14.3 The Power of the ANOVA Test
The power of a test is the probability of rejecting H0 when Ha is, in fact, true. Power measures how likely a test is to detect a specific alternative. When planning a study in which ANOVA will be used for the analysis, it is important to perform power calculations to check that the sample sizes are adequate to detect differences among means that are judged to be important. Power calculations also help evaluate and interpret the results of studies in which H0 was not rejected. We sometimes find that the power of the test was so low against reasonable alternatives that there was little chance of obtaining a significant F.

In Chapter 7, we found the power for the two-sample t test. One-way ANOVA is a generalization of the two-sample t test, so it is not surprising that the procedure for calculating power is quite similar. Here are the steps that are needed:
- Specify
- an alternative (Ha) that you consider important; that is, values for the true population means μ1, μ2, …, μI;
- sample sizes n1, n2, …, nI; in a preliminary study, these are usually all set equal to a common value n;
- a level of significance α, usually equal to 0.05; and
- a guess at the standard deviation σ.
- Find the degrees of freedom DFG=I−1 and DFE=N−1 and the critical value that will lead to rejection of H0. This value, which we denote by F*, is the upper α critical value for the F(DFG, DFE) distribution.
Calculate the noncentrality parameter6
λ=∑ni(μi−ˉμ)2σ2
noncentrality parameter
where ˉμ is a weighted average of the group means,
ˉμ=∑wiμi
and the weights are proportional to the sample sizes,
wi=ni∑ni=niN
- Find the power, which is the probability of rejecting H0 when the alternative hypothesis is true—that is, the probability that the observed C is greater than F*. Under Ha, the F statistic has a distribution known as the noncentral F distribution. This requires special software. SAS, for example, has a function for the noncentral F distribution. Using this function, the power is
power=1−PROBF(F*, DFG, DFE, λ)
noncentral F distribution
The noncentrality parameter λ measures how far apart the means μi are. If the ni are all equal to a common value n, ˉμ is the ordinary average of the μi and
λ=n∑(μi−ˉμ)2σ2
If the means are all equal (the ANOVA H0), then λ=0. Large λ points to an alternative far from H0, and we expect the ANOVA F test to have high power.
Software makes calculation of the power quite easy. The software does Steps 2, 3, and 4, so our task simplifies to just Step 1. Some software doesn’t request the alternative means but rather a difference in means that is judged important. Most software will also assume a constant sample size. Let’s run through an example doing the calculations ourselves and then compare the results with output from two software programs.
EXAMPLE 14.27 The Effect of Fewer Subjects
CASE 14.2 The reading comprehension study described in Case 14.2 had 22 subjects in each group. Suppose that a similar study has only 10 subjects per group. How likely is this study to detect differences in the mean responses that are similar in size to those observed in the actual study?
Based on the results of the actual study, we calculate the power for the alternative μ1=41, μ2=47, μ3=44, with σ=7. The ni are equal, so ˉμ is simply the average of the μi:
ˉμ=41+47+443=44
The noncentrality parameter is, therefore,
λ=n∑(μi−ˉμ)2σ2=(10)[(41−44)2+(47−44)2+(44−44)2]49=(10)(18)49=3.67
Because there are three groups with 10 observations per group, DFG=2 and DFE=27. The critical value for α=0.05 is F*=3.35. The power is, therefore,
1−PROBF(3.35, 2, 27, 3.67)=0.3486
The chance that we reject the ANOVA H0 at the 5% significance level is only about 35%.
Figure 14.18 shows the power calculation output from JMP and Minitab. For JMP, you specify the alternative means, standard deviation, and the total sample size N. The power is calculated when the “Continue” button is clicked. Notice that this result is the same as the result in Example 14.27. For Minitab, you enter the common sample size n, standard deviation, and the difference between means that is deemed important. For the alternative means specified in Example 14.27, the largest difference is 6=47−41 so that was entered. The power is again the same as the result in Example 14.27. This won’t always be the case. Specifying an important difference will often give a power value that is smaller. This is because it computes a noncentrality parameter that is always less than or equal to the noncentrality value based on knowing all the alternative means.
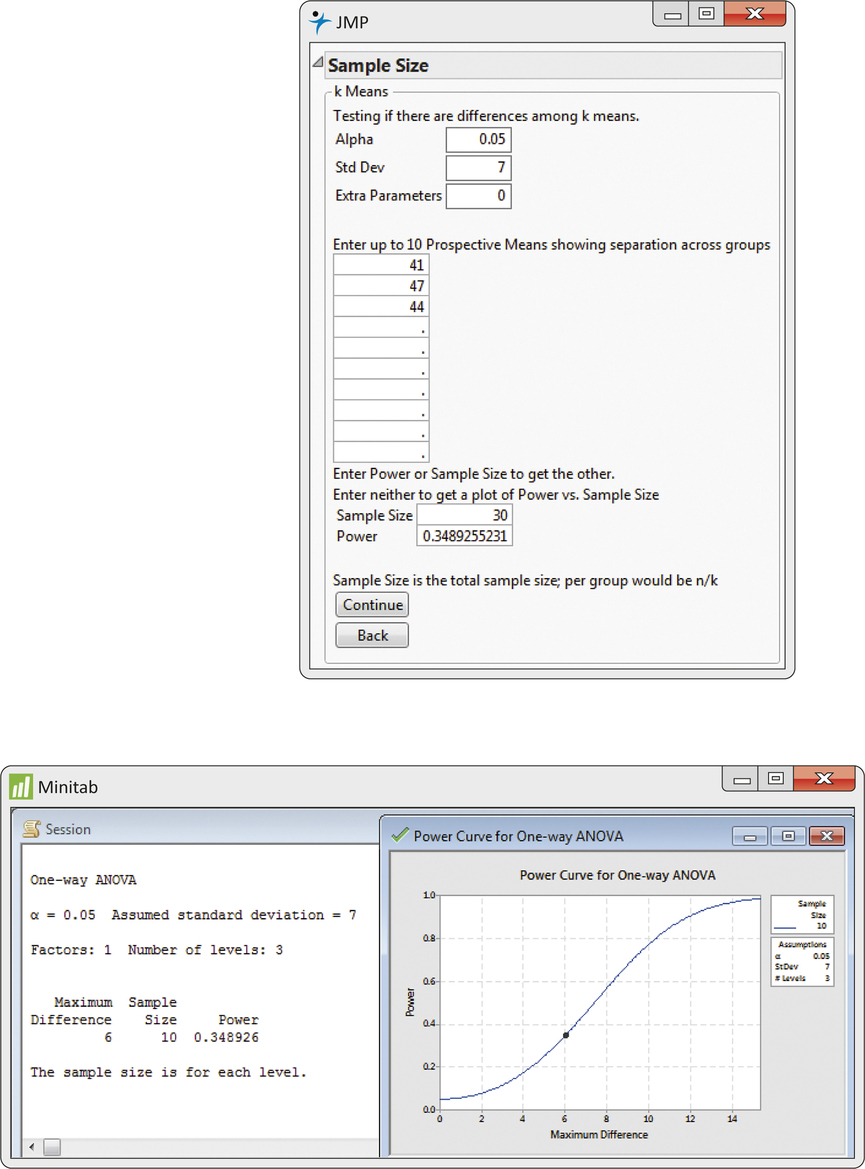
If the assumed values of the μi in this example describe differences among the groups that the experimenter wants to detect, then we would want to use more than 10 subjects per group. Although H0 is false for these μi the chance of rejecting it at the 5% level is only about 35%. This chance can be increased to acceptable levels by increasing the sample sizes.
EXAMPLE 14.28 Choosing the Sample Size for a Future Study
CASE 14.2 To decide on an appropriate sample size for the experiment described in the previous example, we repeat the power calculation for different values of n, the number of subjects in each group. Here are the results:
| n | DFG | DFE | F* | λ | Power |
| 20 | 2 | 57 | 3.16 | 7.35 | 0.65 |
| 30 | 2 | 87 | 3.10 | 11.02 | 0.84 |
| 40 | 2 | 117 | 3.07 | 14.69 | 0.93 |
| 50 | 2 | 147 | 3.06 | 18.37 | 0.97 |
| 100 | 2 | 297 | 3.03 | 36.73 | ≈ 1 |
Try using JMP to verify these calculations. With n=40, the experimenters have a 93% chance of rejecting H0 with α=0.05 and thereby demonstrating that the groups have different means. In the long run, 93 out of every 100 such experiments would reject H0 at the α=0.05 level of significance. Using 50 subjects per group increases the chance of finding significance to 97%. With 100 subjects per group, the experimenters are virtually certain to reject H0. The exact power for n=100 is 0.99990. In most real-life situations, the additional cost of increasing the sample size from 50 to 100 subjects per group would not be justified by the relatively small increase in the chance of obtaining statistically significant results.
Apply Your Knowledge
Question 14.30
14.30 Power calculations for planning a study.
You are planning a new eye gaze study for a different university than that studied in Example 14.13 (pages 729–731). From Example 14.13, we know that the standard deviations for the four groups considered in that study were 1.75, 1.72, 1.53, and 1.67. In Figure 14.9, we found the pooled standard error to be 1.68. Because the power of the F test decreases as the standard deviation increases, use σ=1.80 for the calculations in this exercise. This choice leads to sample sizes that are perhaps a little larger than we need but prevents us from choosing sample sizes that are too small to detect the effects of interest. You would like to conclude that the population means are different when μ1=3.2, μ2=3.7, μ3=3.1 and μ4=3.8.
- Pick several values for n (the number of students that you will select from each group) and calculate the power of the ANOVA F test for each of your choices.
- Plot the power versus the sample size. Describe the general shape of the plot.
- What choice of n would you choose for your study? Give reasons for your answer.
Question 14.31
14.31 Power against a different alternative.
Refer to the previous exercise. Suppose we increase μ4 to 3.9. For each of the choices of n in the previous example, would the power be larger or smaller under this new set of alternative means? Explain your answer.
14.31
The power would be larger. For larger differences between alternative means, λ gets bigger, increasing our power to see these differences.