
36.2 RNA Synthesis Comprises Three Stages
RNA synthesis, like nearly all biological polymerization reactions, takes place in three stages: initiation, elongation, and termination.
Transcription Is Initiated at Promoter Sites on the DNA Template
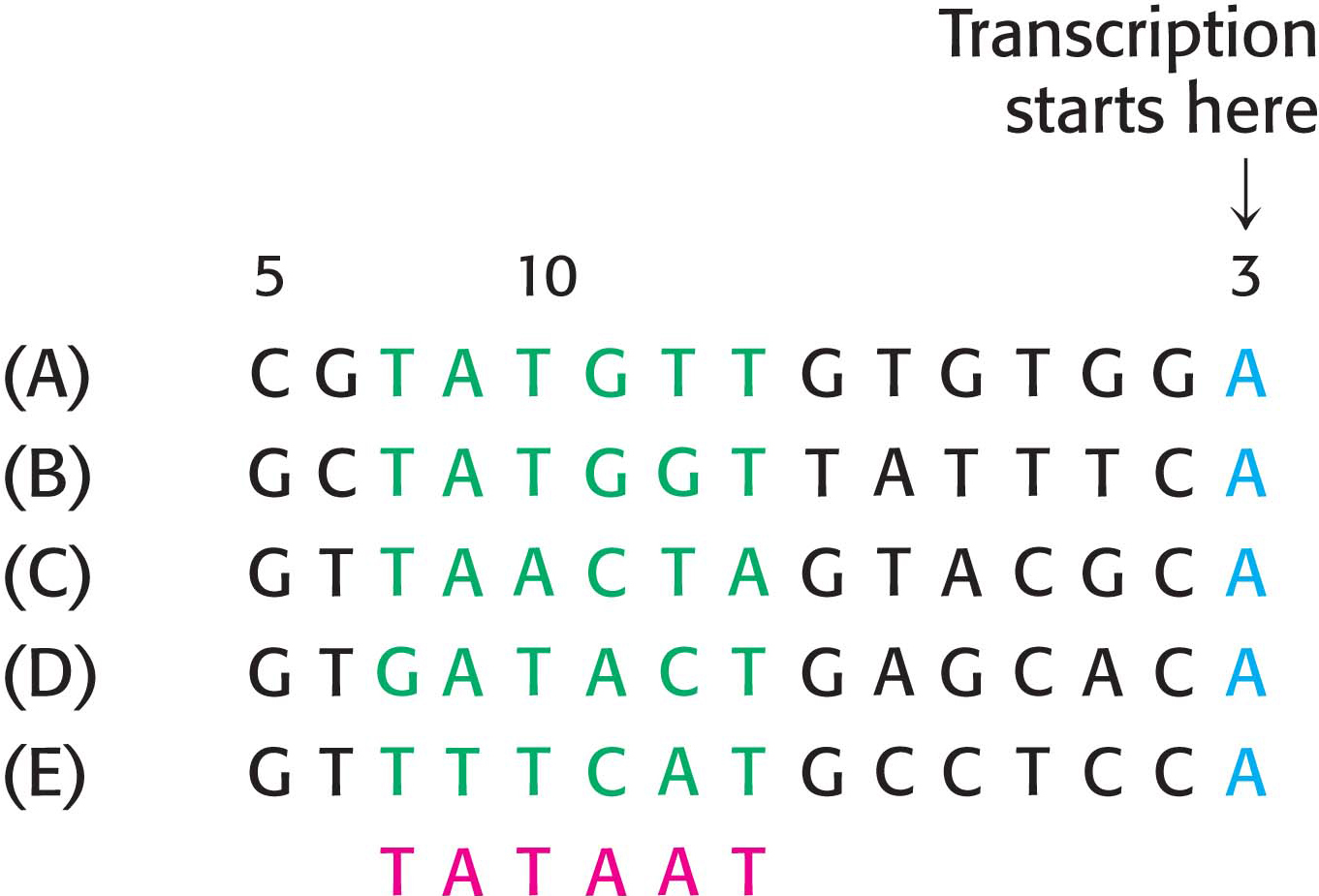
Let us consider the problem of initiation. There may be billions of bases in a genome, arranged into thousands of genes. How does RNA polymerase determine where to begin transcription? Special DNA sequences, called promoters, direct the RNA polymerase to the proper site for the initiation of transcription. Two common DNA sequences that act as the promoter for many bacterial genes are present on the 5′ (upstream) side of the start site. They are known as the −10 site (also called the Pribnow box) and the −35 sequence because they are centered at approximately 10 and 35 nucleotides upstream of the start site. They are each 6 bp long. Their consensus (average) sequences, deduced from the analysis of many promoters (Figure 36.4), are

The first nucleotide (the start site) of a transcribed DNA sequence (gene) is denoted as +1 and the second one as +2; the nucleotide preceding the start site is denoted as −1. These designations refer to the coding strand of DNA.
DID YOU KNOW?
Consensus sequence
Not all base sequences of promoter sites are identical. However, they do possess common features, which can be represented by an idealized consensus sequence. Each base in the consensus sequence TATAAT is found in most prokaryotic promoters. Nearly all promoter sequences differ from this consensus sequence at only one or two bases.
Not all promoters are equally efficient. Genes with strong promoters are transcribed frequently—
Outside the promoter in a subset of highly expressed genes is the upstream element, also called the UP element (for upstream element). This sequence is present 40 to 60 nucleotides upstream of the transcription start site. The UP element is bound by the α subunit of RNA polymerase and increases the efficiency of transcription by creating an additional binding site for the polymerase.
Sigma Subunits of RNA Polymerase Recognize Promoter Sites
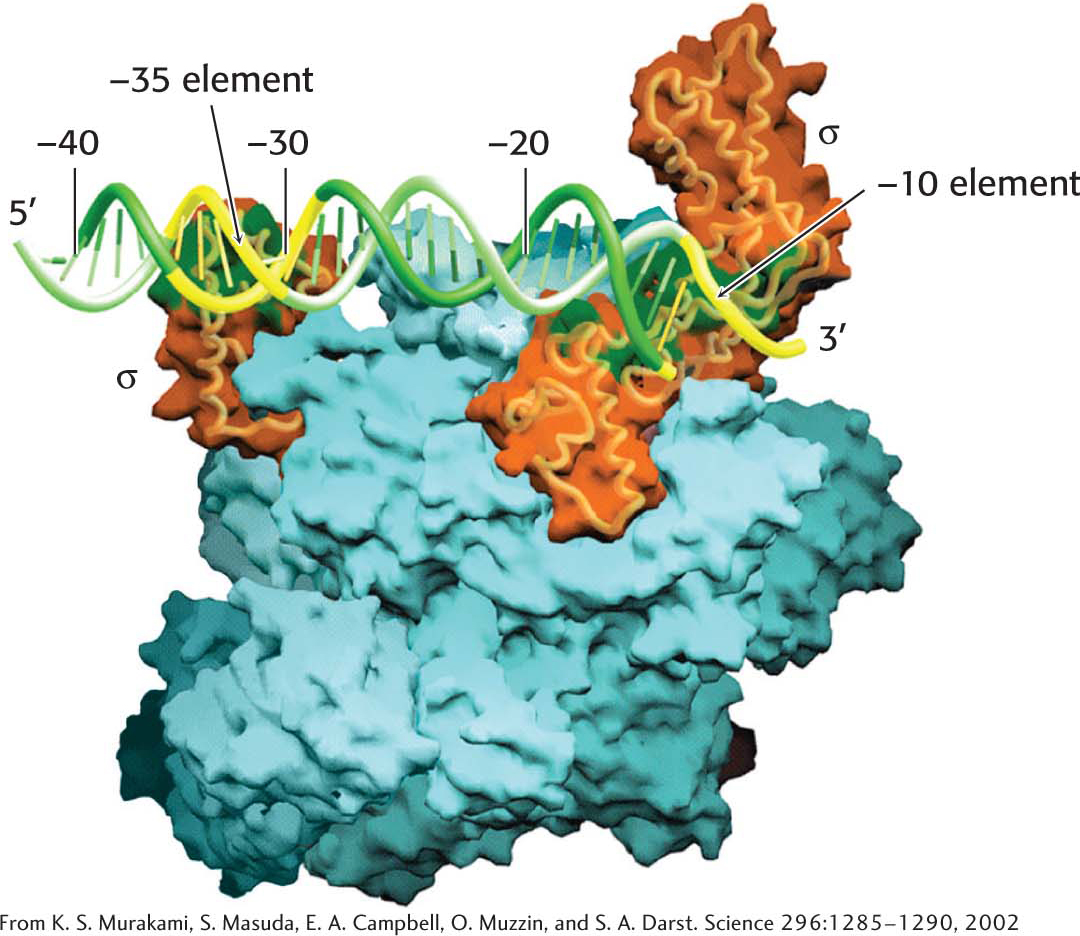
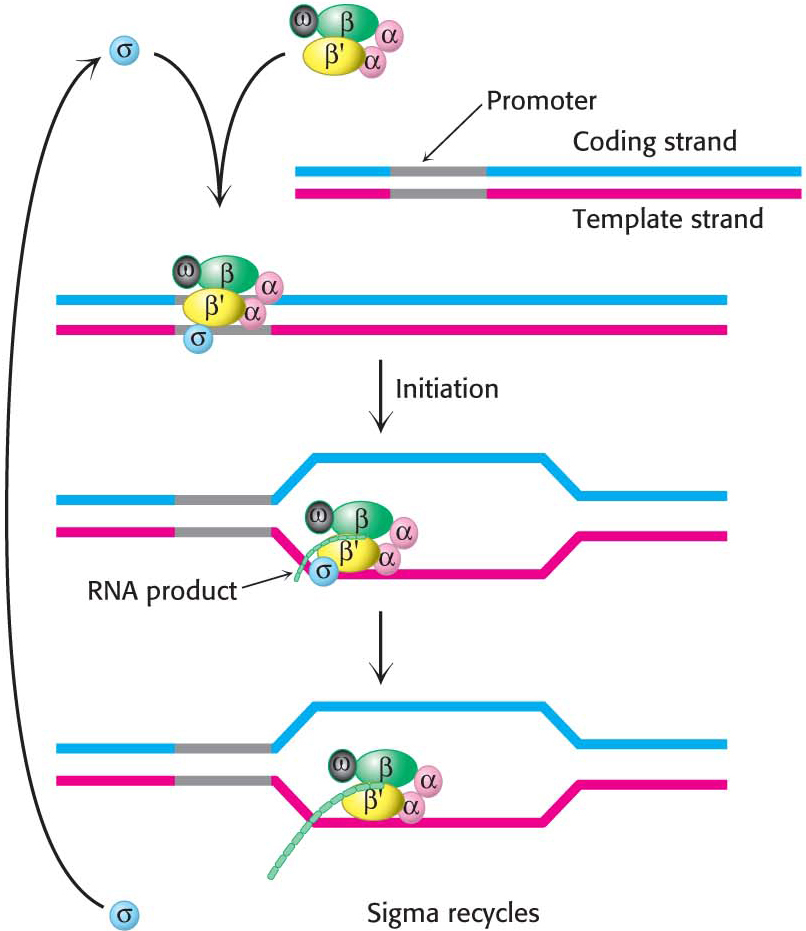
The α2ββ′ω core of E. coli RNA polymerase is unable to start transcription at promoter sites. The first step in initiation is finding the start site for transcription. Proper initiation depends on the σ subunit, which helps the polymerase locate the correct start site. The σ subunit does so in two ways. First, paradoxically, it decreases the affinity of RNA polymerase for general regions of DNA by a factor of 104. This decrease permits the enzyme to bind to the DNA double helix and rapidly slide along it, searching for the promoter. In the absence of the σ subunit, the core enzyme binds DNA indiscriminately and tightly. Second, the σ subunit enables RNA polymerase to recognize promoter sites (Figure 36.5). When the new RNA chain (the nascent chain) reaches 9 or 10 nucleotides in length, it contacts the σ subunit, facilitating its ejection from the transcription complex. Release of the subunit marks the initiation to elongation transition. After its release, the σ subunit can assist initiation by another core enzyme. Thus, the σ subunit acts catalytically (Figure 36.6).
E. coli has many kinds of σ factors for recognizing several types of promoter sequences in E. coli DNA. The type that recognizes the consensus sequences described earlier is called σ70 because it has a mass of 70 kDa. Other σ factors help the bacteria to withstand periods of elevated temperature, nitrogen starvation, and other environmental conditions.
RNA Strands Grow in the 5′-to-3′ Direction
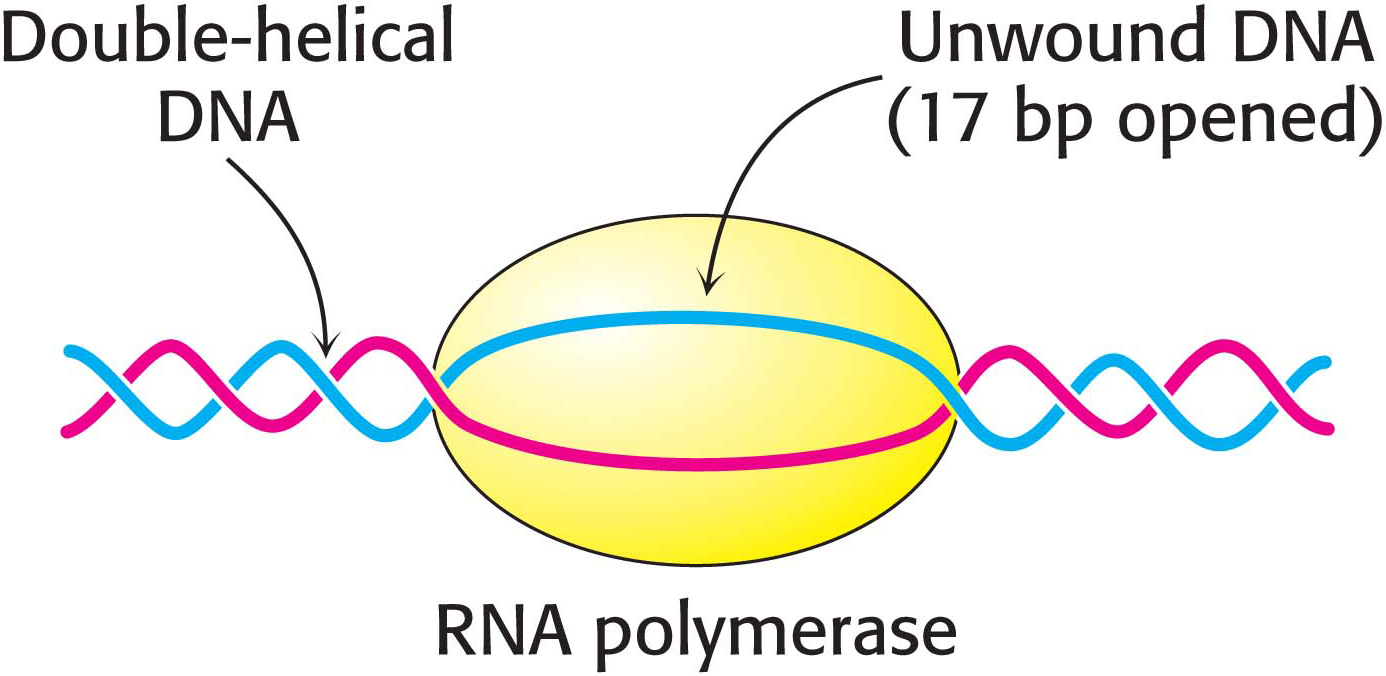
After RNA polymerase has bound to a promoter and before synthesis can begin, it must unwind a segment of the DNA double helix so that nucleotides on the template strand can direct the synthesis of the RNA product. Each bound polymerase molecule unwinds a 17-
The transition from the closed promoter complex (in which DNA is double helical) to the open promoter complex (in which a DNA segment is unwound) is an essential event in transcription. After this event has taken place, the stage is set for the formation of the first phosphodiester linkage of the new RNA chain.
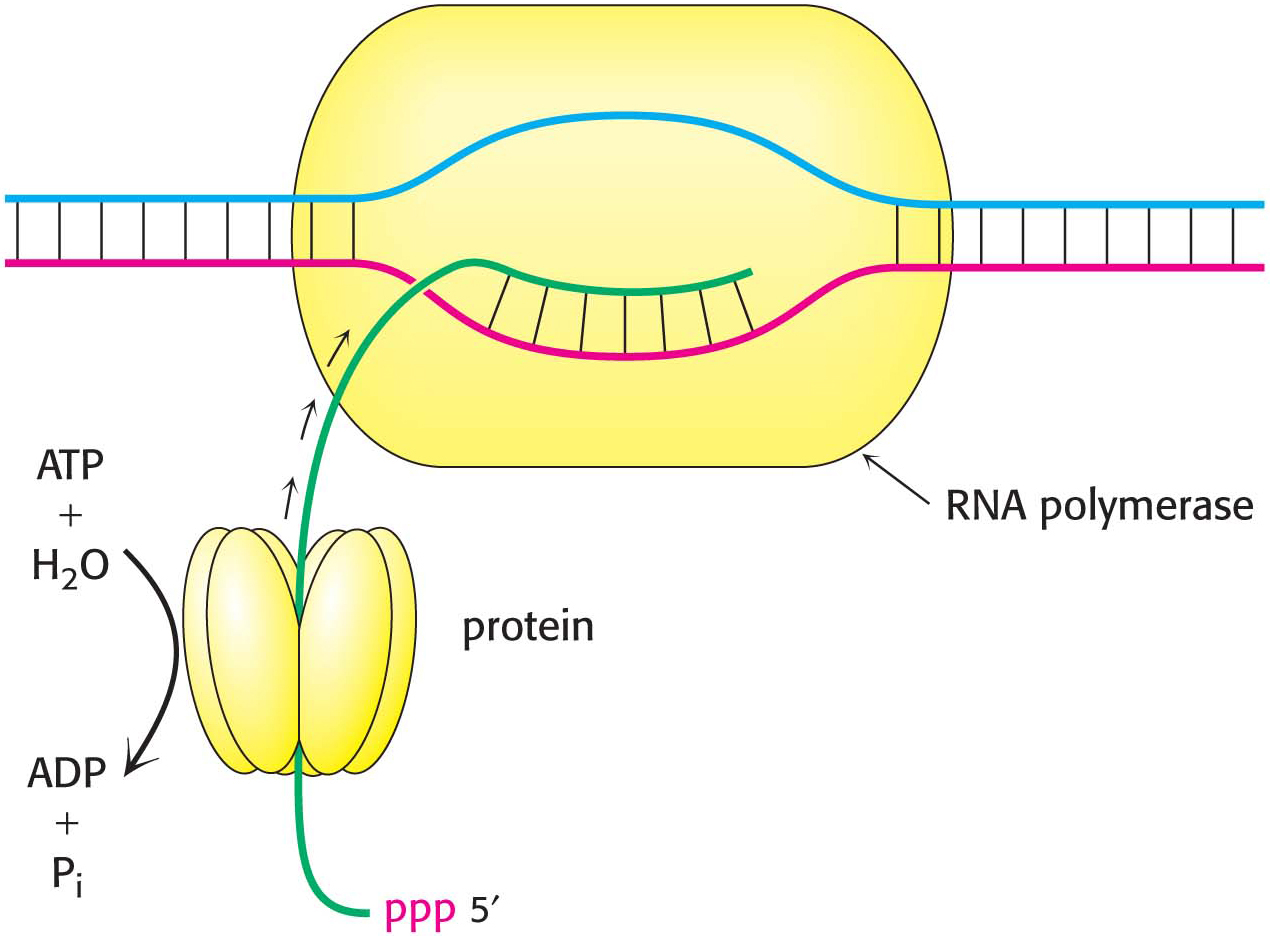
In contrast with DNA synthesis, RNA synthesis can start de novo, without needing a primer. In bacteria, most newly synthesized RNA strands carry a highly distinctive tag on the 5′ end: the first base at that end is either pppG or pppA, confirming that RNA strands, like DNA strands, grow in the 5′ → 3′ direction (Figure 36.8).

Elongation Takes Place at Transcription Bubbles That Move Along the DNA Template
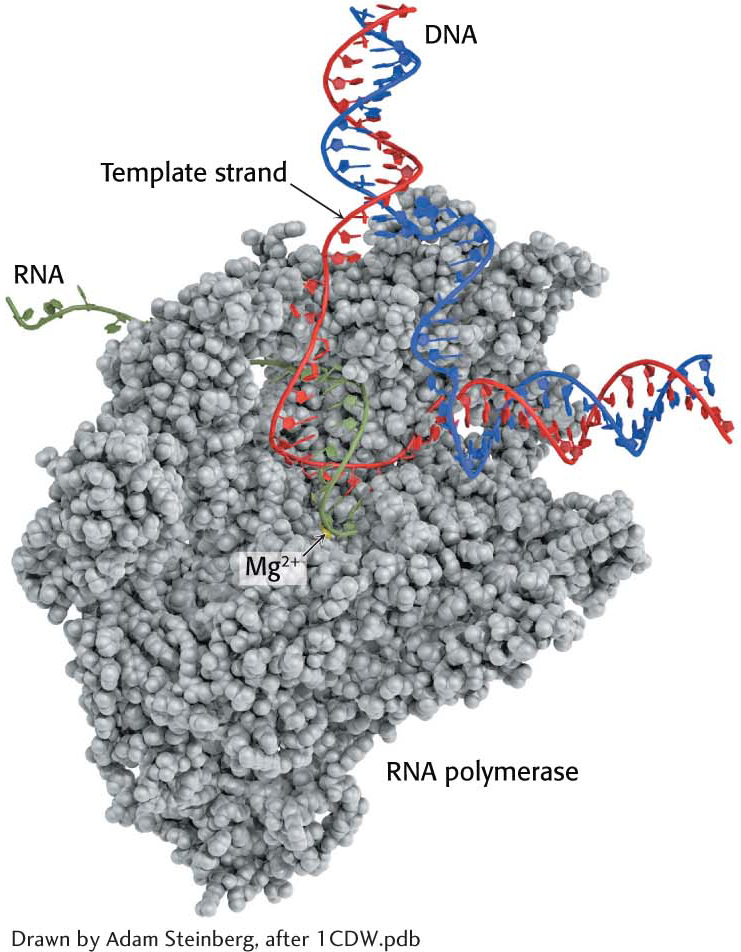
The elongation phase of RNA synthesis begins after the formation of the first phosphodiester linkage. An important change is the loss of the σ subunit shortly after initiation. The loss of σ enables the core enzyme to strongly bind to the DNA template. Indeed, RNA polymerase continues transcription until a termination signal is reached. The region containing RNA polymerase, DNA, and nascent RNA is called a transcription bubble because it contains a locally denatured “bubble” of DNA (Figure 36.9). About 17 bp of DNA are unwound at a time throughout the elongation phase, as in the initiation phase. The newly synthesized RNA forms a hybrid helix with about 8 bp of the template DNA strand. The 3′-hydroxyl group of the RNA in this hybrid helix is positioned so that it can attack the α-phosphorus atom of an incoming ribonucleoside triphosphate. The transcription bubble moves a distance of 170 Å (17 nm) in a second, which corresponds to a rate of elongation of about 50 nucleotides per second, extruding the newly synthesized RNA from the polymerase (Figure 36.10). Although rapid, this rate is much slower than that of DNA synthesis, which is nearly 1000 nucleotides per second.
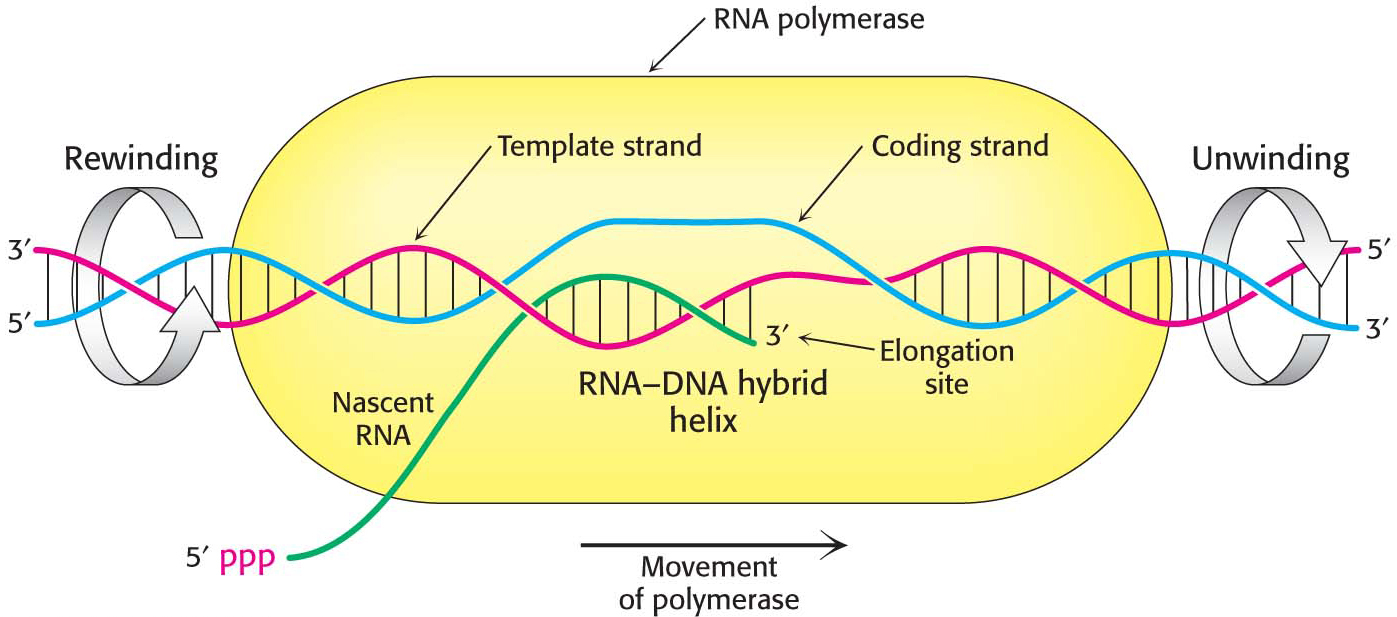
As in all real-
An RNA Hairpin Followed by Several Uracil Residues Terminates the Transcription of Some Genes
As already stated, the σ subunit enables bacterial RNA polymerase to initiate transcription at specific sites. Elongation then takes place, but how does the enzyme determine when to stop transcription? The termination of transcription is as precisely controlled as its initiation. In the termination phase of transcription, the formation of phosphodiester linkages stops, the RNA–
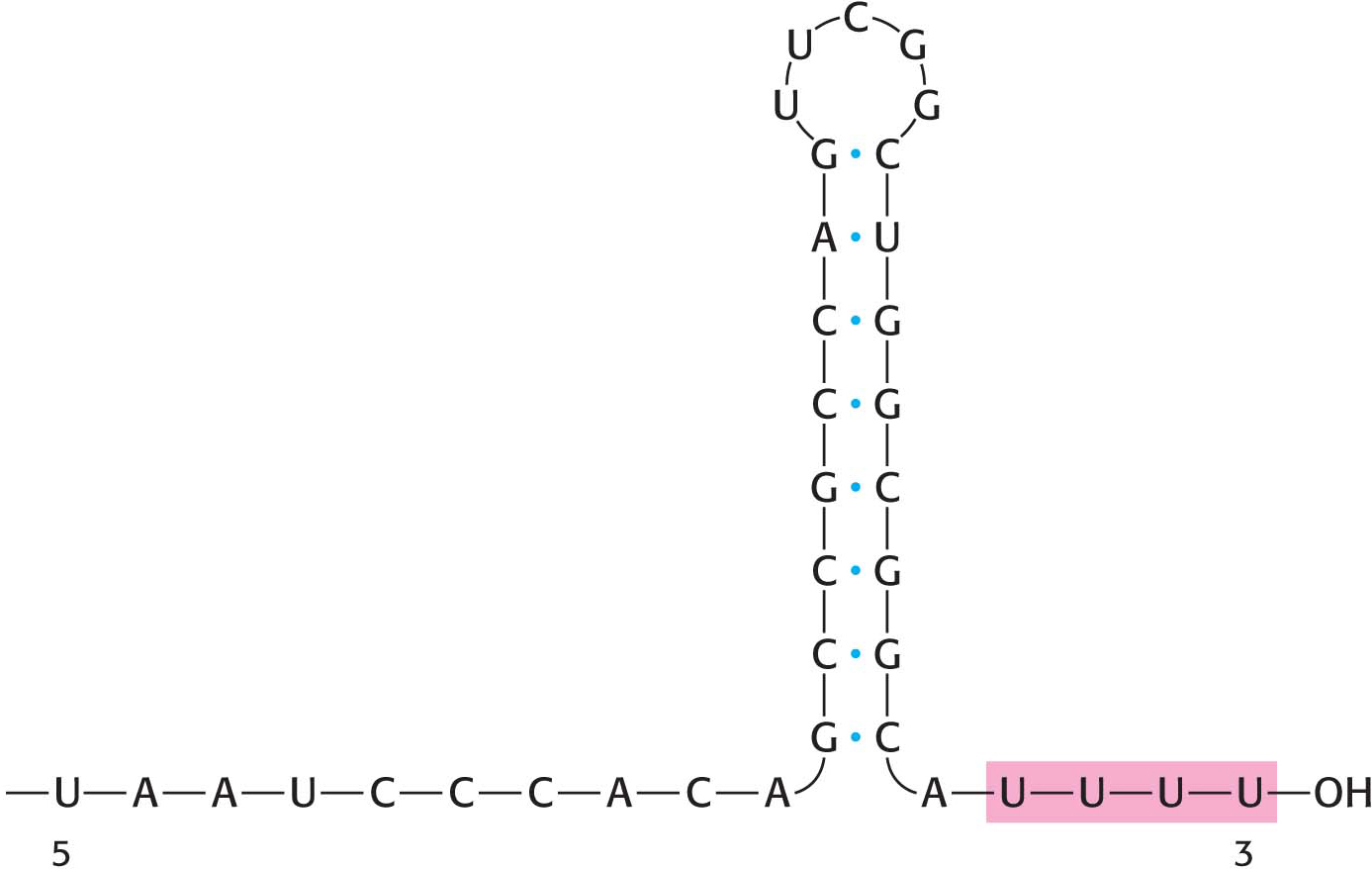
DID YOU KNOW?
Derived from the Greek palindromos, meaning “running back again,” a palindrome is a word, sentence, or verse that reads the same from right to left as it does from left to right: “radar” or “senile felines” are examples.
How does this combination hairpin–
The Rho Protein Helps Terminate the Transcription of Some Genes
RNA polymerase needs no help in terminating transcription when it encounters a hairpin followed by several U residues. At other sites, however, termination requires the participation of an additional protein with ATPase activity called rho (ρ). This type of termination is called protein-
Hexameric ρ specifically binds a stretch of 72 nucleotides on single-
QUICK QUIZ 1
How is transcription initiation controlled in E. coli? What is the mechanism of termination?
The σ factor recognizes the promoter site. When transcription starts, σ leaves the enzyme to assist in the initiation by another polymerase. Termination takes place in one of two common ways. If the RNA product forms a hairpin that is followed by several uracil residues, the polymerase pauses and falls from the template. Alternatively, the ATPase rho binds the RNA products and pushes the polymerase off the template.
Precursors of Transfer and Ribosomal RNA Are Cleaved and Chemically Modified After Transcription
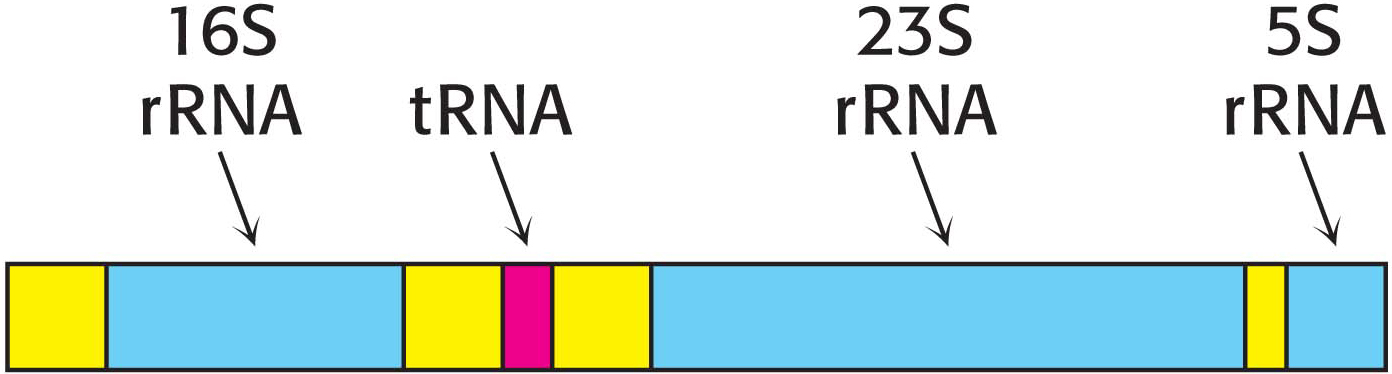
The product of RNA synthesis is not always the mature RNA molecule. Although messenger RNA molecules in bacteria undergo little or no modification after synthesis by RNA polymerase and, indeed, may be translated while they are still being transcribed, it is not the case for transfer RNA molecules and ribosomal RNA molecules. Transfer RNA and ribosomal RNA molecules are generated by cleavage and other modifications of the transcription product. For example, in E. coli, three kinds of rRNA molecules and a tRNA molecule are excised from a single primary RNA transcript that also contains noncoding regions called spacer regions (Figure 36.13). Other transcripts contain arrays of several kinds of tRNA or of several copies of the same tRNA. The nucleases that cleave and trim these precursors of rRNA and tRNA are highly precise. Ribonuclease P, for example, generates the correct 5′ terminus of all tRNA molecules in E. coli. This interesting enzyme contains a catalytically active RNA molecule embedded in its polypeptide chains (Chapter 38). Ribonuclease III excises 5S, 16S, and 23S rRNA precursors from the primary transcript by cleaving double-
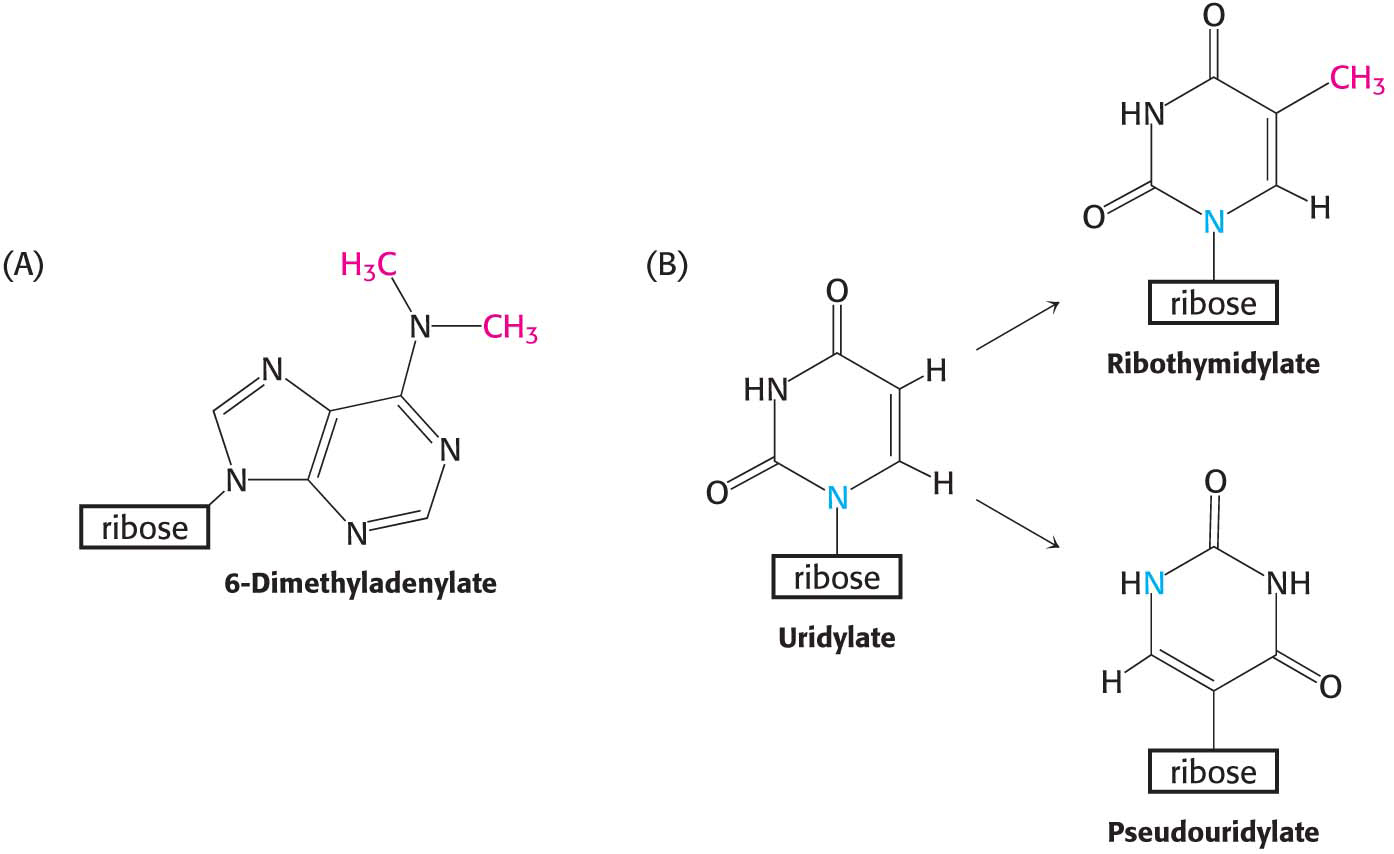
Excision from a precursor is not the only way in which rRNAs and tRNAs are processed. A second type of processing, common for tRNA molecules, is the addition of nucleotides to the termini of some RNA strands. For example, CCA, a terminal sequence required for the function of all tRNAs, is added to the 3′ ends of tRNA molecules that do not already possess this terminal sequence. A third way to alter rRNA and tRNA is the modification of bases and ribose units. In bacteria, some bases of rRNA are methylated. Similarly, unusual bases are formed in all tRNA molecules by the enzymatic modification of a standard ribonucleotide in a tRNA precursor. For example, uridylate residues are modified after transcription to form ribothymidylate and pseudouridylate (Figure 36.14). These modifications generate diversity, allowing greater structural and functional versatility.
 CLINICAL INSIGHT
CLINICAL INSIGHTSome Antibiotics Inhibit Transcription
We are all aware of the benefits of antibiotics, highly specific inhibitors of biological processes that are synthesized by many bacteria. Rifampicin and actinomycin are two antibiotics that inhibit transcription, although in quite different ways. Rifampicin is a semisynthetic derivative of rifamycins, which are isolated from a strain of Amycolatopsis that is related to the bacterium that causes strep throat.
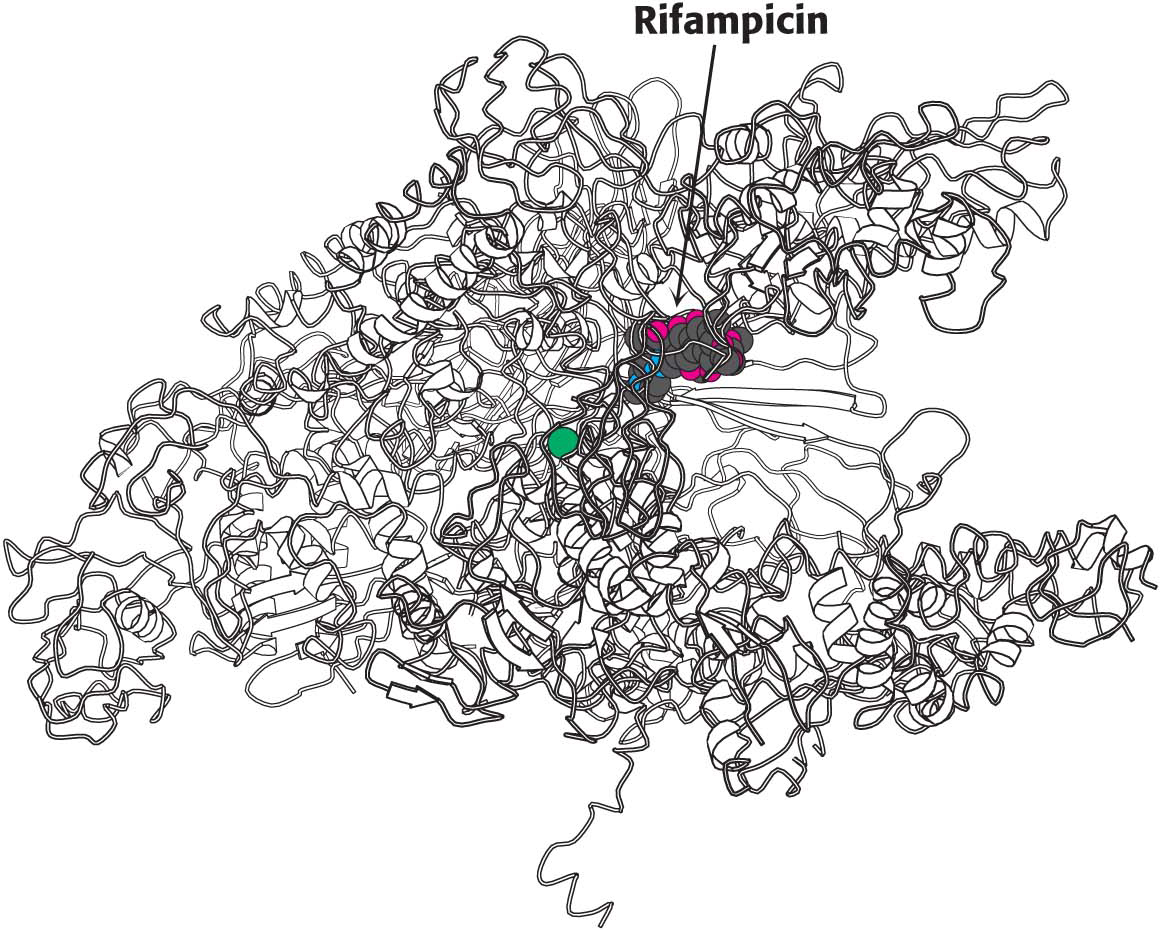
This antibiotic specifically inhibits the initiation of RNA synthesis. Rifampicin interferes with the formation of the first few phosphodiester linkages in the RNA strand by blocking the channel into which the RNA–
Actinomycin D, a polypeptide-