15.2 The Genetic Code Determines How the Nucleotide Sequence Specifies the Amino Acid Sequence of a Protein
In 1953, James Watson and Francis Crick solved the structure of DNA and identified the base sequence as the carrier of genetic information (see Chapter 10). However, the way in which the base sequence of DNA specifies the amino acid sequences of proteins (the genetic code) remained elusive for another 10 years.
One of the first questions about the genetic code to be addressed was how many nucleotides are necessary to specify a single amino acid. The set of nucleotides that encode a single amino acid—the basic unit of the genetic code—is a codon (see Chapter 14). Many early investigators recognized that codons must contain a minimum of three nucleotides. Each nucleotide position in mRNA can be occupied by one of four bases: A, G, C, or U. If a codon consisted of a single nucleotide, only four different codons (A, G, C, and U) would be possible, which is not enough to encode the 20 different amino acids commonly found in proteins. If codons were made up of two nucleotides each (i.e., GU, AC, etc.), there would be 4 × 4 = 16 possible codons—still not enough to encode all 20 amino acids. With three nucleotides per codon, there are 4 × 4 × 4 = 64 possible codons, which is more than enough to specify 20 different amino acids. Therefore, a triplet code requiring three nucleotides per codon is the most efficient way to encode all 20 amino acids. Using mutations in bacteriophage, Francis Crick and his colleagues confirmed in 1961 that the genetic code is indeed a triplet code. ![]() TRY PROBLEMS 20 AND 21
TRY PROBLEMS 20 AND 21
CONCEPTS
The genetic code is a triplet code, in which three nucleotides encode each amino acid in a protein.
 CONCEPT CHECK 3
CONCEPT CHECK 3A codon is
- one of three nucleotides that encode an amino acid.
- three nucleotides that encode an amino acid.
- three amino acids that encode a nucleotide.
- one of four bases in DNA.
Breaking the Genetic Code
When it had been firmly established that the genetic code consists of codons that are three nucleotides in length, the next step was to determine which groups of three nucleotides specify which amino acids. Logically, the easiest way to break the code would have been to determine the base sequence of a piece of RNA, add it to a test tube containing all the components necessary for translation, and allow it to direct the synthesis of a protein. The amino acid sequence of the newly synthesized protein could then be determined, and its sequence could be compared with that of the RNA. Unfortunately, there was no way at that time to determine the nucleotide sequence of a piece of RNA, so indirect methods were necessary to break the code.
The Use of Homopolymers
The first clues to the genetic code came in 1961, from the work of Marshall Nirenberg and Johann Heinrich Matthaei. These investigators created synthetic RNAs by using an enzyme called polynucleotide phosphorylase. Unlike RNA polymerase, polynucleotide phosphorylase does not require a template; it randomly links together any RNA nucleotides that happen to be available. The first synthetic mRNAs used by Nirenberg and Matthaei were homopolymers, RNA molecules consisting of a single type of nucleotide. For example, by adding polynucleotide phosphorylase to a solution of uracil nucleotides, they generated RNA molecules that consisted entirely of uracil nucleotides and thus contained only UUU codons (Figure 15.8). These poly(U) RNAs were then added to 20 tubes, each containing the components necessary for translation and all 20 amino acids. A different amino acid was radioactively labeled in each of the 20 tubes. Radioactive protein appeared in only one of the tubes—the one containing labeled phenylalanine (see Figure 15.8). This result showed that the codon UUU specifies the amino acid phenylalanine. The results of similar experiments using poly(C) and poly(A) RNA demonstrated that CCC encodes proline and AAA encodes lysine; for technical reasons, the results from poly(G) were uninterpretable.
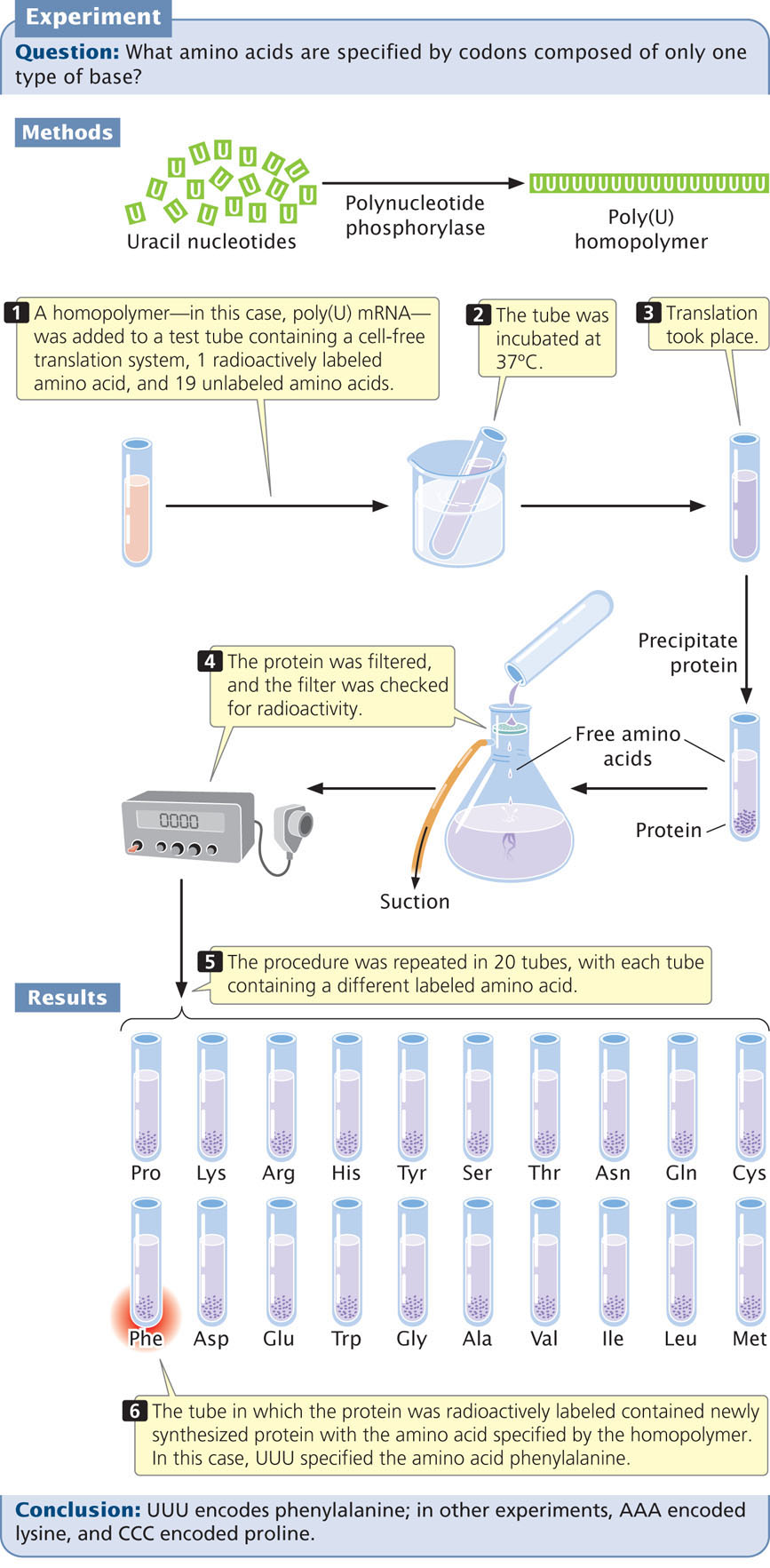
The use Of Random Copolymers
To gain information about additional codons, Nirenberg and his colleagues created synthetic RNAs containing two or three different bases. Because polynucleotide phosphorylase incorporates nucleotides randomly, these RNAs contained random mixtures of the bases and are thus called random copolymers. For example, when adenine and cytosine nucleotides are mixed with polynucleotide phosphorylase, the RNA molecules produced have eight different codons: AAA, AAC, ACC, ACA, CAA, CCA, CAC, and CCC. These poly(AC) RNAs produced proteins containing six different amino acids: asparagine, glutamine, histidine, lysine, proline, and threonine.
The proportions of the different amino acids in the proteins depended on the ratio of the two nucleotides used in creating the synthetic mRNA, and the theoretical probability of finding a particular codon could be calculated from the ratios of the bases. If a 4 : 1 ratio of C to A were used in making the RNA, then the probability of C being at any given position in a codon is 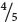 and the probability of A being in it is
and the probability of A being in it is 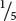 . With random incorporation of bases, the probability of any one of the codons with two Cs and one A (CCA, CAC, or ACC) should be
×
×
=
. With random incorporation of bases, the probability of any one of the codons with two Cs and one A (CCA, CAC, or ACC) should be
×
×
= 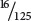 = 0.13, or 13%, and the probability of any codon with two As and one C (AAC, ACA, or CAA) should be
×
×
=
= 0.13, or 13%, and the probability of any codon with two As and one C (AAC, ACA, or CAA) should be
×
×
= 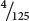 = 0.032, or about 3%. Therefore, an amino acid encoded by two Cs and one A should be more common than an amino acid encoded by two As and one C. By comparing the percentages of amino acids in proteins produced by random copolymers with the theoretical frequencies expected for the codons, Nirenberg and his colleagues could derive information about the base composition of the codons. These experiments revealed nothing, however, about the codon base sequence; histidine was clearly encoded by a codon with two Cs and one A, but whether that codon was ACC, CAC, or CCA was unknown. There were other problems with this method: the theoretical calculations depended on the random incorporation of bases, which did not always occur, and, because the genetic code is redundant, sometimes several different codons specify the same amino acid.
= 0.032, or about 3%. Therefore, an amino acid encoded by two Cs and one A should be more common than an amino acid encoded by two As and one C. By comparing the percentages of amino acids in proteins produced by random copolymers with the theoretical frequencies expected for the codons, Nirenberg and his colleagues could derive information about the base composition of the codons. These experiments revealed nothing, however, about the codon base sequence; histidine was clearly encoded by a codon with two Cs and one A, but whether that codon was ACC, CAC, or CCA was unknown. There were other problems with this method: the theoretical calculations depended on the random incorporation of bases, which did not always occur, and, because the genetic code is redundant, sometimes several different codons specify the same amino acid.
The Use Of Ribosome-Bound tRNAs
To overcome the limitations of random copolymers, Nirenberg and Philip Leder developed another technique in 1964 that used ribosome-bound tRNAs. They found that a very short sequence of mRNA—even one consisting of a single codon—would bind to a ribosome. The codon on the short mRNA would then base pair with the matching anticodon on a transfer RNA that carried the amino acid specified by the codon (Figure 15.9). Short mRNAs that were bound to ribosomes were mixed with tRNAs and amino acids, and this mixture was passed through a nitrocellulose filter. The tRNAs that were paired with the ribosome-bound mRNA stuck to the filter, whereas unbound tRNAs passed through it. The advantage of this system was that it could be used with very short synthetic mRNA molecules that could be synthesized with a known sequence. Nirenberg and Leder synthesized more than 50 short mRNAs with known codons and added them individually to a mixture of ribosomes and tRNAs. They then isolated the tRNAs that were bound to the mRNA and ribosomes and determined which amino acids were present on the bound tRNAs. For example, synthetic RNA with the codon GUU retained a tRNA to which valine was attached, whereas RNAs with the codons UGU and UUG did not. Using this method, Nirenberg and his colleagues were able to determine the amino acids encoded by more than 50 codons.
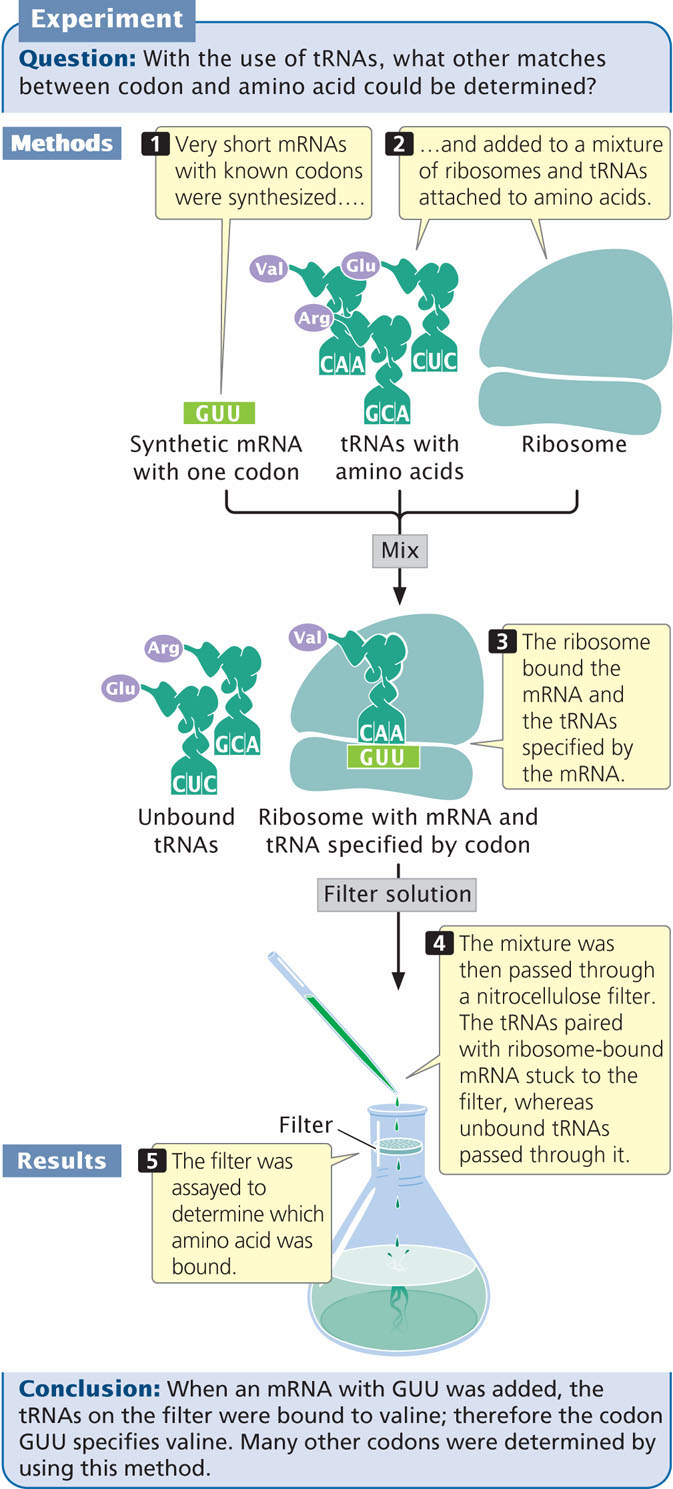
Other experiments provided additional information about the genetic code, and it was fully deciphered by 1968. In the next section, we will examine some of the features of the code, which is so important to modern biology that Francis Crick compared its place to that of the periodic table of the elements in chemistry.
The Degeneracy of the Code
One amino acid is encoded by three consecutive nucleotides in mRNA, and each nucleotide can have one of four possible bases (A, G, C, and U) at each nucleotide position, thus permitting 43 = 64 possible codons (Figure 15.10). Three of these codons are stop codons, specifying the end of translation. Thus, 61 codons, called sense codons, encode amino acids. Because there are 61 sense codons and only 20 different amino acids commonly found in proteins, the code contains more information than is needed to specify the amino acids and is said to be a degenerate code. This expression does not mean that the genetic code is depraved; degenerate is a term that Francis Crick borrowed from quantum physics, where it describes multiple physical states that have equivalent meaning.
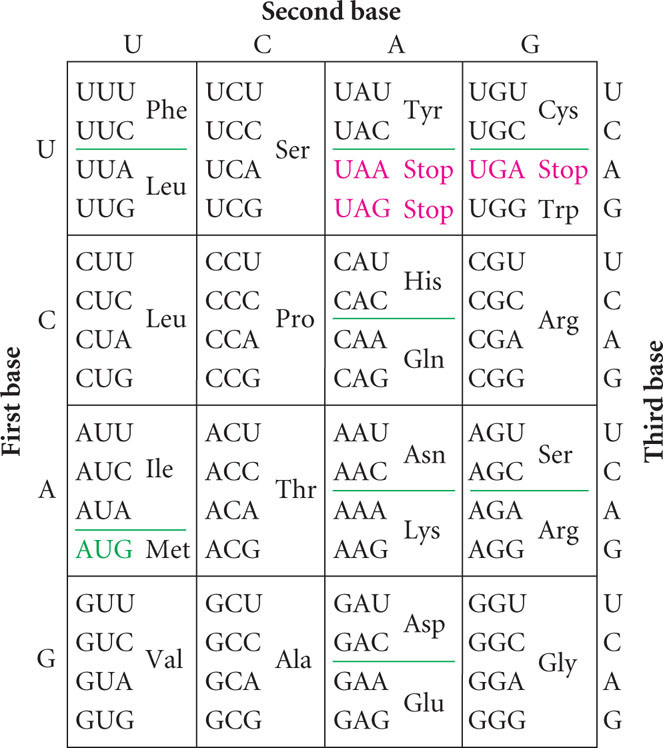
The degeneracy of the genetic code means that amino acids may be specified by more than one codon. Only tryptophan and methionine are encoded by a single codon (see Figure 15.10). Other amino acids are specified by two codons, and some, such as leucine, are specified by six different codons. Codons that specify the same amino acid are said to be synonymous, just as synonymous words are different words that have the same meaning.
As we learned in Chapter 14, tRNAs serve as adapter molecules, binding particular amino acids and delivering them to a ribosome, where the amino acids are then assembled into polypeptide chains. Each type of tRNA attaches to a single type of amino acid. The cells of most organisms possess from about 30 to 50 different tRNAs, and yet there are only 20 different amino acids in proteins. Thus, some amino acids are carried by more than one tRNA. Different tRNAs that accept the same amino acid but have different anticodons are called isoaccepting tRNAs.
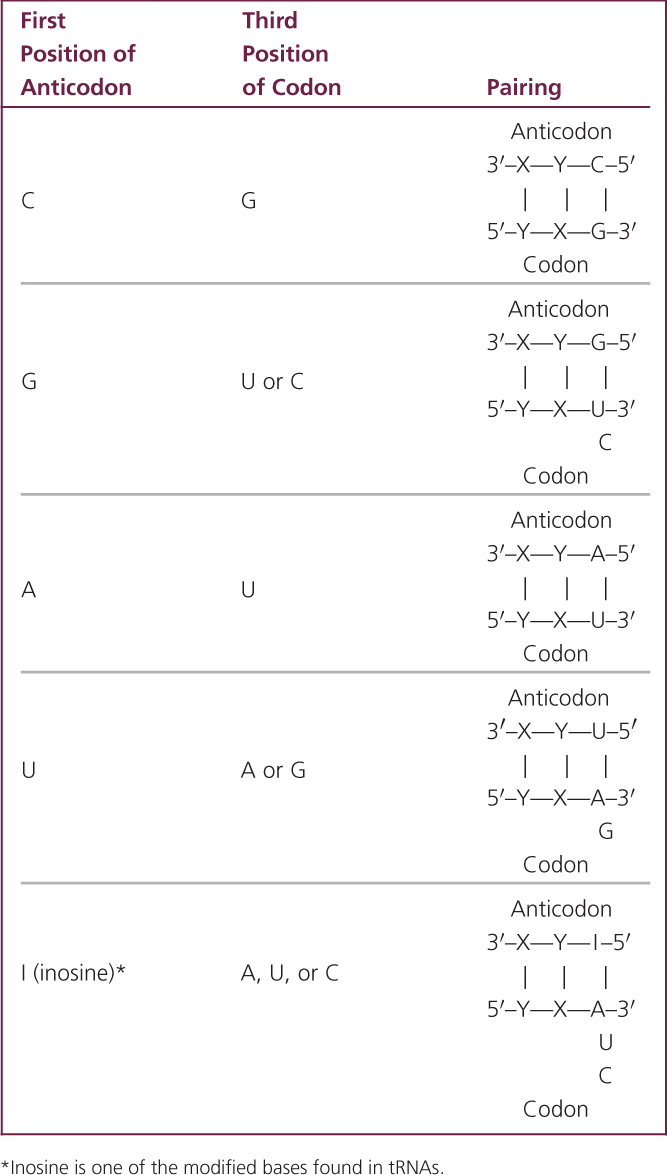
Even though some amino acids have multiple (isoaccepting) tRNAs, there are still more codons than anticodons, because one anticodon can pair with different codons through flexibility in base pairing at the third position of the codon. Examination of Figure 15.10 reveals that many synonymous codons differ only in the third position. For example, alanine is encoded by the codons GCU, GCC, GCA, and GCG, all of which begin with GC. When the codon on the mRNA and the anticodon of the tRNA join (Figure 15.11), the first (5′) base of the codon pairs with the third (3′) base of the anticodon, strictly according to Watson-and-Crick rules: A with U; C with G. Next, the middle bases of codon and anticodon pair, also strictly following the Watson-and-Crick rules. After these pairs have hydrogen bonded, the third bases pair weakly and there may be flexibility, or wobble, in their pairing.
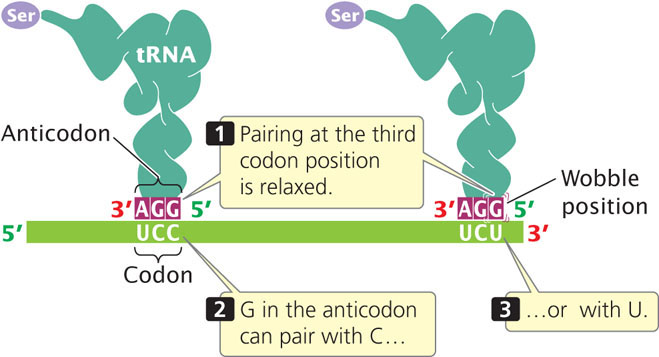
In 1966, Francis Crick developed the wobble hypothesis, which proposed that some nonstandard pairings of bases could take place at the third position of a codon. For example, a G in the anticodon may pair with either a C or a U in the third position of the codon (see Table 15.2: note that inosine in this table is one of the modified base found in tRNAs). The important thing to remember about wobble is that it allows some tRNAs to pair with more than one codon on an mRNA; thus from 30 to 50 tRNAs can pair with 61 sense codons. Some codons are synonymous through wobble. ![]() TRY PROBLEM 26
TRY PROBLEM 26
CONCEPTS
The genetic code consists of 61 sense codons that specify the 20 common amino acids; the code is degenerate, meaning that some amino acids are encoded by more than one codon. Isoaccepting tRNAs are different tRNAs with different anticodons that specify the same amino acid. Also, wobble at the third position of the codon allows different codons to specify the same amino acid.
CONCEPT CHECK 4Through wobble, a single____________can pair with more than one____________.
- codon, anticodon.
- group of three nucleotides in DNA, codon in mRNA.
- tRNA, amino acid.
- anticodon, codon.
The Reading Frame and Initiation Codons
Findings from early studies of the genetic code indicated that the code is generally nonoverlapping. An overlapping code is one in which a single nucleotide may be included in more than one codon, as follows:
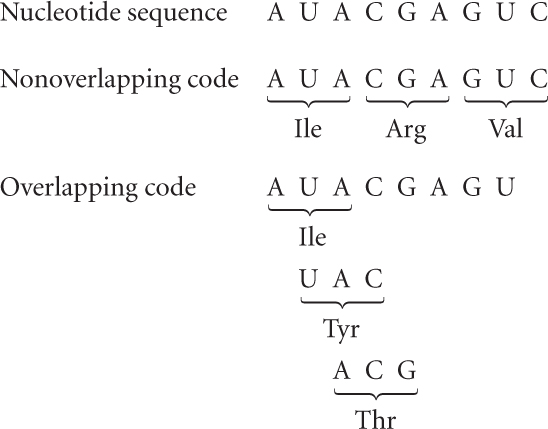
However, usually each nucleotide is part of a single codon. A few overlapping genes are found in viruses, but codons within the same gene do not overlap, and the genetic code is generally considered to be nonoverlapping.
For any sequence of nucleotides, there are three potential sets of codons—three ways in which the sequence can be read in groups of three. Each different way of reading the sequence is called a reading frame, and any sequence of nucleotides has three potential reading frames. The three reading frames have completely different sets of codons and will therefore specify proteins with entirely different amino acid sequences. Thus, it is essential for the translational machinery to use the correct reading frame. How is the correct reading frame established? The reading frame is set by the initiation codon, which is the first codon of the mRNA to specify an amino acid. After the initiation codon, the other codons are read as successive groups of three nucleotides. No bases are skipped between the codons; so there are no punctuation marks to separate the codons.
The initiation codon is usually AUG, although GUG and UUG are used on rare occasions. The initiation codon is not just a sequence that marks the beginning of translation; it specifies an amino acid. In bacterial cells, the first AUG encodes a modified type of methionine, N-formylmethionine; all proteins in bacteria initially begin with this amino acid, but the formyl group (or, in some cases, the entire amino acid) may be removed after the protein has been synthesized. When the codon AUG is at an internal position in a gene, it encodes unformylated methionine. In archaeal and eukaryotic cells, AUG specifies unformylated methionine both at the initiation position and at internal positions. In both bacteria and eukaryotes there are different tRNAs for the initiator methionine (designated tRNAifMet in bacteria and tRNAiMet in eukaryotes) and internal methionine (designated tRNAMet).
Termination Codons
Three codons—UAA, UAG, and UGA—do not encode amino acids. These codons signal the end of the protein in both bacterial and eukaryotic cells and are called stop codons, termination codons, or nonsense codons. No tRNA molecules have anticodons that pair with termination codons.
The Universality of the Code
For many years the genetic code was assumed to be universal, meaning that each codon specifies the same amino acid in all organisms. We now know that the genetic code is almost, but not completely, universal; a few exceptions have been found. Most of these exceptions are termination codons, but there are a few cases in which one sense codon substitutes for another. Most exceptions are found in mitochondrial genes; a few nonuniversal codons have also been detected in the nuclear genes of protozoans and in bacterial DNA (Table 15.3). ![]() TRY PROBLEM 22
TRY PROBLEM 22
| Genome | Codon | Universal Code | Altered Code |
|---|---|---|---|
| Bacterial DNA | |||
| Mycoplasma capricolum | UGA | Stop | Trp |
| Mitochondrial DNA | |||
| Human | UGA | Stop | Trp |
| Human | AUA | Ile | Met |
| Human | AGA, AGG | Arg | Stop |
| Yeast | UGA | Stop | Trp |
| Trypanosomas | UGA | Stop | Trp |
| Plants | CGG | Arg | Trp |
| Nuclear DNA | |||
| Tetrahymena | UAA | Stop | Gln |
| Paramecium | UAG | Stop | Gln |
CONCEPTS
Each sequence of nucleotides possesses three potential reading frames. The correct reading frame is set by the initiation codon. The end of a protein-encoding sequence is marked by a termination codon. With a few exceptions, all organisms use the same genetic code.
CONCEPT CHECK 5Do the initiation and termination codons specify an amino acid? If so, which ones?
CONNECTING CONCEPTS
We have now considered a number of characteristics of the genetic code. Let’s take a moment to review these characteristics.
- The genetic code consists of a sequence of nucleotides in DNA or RNA. There are four letters in the code, corresponding to the four bases—A, G, C, and U (T in DNA).
- The genetic code is a triplet code. Each amino acid is encoded by a sequence of three consecutive nucleotides, called a codon.
- The genetic code is degenerate; of 64 codons, 61 codons encode only 20 amino acids in proteins (3 codons are termination codons). Some codons are synonymous, specifying the same amino acid.
- Isoaccepting tRNAs are tRNAs with different anticodons that accept the same amino acid; wobble allows the anticodon on one type of tRNA to pair with more than one type of codon on mRNA.
- The code is generally nonoverlapping; each nucleotide in an mRNA sequence belongs to a single reading frame.
- The reading frame is set by an initiation codon, which is usually AUG.
- When a reading frame has been set, codons are read as successive groups of three nucleotides.
- Any one of three termination codons (UAA, UAG, and UGA) can signal the end of a protein; no amino acids are encoded by the termination codons.
- The code is almost universal.