
 DRIVING QUESTIONS
DRIVING QUESTIONS
- Why is knowing the sequence of the human genome important?
- What were the similarities and differences between the approaches used by the two research teams that sequenced the genome?
 T STARTED WITH A VISIONARY IDEA: THE ENTIRE SEQUENCE of human DNA spelled out, nucleotide by nucleotide, to be read like a book. Such a reference would be an indispensable medical tool. Scientists could, for example, scan the genome for genes that confer susceptibility to disease, which might lead to better treatments. It would enable diagnostic tests that could help predict the risk of developing genetically based diseases. Fields other than medicine would benefit, too. Comparing the human genome to the genomes of other organisms, for example, would shed light on our own evolution. The possible benefits to science were endless.
T STARTED WITH A VISIONARY IDEA: THE ENTIRE SEQUENCE of human DNA spelled out, nucleotide by nucleotide, to be read like a book. Such a reference would be an indispensable medical tool. Scientists could, for example, scan the genome for genes that confer susceptibility to disease, which might lead to better treatments. It would enable diagnostic tests that could help predict the risk of developing genetically based diseases. Fields other than medicine would benefit, too. Comparing the human genome to the genomes of other organisms, for example, would shed light on our own evolution. The possible benefits to science were endless.
But when an international group of scientists met in the early 1980s and first floated the idea of sequencing the human genome, they were met with skepticism. Some scientists found the idea absurd, especially given its then-estimated $3 billion price tag. Others thought the potential benefits were illusory or overly hyped. Some simply deemed the task impossible, given the state of the technology at the time.
Over the course of the decade, however, as the fields of molecular biology and genetics progressed, the idea gained both scientific and political support. In 1988, congress funded both the national Institutes of health (NIH) and the U.S. department of Energy to explore the novel concept. By 1990, the collaborative effort to sequence the entire string of more than 3 billion As, Gs, cs, and Ts that make up a human genome–the human Genome Project (HGP)–was officially under way.
When the project began, the NIH appointed James Watson, the co-discoverer of the structure of DNA, to head and coordinate it. The ambitious and mammoth undertaking involved more than 20 institutions spread around the globe, in China, France, Germany, Japan, the United Kingdom, the United states, and other countries.
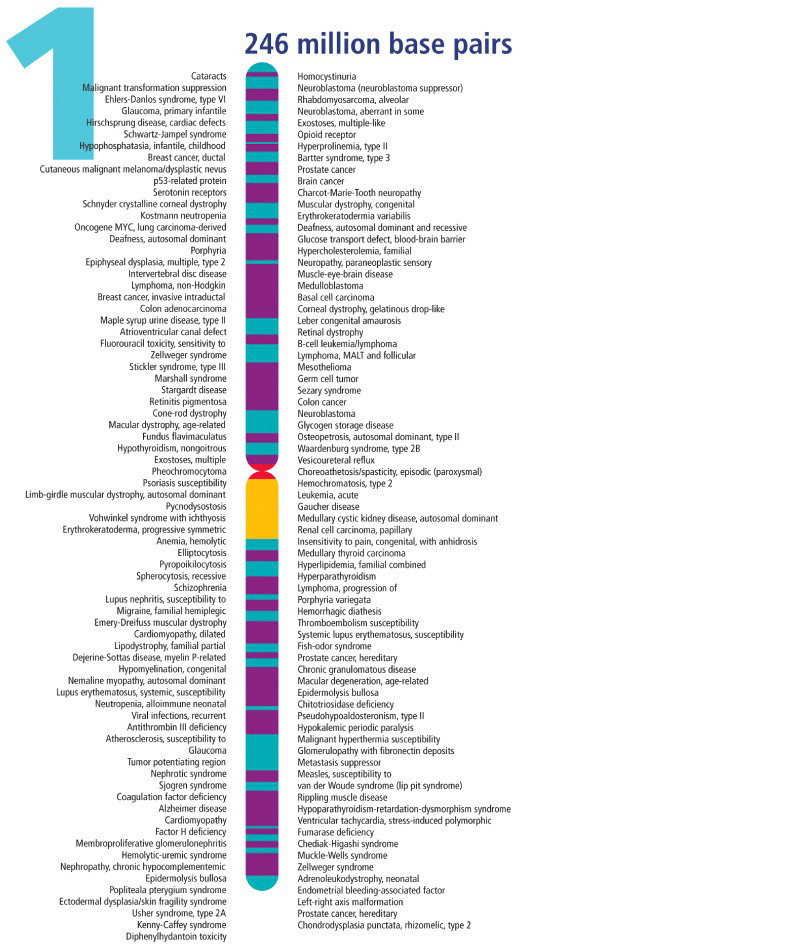
Initially, the researchers set about sequencing every nucleotide on every one of the chromosomes that make up the entire genome. But the DNA sequence machines then available could sequence only about 500 nucleotides at a time; the cost and time to sequence the entire human genome 500 consecutive nucleotides at a time would have been prohibitive. So researchers had to develop a shortcut. The approach they came up with is now known as “hierarchical shotgun sequencing”–“hierarchical” because the researchers first chemically broke human chromosomes into large segments, organized them, and mapped each piece to a known physical location on a chromosome; “shotgun” because they then randomly cut those large segments into a rapid-fire slew of even smaller pieces and sequenced the nucleotides of each small piece. They then assembled the final sequence by matching up overlapping pieces.
Here’s a useful analogy–imagine photocopying this sentence 10 times. Now imagine taking all the paper copies and tearing them at different points. Depending on where you tear, each copy will contain pieces with different parts of the same word. One copy might contain only the “ima” part of the word “imagine,” while another might contain the whole word. You could use the piece containing the entire word to piece together two pieces with “ima” and “gine.” By repeatedly aligning word fragments like this, you could eventually piece together the entire original sentence, even if you didn’t know at the outset what it said.
In addition to allowing many parts of the genome to be analyzed simultaneously, this approach had the advantage of being able to focus on specific regions of chromosomes that researchers were particularly interested in. But this “shortcut” still took time: by this method, scientists estimated it would take 15 years to finish the entire sequence of 3 billion bases (INFOGRAPHIC M3.1).
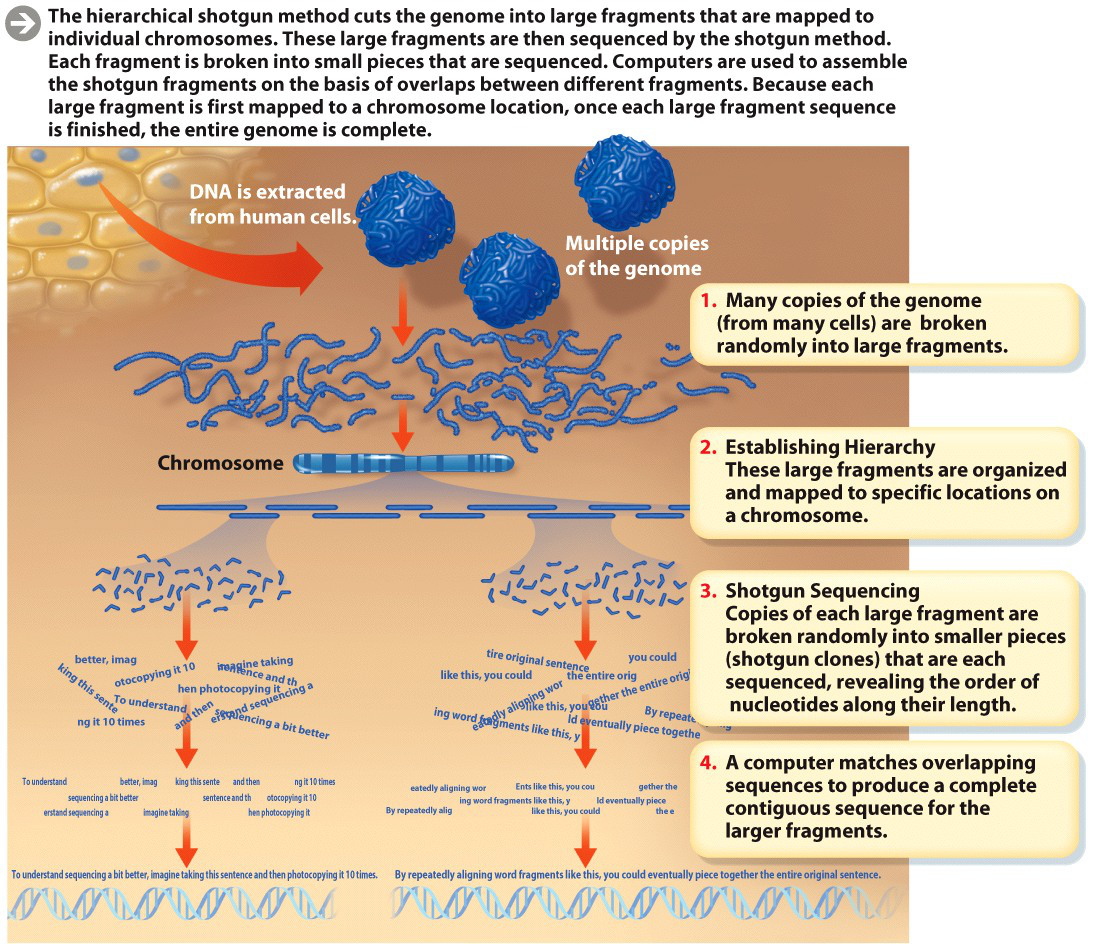
The map of sequences grew, and as sequences were assigned to specific chromosomal locations, it became much easier for scientists to find a home for gene sequences they were working on. Since the information was uploaded to a public online database, any scientist could view the map to see where exactly his or her gene of interest was located and apply that information to further research. But after a year, the project wasn’t progressing as quickly as planned, and some estimated that if things kept plodding along at the same pace, the total cost–which reflected the cost of labor, laboratory space and equipment, chemical reagents, and computer technology, as well as other expenses–could reach more than $100 billion.
Criticism began to mount over the costs and delays of the HGP. In 1991, Craig Venter, who had helped pioneer automated gene sequencing techniques in his lab at NIH, became especially frustrated with the slow pace of sequencing and publicly proposed an alternative approach. To save time, he proposed focusing on just the protein-coding DNA, skipping the regulatory regions. Using this method, he had already identified thousands more genes than the official project had. But Watson, head of the genome project, dismissed the method as sloppy and inadequate. At one point, he even called Venter’s work “brainless,” and said that his sequence machines “could be run by monkeys.” Angered by his rejection and lured by a hefty salary, Venter left NIH in 1992 to found his own investment-backed institute, called The Institute for Genome Research (TIGR). From his new perch, he continued to explore other sequencing methods.
Comparing the human genome to the genomes of other organisms, for example, would shed light on our own evolution. The possible benefits to science were endless.
Meanwhile, in 1992, Watson resigned as head of the HGP after a disagreement with the NIH director over the issue of patenting genes (Watson was opposed). In early 1993, NIH appointed a new head, the geneticist Francis Collins. The idea of speeding up the sequencing using Venter’s shortcut didn’t sit well with Collins, either, and the decision was made to stay the course.
Then, in 1995, Venter surprised the scientific community again by successfully sequencing the entire genome of a bacterium in a short time, using a new sequencing method developed at his institute. This approach involved breaking the entire genome into many small fragments and sequencing them simultaneously–without first mapping them to known chromosome locations, as Collins’s group was doing. Venter argued that the same technique could be used on the human genome. But the human genome was much larger and contained many repetitive sequences–how would the multitude of randomly generated sequences be aligned properly? Venter’s approach–which he called “whole-genome shotgun sequencing”–would be akin to trying to put a jigsaw puzzle together without a photo of the finished puzzle as a guide. Critics claimed that the sequence data would be riddled with mistakes.
Venter was undeterred. In 1998, he dropped another bomb: he had made a deal with the Perkin-Elmer Corporation, which was about to unveil a new automated sequencing machine. Together they would create a new company, to be called Celera Genomics (from the Latin word celeritas, meaning “speed”), that intended single-handedly to sequence the entire human genome in just 3 years for a mere $300 million–a fraction of the cost of the publicly funded consortium. They would use Venter’s whole-genome shotgun method (INFOGRAPHIC M3.2).
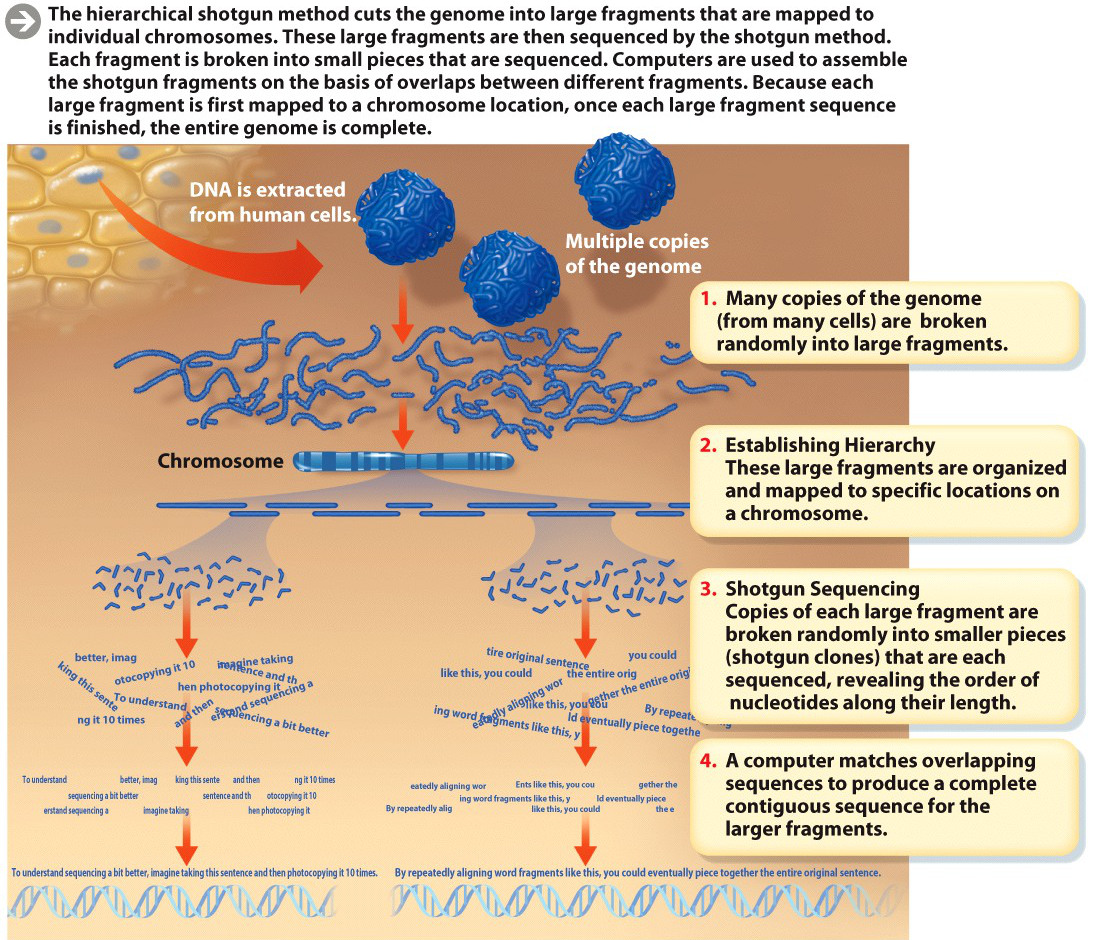
Collins and other leaders of the public project were troubled. The U.S. Congress might favor Celera’s approach and stop funding the public project altogether. Collins was also concerned that Celera was going to try to patent its sequence data, which would have restricted public access to the data.
The race was on. Collins and his colleagues stepped up the pace. Venter wasn’t the only one who had access to new automated sequencing machines and powerful computers that could process large amounts of data. Publicly financed scientists, too, had access to these and other new tools. Such technological advances dramatically cut the amount of time it took to sequence each nucleotide and simultaneously cut costs (INFOGRAPHIC M3.3).
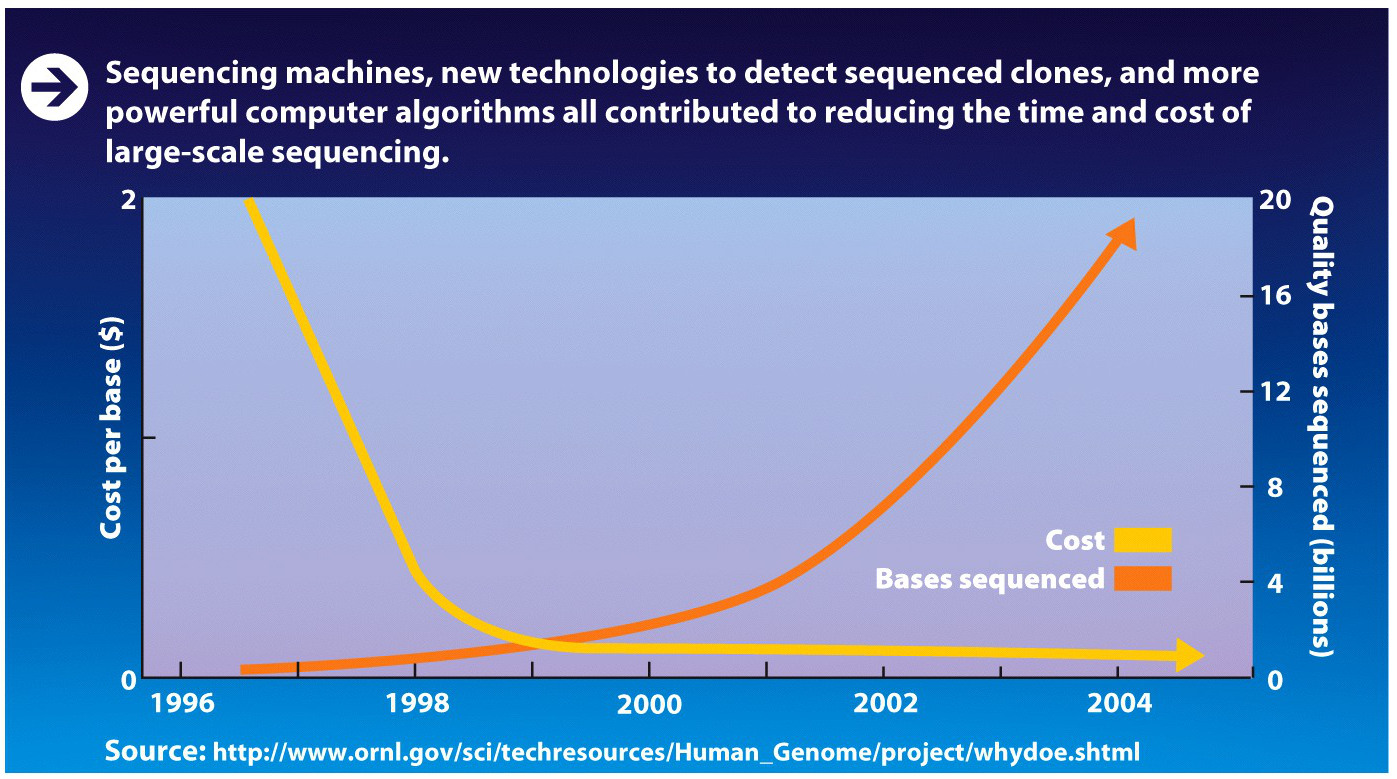
About 6 months after Venter’s announcement, Collins announced that the public consortium would complete sequencing the genome by 2003–2 years ahead of schedule. The consortium also planned to produce a rough draft of the genome by 2001, which was about the same time that Venter planned to finish his draft. Collins justified his decision by stating that scientists were clamoring for the data even in rough form.


For a few years the contest between the privately funded Celera and the publicly funded HGP was bitter, each side criticizing the other’s methods. The two sides eventually agreed to share the glory and appeared at a White House press briefing on June 26, 2000, together with U.S. President Bill Clinton and British Prime Minister Tony Blair, to announce publicly that they had completed a rough draft of the human genome sequence. In February 2001, both groups published their drafts of the human genome simultaneously in the journals Nature and Science.
Just whose genome was in fact sequenced? Geneticists working on the publicly funded project had collected blood samples from anonymous donors. The ultimate sequence is thus a composite pieced together from the gene sequences of several individuals. Celera’s sequence data come mostly from the DNA of Venter himself.
Did one group “win” the race? Some say Venter won, because his sequence was further along when the two groups presented their findings. But others were quick to point out that Venter’s group had used much of the public HGP data in order to assemble his own sequence–which he wouldn’t have been able to do if the data had been kept secret. As the authors of a 2002 scientific report analyzing the two approaches noted, “When speed truly matters, openness is the answer.”
Ultimately, when the HGP was officially completed in 2003, 99% of the gene-containing regions of DNA had been sequenced, with an accuracy of 1 in 100,000 nucleotides, and only 341 gaps in 2.85 billion nucleotides. The achievement was hailed as one of the greatest scientific accomplishments of the 20th century. Some even consider it the greatest achievement ever in biology. Not only did it reveal new characteristics of the human genome, it also shed light on how we differ from other organisms.
While the human genome was being sequenced, scientists had also finished sequencing the genomes of some other organisms. Scientists compared our genome to the genomes of other organisms, and what they found astounded them.
Before the sequencing was complete, scientists thought that what made humans such complex creatures was gene number–that the more complex the creature, the more genes it should have. But the HGP showed that humans carry a mere 20,000 to 25,000 genes–about the same number as a lowly round-worm. This evidence suggested that gene number wasn’t as important as how those genes were expressed into proteins. Before the project, scientists didn’t think noncoding regions of the genome were important. Now they know that noncoding regions actually regulate genes and consequently contribute to the complexity of higher organisms. Moreover, the number of genes an organism has says nothing about the number of proteins that are produced from those genes. Through alternative splicing of mRNA and other mechanisms not yet fully understood, a relatively small number of genes can produce an enormous number of diverse proteins. For example, the human genome may encode more than 1 million proteins from fewer than 25,000 genes.
The achievement was hailed as one of the greatest scientific accomplishments of the 20th century.
While the full potential of the HGP has yet to be tapped, it has already inspired many useful applications across many fields, from medicine to evolution. For example, the National Center for Genome Resources in Santa Fe, New Mexico, uses human genome sequences in an effort to improve human health by improving diagnostics, control, and treatment of disease. They have used genome sequence information to design a screening test that can allow potential parents to know if they are carriers for any of 448 debilitating or fatal diseases. This information can help parents understand their risk of having a child with one of these diseases. They also have developed a test to identify emergency room patients who are at higher risk of developing severe reactions to sepsis (bloodstream infections) and are working on identifying genetic changes that are important in the development of certain types of cancer (INFOGRAPHIC M3.4).
Perhaps the most exciting application of the information is the prospect of “personalized medicine”–treatments based on your genome, tailored specifically to you. It is now possible to sequence a person’s genome in a matter of days, and it may soon be possible to use this information to make ever more precise diagnoses and to link specific treatments to your likelihood of responding. Even smart phone app creators are getting into the action: genomic data may one day soon be employed to help you find a compatible mate.
The human genome sequence will remain a crucial scientific tool for years to come.
MORE TO EXPLORE
 The Human Genome Project Archive http://www.ornl.gov/sci/techresources/Human_Genome/home.shtml
The Human Genome Project Archive http://www.ornl.gov/sci/techresources/Human_Genome/home.shtml
-
Resnick, R. (2011) TED Talk: Welcome to the genomic revolution http://www.ted.com/talks/richard_resnick_welcome_to_the genomic_revolution.html
-
Davies, K. (2001) Cracking the Genome: Inside the Race to Unlock Human DNA. New York: Free Press.