32.2 Transcription Factors Bind DNA and Regulate Transcription Initiation
DNA-binding transcription factors are key to gene regulation in eukaryotes, just as they are in prokaryotes. However, the roles of eukaryotic transcription factors are different in several ways. First, whereas the DNA-binding sites crucial for the control of gene expression in prokaryotes are usually quite close to promoters, those in eukaryotes can be farther away from promoters and can exert their action at a distance. Second, most prokaryotic genes are regulated by single transcription factors, and multiple genes in a pathway are expressed in a coordinated fashion because such genes are often transcribed as part of a polycistronic mRNA. In eukaryotes, the expression of each gene is typically controlled by multiple transcription factors, and the coordinated expression of different genes depends on having similar transcription-factor-binding sites in each gene in the set. Third, in prokaryotes, transcription factors usually interact directly with RNA polymerase. In eukaryotes, while some transcription factors interact directly with RNA polymerase, many others act more indirectly, interacting with other proteins associated with RNA polymerase or modifying chromatin structure. Let us now examine eukaryotic transcription factors in more detail.
Eukaryotic transcription factors usually consist of several domains. The DNA-binding domain binds to regulatory sequences that can either be adjacent to the promoter or at some distance from it. Most commonly, transcription factors include additional domains that help activate transcription. When a transcription factor is bound to the DNA, its activation domain promotes transcription by interacting with RNA polymerase II, by interacting with other associated proteins, or by modifying the local structure of chromatin.
A range of DNA-binding structures are employed by eukaryotic DNA-binding proteins
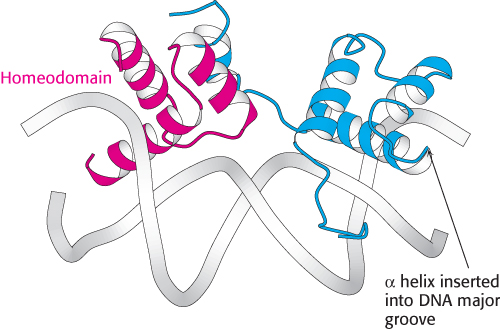
Figure 32.6:  Homeodomain structure. The structure of a heterodimer formed from two different DNA-binding domains, each based on a homeodomain. Notice that each homeodomain has a helix-turn-helix motif with one helix inserted into the major groove of DNA.
Homeodomain structure. The structure of a heterodimer formed from two different DNA-binding domains, each based on a homeodomain. Notice that each homeodomain has a helix-turn-helix motif with one helix inserted into the major groove of DNA.
[Drawn from 1AKH.pdb.]
The structures of many eukaryotic DNA-binding proteins have been determined and a range of structural motifs have been observed, but we will focus on three that reveal the common features and the diversity of these motifs. The first class of eukaryotic DNA-binding unit that we will consider is the homeodomain (Figure 32.6). The structure of the homeodomain and its mode of recognition of DNA are very similar to those of the prokaryotic helix-turn-helix proteins. In eukaryotes, homeodomain proteins often form heterodimeric structures, sometimes with other homeodomain proteins, that recognize asymmetric DNA sequences.
The second class of eukaryotic DNA-binding unit comprises the basic-leucine zipper (bZip) proteins (Figure 32.7). This DNA-binding unit consists of a pair of long α helices. The first part of each α helix is a basic region that lies in the major groove of the DNA and makes contacts responsible for DNA-site recognition. The second part of each α helix forms a coiled-coil structure with its partner. Because these units are often stabilized by appropriately spaced leucine residues, these structures are often referred to as leucine zippers.
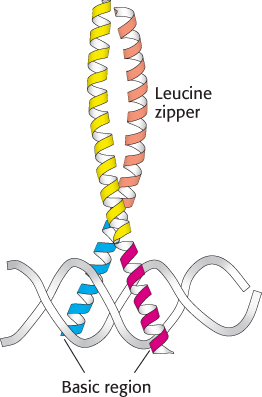
Figure 32.7:
Basic-leucine zipper. This heterodimer comprises two basic-leucine zipper proteins. Notice that the basic region lies in the major groove of DNA. The leucine-zipper part stabilizes the protein dimer.
[Drawn from 1FOS.pdb.]
The final class of eukaryotic DNA-binding units that we will consider here are the Cys2His2 zinc-finger domains (Figure 32.8). A DNA-binding unit of this class comprises tandem sets of small domains, each of which binds a zinc ion through conserved sets of two cysteine and two histidine residues. These structures, often called zinc-finger domains, form a string that follows the major groove of DNA. An α helix from each domain makes specific contact with the edges of base pairs within the groove. Some proteins contain arrays of 10 or more zinc-finger domains, potentially enabling them to contact long stretches of DNA. The human genome encodes several hundred proteins that contain zinc-finger domains of this class. We will encounter another class of zinc-based DNA-binding domain when we consider nuclear hormone receptors in Section 32.3.
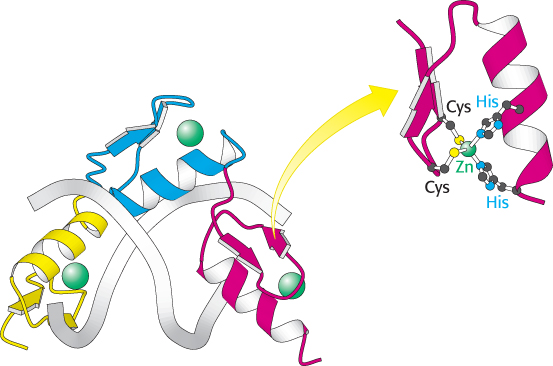
Figure 32.8:
Zinc-finger domains. A DNA-binding domain comprising three Cys2His2 zinc-finger domains (shown in yellow, blue, and red) is shown in a complex with DNA. Each zinc-finger domain is stabilized by a bound zinc ion (shown in green) through interactions with two cysteine residues and two histidine residues. Notice how the protein wraps around the DNA in the major groove.
[Drawn from 1AAY.pdb.]
Activation domains interact with other proteins
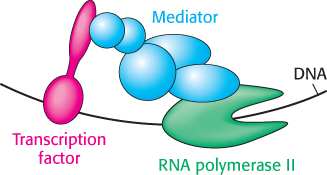
Figure 32.9: Mediator. Mediator, a large complex of protein subunits, acts as a bridge between transcription factors bearing activation domains and RNA polymerase II. These interactions help recruit and stabilize RNA polymerase II near specific genes that are then transcribed.
The activation domains of transcription factors generally recruit other proteins that promote transcription. In some cases, these activation domains interact directly with RNA polymerase II or closely associated proteins. The activation domains act through intermediary proteins that bridge between the transcription factors and the polymerase. An important target of activators is mediator, a complex of 25 to 30 subunits conserved from yeast to human beings, that acts as a bridge between transcription factors and promoter-bound RNA polymerase II (Figure 32.9).
Activation domains are less conserved than DNA-binding domains. In fact, very little sequence similarity has been found. For example, they may be acidic, hydrophobic, glutamine rich, or proline rich. However, they have certain features in common. First, they are often redundant; that is, a part of the activation domain can be deleted without loss of function. Second, they are modular and can activate transcription when paired with a variety of DNA-binding domains. Third, they can act synergistically: two activation domains acting together create a stronger effect than either acting separately.
We have been considering the case in which gene control increases the expression level of a gene. In many cases, the expression of a gene must be decreased by blocking transcription. The agents in such cases are transcriptional repressors. Like activators, transcriptional repressors act in many cases by altering chromatin structure.
Multiple transcription factors interact with eukaryotic regulatory regions
The basal transcription complex described in Chapter 29 initiates transcription at a low frequency. Recall that several general transcription factors join with RNA polymerase II to form the basal transcription complex. Additional transcription factors must bind to other sites that can be near the promoter or quite distant for a gene to achieve a higher rate of mRNA synthesis. In contrast with the regulators of prokaryotic transcription, few eukaryotic transcription factors have any effect on their own. Instead, each factor recruits other proteins to build up large complexes that interact with the transcriptional machinery to activate transcription.
A major advantage of this mode of regulation is that a given regulatory protein can have different effects, depending on what other proteins are present in the same cell. This phenomenon, called combinatorial control, is crucial to multicellular organisms that have many different cell types. Even in unicellular eukaryotes such as yeast, combinatorial control allows the generation of distinct cell types.
Enhancers can stimulate transcription in specific cell types
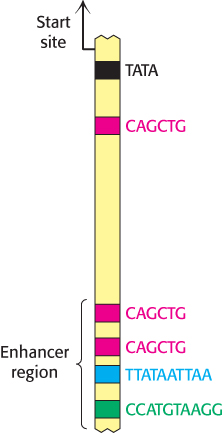
Figure 32.10: Enhancer binding sites. A schematic structure for the region 1 kb upstream of the start site for the muscle creatine kinase gene. One binding site of the form 5′-CAGCTG-3′ is present near the TATA box. The enhancer region farther upstream contains two binding sites for the same protein and two additional binding sites for other proteins.
Transcription factors can often act even if their binding sites lie at a considerable distance from the promoter. These distant regulatory sites are called enhancers (Chapter 29). Enhancers function by serving as binding sites for specific transcription factors. An enhancer is effective only in the specific cell types in which appropriate regulatory proteins are expressed. In many cases, these DNA-binding proteins influence transcription initiation by perturbing the local chromatin structure to expose a gene or its regulatory sites rather than by direct interactions with RNA polymerase. This mechanism accounts for the ability of enhancers to act at a distance.
The properties of enhancers are illustrated by studies of the enhancer controlling the muscle isoform of creatine kinase (Figure 32.10). The results of mutagenesis and other studies revealed the presence of an enhancer located between 1350 and 1050 base pairs upstream of the start site of the gene for this enzyme. Experimentally inserting this enhancer near a gene not normally expressed in muscle cells is sufficient to cause the gene to be expressed at high levels in muscle cells but not in other cells (Figure 32.11).
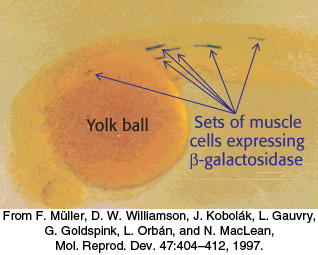
Figure 32.11: An experimental demonstration of enhancer function. A promoter for muscle creatine kinase artificially drives the transcription of β-galactosidase in a zebrafish embryo. Only specific sets of muscle cells produce β-galactosidase, as visualized by the formation of the blue product on treatment of the embryo with X-Gal.
Induced pluripotent stem cells can be generated by introducing four transcription factors into differentiated cells
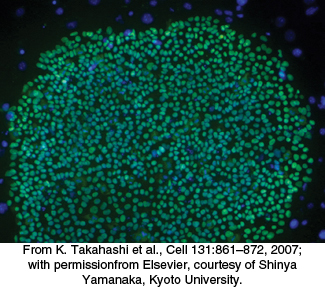
Figure 32.12: Induced pluripotent stem cells. A micrograph of human induced pluripotent stem cells stained green for a transcription factor that is characteristic of pluripotent cells.
 An important application illustrating the power of transcription factors is the development of induced pluripotent stem (iPS) cells. Pluripotent stem cells have the ability to differentiate into many different cell types on appropriate treatment. Previously isolated cells derived from embryos show a very high degree of pluripotency. Over time, researchers identified dozens of genes in embryonic stem cells that contributed to this pluripotency when expressed. In a remarkable experiment reported for mouse cells in 2006 and human cells in 2007, Shinya Yamanaka demonstrated that just four genes out of this entire set could induce pluripotency in already-differentiated skin cells. Yamanaka introduced genes encoding four transcription factors into skin cells called fibroblasts. The fibroblasts de-differentiated into cells that appeared to have characteristics very nearly identical with those of embryonic stem cells (Figure 32.12).
An important application illustrating the power of transcription factors is the development of induced pluripotent stem (iPS) cells. Pluripotent stem cells have the ability to differentiate into many different cell types on appropriate treatment. Previously isolated cells derived from embryos show a very high degree of pluripotency. Over time, researchers identified dozens of genes in embryonic stem cells that contributed to this pluripotency when expressed. In a remarkable experiment reported for mouse cells in 2006 and human cells in 2007, Shinya Yamanaka demonstrated that just four genes out of this entire set could induce pluripotency in already-differentiated skin cells. Yamanaka introduced genes encoding four transcription factors into skin cells called fibroblasts. The fibroblasts de-differentiated into cells that appeared to have characteristics very nearly identical with those of embryonic stem cells (Figure 32.12).
These iPS cells represent powerful research tools and, potentially, a new class of therapeutic agents. The proposed concept is that a sample of a patient’s fibroblasts could be readily isolated and converted into iPS cells. These iPS cells could be treated to differentiate into a desired cell type that could then be transplanted into the patient. For example, such an approach might be used to restore a particular class of nerve cells that had been depleted by a neurodegenerative disease. Although the field of iPS cell research is still evolving, it holds great promise as a possible approach to treat any common and difficult-to-treat diseases.