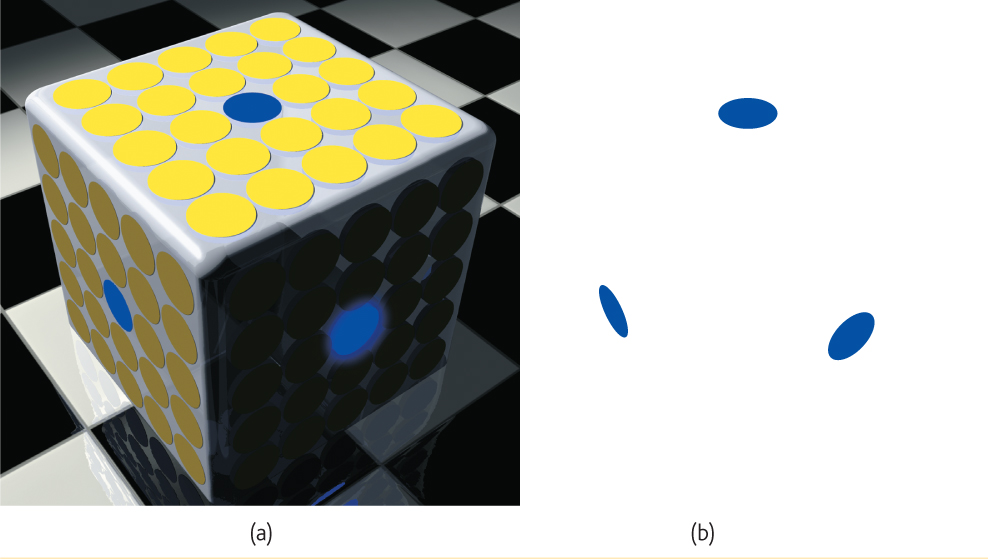
Color constancy is amazing. A blue poker chip under indoor lighting will, in sunlight, reflect wavelengths that match those reflected by a sunlit gold chip (Jameson, 1985). Yet bring a goldfinch indoors and it won’t look like a bluebird. The color is not in the bird’s feathers. You and I see color thanks to our brain’s ability to decode the meaning of the light reflected by an object relative to the objects surrounding it. FIGURE 5.24 dramatically illustrates the ability of a blue object to appear very different in three different contexts. Yet we have no trouble seeing these disks as blue. Paint manufacturers have learned this lesson. Knowing that your perception of a paint color will be determined by other colors in your home, many now offer trial samples you can test in that context. The take-home lesson: Comparisons govern our perceptions.
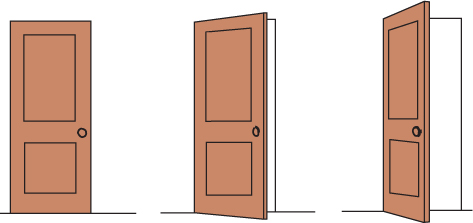
SHAPE AND SIZE CONSTANCIES Thanks to shape constancy, we usually perceive the form of familiar objects, such as the door in FIGURE 5.25, as constant even while our retinas receive changing images of them.
Thanks to size constancy, we perceive objects as having a constant size even while our distance from them varies. We assume a car is large enough to carry people, even when we see its tiny image from two blocks away. This assumption also shows the close connection between perceived distance and perceived size. Perceiving an object’s distance gives us cues to its size. Likewise, knowing its general size—that the object is a car—provides us with cues to its distance.
Even in size-distance judgments, however, we consider an object’s context. The dogs in FIGURE 5.7 earlier in this chapter cast identical images on our retinas. Using linear perspective as a cue (see FIGURE 5.23), our brain assumes that the pursuing dog is farther away. We therefore perceive it as larger. It isn’t.
The interplay between perceived size and perceived distance helps explain several well-known illusions, including the Moon illusion. The Moon looks up to 50 percent larger when near the horizon than when high in the sky. Can you imagine why? One reason is that cues to objects’ distances make the horizon Moon—like the distant dog in FIGURE 5.7—appear farther away. If it’s farther away, our brain assumes, it must be larger than the Moon high in the night sky (Kaufman & Kaufman, 2000). Take away the distance cues—by looking at the horizon Moon (or each dog) through a paper tube—and the object will immediately shrink.
Mistaken judgments like these reveal the workings of our normally effective perceptual processes. The perceived relationship between distance and size is usually valid. But under special circumstances it can lead us astray—as when helping to create the Moon illusion.
Form perception, depth perception, and perceptual constancy illuminate how we organize our visual experiences. Perceptual organization applies to our other senses, too. It explains why we may perceive a clock’s steady tick not as a tick-tick-tick-tick but as grouped sounds, say TICK-tick, TICK-tick. Perception, however, is more than organizing stimuli. Perception also requires what would be a challenge to our video-computer system: interpretation—finding meaning in what we perceive.
150
Visual Interpretation
The debate over whether our perceptual abilities spring from our nature or our nurture has a long history. To what extent do we learn to perceive? German philosopher Immanuel Kant (1724–1804) maintained that knowledge comes from our inborn ways of organizing sensory experiences. Psychology’s findings support this idea. We do come equipped to process sensory information. But British philosopher John Locke (1632–1704) argued that through our experiences we also learn to perceive the world. Psychology also supports this idea. We do learn to link an object’s distance with its size. So, just how important is experience? How much does it shape our perceptual interpretations?
Experience and Visual Perception
5-14 What does research on restored vision, sensory restriction, and perceptual adaptation reveal about the effects of experience on perception?
RESTORED VISION AND SENSORY RESTRICTION Writing to John Locke, a friend wondered what would happen if “a man born blind, and now adult, [was] taught by his touch to distinguish between a cube and a sphere.” Could he, if made to see, visually distinguish the two? Locke’s answer was No, because the man would never have learned to see the difference.

This clever question has since been put to the test with a few dozen adults who, though blind from birth, have later gained sight (Gregory, 1978; von Senden, 1932). Most were born with cataracts—clouded lenses that allowed them to see only light and shadows, rather as someone might see a foggy image through a Ping-Pong ball sliced in half. After surgery that removed the cataracts, the patients could tell the difference between figure and ground, and they could sense colors. This suggests that we are born with these aspects of perception. But much as Locke supposed, they often could not visually recognize objects that were familiar by touch.
In experiments, researchers have outfitted infant kittens and monkeys with goggles through which they could see only diffuse, unpatterned light (Wiesel, 1982). After infancy, when the goggles were removed, the animals’ reactions were much like those of humans born with cataracts. They could distinguish color, but not form. Their eyes were healthy. Their retinas still sent signals to their visual cortex. But the brain’s cortical cells had not developed normal connections. Thus, the animals remained functionally blind to shape. Experience guides the brain’s development as it forms pathways that affect our perceptions.
In humans and other animals, similar sensory restrictions later in life do no permanent harm. When researchers cover an adult animal’s eye for several months, its vision will be unaffected after the eye patch is removed. When surgeons remove cataracts that develop during late adulthood, most people are thrilled at the return to normal vision.
The effect of sensory restriction on infant cats, monkeys, and humans suggests there is a critical period (Chapter 3) for normal sensory and perceptual development. Nurture sculpts what nature has endowed. In less dramatic ways, it continues to do so throughout our lives. Our visual experience matters. For example, despite concerns about their social costs (more on this in Chapter 14), action video games sharpen spatial skills such as visual attention, eye-hand coordination and speed, and tracking multiple objects (Spence & Feng, 2010).

PERCEPTUAL ADAPTATION Given a new pair of glasses, we may feel a little strange, even dizzy. Within a day or two, we adjust. Our perceptual adaptation to changed visual input makes the world seem normal again. But imagine a far more dramatic new pair of glasses—one that shifts the apparent location of objects 40 degrees to the left. When you first put them on and toss a ball to a friend, it sails off to the left. Walking forward to shake hands with the person, you veer to the left.
Could you adapt to this distorted world? Baby chicks cannot. When fitted with such lenses, they have continued to peck where food grains seemed to be (Hess, 1956; Rossi, 1968). But we humans adapt to distorting lenses quickly. Within a few minutes, your throws would again be accurate, your stride on target. Remove the lenses and you would experience an aftereffect. At first your throws would err in the opposite direction, sailing off to the right. But again, within minutes you would adjust.
Indeed, given an even more radical pair of glasses—one that literally turns the world upside down—you could still adapt. Psychologist George Stratton (1896) experienced this when he invented, and for eight days wore, a device that flipped left to right and up to down, making him the first person to experience a right-side-up retinal image while standing upright. The ground was up, the sky was down.
151
At first, when Stratton wanted to walk, he found himself searching for his feet, which were now “up.” Eating was nearly impossible. He became nauseated and depressed. But Stratton persisted, and by the eighth day he could comfortably reach for an object in the right direction and walk without bumping into things. When Stratton finally removed the headgear, he readapted quickly.
In later experiments, people wearing such optical gear have even been able to ride a motorcycle, ski the Alps, and fly an airplane (Dolezal, 1982; Kohler, 1962). The world around them still seemed above their heads or on the wrong side. But by actively moving about in these topsy-turvy worlds, they adapted to the context and learned to coordinate their movements.