4.1Primary Structure: Amino Acids Are Linked by Peptide Bonds to Form Polypeptide Chains
✓ 2 Compare and contrast the different levels of protein structure and how they relate to one another.
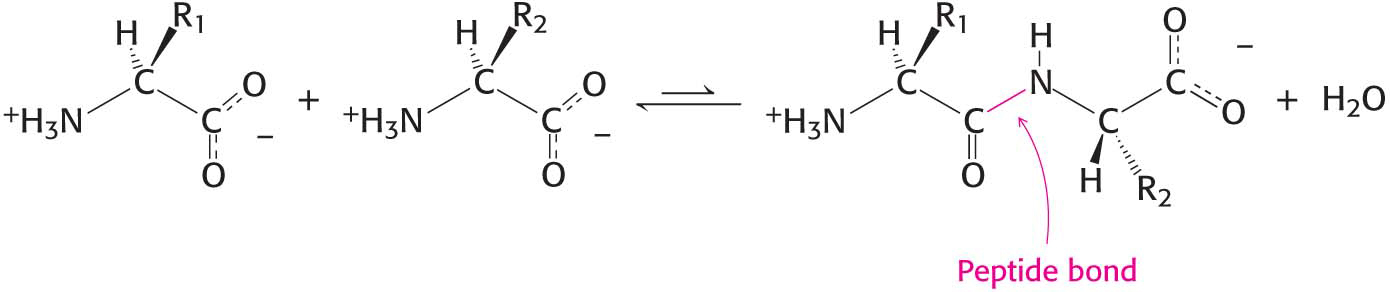
Proteins are complicated three-dimensional molecules, but their three-dimensional structure depends simply on their primary structure—the linear polymers formed by linking the α-carboxyl group of one amino acid to the α-amino group of another amino acid. The linkage joining amino acids in a protein is called a peptide bond (also called an amide bond). The formation of a dipeptide from two amino acids is accompanied by the loss of a water molecule (Figure 4.1). The equilibrium of this reaction lies on the side of hydrolysis rather than synthesis under most conditions. Hence, the biosynthesis of peptide bonds requires an input of free energy. Nonetheless, peptide bonds are quite stable kinetically because the rate of hydrolysis is extremely slow; the lifetime of a peptide bond in aqueous solution in the absence of a catalyst approaches 1000 years.
Figure 4.1 Peptide-bond formation. The linking of two amino acids is accompanied by the loss of a molecule of water.
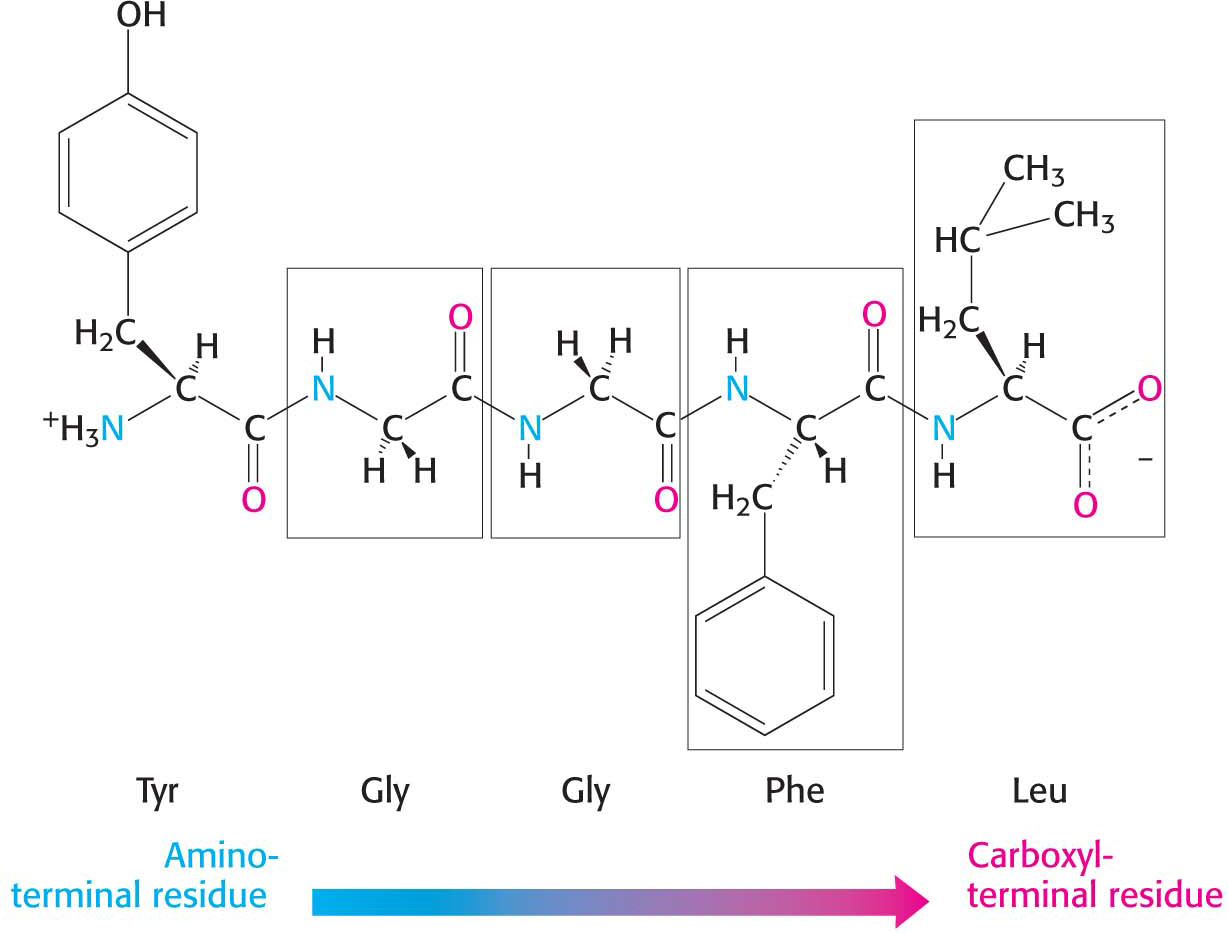
A series of amino acids joined by peptide bonds form a polypeptide chain, and each amino acid unit in a polypeptide is called a residue. A polypeptide chain has directionality, sometimes called polarity, because its ends are different: an α-amino group is at one end, and an α-carboxyl group is at the other. By convention, the amino end is taken to be the beginning of a polypeptide chain, and so the sequence of amino acids in a polypeptide chain is written starting with the amino-terminal residue. Thus, in the pentapeptide Tyr-Gly-Gly-Phe-Leu (YGGFL), tyrosine is the amino-terminal (N-terminal) residue and leucine is the carboxyl-terminal (C-terminal) residue (Figure 4.2). The reverse sequence, Leu-Phe-Gly-Gly-Tyr (LFGGY), is a different pentapeptide, with different chemical properties. Note that the two peptides in question have the same amino acid composition but differ in primary structure.
Figure 4.2 Amino acid sequences have direction. This illustration of the pentapeptide Tyr-Gly-Gly-Phe-Leu (YGGFL) shows the sequence from the amino terminus to the carboxyl terminus. This pentapeptide, Leu-enkephalin, is an opioid peptide that modulates the perception of pain.
Page 49
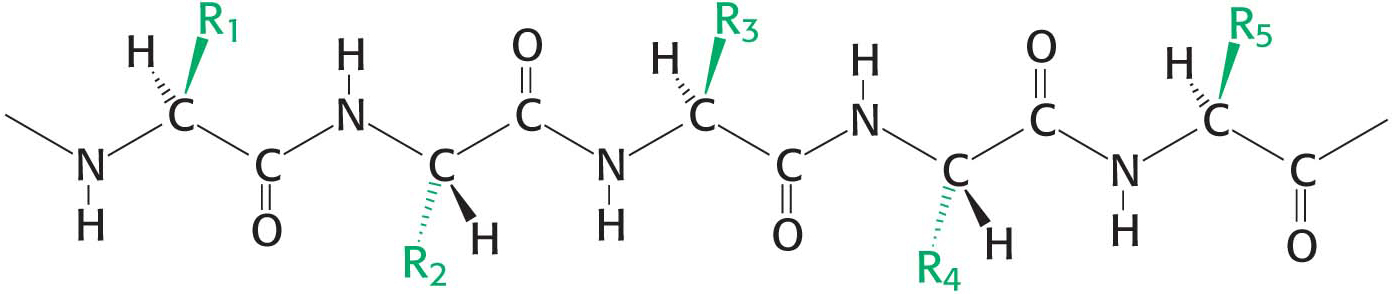
A polypeptide chain consists of a regularly repeating part, called the main chain or backbone, and a variable part, comprising the distinctive side chains (Figure 4.3). The polypeptide backbone is rich in hydrogen-bonding potential. Each residue contains a carbonyl group (C=O), which is a good hydrogen-bond acceptor, and, with the exception of proline, an amino group (N–H), which is a good hydrogen-bond donor. These groups interact with each other and with the functional groups of side chains to stabilize particular structures.
Figure 4.3 Components of a polypeptide chain. A polypeptide chain consists of a constant backbone (shown in black) and variable side chains (shown in green).
Most natural polypeptide chains contain between 50 and 2000 amino acid residues and are commonly referred to as proteins. The largest protein known is the muscle protein titin, which serves as a scaffold for the assembly of the contractile proteins of muscle. Titin consists of almost 27,000 amino acids. Peptides made of small numbers of amino acids are called oligopeptides or simply peptides. The mean molecular weight of an amino acid residue is about 110 g mol−1, and so the molecular weights of most proteins are between 5500 and 22,000 g mol−1. We can also refer to the mass of a protein in units of daltons; a dalton is a unit of mass very nearly equal to that of a hydrogen atom. A protein with a molecular weight of 50,000 g mol−1 has a mass of 50,000 daltons, or 50 kDa (kilodaltons).
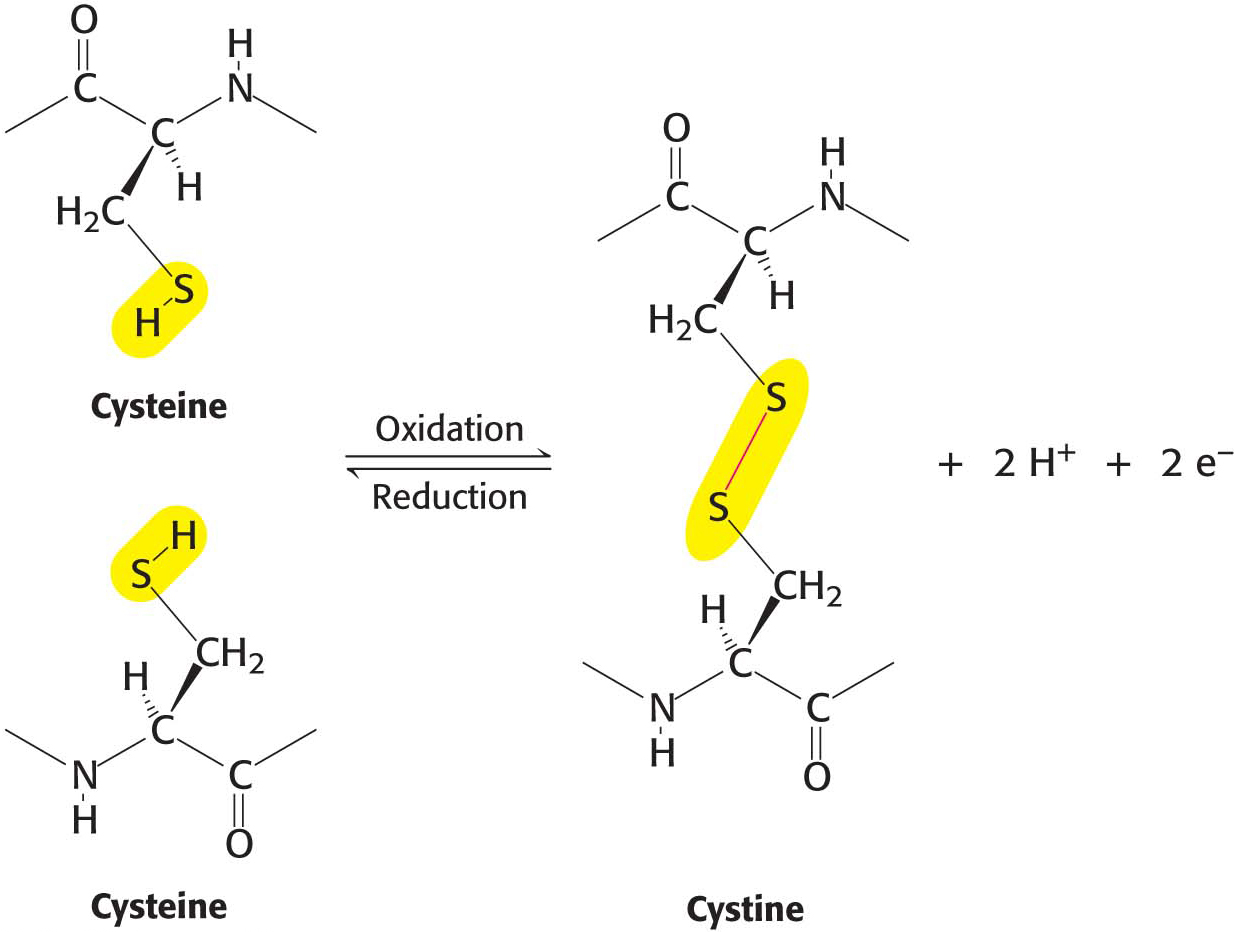
In some proteins, the linear polypeptide chain is covalently cross-linked. The most common cross-links are disulfide bonds, formed by the oxidation of a pair of cysteine residues (Figure 4.4). The resulting unit of two linked cysteines is called cystine. Disulfide bonds can form between cysteine residues in the same polypeptide chain, or they can link two separate chains together. Rarely, nondisulfide cross-links derived from other side chains are present in proteins.
Figure 4.4 Cross-links. The formation of a disulfide bond between two cysteine residues is an oxidation reaction.
Proteins Have Unique Amino Acid Sequences Specified by Genes
In 1953, Frederick Sanger determined the amino acid sequence of insulin, a protein hormone (Figure 4.5). This work is a landmark in biochemistry because it showed for the first time that a protein has a precisely defined amino acid sequence consisting only of l amino acids linked by peptide bonds. Sanger’s accomplishment stimulated other scientists to carry out sequence studies of a wide variety of proteins. The complete amino acid sequences of millions of proteins are now known.
Page 50
Figure 4.5 Amino acid sequence of bovine insulin.
?
QUICK QUIZ
(a) What is the amino terminus of the tripeptide Gly-Ala-Asp? (b) What is the approximate molecular weight of a protein composed of 300 amino acids? (c) Approximately how many amino acids are required to form a protein with a molecular weight of 110,000?
(a) Glycine is the amino terminus. (b) The average molecular weight of amino acids is 110. Therefore, a protein consisting of 300 amino acids has a molecular weight of approximately 33,000. (c) A protein with a molecular weight of 110,000 consists of approximately 1000 amino acids.
Knowing amino acid sequences is important for several reasons. First, amino acid sequences determine the three-dimensional structures of proteins. Second, knowledge of the sequence of a protein is usually essential to elucidating its function (e.g., the catalytic mechanism of an enzyme). Third, alterations in amino acid sequence can produce abnormal function and disease. Severe and sometimes fatal diseases, such as sickle-cell anemia (Chapter 9) and cystic fibrosis, can result from a change in a single amino acid within a protein. Fourth, the sequence of a protein reveals much about its evolutionary history. Proteins resemble one another in amino acid sequence only if they have a common ancestor. Consequently, molecular events in evolution can be traced from amino acid sequences; molecular paleontology is a flourishing area of research.
Polypeptide Chains Are Flexible Yet Conformationally Restricted
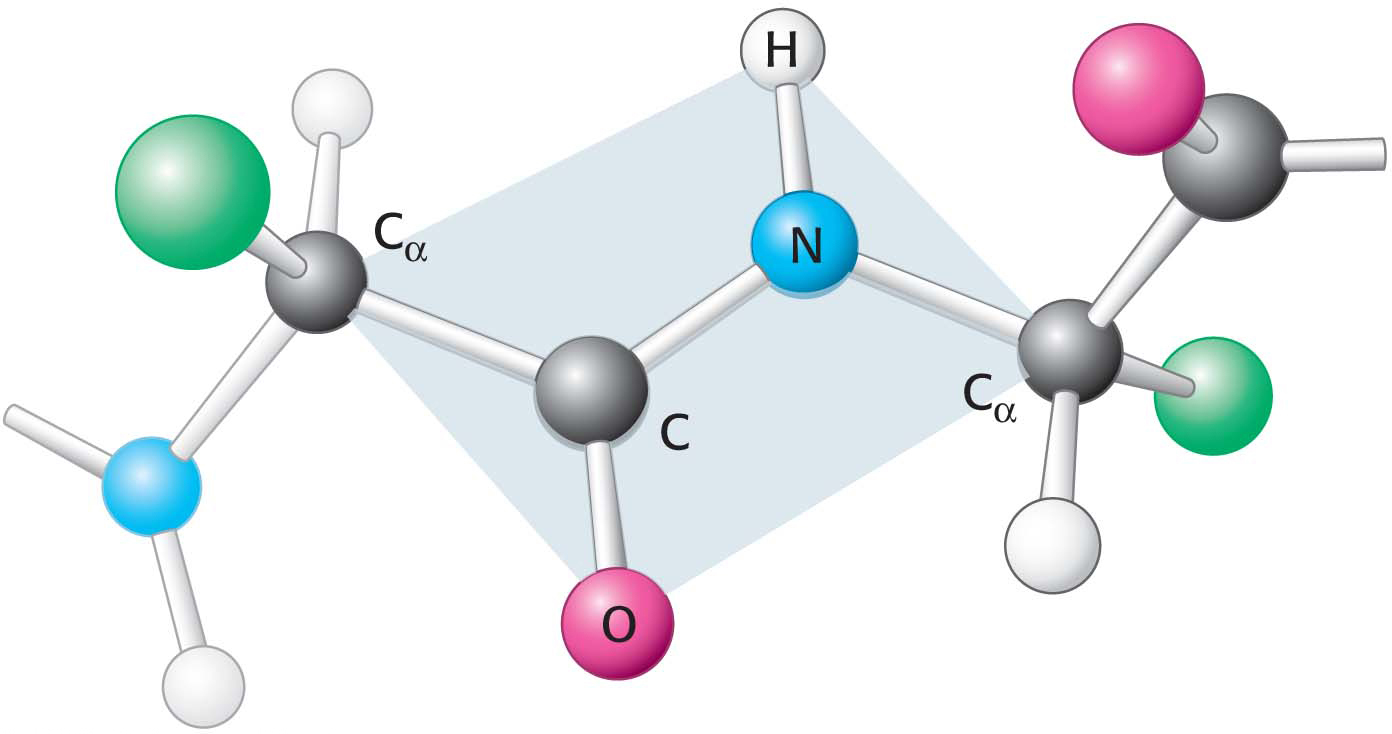
Figure 4.6 Peptide bonds are planar. In a pair of linked amino acids, six atoms (Cα, C, O, N, H, and Cα) lie in a plane. Side chains are shown as green balls.
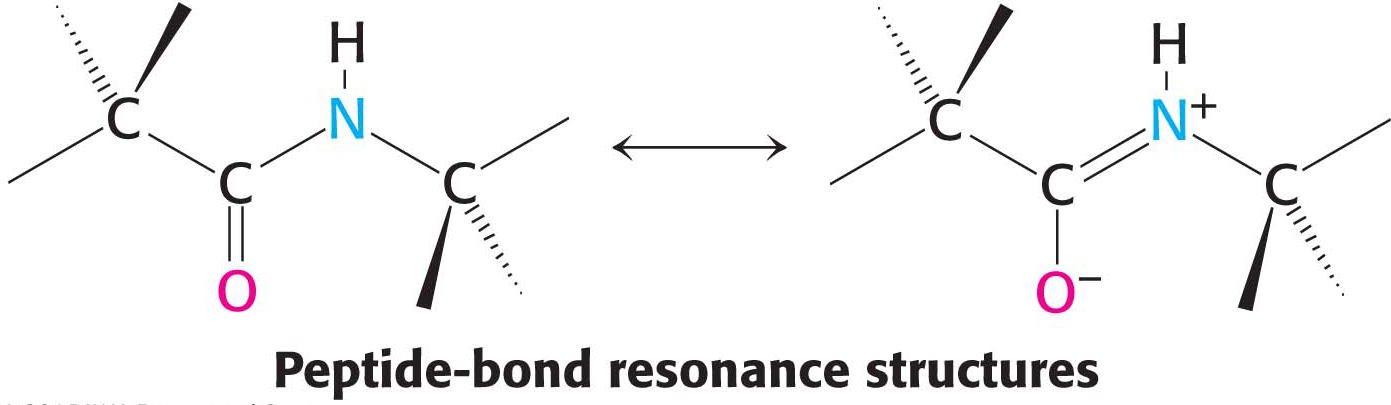
Primary structure determines the three-dimensional structure of a protein, and the three-dimensional structure determines the protein’s function. What are the rules governing the relation between an amino acid sequence and the three-dimensional structure of a protein? This question is very difficult to answer, but we know that certain characteristics of the peptide bond itself are important. First, the peptide bond is essentially planar (Figure 4.6). Thus, for a pair of amino acids linked by a peptide bond, six atoms lie in the same plane: the α-carbon atom and CO group of the first amino acid and the NH group and α-carbon atom of the second amino acid. Second, the peptide bond has considerable double-bond character owing to resonance structures: the electrons resonate between a pure single bond and a pure double bond.
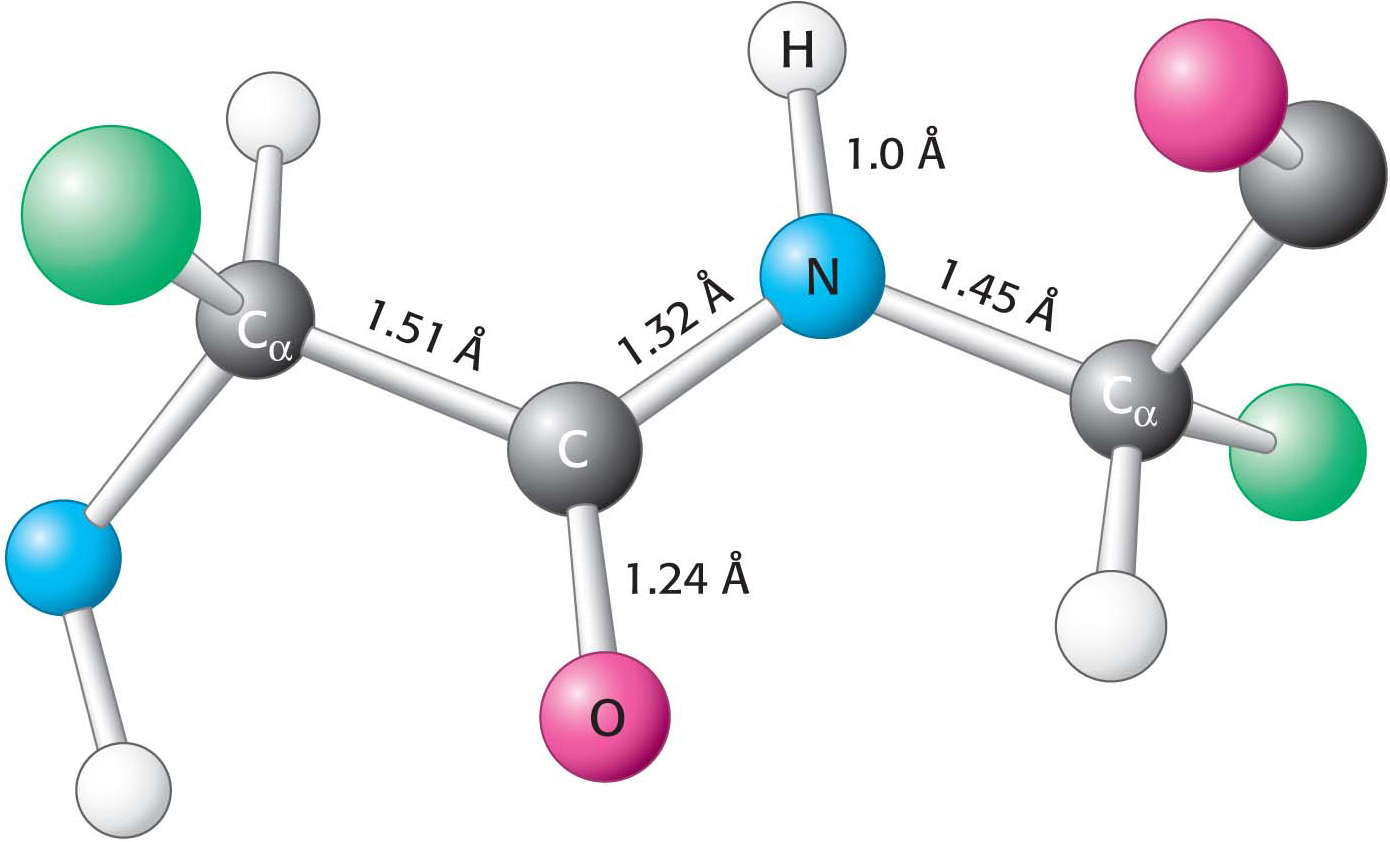
Figure 4.7 Typical bond lengths within a peptide unit. The peptide unit is shown in the trans configuration.
This partial double-bond character prevents rotation about this bond and thus constrains the conformation of the peptide backbone. The double-bond character is also expressed in the length of the bond between the CO and the NH groups. The C–N distance in a peptide bond is typically 1.32 Å (Figure 4.7), which is between the values expected for a C–N single bond (1.45 Å) and a C=N double bond (1.27 Å). Finally, the peptide bond is uncharged, allowing polymers of amino acids linked by peptide bonds to form tightly packed globular structures that would otherwise be inhibited by charge repulsion.
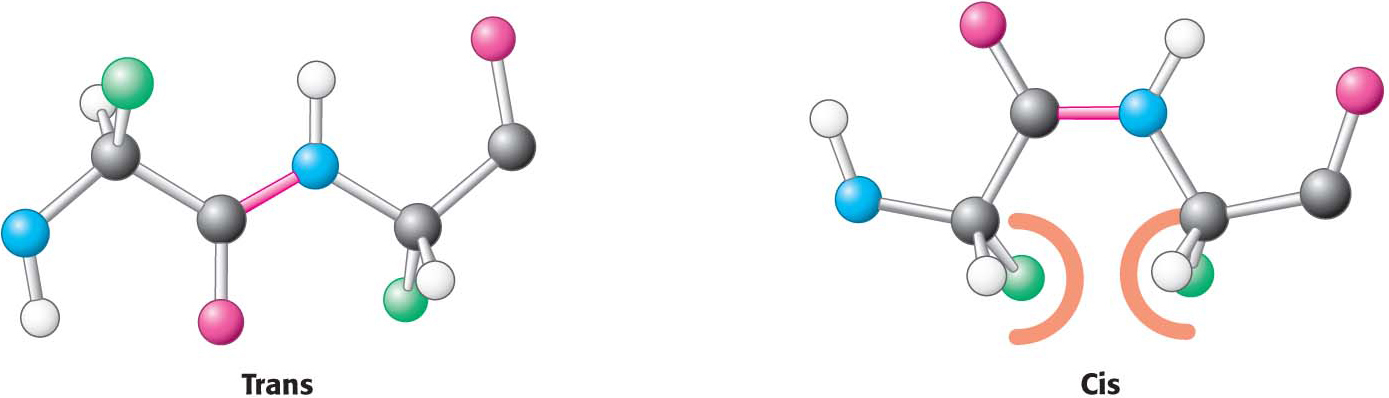
Figure 4.8 Trans and cis peptide bonds. The trans form is strongly favored because of steric clashes in the cis form.
Two configurations are possible for a planar peptide bond. In the trans configuration, the two α-carbon atoms are on opposite sides of the peptide bond. In the cis configuration, these groups are on the same side of the peptide bond. Almost all peptide bonds in proteins are trans. This preference for trans over cis can be explained by the fact that there are steric clashes between R groups in the cis configuration but not in the trans configuration (Figure 4.8).
Page 51
DID YOU KNOW?
Torsion angle, which is a measure of rotation about a bond, is usually taken to lie between –180 and +180 degrees. torsion angles are sometimes called dihedral angles.
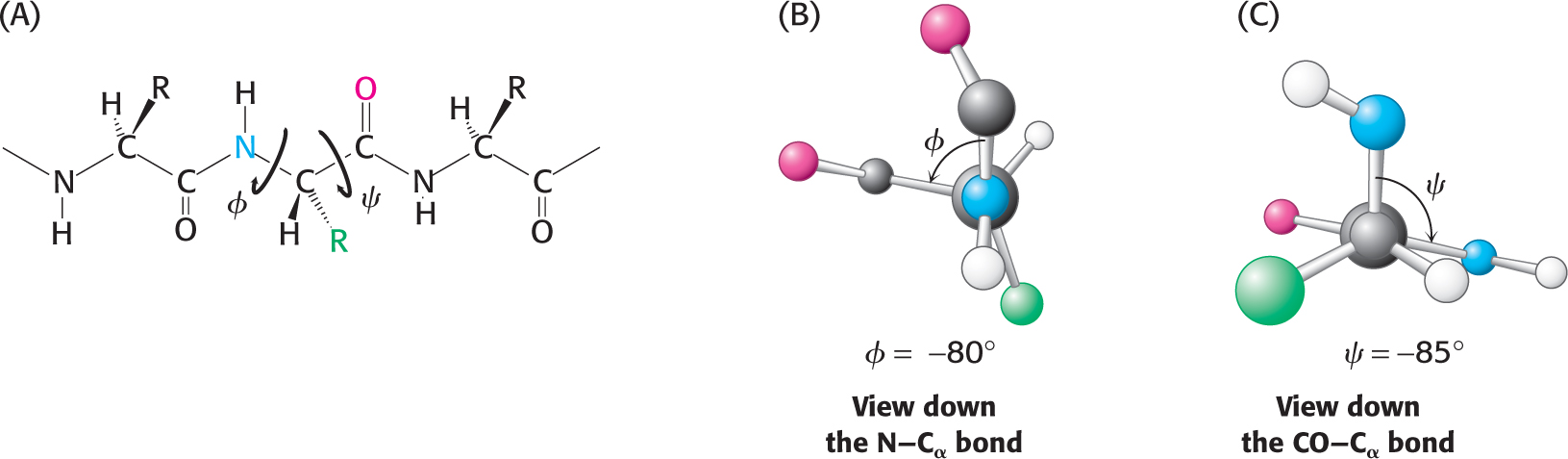
In contrast with the peptide bond, the bonds between the amino group and the α-carbon atom and between the α-carbon atom and the carbonyl group are pure single bonds. The two adjacent rigid peptide units may rotate about these bonds, taking on various orientations. This freedom of rotation about two bonds of each amino acid allows proteins to fold in many different ways. The rotations about these bonds can be specified by torsion angles (Figure 4.9). The angle of rotation about the bond between the nitrogen atom and the α-carbon atom is called phi (φ). The angle of rotation about the bond between the α-carbon atom and the carbonyl carbon atom is called psi (ψ). A clockwise rotation about either bond as viewed toward the α-carbon atom corresponds to a positive value. The φ and ψ angles determine the path of the polypeptide chain.
Figure 4.9 Rotation about bonds in a polypeptide. The structure of each amino acid in a polypeptide can be adjusted by rotation about two single bonds. (A) Phi (ϕ) is the angle of rotation about the bond between the nitrogen and the α-carbon atoms, whereas psi (c) is the angle of rotation about the bond between the carbonyl carbon and the α-carbon atoms. (B) A view down the bond between the nitrogen and the α-carbon atoms. The angle ϕ is measured as the rotation of the carbonyl carbon attached to the α-carbon atom: positive if to the right, negative if to the left. (C) The angle ϕ is measured by the rotation of the amino group as viewed down the bond from the carbonyl carbon to the α-carbon atom: positive if to the right, negative if to the left. Note that the view shown is the reverse of how the rotation is measured and consequently the angle has a negative value.
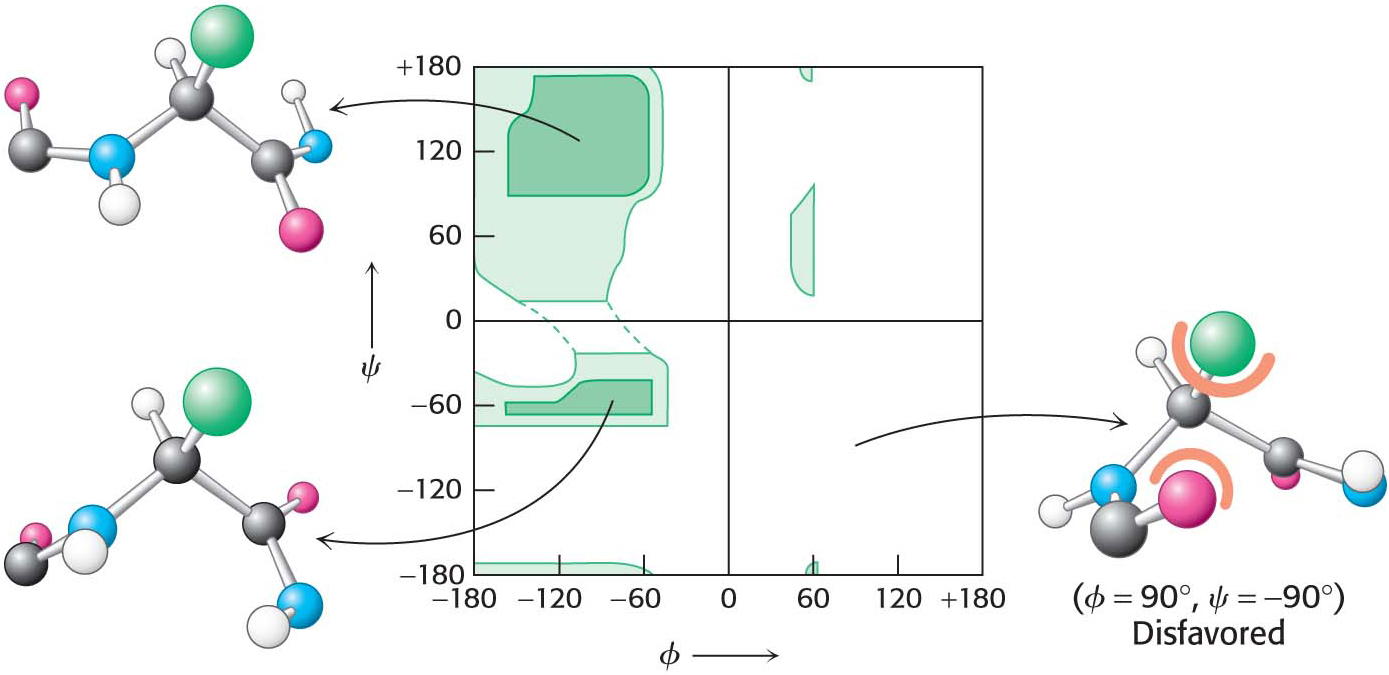
Are all combinations of ϕ and ψ possible? The Indian biophysicist Gopalasamudram Ramachandran recognized that many combinations are not found in nature because of steric clashes between atoms. He generated a two-dimensional plot, now called a Ramachandran plot, of the ϕ and ψ values of possible conformations (Figure 4.10). Three-quarters of the possible (ϕ, ψ) combinations are excluded simply by local steric clashes. Steric exclusion, the fact that two atoms cannot be in the same place at the same time, restricts the number of possible peptide conformations and is thus a powerful organizing principle.
Figure 4.10 A Ramachandran diagram showing the values of ϕ and ψ. Not all ϕ and ψ values are possible without collisions between atoms. The most favorable regions are shown in dark green on the graph; borderline regions are shown in light green. The structure on the right is disfavored because of steric clashes.