Chapter 2. EVOLUTION III—OVERVIEW
Learning Objectives
General Purpose
Conceptual
- Gain experience presenting the results and conclusions of an experiment to other individuals.
- Gain experience interpreting data and formulating conclusions of an experiment.
Now that you have completed the data collection for your experiment, you need to analyze your data. What does it mean for your data to be accurate or precise? Although the words accuracy and precision are often used as though they are synonymous, they are not. Accuracy refers to the closeness of a measured or calculated value to its “true” value. An experiment will have a single, exact outcome. If your recorded value for the experiment was near this value, it was very accurate. An accurate reading can be the result of good experimental technique or it could be the result of random chance. You could have measured the outcome incorrectly, but then also recorded the value wrong, with these two errors canceling each other out and therefore producing a very accurate result. Precision is the closeness of repeated measurements to one another. Precise measurements are not necessarily accurate, but in general a series of very precise measurements will also be very accurate because it is less likely for random events to occur in exactly the same way multiple times. This is partially the reason experiments are usually repeated many times. It allows the investigator to obtain a precise estimate of the “true” value.
It is rare for data to have such great precision that all of the values for a single type of treatment are exactly the same. This may simply be due to factors that either were not controlled or factors that could not be controlled. So if the values for the data vary (even just a small amount), which one is the “true” value? In a real investigation there is likely no way to know what value is the true value and there is no “right” answer. Instead, the experimental results have to be analyzed statistically. This will provide a method for exactly describing the numerical results. It will also provide a way to compare the results of different treatments to determine if the treatments have any meaningful effect on the reaction.
Another aspect of the post-experiment phase of the investigation is determining the best way to present the results so that conclusions can be reached in an easy and direct manner. The choices involved in the data presentation include:
- How the data should be presented (table, figure, both).
- Where tables are used, is it clearer to use multiple tables or combine information into a single table?
- Is a table that summarizes the results needed or helpful?
- Are graphs combining different treatments better for comparison than many separate graphs?
Using a spreadsheet program like Microsoft Excel can be a valuable tool for the organization and presentation of experimental results. These same programs can also be used for creating graphs of your results.
Use an Excel spreadsheet to organize your raw data from your experiment.
In Excel, columns are named as A, B, C… etc. and rows are named as 1, 2, 3… etc. We can use the same naming convention for referring to a particular cell. Take, for example, a hypothetical set of data for the enzyme reaction run at pH 3. For a set of three replicates of this experiment the data in an Excel spreadsheet might be arranged to look like this:
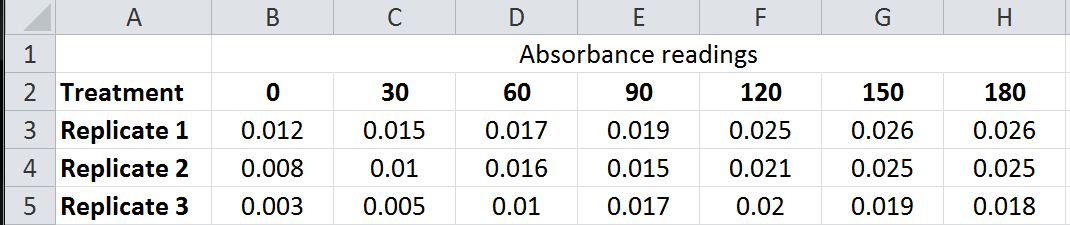
The absorbance value of Treatment 1-time 0 is in cell B3, which means “B” is the column and “3” is the row.
An alternative arrangement of the same data would be:
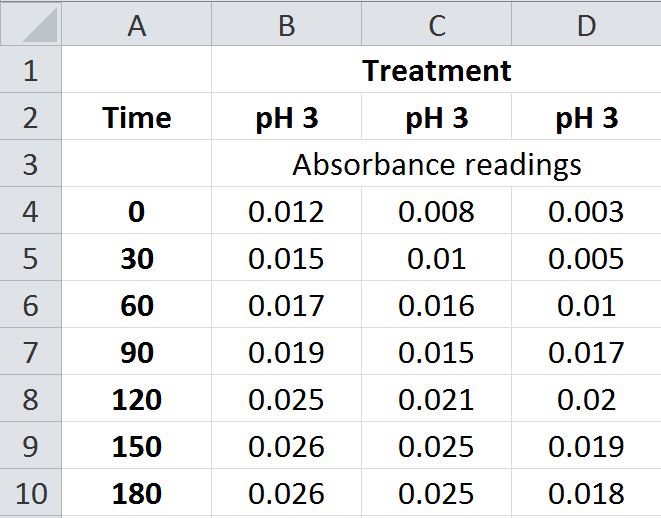
Either of these arrangements (or others) can present the data in a table that is easy to use. Once you have the data organized in a spreadsheet, then you can use this arrangement to easily and accurately make calculations based on the data using the formula function. For example, in the bean experiment from Evolution I, you calculated the frequency of the A alleles for each generation using a calculator (or by hand). There are two potential drawbacks to the method you used: it’s laborious and it can result in mistakes. The same information can be generated using the spreadsheet.
For a presentation of the data in the form of a graph from an experiment with three replicates, you could present three separate graphs:
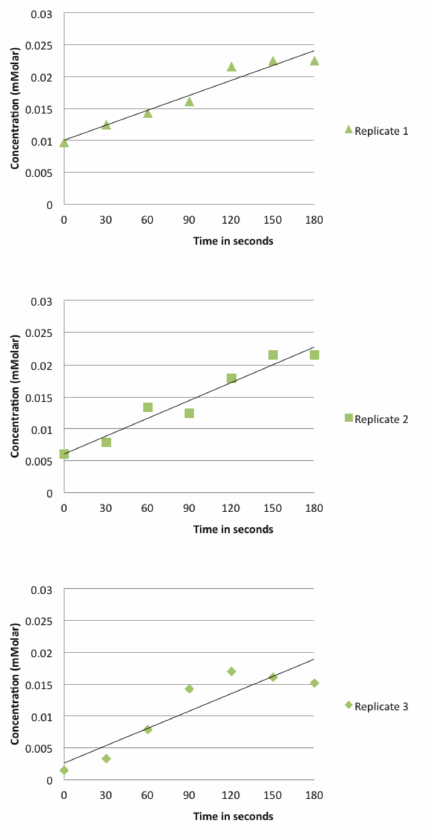
However, that type of presentation makes the direct comparison of the replicates more difficult. An alternative is to place all the replicates on the same graph:
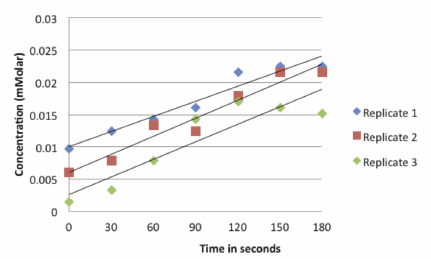
This creates an overly cluttered graph. It does not easily convey the information to the researcher or reader and lacks an unbiased means of interpreting the data for supporting or rejecting hypotheses. To get the best graphic representation of the results, a statistical analysis of the data is necessary. The starting point for almost all statistical analyses is to use descriptive statistics which simply describe the population of data points that you have collected.
Descriptive Statistics
Mean
One descriptor of a population of data is the mean. The mean is the average of a series of data points. The mean describes the center of the population of data. The mean does not consider the range or variation of the numbers. For example, the raw values of data set 1 are quite different than set 2; however, both of these sets have the same mean.
Standard Deviation (std dev or S.D.)
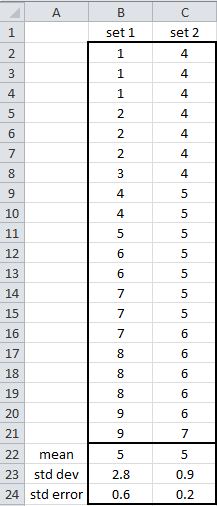
Another descriptor is the standard deviation. This describes how far away from the mean the data points spread. The formula for the standard deviation is:
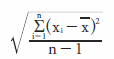
Since the standard deviation takes into account the variation of the data, it is a useful term for describing the data and also for comparing one data set to another. This value has the same units as the mean and is often represented as mean ± standard deviation. For set 1, it would be 5 ± 2.8.
In terms of the data, this means that about 2/3 (66.6%) of the sample values are expected to be between 2.2 to 7.8 (1 standard deviation away from mean in both directions) and 95% of the samples are expected to be between −0.4 to 10.6 (2 standard deviation). See bell curve.
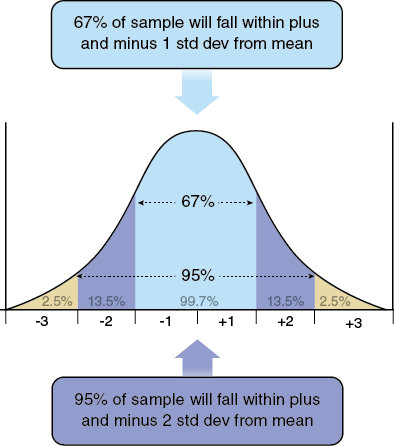
So basically, the standard deviation is an indication of how much variation occurs within the data. Therefore, as expected, the less the variation, such as in data set 2, the smaller the standard deviation.
Standard Error (std error or S.E.)
This is similar to standard deviation, except standard error allows some inference about how well your sample of data represents the total population of data values and the true population mean. The formula for std error is
Obviously, the larger your sample size, the more likely your standard error will be small. This makes sense because you will have a lot more confidence in your data if you did 20 replicates, instead of 2 replicates. This formula takes into account that level of confidence; thus, the standard error is more likely to be representative of the true mean of the population instead of just the mean of that particular set of data points. It is important to notice that the standard deviation is a better representative of the actual range of variation in all the possible data points, whereas standard error is an estimate of that variation.
Using the mean and one of the descriptors of data variation, two or more populations of data can be compared. This can also be useful for dealing with the replicates of experiments. Most spreadsheet programs, including Excel, include formulas for doing the calculations of descriptive statistics. Using the spreadsheet example from the Data Analysis and Presentation Pre-Lab, an average of the concentrations of the three replicates for a single time point is shown below:
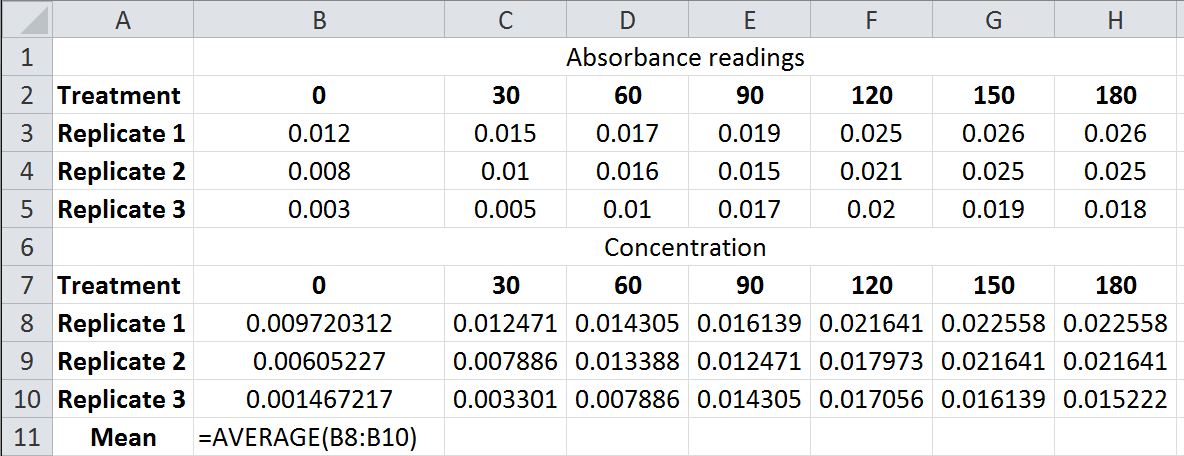
In cell B11 you can calculate the mean (or average) by clicking on the insert function feature (above the spreadsheet, shown highlighted). Type mean or average into the search feature of the function insert window and select the AVERAGE from the list and click OK. This will open a new window labeled Function Arguments. In the Number 1 space, choose the three cells that represent the three replicates. This will return the mean or average of the three replicates. Alternatively, you can simply type the formula into cell B11 using the format shown above.
Once a mean value for one set of replicates has been found you can right corner drag the formula from the B11 cell contents to the remaining cells in the spreadsheet mean row or use copy (Ctrl + c) and paste (Ctrl + v). The spreadsheet will now have mean values for each of the time points based on the three replicates.
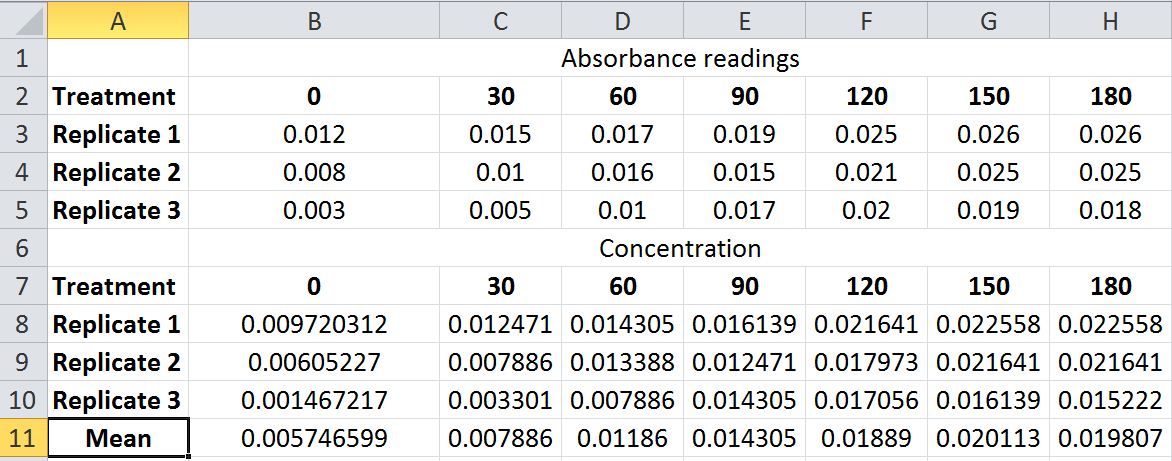
The same approach that was used to determine the mean values can be used for generating the standard deviation values. In cell B12 you can calculate the S.D. by clicking on the insert function feature (above the spreadsheet, shown highlighted). Type standard deviation into the search feature of the function insert window and select the STDEV from the list and click OK. This will open a new window labeled Function Arguments. In the Number 1 space, choose the three cells that represent the three replicates. This will return the standard deviation of the three replicates.
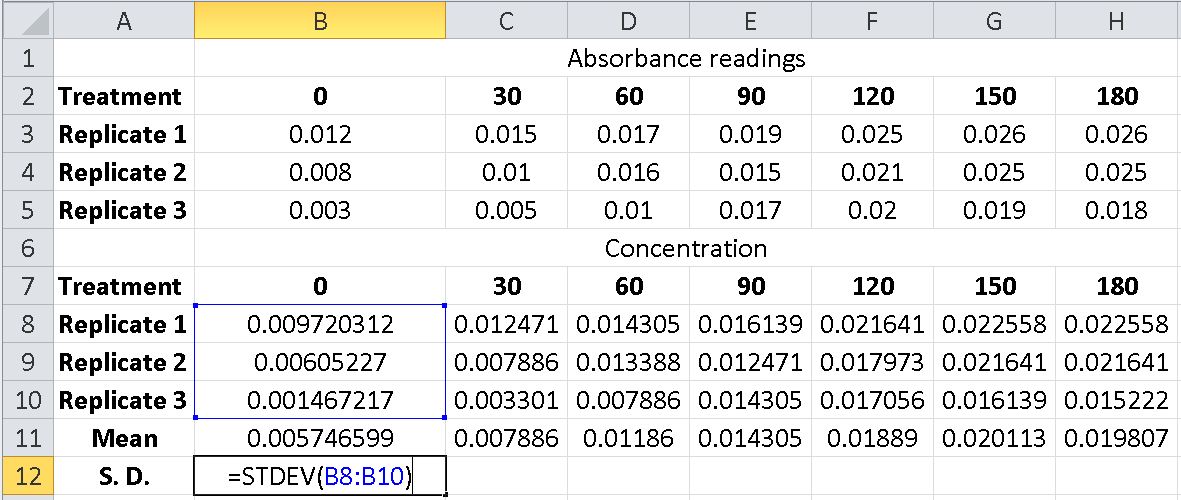
Alternatively, you can simply type the formula into cell B12 using the format shown above. Once a standard deviation for one set of replicates has been found you can right corner drag the formula from the B12 cell contents to the remaining cells in the spreadsheet S.D. row or use copy (Ctrl + c) and paste (Ctrl + v). The spreadsheet will now have S.D. values for each of the time points based on the three replicates.
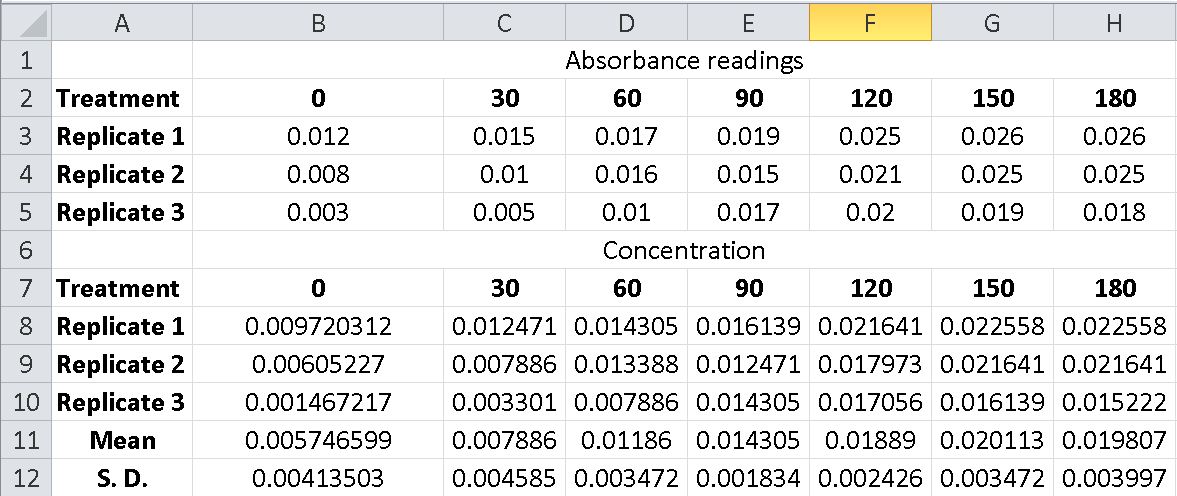
There is no function for Standard Error built into the Excel spreadsheet; however, you can find a square root function (=SQRT) to take the square root of the number of replicates and then divide the S.D. by that number. Alternatively, you can create your own function by entering the appropriate function descriptions in the cell where you want the standard error to show. For example, if in cell B13 you entered =(STDEV(B8:B10))/(SQRT(COUNT(B8:B10))) then the spreadsheet will calculate the S.E. for the three replicate data points for time 0.
We can now restructure the cluttered and less informative graph shown below.
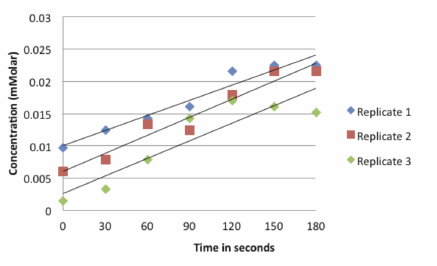
By using statistical analysis of the data and graphing the means of the three replicates, the image becomes easier for the reader or researcher to interpret.
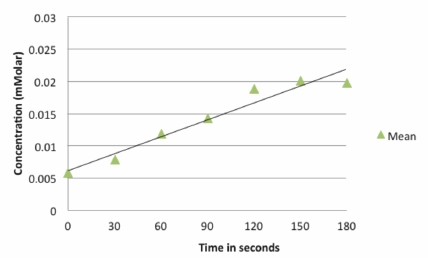
However, by only plotting the mean values for each time point, we lose any sense of the variation in the data. To remedy this problem we need to include a descriptor of the data variability in the graph (either standard deviation or standard error). The graph of the mean values for each time point ± the S.D. now shows the variation in the data.
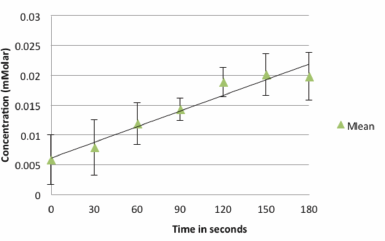
Standard deviation and standard error are both graphed in the same manner. When graphed, your data will basically look like an “I” on top of the data point.
A standard deviation of 0.5 would be graphed by going up 0.5 units above the mean and down 0.5 units below the mean. The variation plotted in this manner is often referred to as “error bars."

The real benefit of using either standard deviation or standard error is you can tell if data sets truly represent different responses to the treatment or if they just represent random variation.
- If ± 1 standard deviation or standard error is plotted on both data sets and these error bars overlap, then these data sets are not “truly” statistically different. In other words, any difference that was observed could be due to random chance.
- If ± 1 standard deviation or standard error is plotted on both data sets and the error bars do not overlap, then you can be reasonably confident that these data sets are different.
- If ± 2 standard deviation or standard error are plotted on both data sets and the error bars still do not overlap, then you can be very confident that these data sets are different.
Smaller error bars represent greater precision in the data but not necessarily greater accuracy in the measurements.
The comparison of error bar method described previously is a simple visual test. This sort of visual comparison in determining if groups of data are “significantly” different is possible with standard error. The rules change slightly for standard deviation because the impact of sample size is not accounted for with standard deviation. The visual comparison of means does not take the place of statistical tests, which are actually the more valid method of comparing means. For the purposes of this lab the visual test will suffice.
Basically what is being done is determining if the variation of the data of individual treatment overlaps to conclude if data sets are truly different (that is, significantly different). As an example, consider the following graph using means ± standard error.
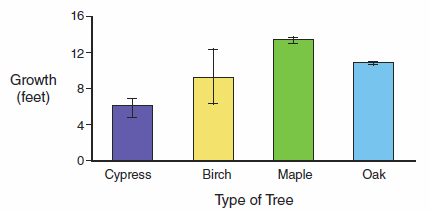
Notice that in a comparison of oak and maple that even though the mean growth rates are relatively close, the growth rates would be considered “significantly” different because even if you doubled the standard error values the bars would not overlap. In contrast, a comparison of birch and maple shows that even though the mean growth rate of the birch and maple is much further apart, the overall growth rate may not really be that different because of the variation in the growth of the birch. The confidence that these data sets are really different is not considered very strong. Lastly, in a comparison of birch and cypress there is really no difference in growth because of the overlap of standard error bars.
If the null hypothesis for this experiment was that all tree species will grow at the same rate and the alternative hypothesis was that tree species grow at different rates, then the data above would allow you to reject the null hypothesis and would therefore support the alternative hypothesis. Keep in mind that this does not prove the alternative hypothesis is correct, but that the alternative hypothesis is consistent with the data (i.e., it could be correct).
Pre-Lab Quiz
Proceed to the Pre-Lab Quiz