Chapter 1. Mendelian Genetics and Chi-square Statistics
Mendelian Genetics and Chi-square Statistics
Mendelian Genetics and Chi-square Statistics
Gregor Mendel, an Augustinian monk, essentially discovered the basic laws that govern how traits are transferred from parent to offspring (all without the aid of microscopes or knowledge of DNA). Mendel was interested in the patterns of inheritance and did a series of experiments in which he cross-pollinated pea plants and observed the appearance of the offspring. Mendel traced specific phenotypes over the course of generations of “crossing” experiments.
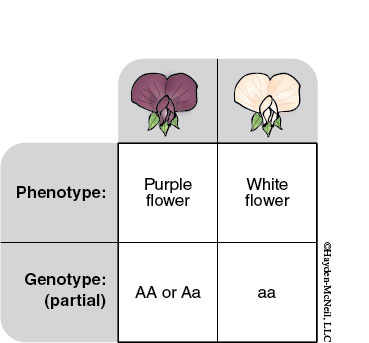
A phenotype is a physical characteristic, a trait you can see or measure, whereas the genotype refers to an individual’s genetic makeup. Mendel worked with easily distinguishable traits. By tracking the number of offspring with specific phenotypes in each generation of a cross, he found that different forms or alleles existed for each trait (e.g., flower color, seed shape) and each parent donates one allele to the offspring. An allele is a specific version of a gene, the DNA that codes for one protein.
Alleles may be dominant or recessive. The two allelic forms are so named because whenever the dominant allele occurs with a recessive allele, the dominant allele is expressed. For example, pea pods come in two colors, green (GG or Gg), which is dominant, and yellow (gg), which is recessive. GG and gg are homozygous genotypes because these individuals carry two of the same alleles. Gg is a heterozygous genotype because the two alleles are different; however, these individuals have the dominant phenotype—they look green. This means you can’t always tell the genotype by looking at the phenotype. Mendel developed laws of inheritance to describe how alleles are represented in gametes and offspring.
Mendel's First Law
The Law of Segregation
During meiosis, the initial diploid cell has a full complement of DNA, that is, it contains two instances (alleles) of every gene. When haploid gametes are formed, only a single set of alelles are represented (one allele of each gene). The two (parental) alleles segregate during gamete formation, so that each gamete contains one and only one allele for every gene.
Mendel's Second Law
The Law of Independent Assortment
Mendel deduced the first law from monohybrid crosses (crosses between parents that differed for only one trait). Mendel found that all traits he studied followed the law of segregation. However, he had studied each trait independently. What would happen if he crossed plants that differed in two traits (a dihybrid cross)? Mendel found that traits were not inherited as a package of solely paternal or maternal forms. Instead, offspring contained all possible combinations of the traits in a specific ratio. Thus, during gamete formation, the way in which alleles for a given trait become distributed is independent of the way in which alleles for other traits become distributed. Allelic pairs segregate independently of otherallelic pairs. So, during gamete formation alleles will not separate solely into paternal and maternal alleles.
When a phenotypic trait is inherited in Mendelian fashion, the ratio of phenotypes and genotypes in the offspring can be predicted. Mendel’s laws allow us to accurately predict the probability of obtaining a particular phenotype in offspring. Based on the outcome of a cross (offspring phenotypes), Mendel’s laws can also be applied to determine the genetic makeup of the parents (in some cases).
The Punnett square is a useful tool for mapping out the possible outcomes of a cross between parents with known genotypes. In Mendel’s first experiment he bred pea plants until he always produced offspring with the same phenotype. These plants are “true-breeding.” True-breeding plants are either homozygous dominant or homozygous recessive for the trait being examined. Mendel then crossed a true-breeding plant with green peas (GG) to a true breeding plant with yellow peas (gg). At the time he knew nothing about heredity, and he expected to get a blending of traits. A Punnett square representing Mendel’s first monohybrid cross can be found below.
Gametes made by one parent are listed at the top; those made by the other parent are down the left side. The boxes of the Punnett square represent all possible outcomes of crossing these two parents. This DOES NOT mean these parents had only four offspring (these peas had many more offspring).
Resulting offspring or first filial (F1) generation
Phenotype: All green
Genotype: All Gg (heterozygous)
Mendel could not figure out what happened to the yellow phenotype. It completely disappeared in the F1 generation. So, like any curious scientist, he crossed two plants from his F1 generation to see what would happen. Deduce Mendel’s results by filling in the following Punnett square.
This second filial (F2) generation has a genotypic ratio of___GG:___ Gg:___ gg among the offspring. The phenotypic ratio is________ green:_________yellow. This phenotypic ratio was observed by Mendel in all his monohybrid crosses (for many different traits).
The following exercises apply Mendel’s laws to corn genetics; you will predict pheno- typic probabilities and use a chi-square statistic to test whether your results agree with Mendel’s laws.
The Monohybrid Cross
The Monohybrid Cross
In this exercise you will test Mendel’s first law using corn ears that display two distinct phenotypes for seed colors: purple and yellow. The purple allele is dominant—this allele allows production of a purple pigment, and as long as one copy of this allele is present (PP or Pp), purple pigment is produced by the corn seed. The yellow allele is recessive—this version of the gene probably codes for a non-functional protein. When a corn seed has two recessive alleles (pp), the seed is yellow. Note that dominance has nothing to do with how common a trait is. Yellow corn is more common than purple corn, but the purple trait is dominant.
On a single ear of corn, you find hundreds of kernels. Each of these kernels is a baby corn plant made by the union of haploid gametes (the pollen and the ovule). The advantage of using an ear of corn to test Mendel’s laws is that it allows us to obtain a large sample size in a short amount of time, because each corn kernel represents an individual offspring from the same plant. Researchers artificially controlled pollen exposure of P-generation plants and then allowed the F1 offspring to self-pollinate in order to obtain the F2 corn seeds you observe in this lab.
The biological supply company we bought the corn from claims that the P-generation parents for this monohybrid corn were a true-breeding purple seed plant (PP) and a true-breeding yellow seed plant (pp).
The Chi-square Statistical Test
The Chi-square Statistical Test
Statistics is a branch of mathematics used by many disciplines to summarize and analyze data. You are probably already familiar with summary statistics such as mean (or average), median, and range. In this lab we use the chi-square statistical test to analyze our Mendelian genetics data. The purpose of statistical tests is to tell us how surprised we should be by our results. In this case, we use the chi-square test to determine how closely our data match our expectations. In other words, the chi-square test will tell us how surprised we should be by any difference between our observed and our expected results. A chi-square test is generally used to test categorical data (in our case we have two phenotypic categories: purple and yellow).
Let’s start with our expected results. Recall the hypothesis that you established for the monohybrid corn cross. Let’s assume for this example that one parent was homozygous for the dominant trait P (purple pigment, genotype PP) and the other parent was homozygous for the recessive trait p (yellow/lack of purple pigment, genotype pp). Their F1 offspring were all heterozygous for this trait (look purple because they can make purple pigment, genotype Pp). When two of these heterozygous F1 offspring were mated, they produced F2 offspring with all three genotypes (PP, Pp, pp). We would expect about ¼ of the offspring to be PP, 2/4 to be Pp (P from pollen and p from egg or p from pollen and P from egg), and ¼ to be pp. Since only the pp offspring look yellow, we expect about ¾ of the offspring to look purple and ¼ to look yellow.
As you all know, there is an element of chance here. When a couple has children, we would expect about half their children to be female (because they got an X chromosome from dad) and half to be male (Y chromosome from dad). While it is true that for each egg fertilization event there is about an equal chance that it will be fertilized by a sperm carrying an X chromosome or a sperm carrying a Y chromosome, there are lots of people with two girls, three boys, three girls and one boy, etc. This happens because of the random chance element . . . you could get two fertilizations in a row by a sperm carrying an X chromosome just like you could get two heads in a row when flipping a coin (even though you would expect heads and tails to occur with equal probability on average). So, when we say we expect ¾ of the F2 offspring to look purple and ¼ to look yellow, we may not get EXACTLY a 3:1 ratio of offspring. However, if the ratio is fairly close to what we expect, we won’t be surprised. If the ratio is very different, we will be surprised, and we may have cause to doubt whether our biological supply company is a reputable supplier of monohybrid corn. The chi-square test will tell us how surprised we should be by any difference between our expected results and our observed results. Our null hypothesis is that our observed results should not differ from the expected results. Let’s get back to the data. . .
We need to calculate how many purple and yellow seeds we would expect if there were exactly three purple seeds for every one yellow seed. To do this, multiply your total number of seeds by ¾ to get your expected number of purple seeds and by ¼ to get your expected number of yellow seeds.
Expected # purple = _________; Expected # yellow = _________
Now we are ready to test our hypothesis using the chi-square statistic. The formula used for calculating this statistic is: chi-square value (χ 2) = Σ (O–E)2/E, where O = your observed values, E = your expected values, and Σ means that you have to find the sum of these (O – E)2/E terms for each of your categories (we have two categories, but you could have more . . . for example, in your dihybrid cross).
Note that this chi-square formula is more complicated than you might initially expect. One reason for this is that sample size (how many Os and Es) affects how surprised you should be. For example, if you flipped a coin 4 times, you would be a little surprised to get four heads in a row (4/4), but if you flipped a coin 4,000 times, you would be really surprised to get 4,000 heads in a row (4,000/4,000). So, when dealing with probability, 4/4 is not really the same as 4,000/4,000. For those of you who are mathematically inclined, this is why we look at the square of the difference divided by the expected value. For those of you who are not mathematically inclined, you just need to know that this is the formula and you need to be able to calculate your chi-square value using it.
Use the following table to calculate your chi-square value for your monohybrid cross class data.
So, how does this “chi-square value” tell us anything about accepting or rejecting a hypothesis?
We use this value to get a p-value using a chi-square table. An abbreviated one is shown below.
The p-value equals the probability that the deviation between your observed and expected values could have occurred due to chance alone. Thus, the lower the p-value, the less likely your results are due to random chance. By convention, biologists agree that a 1 in 20 (or less) chance that your data are due to random chance means that random effects are unlikely to be the correct explanation for your data. In order to find our p-value, we have to first know our degrees of freedom (df). For this test, df = the number of categories – 1. Since we had 2 categories (purple and yellow), our df = 1. Therefore, we only look at the first row of this table and compare our chi-square value to the values given in this row of the table.
First, look at the chi-square value listed under p = 0.05. This value (3.84) is called the critical chi-square value because if your chi-square value is ≥ the critical chi-square value, your p-value is ≤ 0.05 and there is less than a 1 in 20 chance that you could get your observed deviation from your expected values during chance events. Thus, if your chi-square value is ≥ 3.84, you should reject your hypothesis that the observed corn phenotypes represent the 3:1 ratio expected under Mendelian genetics. On the other hand, if your chi-square value is less than the critical value, then p is greater than 0.05 and the variation between your expected and observed values could easily just be due to chance (so you accept your hypothesis that the monohybrid corn has a 3:1 phenotypic ratio, i.e., the null hypothesis of no deviation of the observed from the expected).
Give your chi-square value and your approximate p-value and explain whether you accept or reject your hypothesis of a 3:1 purple:yellow phenotypic ration among F2 offspring.
Note that your chi-square value is only as good as the hypothesis upon which you base your expected values calculation. For example, if we were to hypothesize that we would get an equal number of purple and yellow offspring, our expected values would be very different, giving us a completely different chi-square value.
Dihybrid Cross
Dihybrid Cross
The objective of this exercise is to test Mendel’s second law of independent assortment. Using the same procedure for the monohybrid cross on the preceding pages, you will observe the phenotypes of an F2 ear of corn that is the product of a P-generation cross between true-breeding (homozygous) plants that differed in two traits (kernel color and texture). In corn, you already know that kernel color comes in two forms: purple, which is dominant, and yellow, which is recessive. Corn texture also comes in two forms. Smooth kernels (S) are dominant to wrinkled kernels (s). In this case, the gene involved codes for an enzyme that links glucose molecules together to make starch. The recessive allele codes for a non-functional enzyme. Consequently no starch is made. This corn is sold as “sweet” corn because of all the glucose. When it is fresh, it looks normal, but when it dries out, all the water that had entered it due to osmosis leaves, and the kernel wrinkles up.
For this dihybrid cross, the P-generation genotypes were PPss and ppSS and the possible F2 phenotypes are: purple smooth, purple wrinkled, yellow smooth, and yellow wrinkled. Since one parent can only make gametes with the dominant P and s alleles and the other parent can only make gametes with the recessive p and S alleles, all F1 offspring must be heterozygous (PpSs) with the purple smooth phenotype. Complete the Punnett square below to determine the ratio of offspring genotypes and phenotypes when the F1 corn is self-pollinated to produce an F2 generation. Note that the top row and far left column show all possible gametes these F1 offspring could make.
Write down the number of each F2 phenotype found in your Punnett square:
Purple smooth (PPSS, PpSS, PPSs, PpSs)
Purple wrinkled (PPss, Ppss)
Yellow smooth (ppSS, ppSs)
Yellow wrinkled (ppss)
This is the expected phenotypic ratio for a dihybrid cross of heterozygous parents. Use this expected ratio to formulate your hypothesis (what ratio of phenotypes do you expect for this cross?).
Hypothesis: