
34.2 DNA Replication Is Highly Coordinated
✓ 4 Describe how replication is organized, and distinguish between eukaryotic replication and bacterial replication.
DNA replication must be very rapid, given the sizes of the genomes and the rates of cell division. The E. coli genome contains 4.6 million base pairs and is copied in less than 40 minutes. Thus, 2000 bases are incorporated per second. Enzyme activities need to be highly coordinated to replicate entire genomes precisely and rapidly.
We begin our consideration of the coordination of DNA replication by looking at E. coli, which has been extensively studied. For this organism, with a small genome, replication begins at a single site and continues around the circular chromosome. The coordination of eukaryotic DNA replication is more complex than bacterial replication because there are many initiation sites throughout the genome and because an additional enzyme is needed to replicate the ends of linear chromosomes.
DNA Replication in E coli Begins at a Unique Site
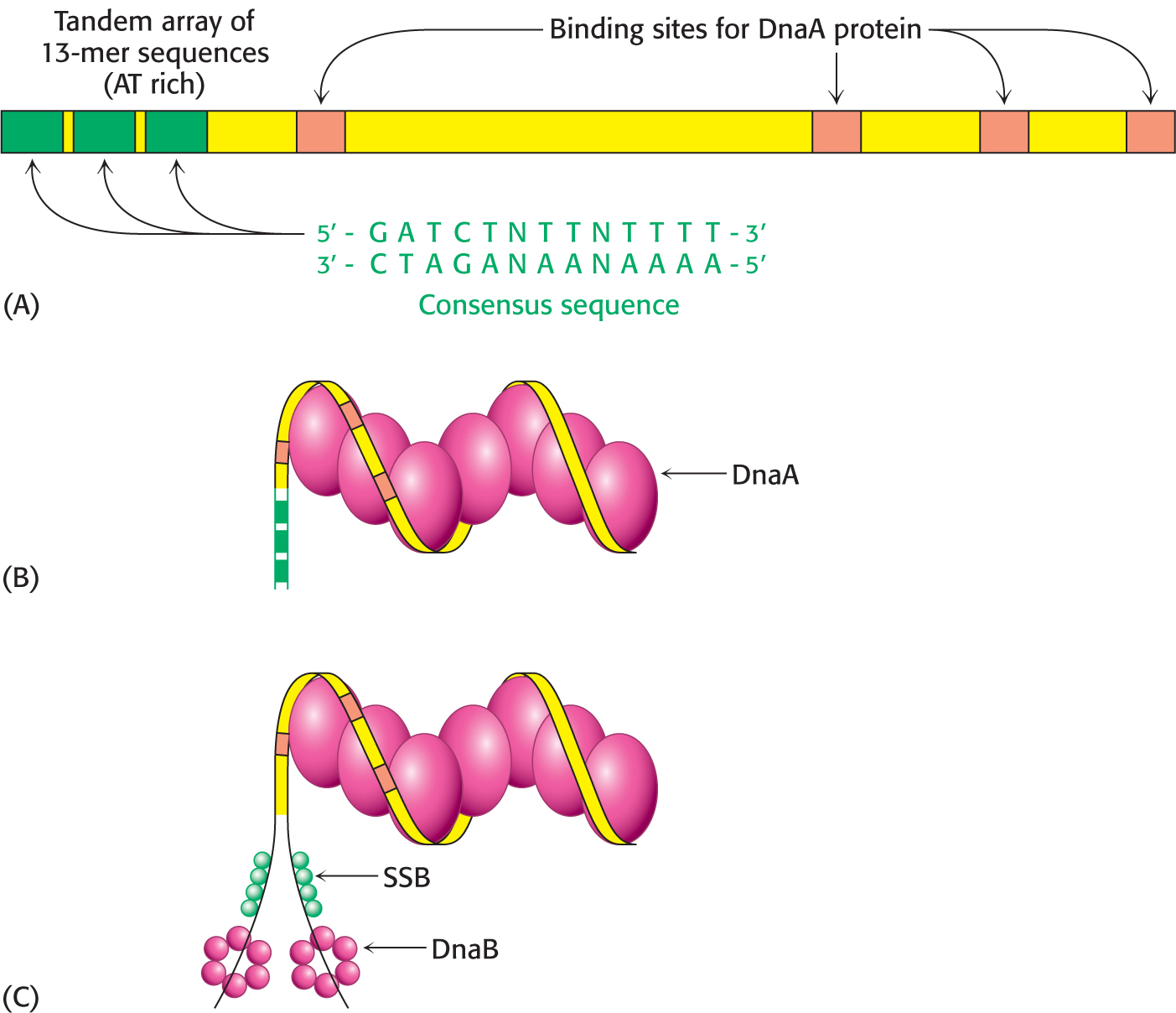
In E. coli, DNA replication starts at a unique site within the entire 4 × 106 bp genome. This origin of replication, called the oriC locus, is a 245-
The oriC locus contains four copies of a sequence that are preferred binding sites for the origin-
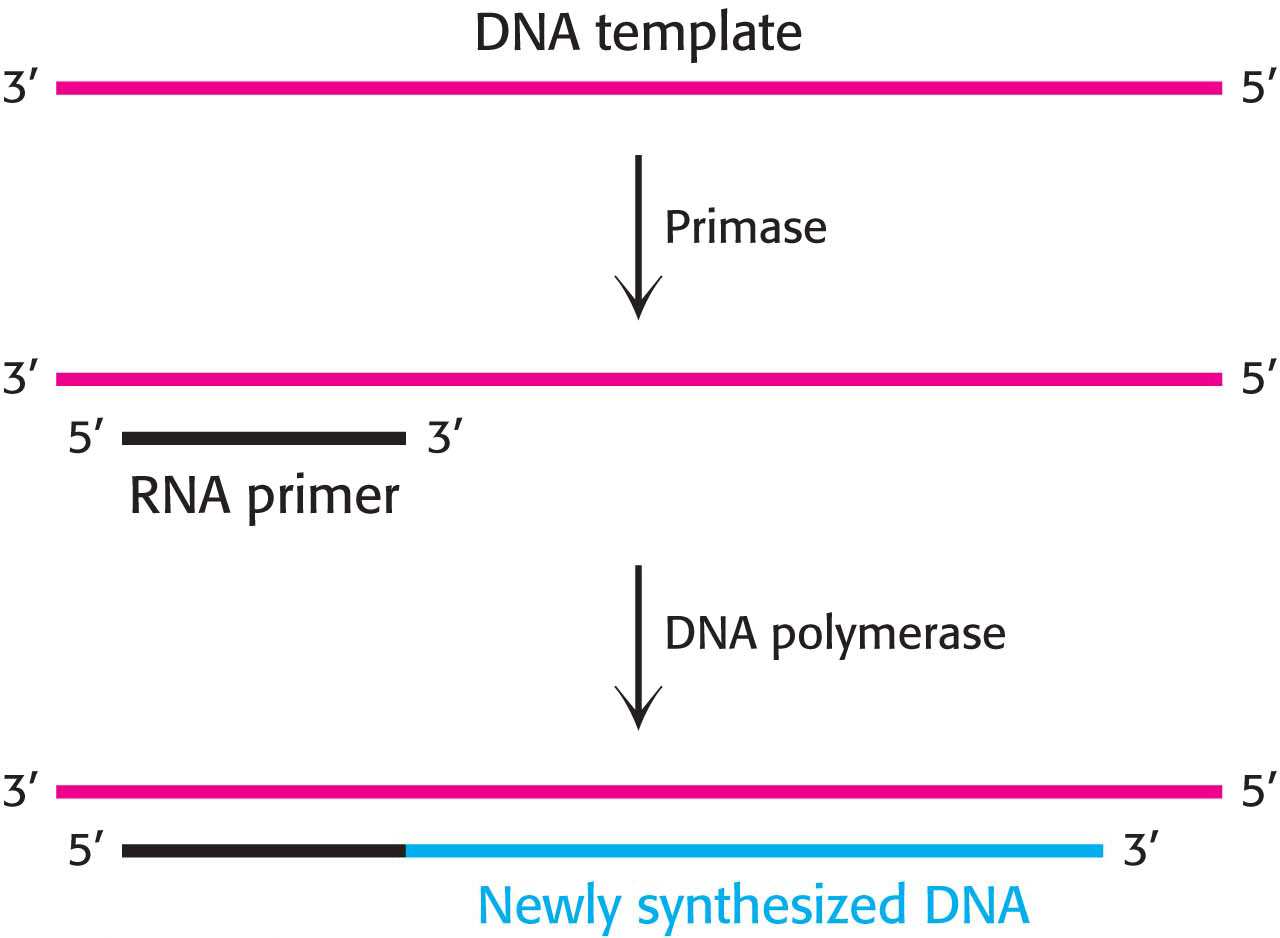
An RNA Primer Synthesized by Primase Enables DNA Synthesis to Begin
Even with the DNA template exposed and the prepriming complex assembled, there are still obstacles to DNA synthesis. DNA polymerases can add nucleotides only to a free hydroxyl group; they cannot start a strand de novo. Therefore, a primer is required. How is this primer formed? An important clue came from the observation that RNA synthesis is required for the initiation of DNA synthesis. In fact, RNA primes the synthesis of DNA. A specialized RNA polymerase called primase joins the prepriming complex in a multisubunit assembly called the primosome. Primase synthesizes a short stretch of RNA (about 10 nucleotides) that is complementary to one of the template DNA strands (Figure 34.12). The RNA primer is removed by a 5′ → 3′ exonuclease; in E. coli, the exonuclease is present as the third active site in DNA polymerase I.
One Strand of DNA Is Made Continuously and the Other Strand Is Synthesized in Fragments
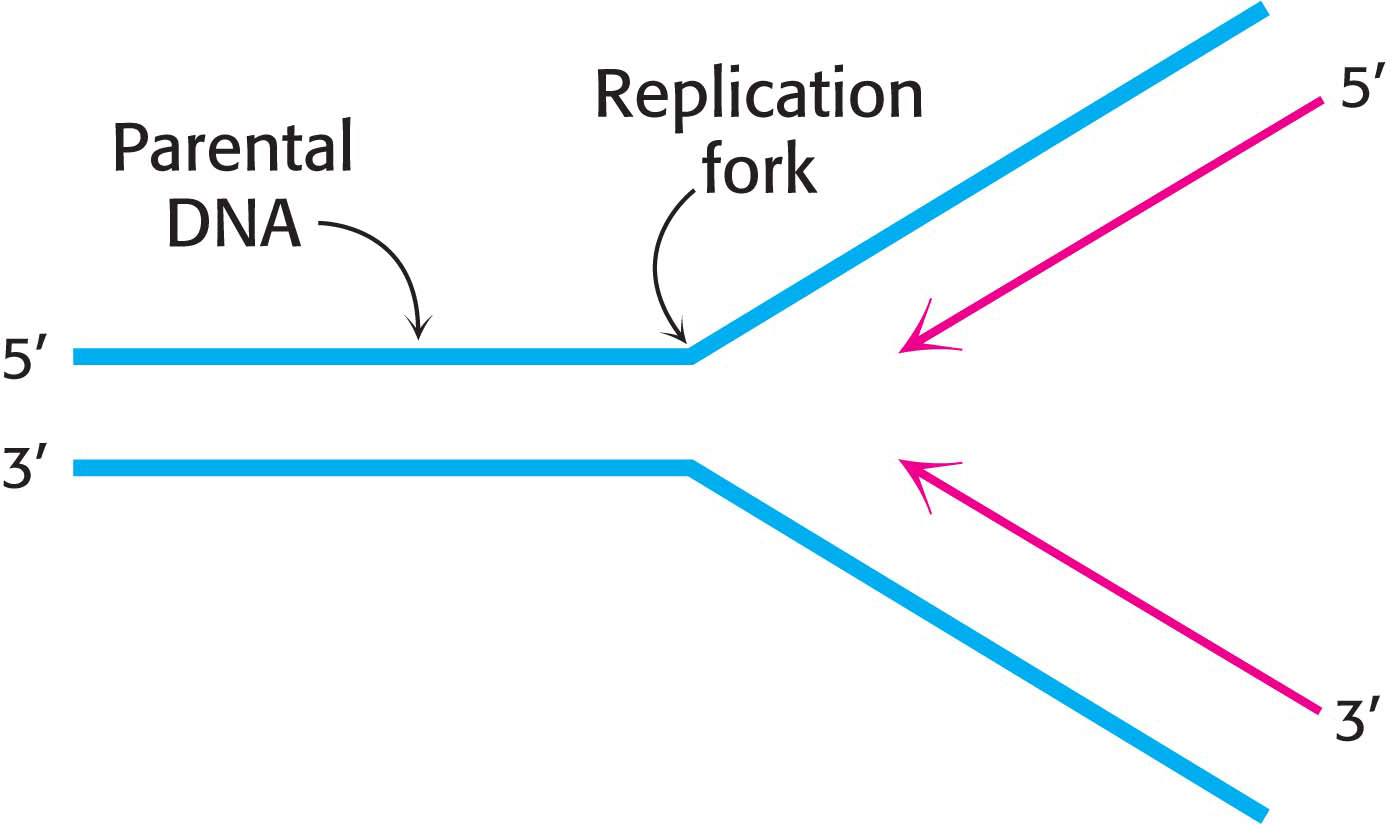
Both strands of parental DNA serve as templates for the synthesis of new DNA. The site of DNA synthesis is called the replication fork because the complex formed by the newly synthesized daughter strands arising from the parental duplex resembles a two-
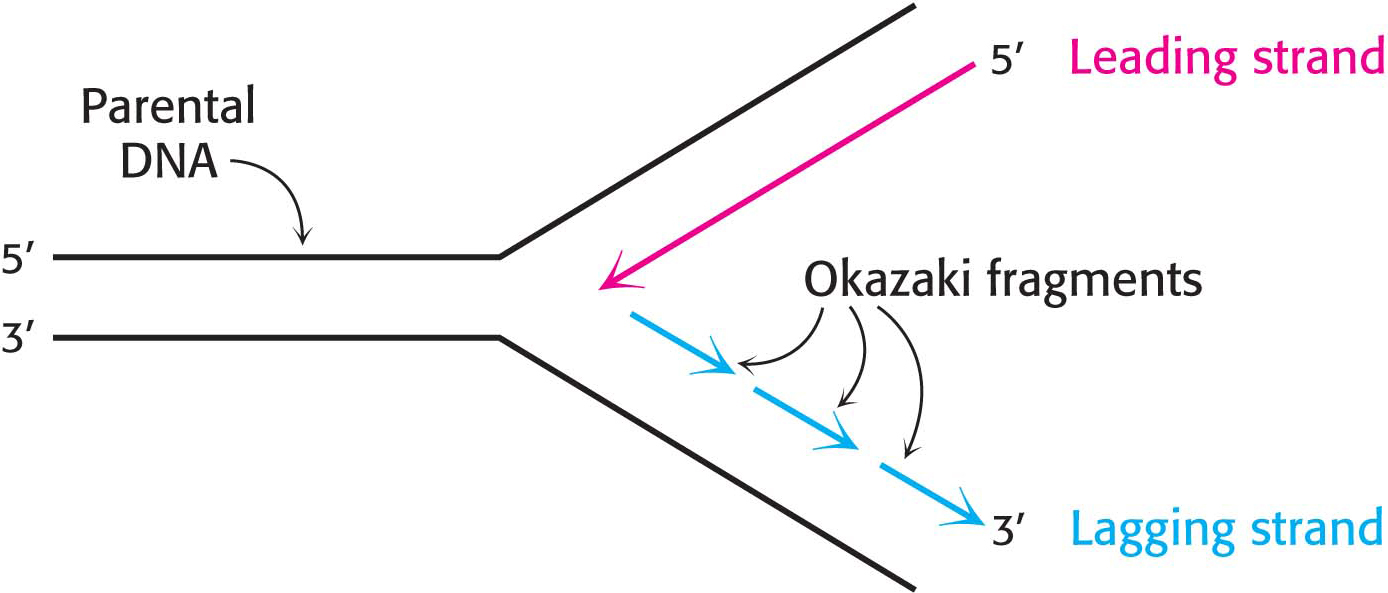
This dilemma was resolved when careful experimentation found that a significant proportion of newly synthesized DNA exists as small fragments. These units of about a thousand nucleotides, called Okazaki fragments (after Reiji Okazaki, who first identified them), are present briefly in the vicinity of the replication fork (Figure 34.14). As replication proceeds, these fragments become covalently joined through the action of DNA ligase, an enzyme that uses ATP hydrolysis to power the joining of DNA fragments to form one of the daughter strands. The other new strand is synthesized continuously. The strand formed from Okazaki fragments is termed the lagging strand, whereas the one synthesized without interruption is the leading strand. Both the Okazaki fragments and the leading strand are synthesized in the 5′ → 3′ direction. The discontinuous assembly of the lagging strand enables 5′ → 3′ polymerization at the nucleotide level to give rise to overall growth in the 3′ → 5′ direction.
DNA Replication Requires Highly Processive Polymerases
We have been introduced to the enzymes that participate in DNA replication. They include helicases and topoisomerases, and we have examined the general properties of polymerases by focusing on DNA polymerase I. We now examine the enzyme responsible for the rapid and accurate synthesis of DNA in E. coli—the holoenzyme DNA polymerase III. The hallmarks of this multi-
The source of the processivity—
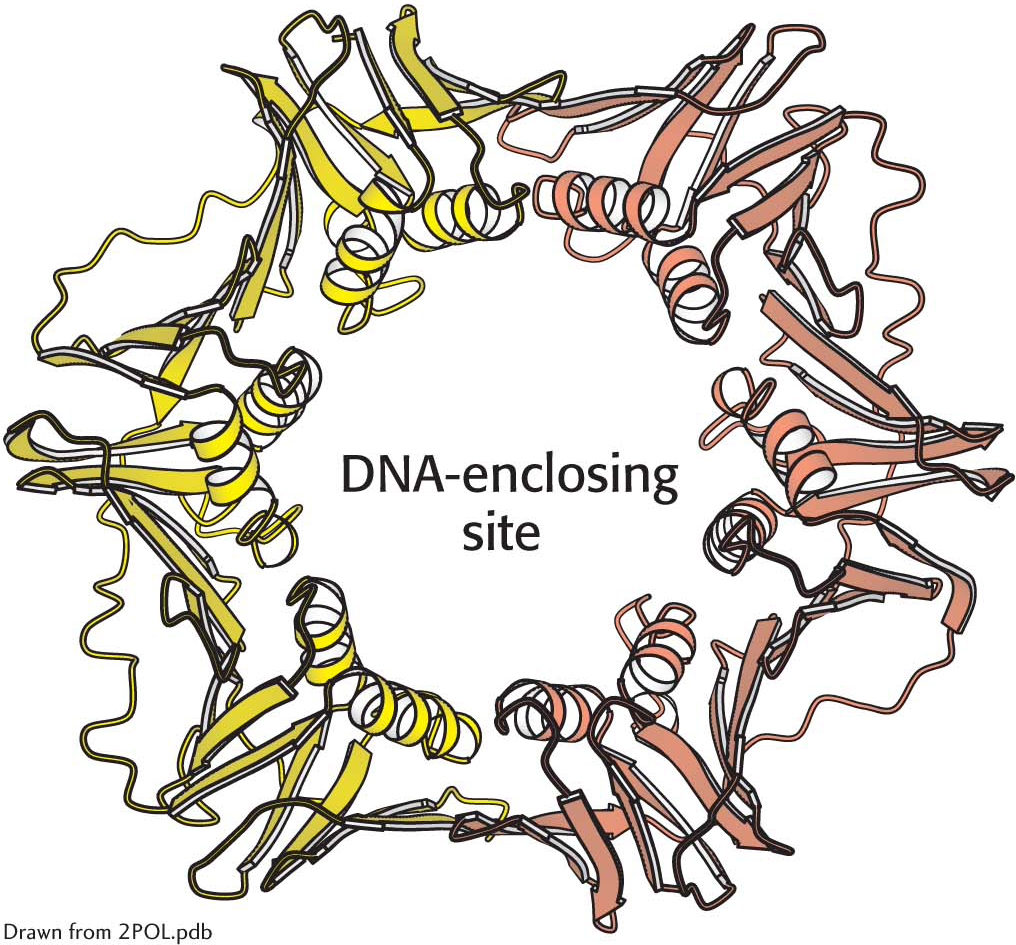
 The structure of a sliding DNA clamp. The dimeric β2 subunit of DNA polymerase III forms a ring that surrounds the DNA duplex. Notice the central cavity through which the DNA template slides. Clasping the DNA molecule in the ring, the polymerase enzyme is able to move without falling off the DNA substrate.
The structure of a sliding DNA clamp. The dimeric β2 subunit of DNA polymerase III forms a ring that surrounds the DNA duplex. Notice the central cavity through which the DNA template slides. Clasping the DNA molecule in the ring, the polymerase enzyme is able to move without falling off the DNA substrate.
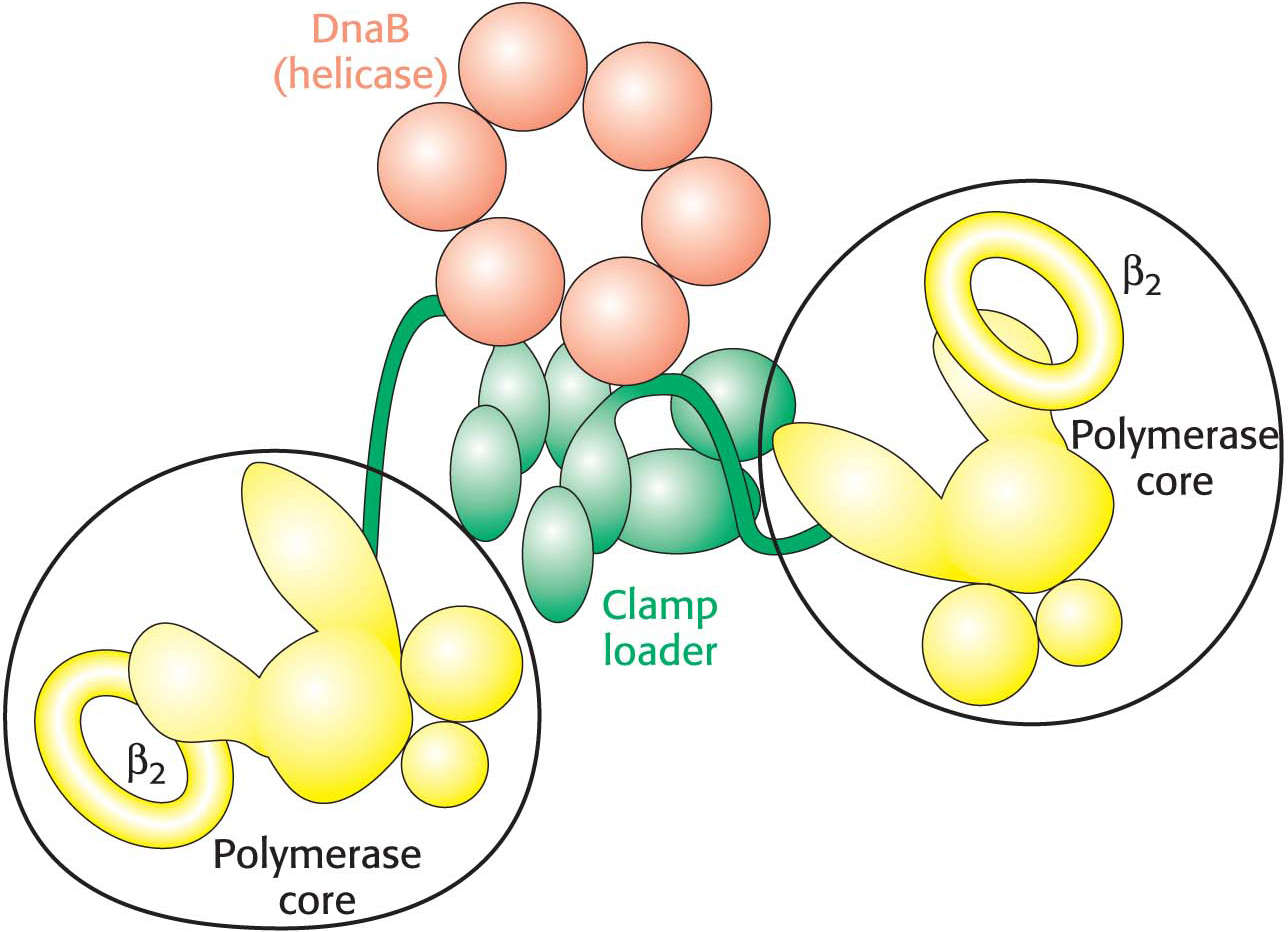
How does DNA become trapped inside the sliding clamp? Polymerases also include assemblies of subunits that function as clamp loaders. These enzymes grasp the sliding clamp and, utilizing the energy of ATP, pull apart the two subunits of the sliding clamp on one side. DNA can move through the gap, inserting itself through the central hole. ATP hydrolysis then releases the clamp, which closes around the DNA.
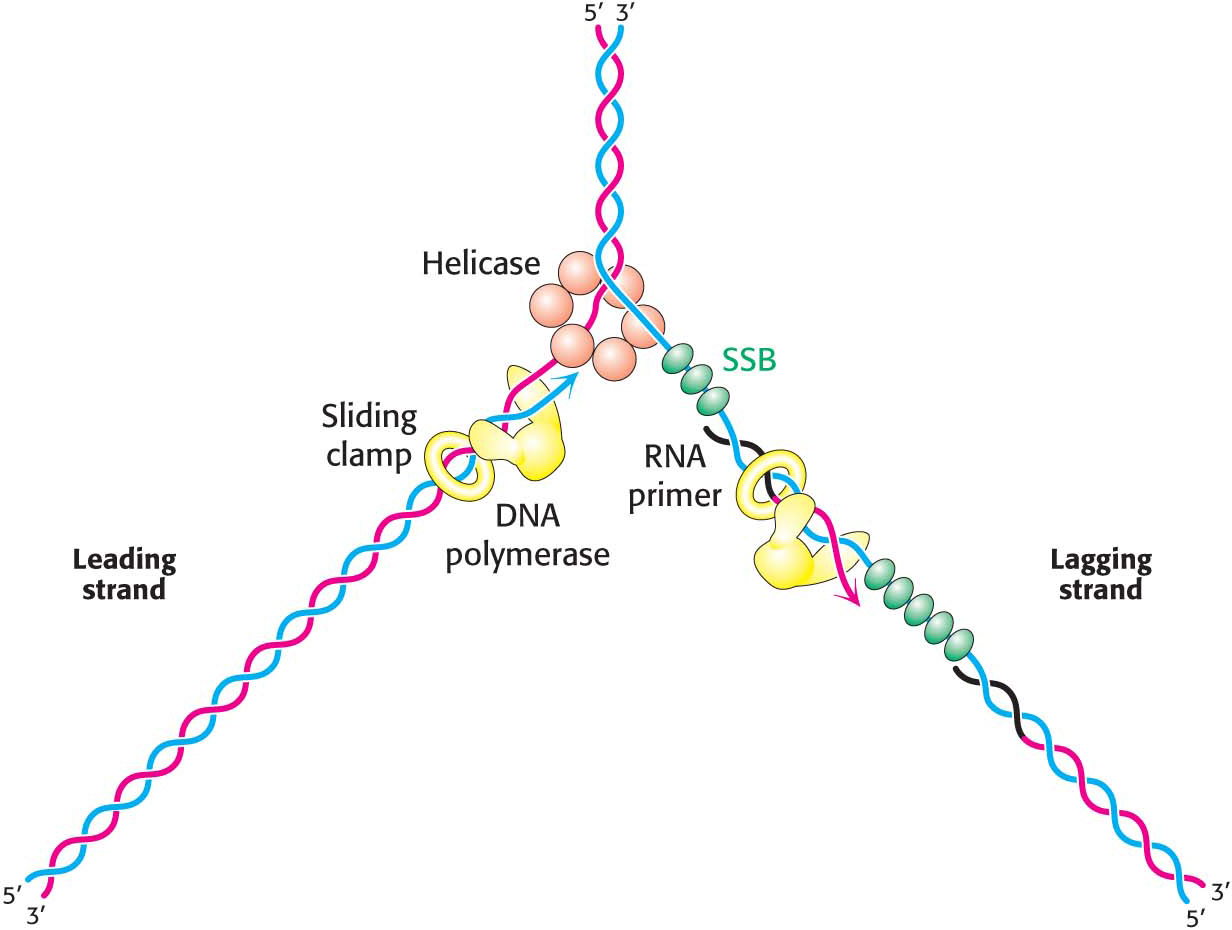
The Leading and Lagging Strands Are Synthesized in a Coordinated Fashion
Replicative polymerases such as DNA polymerase III synthesize the leading and lagging strands simultaneously at the replication fork (Figure 34.16). DNA polymerase III begins the synthesis of the leading strand starting from the RNA primer formed by primase. The duplex DNA ahead of the polymerase is unwound by a helicase. Single-
The mode of synthesis of the lagging strand is necessarily more complex. As mentioned earlier, the lagging strand is synthesized in fragments so that 5′ → 3′ polymerization leads to overall growth in the 3′ → 5′ direction. Yet the synthesis of the lagging strand is coordinated with the synthesis of the leading strand. How is this coordination accomplished? Examination of the subunit composition of the DNA polymerase III holoenzyme reveals an elegant solution (Figure 34.17). The holoenzyme includes two copies of the polymerase core enzyme, which consists of the DNA polymerase itself, a 3′-to-
QUICK QUIZ 2
Why is processivity a crucial property for DNA polymerase III?
DNA polymerase III is charged with copying the entire genome in a limited time. Processivity—
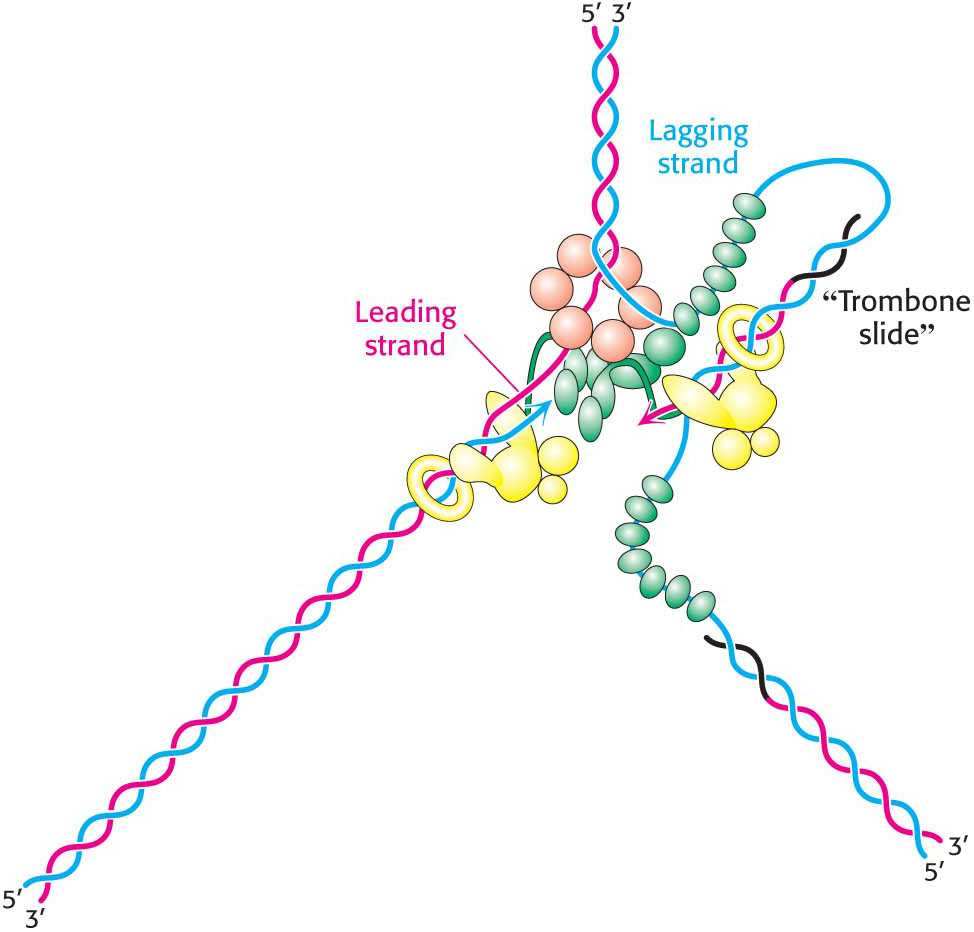
The lagging-

DNA Synthesis Is More Complex in Eukaryotes Than in Bacteria
Replication in eukaryotes is mechanistically similar to replication in bacteria but is more challenging in three ways. One challenge is sheer size: E. coli must replicate 4.6 million base pairs, whereas a human diploid cell must replicate 6 billion base pairs. The second challenge is the fact that, while the genetic information for E. coli is contained on 1 chromosome, human beings have 23 pairs of chromosomes that must be replicated. Finally, whereas the E. coli chromosome is circular, human chromosomes are linear. The third challenge arises because of the nature of DNA synthesis on the lagging strand. Linear chromosomes are subject to shortening with each round of replication unless countermeasures are taken.
The first two challenges are met by the use of multiple origins of replication, which are located between 30 and 300 kilobase pairs (kbp) apart. In human beings, replication of the entire genome requires about 30,000 origins of replication, with each chromosome containing several hundred. Each origin of replication represents a replication unit, or replicon. The use of multiple origins of replication requires mechanisms for ensuring that each sequence is replicated once and only once. How are replicons controlled so that each replicon is replicated only once in each cell division? Proteins, called licensing factors because they permit (license) the formation of the DNA synthesis initiation complex, bind to the origin of replication. These proteins ensure that each replicon is replicated only once in each round of DNA synthesis. After the licensing factors have established the initiation complex, these factors are subsequently destroyed. The license expires after one use.
Two distinct polymerases are needed to copy a eukaryotic replicon. An initiator polymerase called polymerase α begins replication. This enzyme includes a primase subunit, used to synthesize the RNA primer, as well as an active DNA polymerase. After this polymerase has added a stretch of about 20 deoxynucleotides to the primer, it is replaced by DNA polymerase δ, a more processive enzyme and the principal replicative polymerase in eukaryotes. This process is called polymerase switching because one polymerase has replaced another.
Telomeres Are Unique Structures at the Ends of Linear Chromosomes
Whereas the genomes of essentially all bacteria are circular, the chromosomes of human beings and other eukaryotes are linear. The free ends of linear DNA molecules introduce several complications. First, the unprotected termini of the DNA at the end of a chromosome are likely to be more susceptible to digestion by exonucleases if they are left to freely dangle at the end of the chromosome during replication. Second, the complete replication of DNA ends is difficult because polymerases act only in the 5′ → 3′ direction. The lagging strand would have an incomplete 5′ end after the removal of the RNA primer. Each round of replication would further shorten the chromosome, which would, like the Cheshire cat, slowly disappear (Figure 34.20).
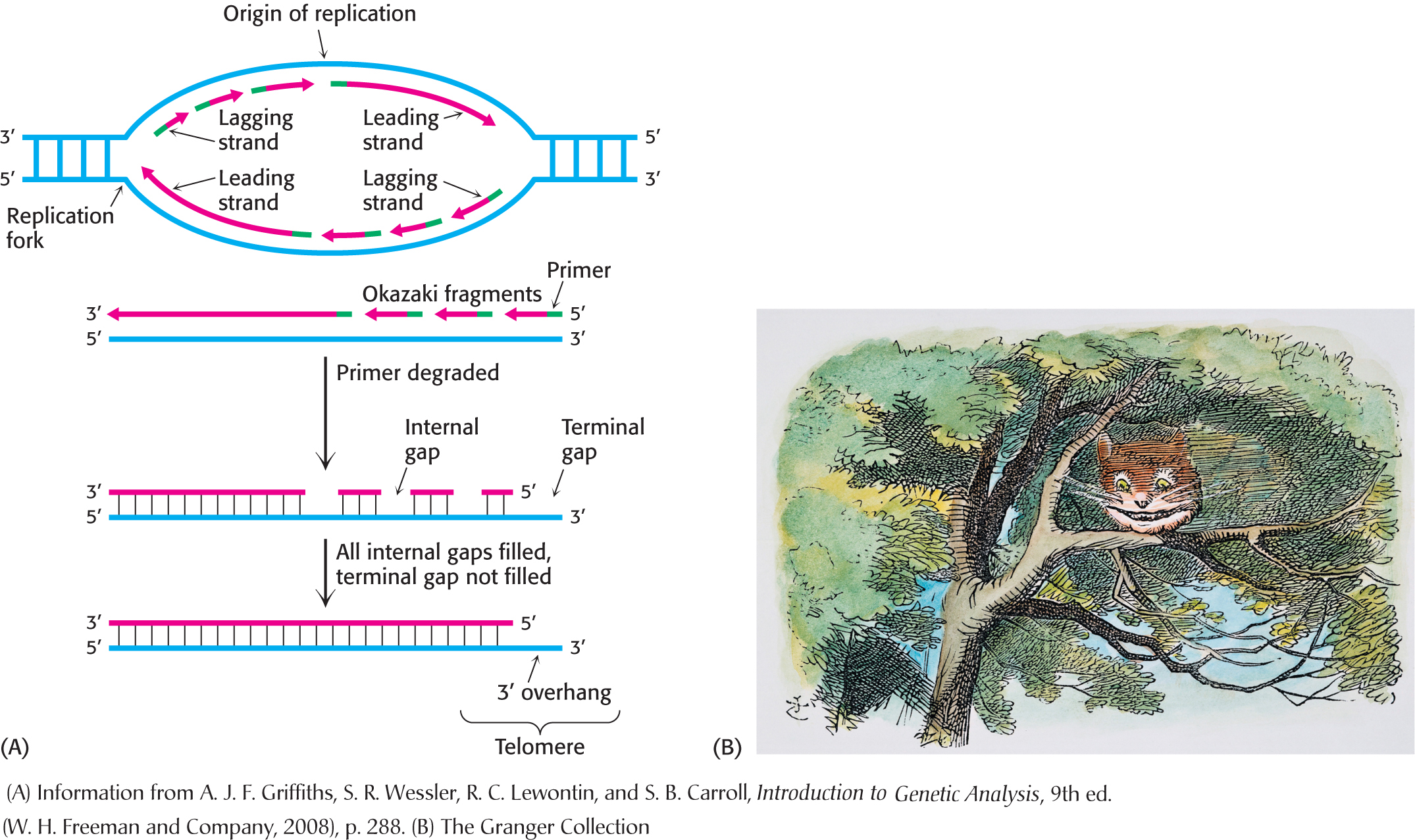
What characteristics of the chromosome ends, called telomeres (from the Greek telos, meaning “an end”), mitigate these two problems? The most notable feature of telomeric DNA is that it contains hundreds of tandem repeats of a hexanucleotide sequence. One of the strands is G-

 CLINICAL INSIGHT
CLINICAL INSIGHTTelomeres Are Replicated by Telomerase, a Specialized Polymerase That Carries Its Own RNA Template
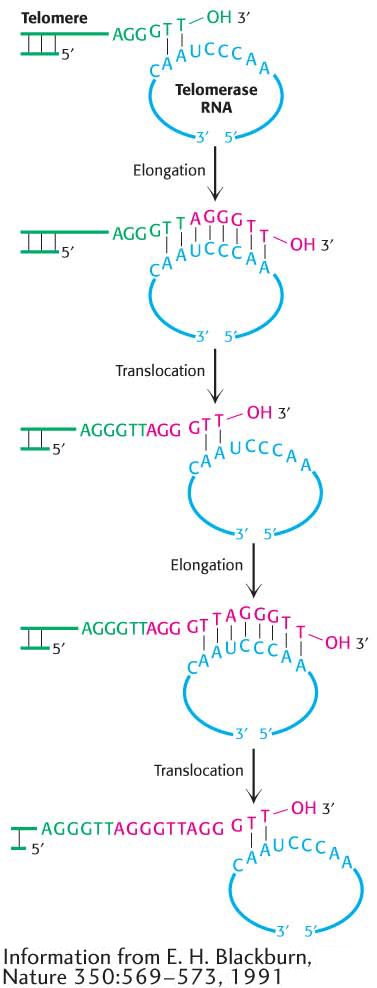
We now see how telomeres help to protect the ends of the DNA, but the problem of how the ends are replicated remains. What steps are taken to prevent the lagging strand from disappearing after repeated cycles of replication? The solution is to add nucleotides to the leading strand so that the lagging strand will always maintain its approximate length. This task falls to the enzyme telomerase, which contains an RNA molecule that acts as a template for extending the leading strand. The extended leading strand then acts as a template to elongate the lagging strand, thus ensuring that the chromosome will not shorten after many rounds of replication (Figure 34.22).
Telomerase activity is low or absent in most human cells. Consequently, as the cells divide, telomeres shorten. At some point, cell division ceases because the telomeres are too short and programmed cell death is initiated. Thus, telomere shortening serves as a counting device to limit cell proliferation. Indeed, telomere shortening may play a role in aging and the development of pathological conditions. So if telomerase activity is low in human cells, why can cancer, which is characterized by unlimited cell proliferation, develop in humans? Telomerase reactivation is one of the hallmarks of cancer cells. Because cancer cells express high levels of telomerase, whereas most normal cells do not, telomerase is a potential target for anticancer therapy. A variety of approaches for blocking telomerase expression or blocking its activity are under investigation for cancer treatment and prevention.