✓ 4 Explain how RNA is processed after its transcription in eukaryotes.
The most extensively modified transcription product is that of RNA polymerase II: most of this RNA will be processed to mRNA. The immediate product of RNA polymerase II is sometimes referred to as pre-mRNA. Both the 5′ and the 3′ ends of the pre-mRNA are modified, and most pre-mRNA molecules are spliced to remove the introns.
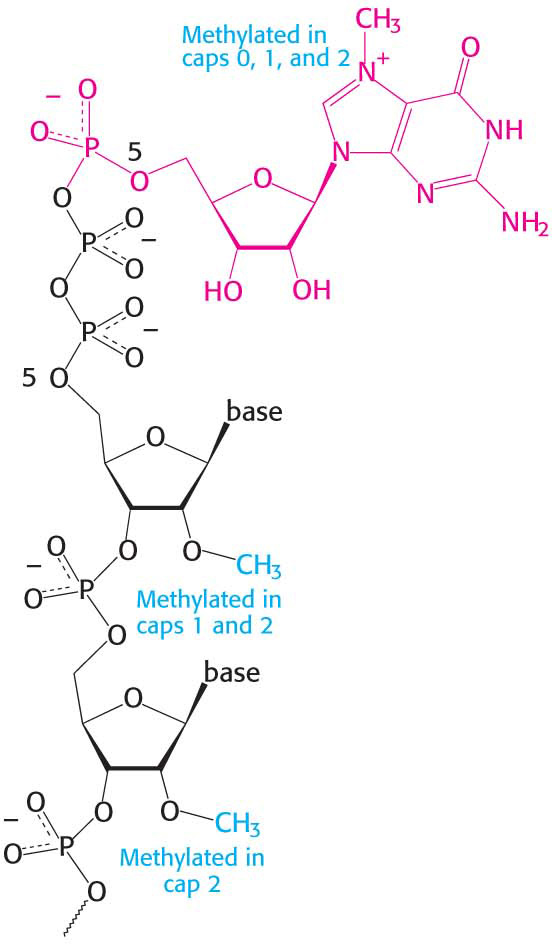
Figure 38.3 Capping the 5′ end. Caps at the 5′ end of eukaryotic mRNA include 7-methylguanylate (red) attached by a triphosphate linkage to the ribose at the 5′ end. None of the riboses are methylated in cap 0, one is methylated in cap 1, and both are methylated in cap 2.
The 5′ triphosphate end of the nascent RNA strand is modified shortly after initiation of RNA synthesis, when the strand is about 25 nucleotides in length. The modification occurs in three steps. First, a phosphoryl group is removed by hydrolysis by RNA triphosphatase. Second, the diphosphate 5′ end of the RNA attacks the α-phosphorus atom of a molecule of GTP to form an unusual 5′–5′ triphosphate linkage, a reaction catalyzed by guanylyltransferase. This distinctive terminus is called a 5′ cap (Figure 38.3). Third, the N-7 nitrogen atom of the terminal guanine is then methylated by RNA N-7 guanine methyltransferase, which uses S-adenosylmethionine as the methyl donor to form cap 0. The triphosphatase and guanylyltranseferase are present on the same polypeptide chain, providing another example of a bifunctional enzyme. The adjacent riboses may be subsequently methylated to form cap 1 or cap 2. Caps contribute to the stability of mRNAs by protecting their 5′ ends from phosphatases and nucleases. In addition, caps enhance the translation of mRNA by eukaryotic protein-synthesizing systems (Chapter 40).
As mentioned earlier, pre-mRNA is also modified at the 3′ end. Most eukaryotic mRNAs contain a polyadenylate, or poly(A), tail at that end, added after transcription has ended. Thus, DNA does not encode this poly(A) tail. Indeed, the nucleotide preceding the poly(A) attachment site is not the last nucleotide to be transcribed. Some primary transcripts contain hundreds of nucleotides beyond the 3′ end of the mature mRNA, all of which are removed before the poly(A) tail is added.
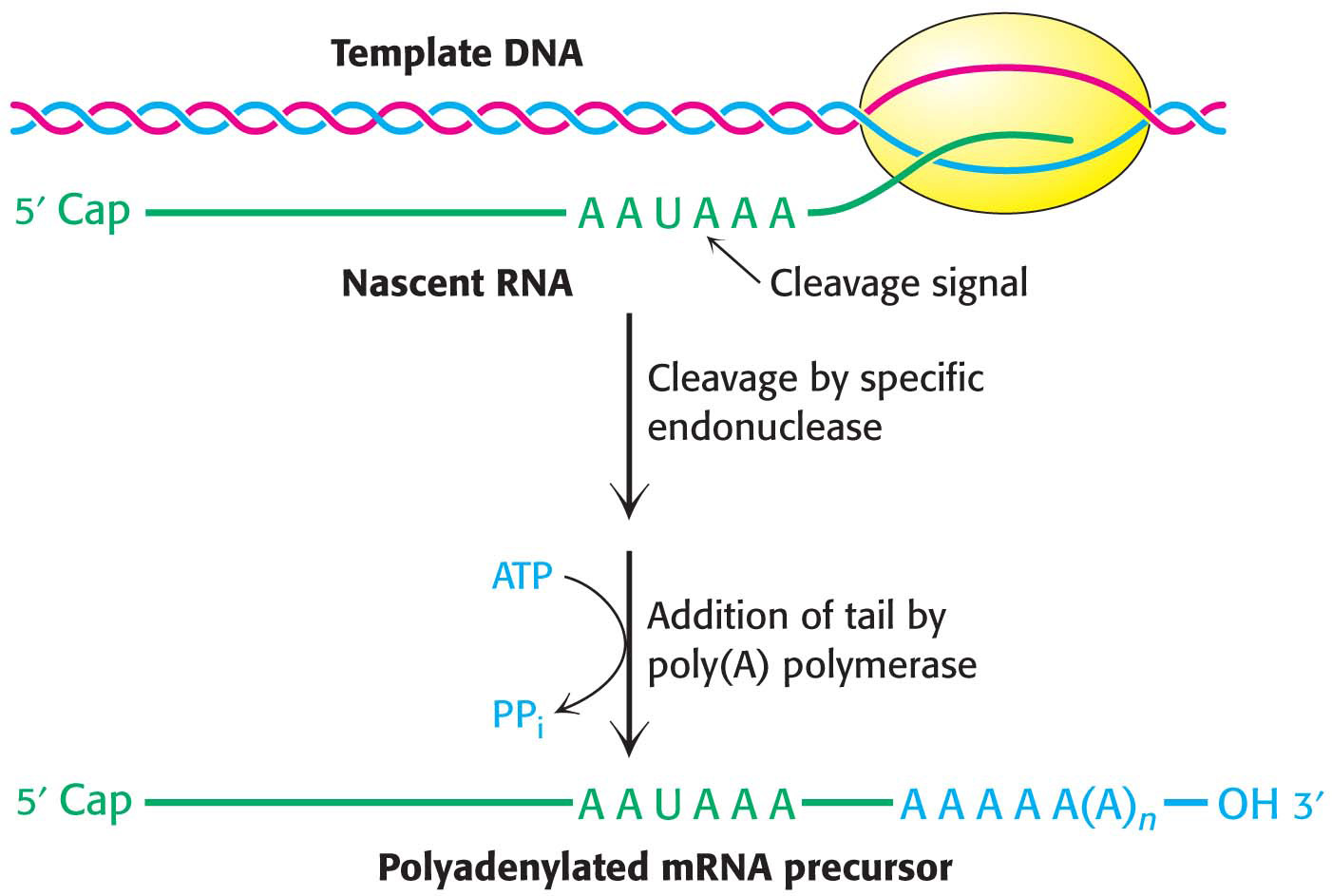
How is the final form of the 3′ end of the pre-mRNA created? The 3′ end of the pre-mRNA is generated by a complex that contains a specific endonuclease (the cleavage and polyadenylation specificity factor, CPSF) that recognizes the sequence AAUAAA (Figure 38.4). The presence of internal AAUAAA sequences in some mature mRNAs indicates that AAUAAA is only part of the cleavage signal; its context also is important. After cleavage of the pre-RNA by the endonuclease, a poly(A) polymerase adds about 250 adenylate residues to the 3′ end of the transcript; ATP is the donor in this reaction.
Figure 38.4 Polyadenylation of a primary transcript. A specific endonuclease cleaves the RNA downstream of AAUAAA. Poly(A) polymerase then adds about 250 adenylate residues.
Page 694
The role of the poly(A) tail is still not firmly established despite much effort. However, evidence that it enhances translation efficiency and the stability of mRNA is accumulating. Messenger RNA devoid of a poly(A) tail can be transported out of the nucleus, but such RNA is usually a much less effective template for protein synthesis than is one with a poly(A) tail. The half-life of an mRNA molecule may be determined in part by the rate of degradation of its poly(A) tail.
Sequences at the Ends of Introns Specify Splice Sites in mRNA Precursors
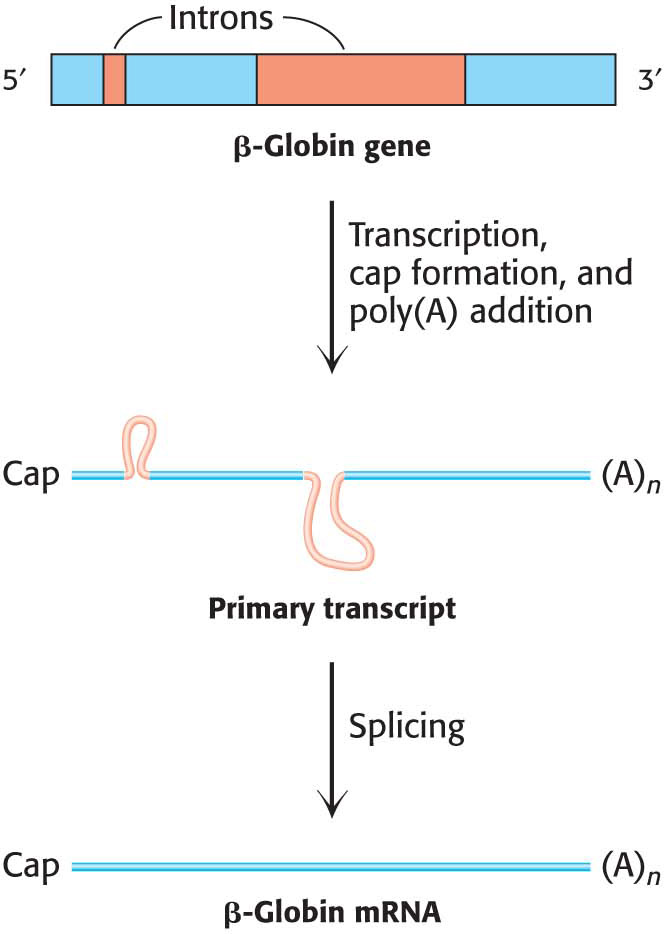
Figure 38.5 The transcription and processing of the β-globin gene. The gene is transcribed to yield the primary transcript, which is modified by cap and poly(A) addition. The introns in the primary RNA transcript are removed to form the mRNa.
Processing at the ends of the pre-mRNA molecule is not the only modification that these molecules must undergo. More than 90% of human protein-encoding genes are composed of exons and introns—coding regions and noncoding regions, respectively. The introns must be removed, and the exons must be linked to form the final mRNA in a process called splicing (Figure 38.5). To achieve the accurate removal of introns, the correct splice site must be clearly marked. Does a particular sequence denote the splice site? The sequences of thousands of intron–exon junctions within RNA transcripts are known. In eukaryotes ranging from yeast to mammals, these sequences have a common structural motif: the intron begins with GU and ends with AG. The consensus sequence at the 5′ splice site in vertebrates is AGGUAAGU, where the GU is invariant (Figure 38.6). At the 3′ end of an intron, the consensus sequence is a stretch of 10 pyrimidines (U or C, termed the polypyrimidine tract), followed by any base and then by C, and ending with the invariant AG. Introns also have an important internal site located between 20 and 50 nucleotides upstream of the 3′ splice site; it is called the branch site for reasons that will be evident shortly.
Figure 38.6 Splice sites. Consensus sequences for the 5′ splice site and the 3′ splice site are shown. Py stands for pyrimidine.
The 5′ and 3′ splice sites and the branch site are essential for determining where splicing takes place. Mutations in each of these three critical regions lead to aberrant splicing. Introns vary in length from 50 to 10,000 nucleotides, and so the splicing machinery may have to find the 3′ site several thousand nucleotides away. This splicing must be exquisitely sensitive because the nucleotide information is converted into protein information in three nonoverlapping nucleotide sequences called codons (Chapter 39). Thus, a one-nucleotide shift in the course of splicing would alter the nucleotide information on the 3′ side of the splice to give an entirely different amino acid sequence, likely including a Stop codon that would prematurely stop protein synthesis. Specific sequences near the splice sites (in both the introns and the exons) play an important role in splicing regulation, particularly in designating splice sites when there are many alternatives. Despite our knowledge of splice-site sequences, predicting pre-mRNAs and their protein products from genomic DNA sequence information remains a challenge.
Page 695
Small Nuclear RNAs in Spliceosomes Catalyze the Splicing of mRNA Precursors
What are the molecular machines that so precisely excise introns and join exons? A group of special RNAs and more than 300 proteins combine with pre-mRNA to form a large splicing complex called the spliceosome. The splicesome has a mass of ~ 4.8 MDa, and may be the most complicated molecular machine in the cell. Let’s consider some of the components of the spliceosome.
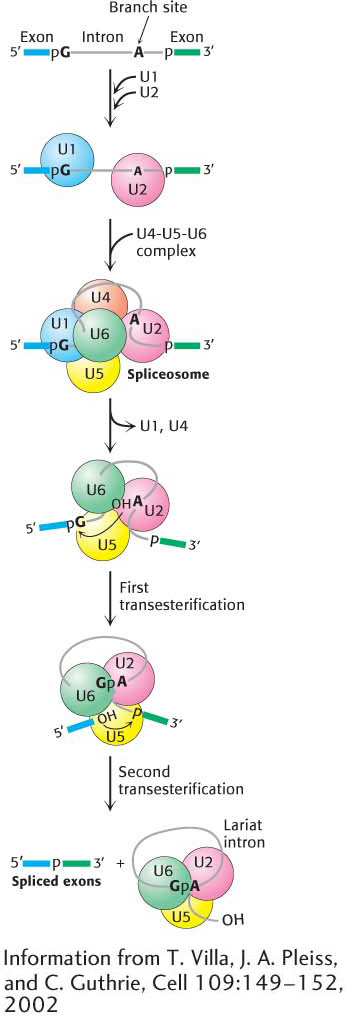
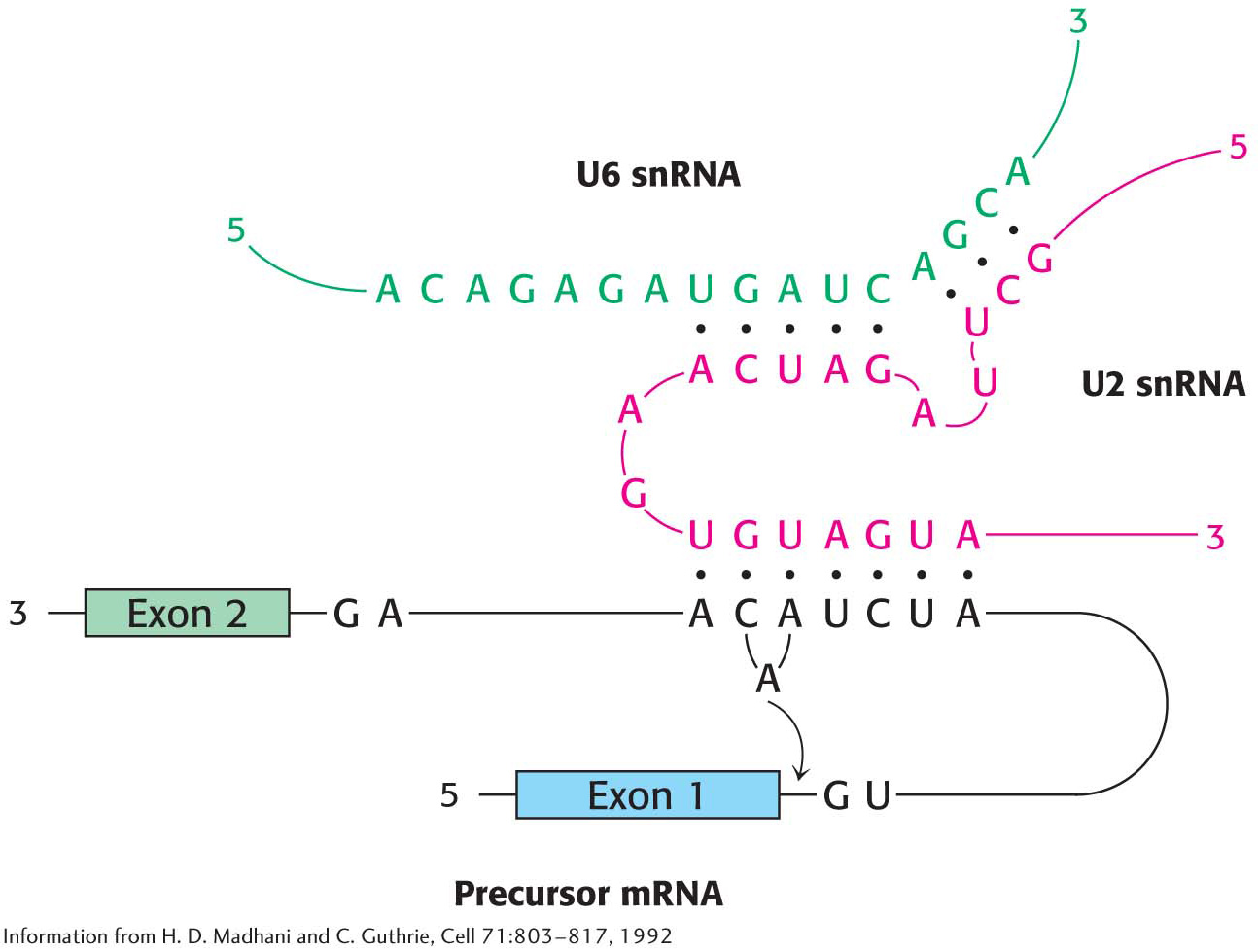
Figure 38.7 Spliceosome assembly and action. U1 binds the 5′ splice site, and U2 binds to the branch point. A preformed U4-U5-U6 complex then joins the assembly to form the complete spliceosome. Extensive interactions between U6 and U2 displace U1 and U4. Then, in the first transesterification step, the branch-site adenosine attacks the 5′ splice site, making a lariat intermediate. U5 holds the two exons in close proximity, and the second transesterification takes place, with the 5′ splice-site hydroxyl group attacking the 3′ splice site. These reactions result in the mature spliced mRNA and a lariat form of the intron bound by U2, U5, and U6.
The nucleus contains many types of small RNA molecules (Table 37.2). One particular class of such RNAs, referred to as snRNAs (small nuclear RNAs) and designated U1, U2, U4, U5, and U6, is essential for splicing mRNA precursors. These RNA molecules and their associated proteins are key components of the splicesome. The RNA-protein complexes are termed snRNPs (small nuclear ribo-nucleoprotein particles); investigators often speak of them as “snurps.” In mammalian cells, the first step in the splicing is the recognition of the 5′ splice site by the U1 snRNP (Figure 38.7). In fact, the RNA component of U1 snRNP contains a six-nucleotide sequence that base-pairs to the 5′ splice site of the pre-mRNA. This binding initiates spliceosome assembly on the pre-mRNA molecule. U2 snRNP then binds the branch site in the intron. A preassembled U4-U5-U6 tri-snRNP joins this complex of U1, U2, and the mRNA precursor to form the spliceosome.
The splicing process continues when U5 interacts with exon sequences in the 5′ splice site and subsequently with the 3′ exon. Next, U6 disengages from U4 and interacts with U2 and with the 5′ end of the intron, displacing U1 from the spliceosome. The U2 and U6 snRNAs form the catalytic center of the spliceosome (Figure 38.8). U4 serves as an inhibitor that masks U6 until the specific splice sites are aligned. These rearrangements bring the ends of the intron together and result in a transesterificationreaction. The 5′ exon is cleaved, and the remaining pre-mRNA molecule forms a lariat intermediate in which the first nucleotide of the intron (G) is joined to an A in the branch region in an unusual 5′–2′ phosphodiester linkage.
Figure 38.8 The splicing catalytic center. The catalytic center of the spliceosome is formed by U2 snRNA (red) and U6 snRNA (green), which are base-paired. U2 is also base-paired to the branch site of the mRNA precursor.
DID YOU KNOW?
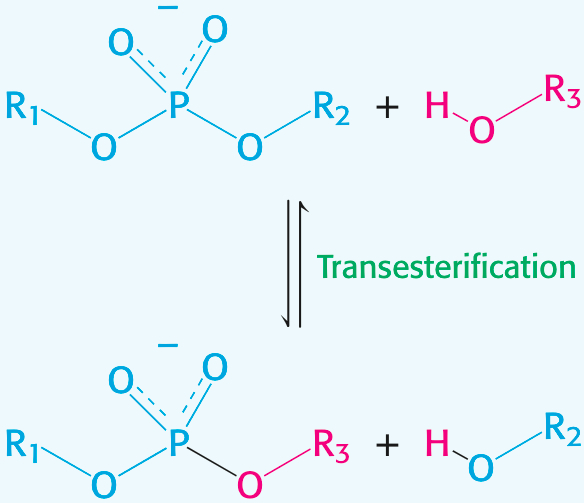
Transesterification is the reaction of an alcohol with an ester to form a different alcohol and a different ester.
Page 696
Further rearrangements of RNA in the spliceosome facilitate the second transesterification. In these rearrangements, U5 holds the free 5′ exon and the 3′ exon close together to facilitate the second transesterification, generating the spliced product. U2, U5, and U6 bound to the excised lariat intron are released to complete the splicing reaction.
?
QUICK QUIZ
Describe the roles of the various snRNPs in the splicing process.
U1 snRNP binds to the 5′ splice site, initiating spliceosome formation. U2 snRNP then binds at the branch site. The tri-snRNP U4-U5-U6 then joins, completing spliceosome formation. U5 interacts with the 5′ splice site and the 3′ exon. U6 disengages from U4 and pairs with U2. These rearrangements result in the cleavage of the 5′ exon and the formation of the lariat. U5 facilitates the alignment of the 5′ exon to attack the 3′ splice site, which forms the final product.
Many of the steps in the splicing process require ATP hydrolysis. How is the free energy associated with ATP hydrolysis used to power splicing? To achieve the well-ordered rearrangements necessary for splicing, ATP-powered RNA helicases must unwind RNA helices and allow alternative base-pairing arrangements to form. Thus, two features of the splicing process are noteworthy. First, RNA molecules play key roles in directing the alignment of splice sites and in carrying out catalysis. Second, ATP-powered helicases unwind RNA duplex intermediates that facilitate catalysis and induce the release of snRNPs from the mRNA.
CLINICAL INSIGHT
Mutations that Affect Pre-mRNA Splicing Cause Disease
Mutations in either the pre-mRNA (cis-acting) or the splicing factors (trans-acting) can cause defective pre-mRNA splicing. Mutations in the pre-mRNA cause some forms of thalassemia, a group of hereditary anemias characterized by the defective synthesis of hemoglobin. The gene for the hemoglobin β chain consists of three exons and two introns. Cis-acting mutations that cause aberrant splicing can arise at the 5′ or 3′ splice site in either of the two introns or in its exons. The mutations usually result in an incorrectly spliced pre-mRNA that, because of a premature termination signal, cannot encode a full-length protein. The defective mRNA is normally degraded rather than translated (Figure 38.9). Mutations affecting splicing have been estimated to cause at least 15% of all genetic diseases.
Figure 38.9 A splicing mutation that causes thalassemia. An A−to−G mutation within the first intron of the gene for the human hemoglobin β chain creates a new 5′ splice site (GU). The abnormal mature mRNA now has a premature Stop codon and is degraded.
Disease-causing mutations may also appear in protein splicing factors. Retinitis pigmentosa is a disease of acquired blindness, first described in 1857, with an incidence of 1/3500 individuals. About 5% of the autosomal dominant form of retinitis pigmentosa is likely due to mutations in a pre-mRNA splicing factor that is a component of the U4-U5-U6 tri-snRNP. How a mutation in a splicing factor that is present in all cells causes disease only in the retina is unclear; nevertheless, retinitis pigmentosa is a good example of how mutations that disrupt spliceosome function can cause disease.
Page 697
CLINICAL INSIGHT
Most Human Pre-mRNAs Can Be Spliced in Alternative Ways to Yield Different Proteins
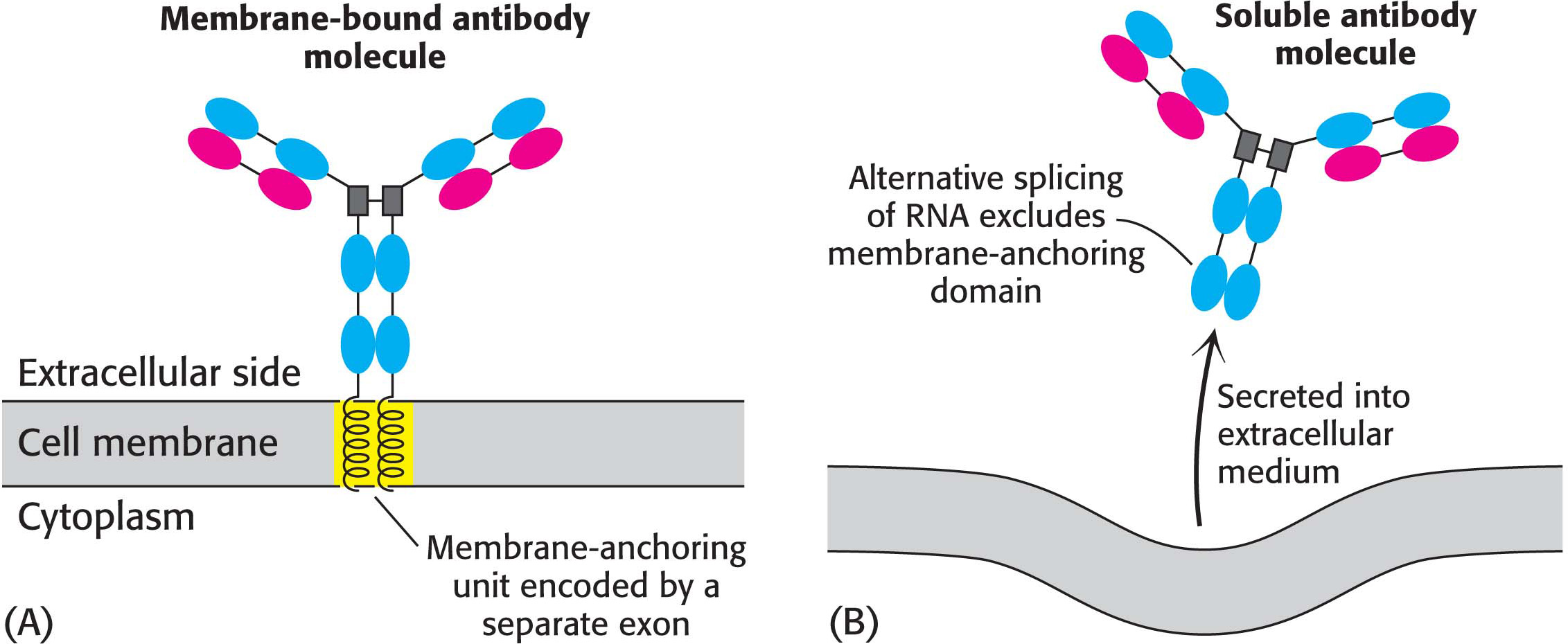
Alternative splicing is a widespread mechanism for generating protein diversity. Current estimates are that more than 70% of human genes that encode proteins are alternatively spliced. Different combinations of exons in the same gene may be spliced into a mature RNA, producing distinct forms of a protein for specific tissues, developmental stages, or signaling pathways. For example, a precursor of an antibody-producing cell forms an antibody that is anchored in the cell’s plasma membrane (Figure 38.10). The attached antibody recognizes a specific foreign antigen, which leads to cell differentiation and proliferation. The activated antibody-producing cells then splice their nascent RNA transcript in an alternative manner to form soluble antibody molecules that are secreted rather than retained on the cell surface. We see here a clear-cut example of a benefit conferred by the complex arrangement of introns and exons in higher organisms.
Figure 38.10 Alternative splicing. Alternative splicing generates mRNAs that are templates for different forms of a protein: (A) a membrane-bound antibody on the surface of a lymphocyte and (B) its soluble counterpart, exported from the cell. The membrane-bound antibody is anchored to the plasma membrane by a helical segment (highlighted in yellow) that is encoded by its own exon.
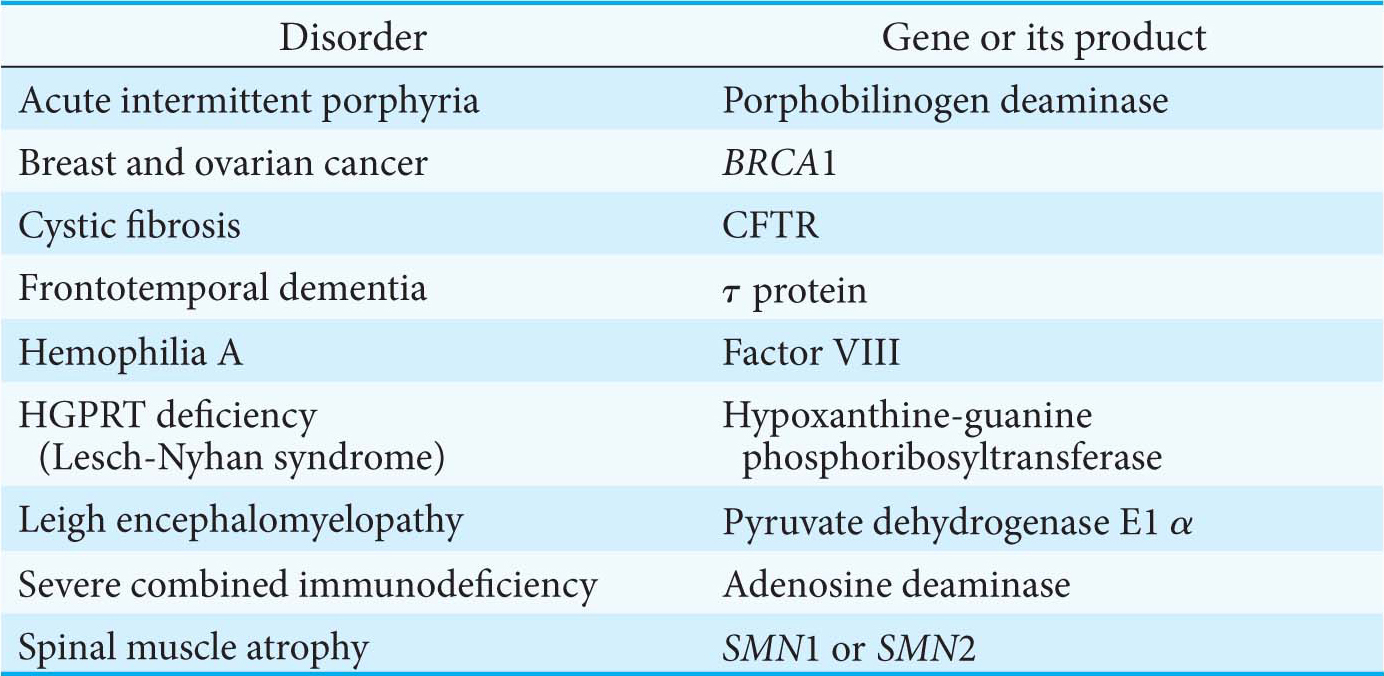
What controls which splicing sites are selected? The selection is determined by the binding of trans-acting splicing factors to cis-acting sequences in the pre-mRNA. Most alternative splicing leads to changes in the coding sequence, resulting in proteins with different functions. To better understand the power of alternative splicing, let’s consider a gene with five positions at which alternative splicing can take place. With the assumption that these alternative splicing pathways can be regulated independently, a total of 25 = 32 different mRNAs can be generated. Alternative splicing provides a powerful mechanism for expanding the versatility of genomic sequences through combinatorial control. Several human diseases that can be attributed to defects in alternative splicing are listed in Table 38.1.
Page 698
Table 38.1 Selected human diseases attributed to defects in alternative splicing
The Transcription and Processing of mRNA Are Coupled
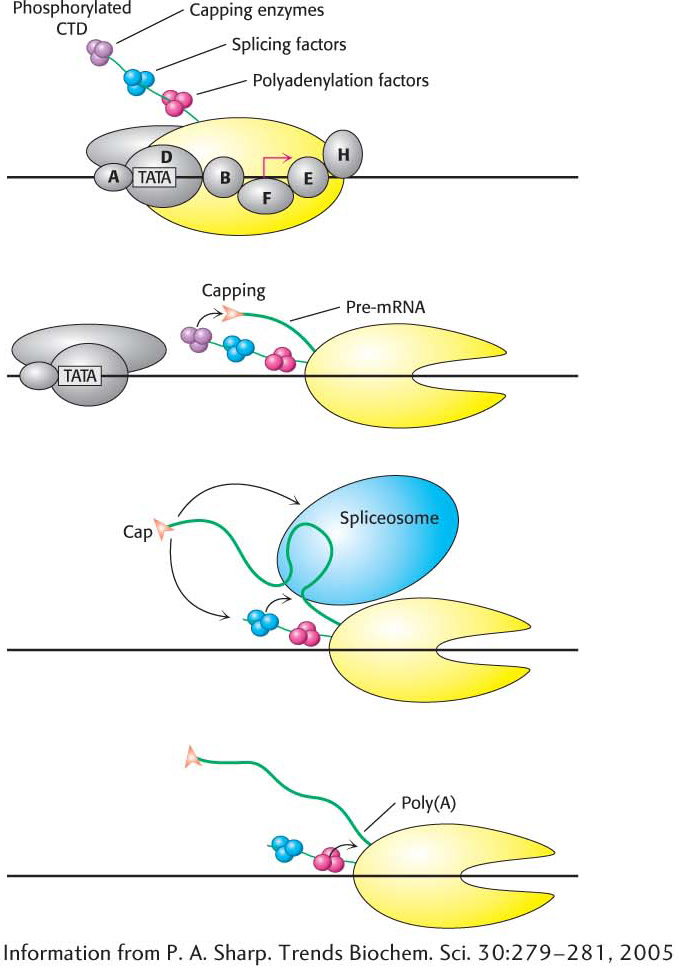
Figure 38.11 The CTD: Coupling transcription to pre-mRNA processing. The transcription factor TFIIH phosphorylates the carboxyl-terminal domain (CTD) of RNA polymerase II, signaling the transition from transcription initiation to elongation. The phosphorylated CTD binds factors required for pre-mRNA capping, splicing, and polyadenylation. These proteins are brought in close proximity to their sites of action on the nascent pre-mRNA as it is transcribed in the course of elongation.
Although the transcription and processing of mRNAs have been described herein as separate events in gene expression, experimental evidence suggests that the two steps are coordinated by the carboxyl-terminal domain of RNA polymerase II. We have seen that the CTD consists of a unique repeated seven-amino-acid sequence, YSPTSPS. Either the second serine, the fifth serine, or both may be phosphorylated in the various repeats. The phosphorylation state of the CTD is controlled by a number of kinases and phosphatases and leads the CTD to bind many of the proteins having roles in RNA transcription and processing. The CTD contributes to efficient transcription by recruiting these proteins to the pre-mRNA (Figure 38.11), including
capping enzymes, which methylate the 5′ guanine nucleotide base on the pre-mRNA immediately after transcription begins;
components of the splicing machinery, which initiate the excision of each intron as it is synthesized; and
an endonuclease that cleaves the transcript at the poly(A) addition site, creating a free 3′-OH group that is the target for 3′ adenylation.
These events take place sequentially, directed by the phosphorylation state of the CTD.
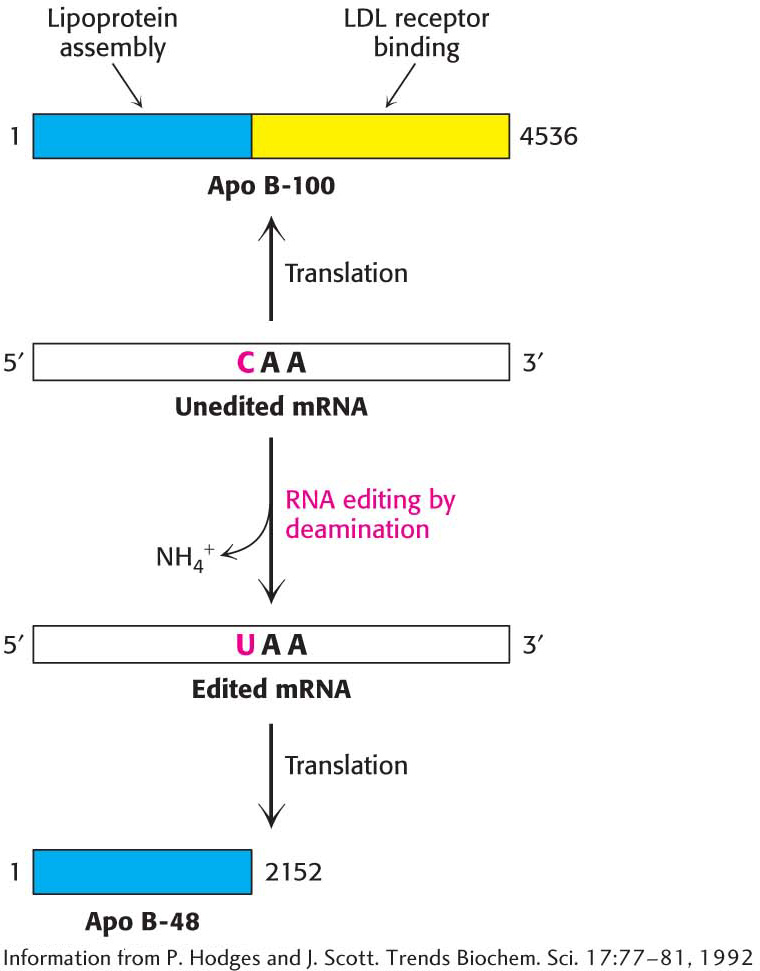
Figure 38.12 RNA editing. Enzyme-catalyzed deamination of a specific cytidine residue in the mRNA for apolipoprotein B−100 changes a codon for glutamine (CAA) to a Stop codon (UAA). Apolipoprotein B−48, a truncated version of the protein lacking the LDL receptor-binding domain, is generated by this posttranscriptional change in the mRNA sequence.
BIOLOGICAL INSIGHT
RNA Editing Changes the Proteins Encoded by mRNA
Alternative splicing is not the only means of generating diverse proteins from one gene. Remarkably, the amino-acid-sequence information encoded by some mRNAs is altered after transcription. RNA editing is the term for a change in the nucleotide sequence of RNA after transcription by processes other than RNA splicing. RNA editing is prominent in the synthesis of apolipoproteins (Table 29.1). Apolipoprotein B (apo B) plays a role in the transport of triacylglycerols and cholesterol as a component of lipoprotein particles. Apo B exists in two forms, a 512-kDa apo B-100 and a 240-kDa apo B-48. The larger form, synthesized by the liver, participates in the transport of lipids synthesized in the cell. The smaller form, synthesized by the small intestine, carries dietary fat in the form of chylomicrons. Apo B-48 contains the 2152 N-terminal residues of the 4536-residue apo B-100. What is the relation between these two forms of apo B? Experiments revealed that a totally unexpected mechanism for generating diversity is at work: the changing of the nucleotide sequence of mRNA after its synthesis (Figure 38.12). A specific cytidine residue of mRNA is deaminated to uridine, which changes the codon at residue 2153 from CAA (Gln) to UAA (stop). The deaminase that catalyzes this reaction is present in the small intestine, but not in the liver, and is expressed only at certain developmental stages.
Page 699
RNA editing is likely much more common than was formerly thought. Antarctic and Arctic octopuses provide a fascinating example of RNA editing. In very cold temperatures, nerve impulses in these creatures would slow because the K+ channels required for nerve impulse transmission cannot open and close rapidly enough. To prevent this situation, RNA editing is used to generate channels that function rapidly enough to maintain nerve functions in the extreme cold. Thus, temperature adaptation in octopus neurons occurs by RNA editing.


 CLINICAL INSIGHT
CLINICAL INSIGHT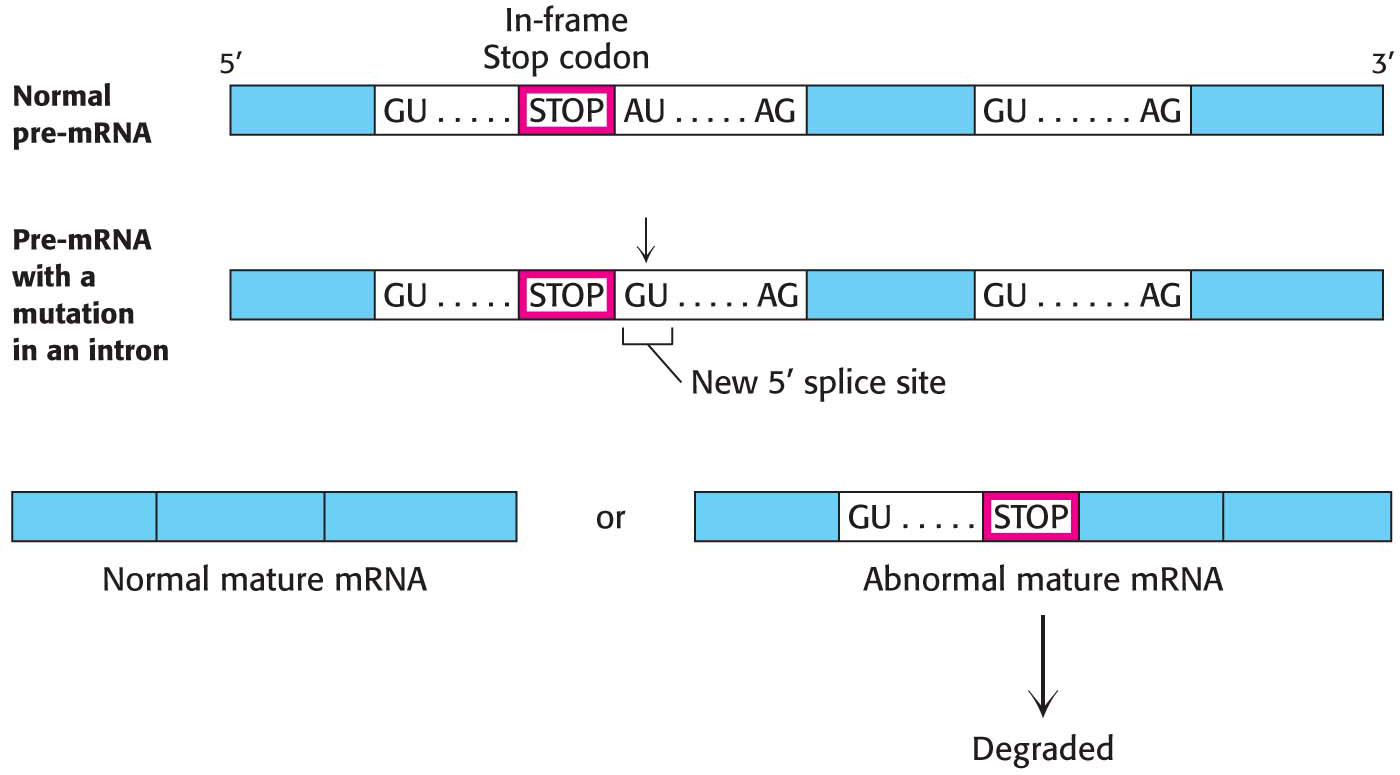
 BIOLOGICAL INSIGHT
BIOLOGICAL INSIGHT