A.2 Significant Differences
LOQ A-
Data are “noisy.” The average score in one group could conceivably differ from the average score in another group not because of any real difference but merely because of chance fluctuations in the people sampled. How confidently, then, can we infer that an observed difference is not just a fluke—
When Is an Observed Difference Reliable?
In deciding when it is safe to generalize from a sample, we should keep three principles in mind:
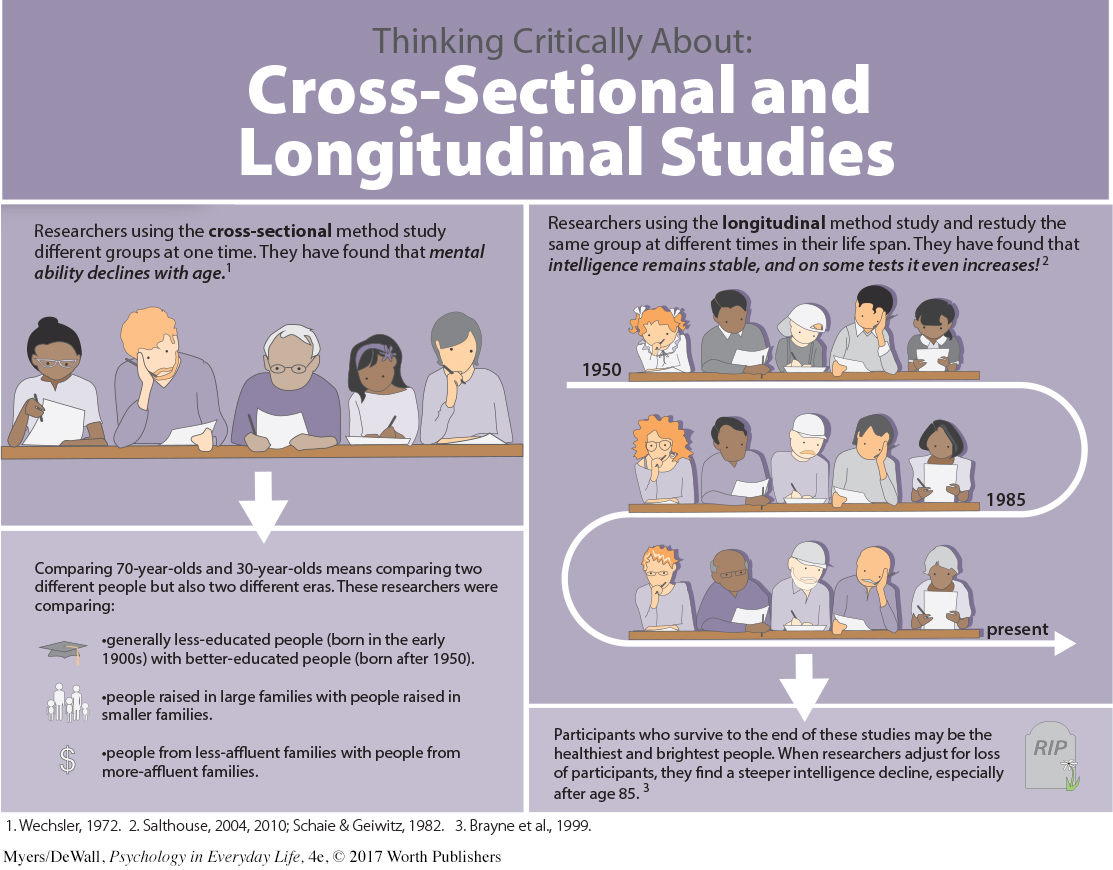
Representative samples are better than biased (unrepresentative) samples. The best basis for generalizing is from a representative sample of cases, not from the exceptional and memorable cases one finds at the extremes. Research never randomly samples the whole human population. Thus, it pays to keep in mind what population a study has sampled. (To see how an unrepresentative sample can lead you astray, see Thinking Critically About: Cross-
Sectional and Longitudinal Studies.) Less-
variable observations are more reliable than those that are more variable. As we noted earlier in the example of the basketball player whose game-to- game points were consistent, an average is more reliable when it comes from scores with low variability. More cases are better than fewer cases. An eager prospective student visits two university campuses, each for a day. At the first, the student randomly attends two classes and discovers both instructors to be witty and engaging. At the next campus, the two sampled instructors seem dull and uninspiring. Returning home, the student (discounting the small sample size of only two teachers at each institution) tells friends about the “great teachers” at the first school, and the “bores” at the second. Again, we know it but we ignore it: Averages based on many cases are more reliable (less variable) than averages based on only a few cases.
LOQ A-
The point to remember: Smart thinkers are not overly impressed by a few anecdotes. Generalizations based on a few unrepresentative cases are unreliable.
When Is an Observed Difference “Significant”?
Perhaps you’ve compared men’s and women’s scores on a laboratory test of aggression, and you’ve found a gender difference. But individuals differ. How likely is it that the difference you observed was just a fluke? Statistical testing can estimate the probability of the result occurring by chance.
Here is the underlying logic: When averages from two samples are each reliable measures of their respective populations (as when each is based on many observations that have small variability), then their difference is probably reliable as well. (Example: The less the variability in women’s and in men’s aggression scores, the more confidence we would have that any observed gender difference is reliable.) And when the difference between the sample averages is large, we have even more confidence that the difference between them reflects a real difference in their populations.

statistical significance a statistical statement of how likely it is that an obtained result occurred by chance.
In short, when sample averages are reliable, and when the difference between them is relatively large, we say the difference has statistical significance. This means that the observed difference is probably not due to chance variation between the samples.
In judging statistical significance, psychologists are conservative. They are like juries who must presume innocence until guilt is proven. For most psychologists, proof beyond a reasonable doubt means not making much of a finding unless the odds of its occurring by chance, if no real effect exists, are less than 5 percent.
When reading about research, you should remember that, given large enough samples, a difference between them may be “statistically significant” yet have little practical significance. For example, comparisons of intelligence test scores among hundreds of thousands of first-
The point to remember: Statistical significance indicates the likelihood that a result will happen by chance. But this does not say anything about the importance of the result.
Retrieve + Remember
Question 15.4
•Can you solve this puzzle?
The registrar’s office at the University of Michigan has found that usually about 100 students in Arts and Sciences have perfect marks at the end of their first term at the university. However, only about 10 to 15 students graduate with perfect marks. What do you think is the most likely explanation for the fact that there are more perfect marks after one term than at graduation (Jepson et al., 1983)?
ANSWER: Averages based on fewer courses are more variable, which guarantees a greater number of extremely low and high marks at the end of the first term.
Question 15.5
•________ statistics summarize data, while _______ statistics determine if data can be generalized to other populations.
ANSWERS: Descriptive; inferential
 For a 9.5-
For a 9.5-
cross-
longitudinal study research in which the same people are restudied and retested over a long period of time.