28.3 DNA Replication Is Highly Coordinated
DNA replication must be very rapid, given the sizes of the genomes and the rates of cell division. The E. coli genome contains 4.6 million base pairs and is copied in less than 40 minutes. Thus, 2000 bases are incorporated per second. Enzyme activities must be highly coordinated to replicate entire genomes precisely and rapidly.
We begin our consideration of the coordination of DNA replication by looking at E. coli, which has been extensively studied. For this organism with a relatively small genome, replication begins at a single site and continues around the circular chromosome. The coordination of eukaryotic DNA replication is much more complex because there are many initiation sites throughout the genome and an additional enzyme is needed to replicate the ends of linear chromosomes.
DNA replication requires highly processive polymerases
Processive enzyme
From the Latin procedere, “to go forward.”
An enzyme that catalyzes multiple rounds of the elongation or digestion of a polymer while the polymer stays bound. A distributive enzyme, in contrast, releases its polymeric substrate between successive catalytic steps.
Replicative polymerases are characterized by their very high catalytic potency, fidelity, and processivity. Processivity refers to the ability of an enzyme to catalyze many consecutive reactions without releasing its substrate. These polymerases are assemblies of many subunits that have evolved to grasp their templates and not let go until many nucleotides have been added. The source of the processivity was revealed by the determination of the three-
840
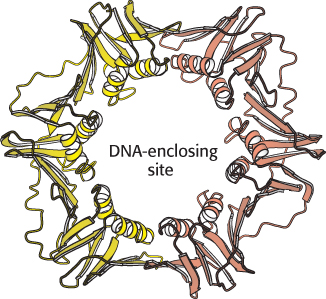
How does DNA become entrapped inside the sliding clamp? Replicative polymerases also include assemblies of subunits that function as clamp loaders. These enzymes grasp the sliding clamp and, utilizing the energy of ATP binding, pull apart one of the interfaces between the two subunits of the sliding clamp. DNA can move through the gap, inserting itself through the central hole. ATP hydrolysis then releases the clamp, which closes around the DNA.
The leading and lagging strands are synthesized in a coordinated fashion
Replicative polymerases such as DNA polymerase III synthesize the leading and lagging strands simultaneously at the replication fork (Figure 28.22). DNA polymerase III begins the synthesis of the leading strand starting from the RNA primer formed by primase. The duplex DNA ahead of the polymerase is unwound by a hexameric helicase called DnaB. Copies of single-
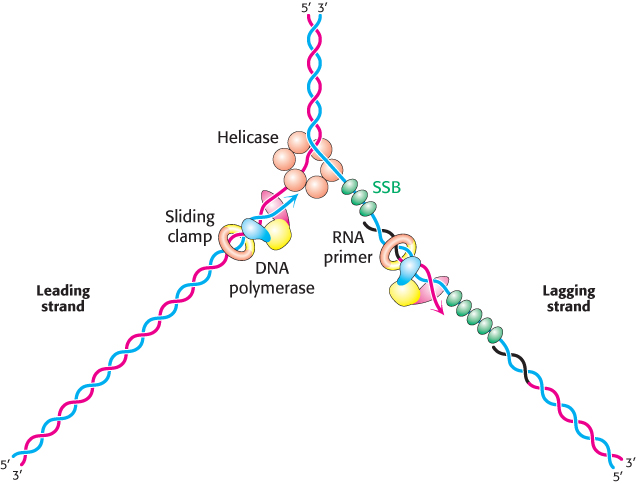
The mode of synthesis of the lagging strand is necessarily more complex. As mentioned earlier, the lagging strand is synthesized in fragments so that 5′ → 3′ polymerization leads to overall growth in the 3′ → 5′ direction. Yet the synthesis of the lagging strand is coordinated with the synthesis of the leading strand. How is this coordination accomplished? Examination of the subunit composition of the DNA polymerase III holoenzyme reveals an elegant solution (Figure 28.23). The holoenzyme includes two copies of the polymerase core enzyme, which consists of the DNA polymerase itself (the α subunit); the ε subunit, a 3′-to-
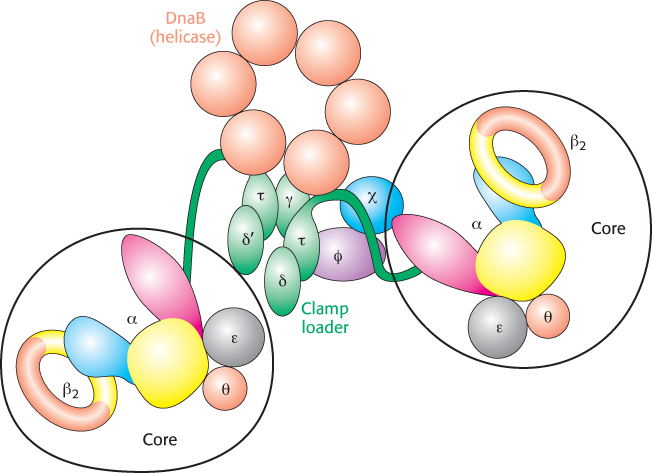
841
The lagging-
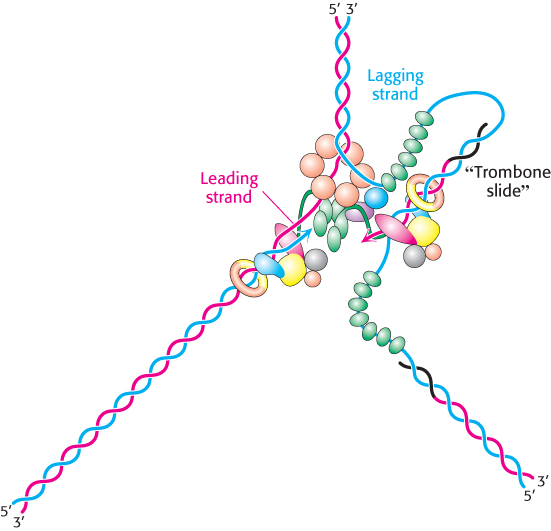
842
The gaps between fragments of the nascent lagging strand are filled by DNA polymerase I. This essential enzyme also uses its 5′ → 3′ exonuclease activity to remove the RNA primer lying ahead of the polymerase site. The primer cannot be erased by DNA polymerase III, because the enzyme lacks 5′ → 3′ editing capability. Finally, DNA ligase connects the fragments.
DNA replication in Escherichia coli begins at a unique site
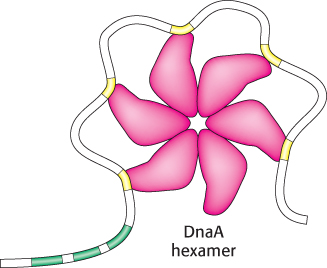
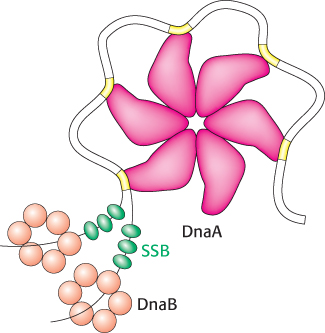
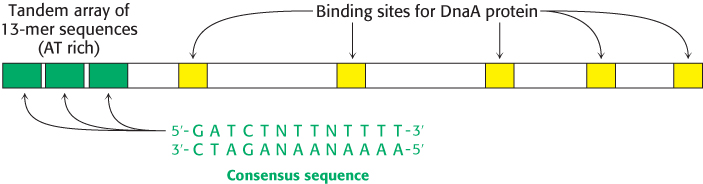
In E. coli, DNA replication starts at a unique site within the entire 4.6 × 106 bp genome. This origin of replication, called the oriC locus, is a 245-
1. The binding of DnaA proteins to DNA is the first step in the preparation for replication. DnaA is a member of the P-
2. Single DNA strands are exposed in the prepriming complex. With DNA wrapped around a DnaA hexamer, additional proteins are brought into play. The hexameric helicase DnaB is loaded around the DNA with the help of the helicase loader protein DnaC. Local regions of oriC, including the AT regions, are unwound and trapped by the single-
3. The polymerase holoenzyme assembles. The DNA polymerase III holoenzyme assembles on the prepriming complex, initiated by interactions between DnaB and the sliding-
843
DNA synthesis in eukaryotes is initiated at multiple sites
Replication in eukaryotes is mechanistically similar to replication in prokaryotes but is more challenging for a number of reasons. One of them is sheer size: E. coli must replicate 4.6 million base pairs, whereas a human diploid cell must replicate more than 6 billion base pairs. Second, the genetic information for E. coli is contained on 1 chromosome, whereas, in human beings, 23 pairs of chromosomes must be replicated. Finally, whereas the E. coli chromosome is circular, human chromosomes are linear. Unless countermeasures are taken, linear chromosomes are subject to shortening with each round of replication.
The first two challenges are met by the use of multiple origins of replication. In human beings, replication requires about 30,000 origins of replication, with each chromosome containing several hundred. Each origin of replication is the starting site for a replication unit, or replicon. DNA replication can be monitored by single-

1. The assembly of the ORC is the first step in the preparation for replication. In human beings, the ORC is composed of six different proteins, each homologous to DnaA. These proteins come together to form a hexameric structure analogous to the assembly formed by DnaA.
2. Licensing factors recruit a helicase that exposes single strands of DNA. After the ORC has been assembled, additional proteins are recruited, including Cdc6, a homolog of the ORC subunits, and Cdt1. These proteins, in turn, recruit a hexameric helicase with six distinct subunits called Mcm2-
3. Two distinct polymerases are needed to copy a eukaryotic replicon. An initiator polymerase called polymerase α begins replication but is soon replaced by a more processive enzyme. This process is called polymerase switching because one polymerase has replaced another. This second enzyme, called DNA polymerase δ, is the principal replicative polymerase in eukaryotes (Table 28.1).
|
Name |
Function |
|---|---|
|
Prokaryotic Polymerases |
|
|
DNA polymerase I |
Erases primer and fills in gaps on lagging strand |
|
DNA polymerase II (error- |
DNA repair |
|
DNA polymerase III |
Primary enzyme of DNA synthesis |
|
Eukaryotic Polymerases |
|
|
DNA polymerase α Primase subunit DNA polymerase unit |
Initiator polymerase Synthesizes the RNA primer Adds stretch of about 20 nucleotides to the primer |
|
DNA polymerase β (error- |
DNA repair |
|
DNA polymerase δ |
Primary enzyme of DNA synthesis |
844
Replication begins with the binding of DNA polymerase α. This enzyme includes a primase subunit, used to synthesize the RNA primer, as well as an active DNA polymerase. After this polymerase has added a stretch of about 20 deoxynucleotides to the primer, another replication protein, called replication factor C (RFC), displaces DNA polymerase α. Replication factor C attracts a sliding clamp called proliferating cell nuclear antigen (PCNA), which is homologous to the β2 subunit of E. coli polymerase III. The binding of PCNA to DNA polymerase δ renders the enzyme highly processive and suitable for long stretches of replication. Replication continues in both directions from the origin of replication until adjacent replicons meet and fuse. RNA primers are removed and the DNA fragments are ligated by DNA ligase.
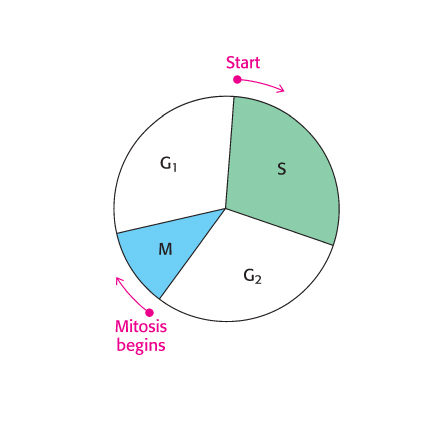
The use of multiple origins of replication requires mechanisms for ensuring that each sequence is replicated once and only once. The events of eukaryotic DNA replication are linked to the eukaryotic cell cycle (Figure 28.29). The processes of DNA synthesis and cell division are coordinated in the cell cycle so that the replication of all DNA sequences is complete before the cell progresses into the next phase of the cycle. This coordination requires several checkpoints that control the progression along the cycle. A family of small proteins termed cyclins are synthesized and degraded by proteasomal digestion in the course of the cell cycle. Cyclins act by binding to specific cyclin-
Telomeres are unique structures at the ends of linear chromosomes
Whereas the genomes of essentially all prokaryotes are circular, the chromosomes of human beings and other eukaryotes are linear. The free ends of linear DNA molecules introduce several complications that must be resolved by special enzymes. In particular, complete replication of DNA ends is difficult because polymerases act only in the 5′ → 3′ direction. The lagging strand would have an incomplete 5′ end after the removal of the RNA primer. Each round of replication would further shorten the chromosome.
The first clue to how this problem is resolved came from sequence analyses of the ends of chromosomes, which are called telomeres (from the Greek telos, “an end”). Telomeric DNA contains hundreds of tandem repeats of a six-
845
The structure adopted by telomeres has been extensively investigated. Evidence suggests that they may form large duplex loops (Figure 28.30). The single-

Telomeres are replicated by telomerase, a specialized polymerase that carries its own RNA template
How are the repeated sequences generated? An enzyme, termed telomerase, that executes this function has been purified and characterized. When a primer ending in GGTT is added to human telomerase in the presence of deoxynucleoside triphosphates, the sequences GGTTAGGGTT and GGTTAGGGTTAGGGTT, as well as longer products, are generated. Elizabeth Blackburn and Carol Greider discovered that the enzyme adding the repeats contains an RNA molecule that serves as the template for the elongation of the G-
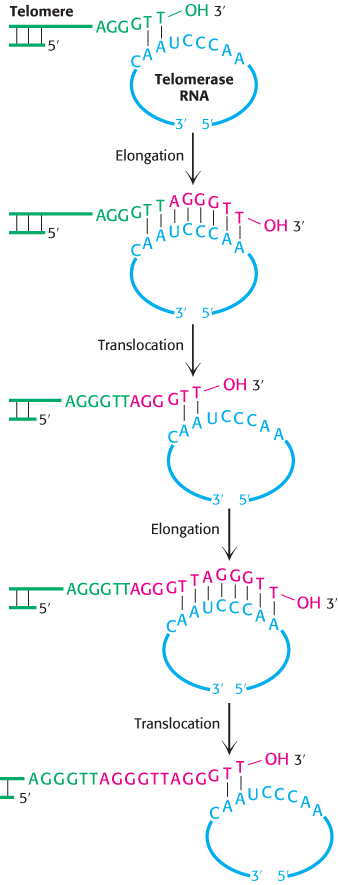
Subsequently, a protein component of telomerases also was identified. This component is related to reverse transcriptases, enzymes first discovered in retroviruses that copy RNA into DNA (Section 5.2). Thus, telomerase is a specialized reverse transcriptase that carries its own template. Telomerase is generally expressed at high levels only in rapidly growing cells. Thus, telomeres and telomerase can play important roles in cancer-
 Because cancer cells express high levels of telomerase, whereas most normal cells do not, telomerase is a potential target for anticancer therapy. A variety of approaches for blocking telomerase expression or blocking its activity are under investigation for cancer treatment and prevention.
Because cancer cells express high levels of telomerase, whereas most normal cells do not, telomerase is a potential target for anticancer therapy. A variety of approaches for blocking telomerase expression or blocking its activity are under investigation for cancer treatment and prevention.