4.5 Gene Expression Is the Transformation of DNA Information into Functional Molecules
The information stored as DNA becomes useful when it is expressed in the production of RNA and proteins. This rich and complex topic is the subject of several chapters later in this book, but here we introduce the basics of gene expression. DNA can be thought of as archival information, stored and manipulated judiciously to minimize damage (mutations). It is expressed in two steps. First, an RNA copy is made that encodes directions for protein synthesis. This messenger RNA can be thought of as a photocopy of the original information: it can be made in multiple copies, used, and then disposed of. Second, the information in messenger RNA is translated to synthesize functional proteins. Other types of RNA molecules exist to facilitate this translation.
Several kinds of RNA play key roles in gene expression
Scientists used to believe that RNA played a passive role in gene expression, as a mere conveyor of information. However, recent investigations have shown that RNA plays a variety of roles, from catalysis to regulation. Cells contain several kinds of RNA (Table 4.3):
|
Type |
Relative amount (%) |
Sedimentation coefficient (S) |
Mass (kDa) |
Number of nucleotides |
|---|---|---|---|---|
|
Ribosomal RNA (rRNA) |
80 |
23 |
1.2 × 103 |
3700 |
|
|
|
16 |
0.55 × 103 |
1700 |
|
|
|
5 |
3.6 × 101 |
120 |
|
Transfer RNA (tRNA) |
15 |
4 |
2.5 × 101 |
75 |
|
Messenger RNA (mRNA) |
5 |
|
Heterogeneous |
|
120
1. Messenger RNA (mRNA) is the template for protein synthesis, or translation. An mRNA molecule may be produced for each gene or group of genes that is to be expressed in E. coli, whereas a distinct mRNA is produced for each gene in eukaryotes. Consequently, mRNA is a heterogeneous class of molecules. In prokaryotes, the average length of an mRNA molecule is about 1.2 kilobases (kb). In eukaryotes, mRNA has structural features, such as stem-
2. Transfer RNA (tRNA) carries amino acids in an activated form to the ribosome for peptide-
Kilobase (kb)
A unit of length equal to 1000 base pairs of a double-
One kilobase of double-
3. Ribosomal RNA (rRNA) is the major component of ribosomes (Chapter 30). In prokaryotes, there are three kinds of rRNA, called 23S, 16S, and 5S RNA because of their sedimentation behavior. One molecule of each of these species of rRNA is present in each ribosome. Ribosomal RNA was once believed to play only a structural role in ribosomes. We now know that rRNA is the actual catalyst for protein synthesis.
Ribosomal RNA is the most abundant of these three types of RNA. Transfer RNA comes next, followed by messenger RNA, which constitutes only 5% of the total RNA. Eukaryotic cells contain additional small RNA molecules that play a variety of roles including the regulation of gene expression, processing of RNA and the synthesis of proteins. We will examine these small RNAs in later chapters. In this chapter, we will consider rRNA, mRNA, and tRNA.
All cellular RNA is synthesized by RNA polymerases
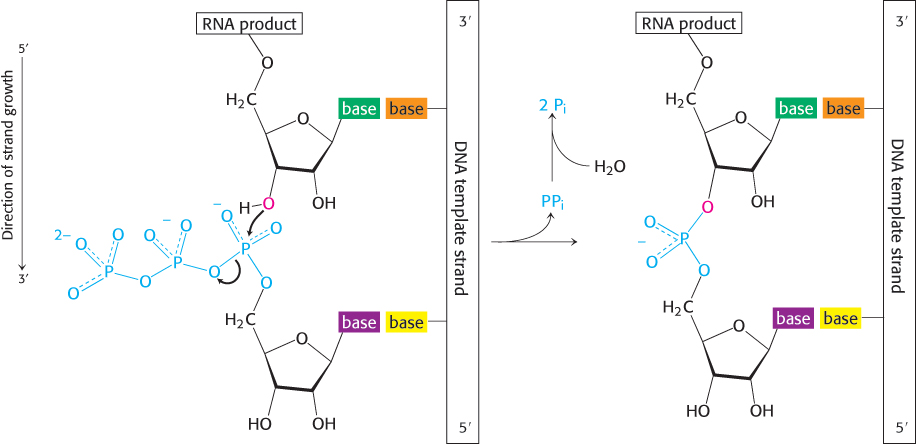
The synthesis of RNA from a DNA template is called transcription and is catalyzed by the enzyme RNA polymerase (Figure 4.27). RNA polymerase catalyzes the initiation and elongation of RNA chains. The reaction catalyzed by this enzyme is
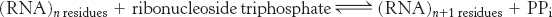
121
RNA polymerase requires the following components:
1. A template. The preferred template is double-
2. Activated precursors. All four ribonucleoside triphosphates—ATP, GTP, UTP, and CTP—
3. A divalent metal ion. Either Mg2+ or Mn2+ is effective.
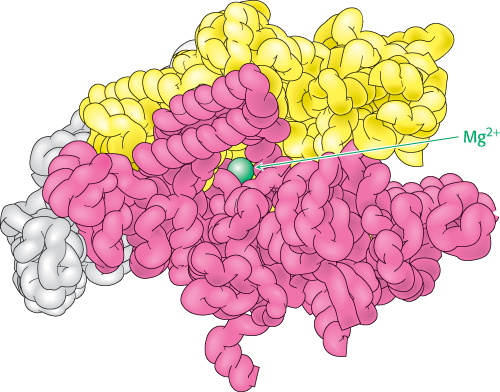
The synthesis of RNA is like that of DNA in several respects (Figure 4.28). First, the direction of synthesis is 5′ → 3′. Second, the mechanism of elongation is similar: the 3′-OH group at the terminus of the growing chain makes a nucleophilic attack on the innermost phosphoryl group of the incoming nucleoside triphosphate. Third, the synthesis is driven forward by the hydrolysis of pyrophosphate. In contrast with DNA polymerase, however, RNA polymerase does not require a primer. In addition, the ability of RNA polymerase to correct mistakes is not as extensive as that of DNA polymerase.
All three types of cellular RNA—
RNA polymerases take instructions from DNA templates
|
DNA template (plus, or coding, strand of ϕX174) |
RNA product |
||
|---|---|---|---|
|
A |
25 |
U |
25 |
|
T |
33 |
A |
32 |
|
G |
24 |
C |
23 |
|
C |
18 |
G |
20 |
RNA polymerase, like the DNA polymerases described earlier, takes instructions from a DNA template. The earliest evidence was the finding that the base composition of newly synthesized RNA is the complement of that of the DNA template strand, as exemplified by the RNA synthesized from a template of single-

122
Transcription begins near promoter sites and ends at terminator sites
Consensus sequence
Not all base sequences of promoter sites are identical. However, they do possess common features, which can be represented by an idealized consensus sequence. Each base in the consensus sequence TATAAT is found in most prokaryotic promoters. Nearly all promoter sequences differ from this consensus sequence at only one or two bases.
RNA polymerase must detect and transcribe discrete genes from within large stretches of DNA. What marks the beginning of the unit to be transcribed? DNA templates contain regions called promoter sites that specifically bind RNA polymerase and determine where transcription begins. In bacteria, two sequences on the 5′ (upstream) side of the first nucleotide to be transcribed function as promoter sites (Figure 4.30A). One of them, called the Pribnow box, has the consensus sequence TATAAT and is centered at −10 (10 nucleotides on the 5′ side of the first nucleotide transcribed, which is denoted by +1). The other, called the −35 region, has the consensus sequence TTGACA. The first nucleotide transcribed is usually a purine.
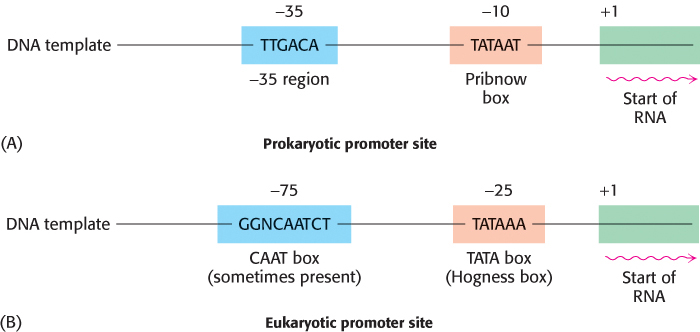
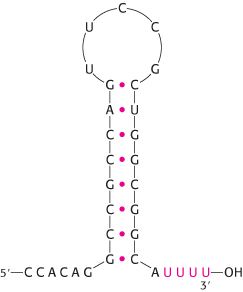
Eukaryotic genes encoding proteins have promoter sites with a TATAAA consensus sequence, called a TATA box or a Hogness box, centered at about −25 (Figure 4.30B). Many eukaryotic promoters also have a CAAT box with a GGNCAATCT consensus sequence centered at about −75. The transcription of eukaryotic genes is further stimulated by enhancer sequences, which can be quite distant (as many as several kilobases) from the start site, on either its 5′ or its 3′ side.
123
In E. coli, RNA polymerase proceeds along the DNA template, transcribing one of its strands until it synthesizes a terminator sequence. This sequence encodes a termination signal, which is a base-
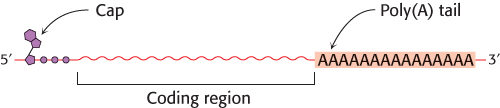
In eukaryotes, the messenger RNA is modified after transcription (Figure 4.32). A “cap” structure, a guanosine nucleotide attached to the mRNA with an unusual 5′-5′ triphosphate linkage, is attached to the 5′ end, and a sequence of adenylates, the poly(A) tail, is added to the 3′ end. These modifications will be presented in detail in Chapter 29.
Transfer RNAs are the adaptor molecules in protein synthesis
We have seen that mRNA is the template for protein synthesis. How then does it direct amino acids to become joined in the correct sequence to form a protein? In 1958, Francis Crick wrote:
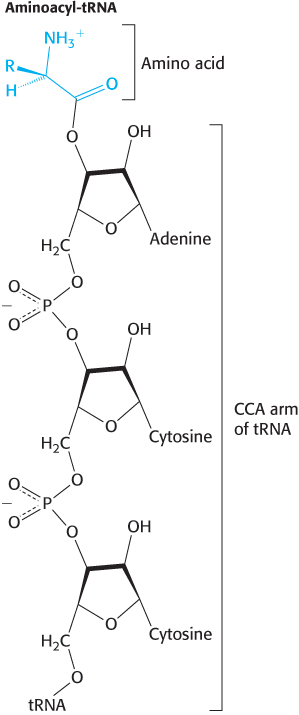
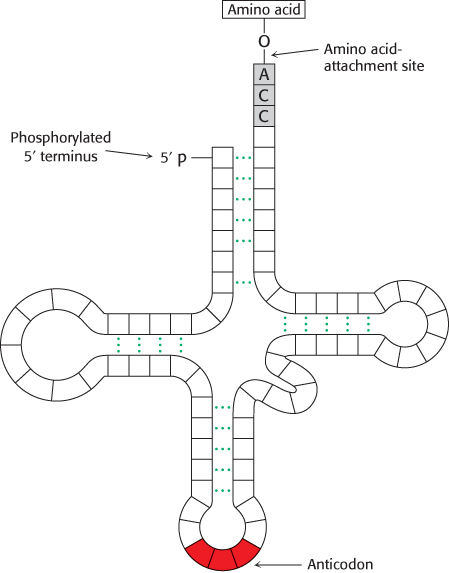
RNA presents mainly a sequence of sites where hydrogen bonding could occur. One would expect, therefore, that whatever went onto the template in a specific way did so by forming hydrogen bonds. It is therefore a natural hypothesis that the amino acid is carried to the template by an adaptor molecule, and that the adaptor is the part that actually fits onto the RNA. In its simplest form, one would require twenty adaptors, one for each amino acid.
This highly innovative hypothesis soon became established as fact. The adaptors in protein synthesis are transfer RNAs. The structure and reactions of these remarkable molecules will be considered in detail in Chapter 30. For the moment, it suffices to note that tRNAs contain an amino acid-
124