14.2 Messenger RNAs, Which Encode the Amino Acid Sequences of Proteins, Are Modified after Transcription in Eukaryotes
As soon as DNA was identified as the source of genetic information, it became clear that DNA cannot directly encode proteins. In eukaryotic cells, DNA resides in the nucleus, yet protein synthesis takes place in the cytoplasm. Geneticists recognized that an additional molecule must take part in transferring genetic information.
The results of studies of bacteriophage infection conducted in the late 1950s and early 1960s pointed to RNA as a likely candidate for this transport function. Bacteriophages inject their DNA into bacterial cells, where the DNA is replicated, and large amounts of phage protein are produced on the bacterial ribosomes. As early as 1953, Alfred Hershey discovered a type of RNA that was synthesized rapidly after bacteriophage infection. Findings from later studies showed that this short-lived RNA had a nucleotide composition similar to that of the phage DNA but quite different from that of the bacterial RNA. These observations were consistent with the idea that RNA was copied from DNA and that this RNA then directed the synthesis of proteins.
At the time, ribosomes were known to be somehow implicated in protein synthesis, and much of the RNA in a cell was known to be in the form of ribosomes. Ribosomes were believed to be the agents by which genetic information was moved to the cytoplasm for the production of protein. Using equilibrium density gradient centrifugation (see Figure 12.2), Sydney Brenner, François Jacob, and Matthew Meselson demonstrated in 1961 that it is not the case. They showed that new ribosomes are not produced during the burst of protein synthesis that accompanies phage infection (Figure 14.4). Ribosomes did not carry the genetic information needed to produce new phage proteins.

In a related experiment, François Gros and his colleagues infected E. coli cells with bacteriophages while adding radio-actively labeled uracil, which would become incorporated into newly produced phage RNA, to the medium. Gros and his coworkers found that the newly produced phage RNA was short-lived, lasting only a few minutes, and was associated with ribosomes but was distinct from them. They concluded that newly synthesized, short-lived RNA carries the genetic information for protein structure to the ribosome. The term messenger RNA was coined for this carrier.
The Structure of Messenger RNA
Messenger RNA functions as the template for protein synthesis; it carries genetic information from DNA to a ribosome and helps to assemble amino acids in their correct order. In bacteria, mRNA is transcribed directly from DNA but, in eukaryotes, a pre-mRNA (also called the primary transcript) is first transcribed from DNA and then processed to yield the mature mRNA. We will reserve the term mRNA for RNA molecules that have been completely processed and are ready to undergo translation.
In the mRNA, each amino acid in a protein is specified by a set of three nucleotides called a codon. Both prokaryotic and eukaryotic mRNAs contain three primary regions (Figure 14.5). The 5′ untranslated region (5′ UTR; sometimes called the leader) is a sequence of nucleotides at the 5′ end of the mRNA that does not encode any of the amino acids of a protein. In bacterial mRNA, this region contains a consensus sequence (UAAGGAGGU) called the Shine-Dalgarno sequence, which serves as the ribosome-binding site during translation (see Chapter 15); it is found approximately seven nucleotides upstream of the first codon translated into an amino acid (called the start codon). During translation, the Shine–Dalgarno sequence is complementary to and pairs with sequences found in one of the RNA molecules that make up the ribosome. Eukaryotic mRNA has no equivalent consensus sequence in its 5′ untranslated region. In eukaryotic cells, ribosomes bind to a modified 5′ end of mRNA, as discussed later in this chapter.
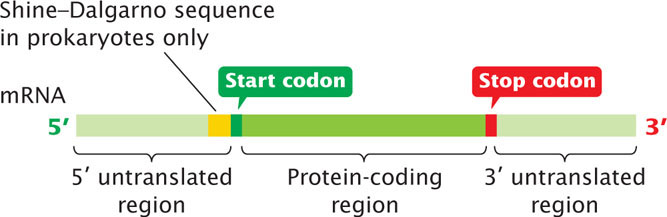
The next section of mRNA is the protein-coding region, which comprises the codons that specify the amino acid sequence of the protein. The protein-coding region begins with a start codon and ends with a stop codon. The last region of mRNA is the 3′ untranslated region (3′ UTR; sometimes called a trailer), a sequence of nucleotides at the 3′ end of the mRNA and not translated into protein. The 3′ UTR affects the stability of mRNA and the translation of the mRNA protein-coding sequence. View  Animation 14.1 to see how mutations in different regions of a gene affect the flow of information from genotype to phenotype.
Animation 14.1 to see how mutations in different regions of a gene affect the flow of information from genotype to phenotype.
CONCEPTS
Messenger RNA molecules contain three main regions: a 5′ untranslated region, a protein-coding region, and a 3′ untranslated region. The 5′ and 3′ untranslated regions do not encode any amino acids of a protein, but contain information that is important in translation, RNA stability, and regulation of gene expression.
Pre-mRNA Processing
In bacterial cells, transcription and translation take place simultaneously; while the 3′ end of an mRNA is undergoing transcription, ribosomes attach to the Shine–Dalgarno sequence near the 5′ end and begin translation. Because transcription and translation are coupled, bacterial mRNA has little opportunity to be modified before protein synthesis. In contrast, transcription and translation are separated in both time and space in eukaryotic cells. Transcription takes place in the nucleus, whereas translation takes place in the cytoplasm; this separation provides an opportunity for eukaryotic RNA to be modified before it is translated. Indeed, eukaryotic mRNA is extensively altered after transcription. Changes are made to the 5′ end, the 3′ end, and the protein-coding section of the RNA molecule (Table 14.2).
| Modification | Function |
|---|---|
| Addition of 5′ cap | Facilitates binding of ribosome to 5′ end of mRNA, increases mRNA stability, enhances RNA splicing |
| 3′ cleavage and addition of poly(A) tail | Increases stability of mRNA, facilitates binding of ribosome to mRNA |
| RNA splicing | Removes noncoding introns from pre-mRNA, facilitates export of mRNA to cytoplasm, allows for multiple proteins to be produced through alternative splicing |
| RNA editing | Alters nucleotide sequence of mRNA |
The Addition of the 5′ Cap
One type of modification of eukaryotic pre-mRNA is the addition of a structure called a 5′ cap. The cap consists of an extra nucleotide at the 5′ end of the mRNA and methyl groups (CH3) on the base in the newly added nucleotide and on the 2′-OH group of the sugar of one or more nucleotides at the 5′ end (Figure 14.6). The addition of the cap takes place rapidly after the initiation of transcription and, as will be discussed in more depth in Chapter 15, functions in the initiation of translation. Cap-binding proteins recognize the cap and attach to it; a ribosome then binds to these proteins and moves downstream along the mRNA until the start codon is reached and translation begins. The presence of a 5′ cap also increases the stability of mRNA and influences the removal of introns.

As noted in the discussion of transcription in Chapter 13, three phosphate groups are present at the 5′ end of all RNA molecules because phosphate groups are not cleaved from the first ribonucleoside triphosphate in the transcription reaction. The 5′ end of pre-mRNA can be represented as 5′-pppNpNpN…, in which the letter “N” represents a ribonucleotide and “p” represents a phosphate. Shortly after the initiation of transcription, one of these phosphate groups is removed and a guanine nucleotide is added (see Figure 14.6). This guanine nucleotide is attached to the pre-mRNA by a unique 5′-5′ bond, which is quite different from the usual 5′–3′ phosphodiester bond that joins all the other nucleotides in RNA. One or more methyl groups are then added to the 5′ end; the first of these methyl groups is added to position 7 of the base of the terminal guanine nucleotide, making the base 7-methylguanine. Next, a methyl group may be added to the 2′ position of the sugar in the second and third nucleotides (see Figure 14.6). Rarely, additional methyl groups may be attached to the bases of the second and third nucleotides of the pre-mRNA.
Several different enzymes take part in the addition of the 5′ cap. The initial step is carried out by an enzyme that associates with RNA polymerase II. Because neither RNA polymerase I nor RNA polymerase III have this associated enzyme, RNA molecules transcribed by these polymerases (rRNAs, tRNAs, and some snRNAs) are not capped.
The Addition of the Poly(A) Tail
A second type of modification to eukaryotic mRNA is the addition of 50 to 250 or more adenine nucleotides at the 3′ end, forming a poly(A) tail. These nucleotides are not encoded in the DNA but are added after transcription (Figure 14.7) in a process termed polyadenylation. Many eukaryotic genes transcribed by RNA polymerase II are transcribed well beyond the end of the coding sequence (see Chapter 13); most of the extra material at the 3′ end is then cleaved and the poly(A) tail is added. For some pre-mRNA molecules, more than 1000 nucleotides may be removed from the 3′ end before polyadenylation.
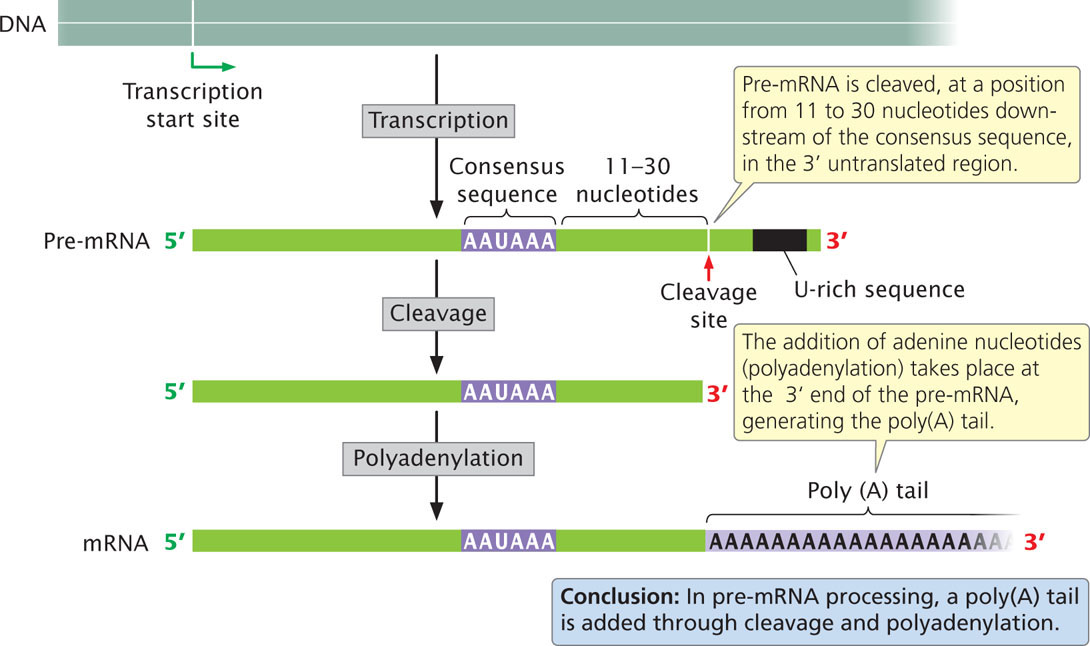
Processing of the 3′ end of pre-mRNA requires sequences, termed the polyadenylation signal, both upstream and downstream of the site where cleavage occurs. The consensus sequence AAUAAA is usually from 11 to 30 nucleotides upstream of the cleavage site (see Figure 14.7) and determines the point at which cleavage will take place. A sequence rich in uracil nucleotides (or in guanine and uracil nucleotides) is typically downstream of the cleavage site. A large number of proteins take part in finding the cleavage site and removing the 3′ end. After cleavage has been completed, adenine nucleotides are added without a template to the new 3′ end, creating the poly(A) tail. The poly(A) tail confers stability on many mRNAs, increasing the time during which the mRNA remains intact and available for translation before it is degraded by cellular enzymes. The stability conferred by the poly(A) tail depends on the proteins that attach to the tail and on its length. The poly(A) tail also facilitates attachment of the ribosome to the mRNA and plays a role in export of the mRNA into the cytoplasm.
Poly(U) tails are added to the 3′ ends of some mRNAs, microRNAs, and small nuclear RNAs. Although the function of poly(U) tails is still under investigation, evidence suggests that poly(U) tails on some mRNAs may facilitate their degradation. ![]() TRY PROBLEM 29
TRY PROBLEM 29
CONCEPTS
Eukaryotic pre-mRNAs are processed at their 5′ and 3′ ends. A cap, consisting of a modified nucleotide and several methyl groups, is added to the 5′ end. The cap facilitates the binding of a ribosome, increases the stability of the mRNA, and may affect the removal of introns. Processing at the 3′ end includes cleavage downstream of an AAUAAA consensus sequence and the addition of a poly(A) tail.
 CONCEPT CHECK 3
CONCEPT CHECK 3Why are pre-mRNAs capped, but tRNAs and rRNAs aren’t?
RNA Splicing
The other major type of modification of eukaryotic pre-mRNA is the removal of introns by RNA splicing. This modification takes place in the nucleus, before the RNA moves to the cytoplasm.
Consensus sequences and the Spliceosome
Splicing requires the presence of three sequences in the intron. One end of the intron is referred to as the 5′ splice site, and the other end is the 3′ splice site (Figure 14.8); these splice sites possess short consensus sequences. Most introns in pre-mRNAs begin with GU and end with AG, indicating that these sequences play a crucial role in splicing. Indeed, changing a single nucleotide at either of these sites prevents splicing.

The third sequence important for splicing is at the branch point, which is an adenine nucleotide that lies from 18 to 40 nucleotides upstream of the 3′ splice site (see Figure 14.8). The sequence surrounding the branch point does not have a strong consensus. The deletion or mutation of the adenine nucleotide at the branch point prevents splicing.
Splicing takes place within a large structure called the spliceosome, which is one of the largest and most complex of all molecular structures. The spliceosome consists of five RNA molecules and almost 300 proteins. The RNA components are small nuclear RNAs (snRNAs, see Chapter 13) ranging in length from 107 to 210 nucleotides; these snRNAs associate with proteins to form small nuclear ribonucleoprotein particles (snRNPs). Each snRNP contains a single snRNA molecule and multiple proteins. The spliceosome is composed of five snRNPs (U1, U2, U4, U5, and U6), and some proteins not associated with an snRNA.
CONCEPTS
Introns in nuclear genes contain three consensus sequences critical to splicing: a 5′ splice site, a 3′ splice site, and a branch point. The splicing of pre-mRNA takes place within a large complex called the spliceosome, which consists of snRNAs and proteins.
CONCEPT CHECK 4If a splice site were mutated so that splicing did not take place, what would be the effect on the mRNA?
- It would be shorter than normal.
- It would be longer than normal.
- It would be the same length but would encode a different protein.
The Process of Splicing
Before splicing takes place, an intron lies between an upstream exon (exon 1) and a downstream exon (exon 2), as shown in Figure 14.9. Pre-mRNA is spliced in two distinct steps. In the first step of splicing, the pre-mRNA is cut at the 5′ splice site. This cut frees exon 1 from the intron, and the 5′ end of the intron attaches to the branch point; the intron folds back on itself, forming a structure called a lariat. In this reaction, the guanine nucleotide in the consensus sequence at the 5′ splice site bonds with the adenine nucleotide at the branch point through a transesterification reaction. In this reaction, both 5′ cleavage and lariat formation occur in a single step. The result is that the 5′ phosphate group of the guanine nucleotide is now attached to the 2′-OH group of the adenine nucleotide at the branch point (see Figure 14.9).

In the second step of RNA splicing, a cut is made at the 3′ splice site and, simultaneously, the 3′ end of exon 1 becomes covalently attached (spliced) to the 5′ end of exon 2. The intron is released as a lariat. Eventually, a lariat debranching enzyme breaks the bond at the branch point, producing a linear intron that is rapidly degraded by nuclear enzymes. The mature mRNA consisting of the exons spliced together is exported to the cytoplasm, where it is translated.
These splicing reactions take place within the spliceosome, which assembles on the pre-mRNA in a step-by-step fashion and carries out the splicing reactions (Figure 14.10). A crucial feature of the process is a series of interactions between the mRNA and the snRNAs and between different snRNAs. These interactions depend on complementary base pairing between the different RNA molecules and bring the essential components of the pre-mRNA transcript and the spliceosome close together, which make splicing possible. Key catalytic steps in the splicing process are carried out by the snRNAs that constitute the spliceosome.
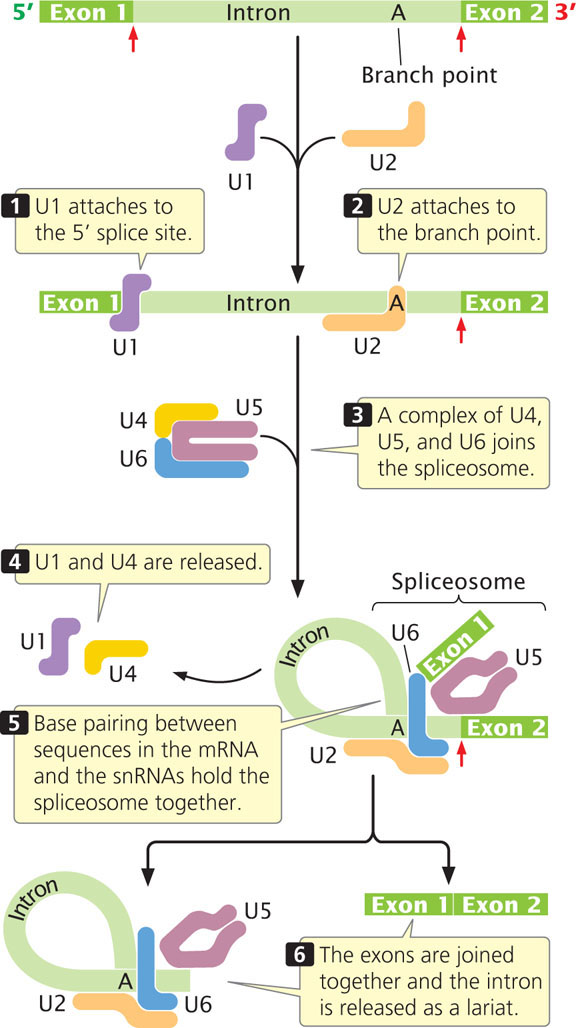
First, snRNP U1 attaches to the 5′ splice site, and then U2 attaches to the branch point. A complex consisting of U4, U5, and U6 (which form a single snRNP) joins the spliceosome. This addition causes a conformational change in the spliceosome, the intron loops over, and the 5′ splice site is brought close to the branch point. Particles U1 and U4 dissociate from the spliceosome, with the subsequent formation of base pairs between U6 and U2 and between U6 and the 5′ splice site. The 5′ splice site, 3′ splice site, and branch point are in close proximity, held together by the spliceosome. The two transesterification reactions take place, joining the two exons together and releasing the intron as a lariat.
Most mRNAs are produced from a single pre-mRNA molecule from which the exons are spliced together. However, in a few organisms (principally nematodes and trypanosomes), mRNAs may be produced by splicing together sequences from two or more different RNA molecules; this process is called trans-splicing.
Many human genetic diseases arise from mutations that affect pre-mRNA splicing; indeed, about 15% of single-base substitutions that result in human genetic diseases alter pre-mRNA splicing. Some of these mutations interfere with recognition of the normal 5′ and 3′ splice sites. Others create new splice sites, as was the case with the mutation that caused the royal hemophilia discussed in the introduction to this chapter. ![]() TRY PROBLEM 24
TRY PROBLEM 24
RNA splicing, which takes place in the nucleus, must be done before the RNA can move into the cytoplasm. Incompletely spliced RNAs remain in the nucleus until splicing is complete or until the pre-mRNA is degraded. Immediately after splicing, a group of proteins called the exon-junction complex (EJC) is deposited approximately 20 nucleotides upstream of each exon–exon junction on the mRNA. The EJC promotes the export of the mRNA from the nucleus into the cytoplasm.
CONCEPTS
Intron splicing of nuclear genes is a two-step process: (1) the 5′ end of the intron is cleaved and attached to the branch point to form a lariat and (2) the 3′ end of the intron is cleaved and the ends of the two exons are spliced together. In the process, the exons are joined and the intervening intron is removed. These reactions take place within the spliceosome.
Minor Splicing
Some introns in the pre-mRNAs of multicellular eukaryotes utilize a different process of intron removal known as minor splicing. Introns that undergo minor splicing have different consensus sequences at the 5′ splice site and branch point and use a minor spliceosome, which contains a somewhat different set of snRNAs. Some 700-800 genes in the human genome contain introns that undergo minor splicing.
Self-Splicing Introns
Some introns are self-splicing—they possess the ability to remove themselves from an RNA molecule. These self-splicing introns fall into two major categories. Group I introns are found in a variety of genes, including some rRNA genes in protists, some mitochondrial genes in fungi, and even some bacterial and bacteriophage genes. Although the lengths of group I introns vary, all of them fold into a common secondary structure with nine looped stems (Figure 14.11a), which are necessary for splicing.

Group II introns, present in genes of eubacteria, archaea, and eukaryotic organelles, also have the ability to self-splice. All group II introns also fold into secondary structures (Figure 14.11b). The splicing of group II introns is accomplished by a mechanism that has some similarities to the spliceosomal-mediated splicing of nuclear genes, and splicing generates a lariat structure. Because of these similarities, group II introns and nuclear pre-mRNA introns have been suggested to be evolutionarily related; perhaps the nuclear introns evolved from self-splicing group II introns and later adopted the proteins and snRNAs of the spliceosome to carry out the splicing reaction.
CONCEPTS
Some introns are removed by the minor splicing system. Other introns are self-splicing and consist of two types: group I introns and group II introns. These introns have complex secondary structures that enable them to catalyze their excision from RNA molecules without the aid of enzymes or other proteins.
Alternative Processing Pathways
A finding that complicates the view of a gene as a sequence of nucleotides that specifies the amino acid sequence of a protein (see section on The Concept of the Gene Revisited) is the existence of alternative processing pathways. In these pathways, a single pre-mRNA is processed in different ways to produce alternative types of mRNA, resulting in the production of different proteins from the same DNA sequence.
One type of alternative processing is alternative splicing, in which the same pre-mRNA can be spliced in more than one way to yield multiple mRNAs that are translated into different amino acid sequences and thus different proteins (Figure 14.12a). Another type of alternative processing requires the use of multiple 3′ cleavage sites (Figure 14.12b) where two or more potential sites for cleavage and polyadenylation are present in the pre-mRNA. In the example in Figure 14.12b, cleavage at the first site produces a relatively short mRNA compared with the mRNA produced through cleavage at the second site. The use of an alternative cleavage site may or may not produce a different protein, depending on whether the position of the site is before or after the termination codon.

Both alternative splicing and multiple 3′ cleavage sites can exist in the same pre-mRNA transcript. An example is seen in the mammalian gene that encodes calcitonin; this gene contains six exons and five introns (Figure 14.13a). The entire gene is transcribed into pre-mRNA (Figure 14.13b). There are two possible 3′ cleavage sites. In cells of the thyroid gland, 3′ cleavage and polyadenylation take place after the fourth exon to produce a mature mRNA consisting of exons 1, 2, 3, and 4 (Figure 14.13c). This mRNA is translated into the hormone calcitonin, which is produced by the thyroid gland and regulates levels of calcium. In brain cells, the identical pre-mRNA is transcribed from DNA, but cleavage and polyadenylation take place after the sixth exon, yielding an initial transcript that includes all six exons. During splicing, exon 4 is removed, and so only exons 1, 2, 3, 5, and 6 are present in the mature mRNA (Figure 14.13d). When translated, this mRNA produces a protein called calcitonin-gene-related peptide (CGRP), which has an amino acid sequence quite different from that of calcitonin. CGRP causes dilation of blood vessels and can function in transmission of pain. Some research suggests that CGRP is involved in the development of migraine headaches. Alternative splicing may produce different combinations of exons in the mRNA, but the order of the exons is not usually changed.
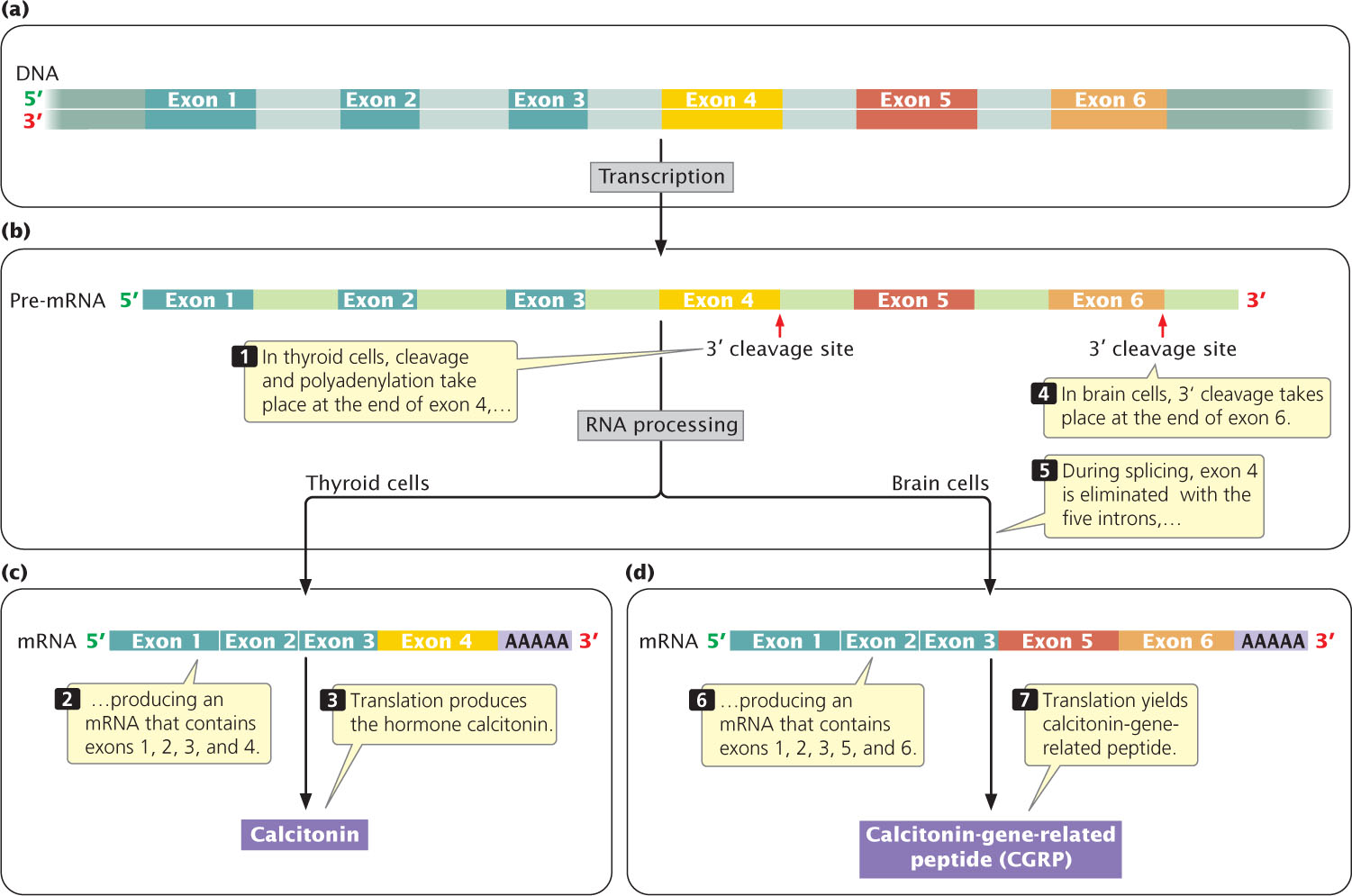
Alternative processing of pre-mRNAs is common in multicellular eukaryotes. For example, researchers estimate that more than 90% of all human genes undergo alternative splicing. Often the form of splicing differs between human tissues: human brain and liver tissues have more alternatively spliced RNA compared with other tissues. Sometimes splicing even varies from one person to another. Different processing pathways contribute to gene regulation, as will be discussed in Chapter 17.
Alternative splicing may play a role in organism complexity. The complete sequencing of the genomes of numerous organisms (see Chapter 20) has led to the conclusion that an organism’s number of genes is not correlated with the organism’s complexity. For example, fruit flies have only about 14,000 genes, whereas anatomically simpler nematode worms have 19,000 genes. The plant Arabidopsis thaliana has about 20,000 genes, almost as many as humans have. If anatomically simple organisms have as many genes as complex organisms have, how is developmental complexity encoded in the genome? A possible answer is alternative processing, which can produce multiple proteins from a single gene and is an important source of protein diversity in vertebrates.
Recent research demonstrates that even closely related species often differ in how their pre-mRNAs are spliced, and alternative splicing may have played an important role in speciation (see Chapter 26).
CONCEPTS
Alternative splicing enables exons to be spliced together in different combinations to yield mRNAs that encode different proteins. Alternative 3′ cleavage sites allow pre-mRNA to be cleaved at different sites.
CONCEPT CHECK 5Alternative 3′ cleavage sites result in
- multiple genes of different lengths.
- multiple pre-mRNAs of different lengths.
- multiple mRNAs of different lengths.
- all of the above.
RNA Editing
The assumption that all information about the amino acid sequence of a protein resides in DNA is violated by a process called RNA editing. In RNA editing, the coding sequence of an mRNA molecule is altered after transcription, so the protein has an amino acid sequence that differs from that encoded by the gene.
RNA editing was first detected in 1986 when the coding sequences of mRNAs were compared with the coding sequences of the DNA from which they had been transcribed. In some nuclear genes in mammalian cells and in some mitochondrial genes in plant cells, there had been substitutions in some of the nucleotides of the mRNA. More extensive RNA editing has been found in the mRNA for some mitochondrial genes in trypanosome parasites (which cause African sleeping sickness; Figure 14.14). In some mRNAs of these organisms, more than 60% of the sequence is determined by RNA editing. Different types of RNA editing have now been observed in mRNAs, tRNAs, and rRNAs from a wide range of organisms; the types include the insertion and the deletion of nucleotides and the conversion of one base into another.

If the modified sequence in an edited RNA molecule doesn’t come from a DNA template, then how is it specified? A variety of mechanisms can bring about changes in RNA sequences. In some cases, molecules called guide RNAs (gRNAs) play a crucial role. A gRNA contains sequences that are partly complementary to segments of the pre-edited RNA, and the two molecules undergo base pairing in these sequences (Figure 14.15). After the mRNA is anchored to the gRNA, the mRNA undergoes cleavage and nucleotides are added, deleted, or altered according to the template provided by gRNA. In other cases, enzymes bring about base conversion. In humans, for example, a gene is transcribed into mRNA that encodes a lipid-transporting polypeptide called apolipoprotein-B100, which has 4563 amino acids and is synthesized in liver cells. A truncated form of the protein called apolipoprotein-B48—with only 2153 amino acids—is synthesized in intestinal cells through editing of the apolipoprotein-B100 mRNA. In this editing, an enzyme deaminates a cytosine base, converting it into uracil. This conversion changes a codon that specifies the amino acid glutamine into a stop codon that prematurely terminates translation, resulting in the shortened protein. ![]() TRY PROBLEM 34
TRY PROBLEM 34

CONCEPTS
Individual nucleotides in the interior of pre-mRNA may be changed, added, or deleted by RNA editing. The amino acid sequence produced by the edited mRNA is not the same as that encoded by DNA.
CONCEPT CHECK 6What specifies the modified sequence of nucleotides found in an edited RNA molecule?
CONNECTING CONCEPTS
Chapters 13 and 14 introduced a number of different components of genes and RNA molecules, including promoters, 5′ untranslated regions, coding sequences, introns, 3′ untranslated regions, poly(A) tails, and caps. Let’s see how some of these components are combined to create a typical eukaryotic gene and how a mature mRNA is produced from them.
The promoter, which typically lies upstream of the transcription start site, is necessary for transcription to take place but is itself not usually transcribed when protein-encoding genes are transcribed by RNA polymerase II (Figure 14.16a). Farther upstream or downstream of the start site, there may be enhancers—DNA sequences that also regulate transcription.

In transcription, all the nucleotides between the transcription start site and the termination site are transcribed into pre-mRNA, including exons, introns, and a long 3′ end that is later cleaved from the transcript (Figure 14.16b). Notice that the 5′ end of the first exon contains the sequence that encodes the 5′ untranslated region and that the 3′ end of the last exon contains the sequence that encodes the 3′ untranslated region.
The pre-mRNA is then processed to yield a mature mRNA. The first step in this processing is the addition of a cap to the 5′ end of the pre-mRNA (Figure 14.16c). Next, the 3′ end is cleaved at a site downstream of the AAUAAA consensus sequence in the last exon (Figure 14.16d). Immediately after cleavage, a poly(A) tail is added to the 3′ end (Figure 14.16e). Finally, the introns are removed to yield the mature mRNA (Figure 14.16f). The mRNA now contains 5′ and 3′ untranslated regions, which are not translated into amino acids, and the nucleotides that carry the protein-coding sequences. You can explore the consequences of failed RNA processing by viewing and interacting with Animation 14.2.
The nucleotide sequence of a small gene (the human interleukin 2 gene), with these components identified, is presented in Figure 14.17.
