Potential targets can be identified in the human proteome
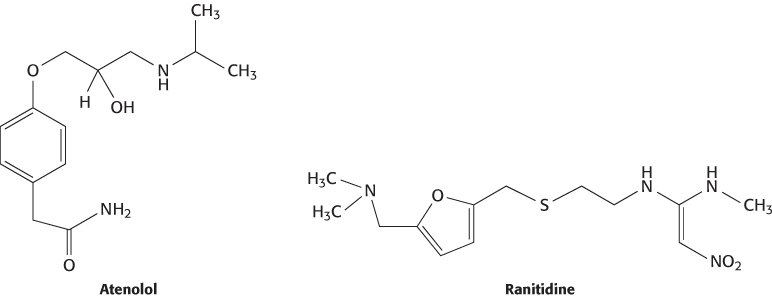
The human genome encodes approximately 21,000 proteins, not counting the variation produced by alternative mRNA splicing and posttranslational modifications. Many of these proteins are potential drug targets, in particular those that are enzymes or receptors and have significant biological effects when activated or inhibited. Several large protein families are particularly rich sources of targets. For example, the human genome includes genes for more than 500 protein kinases that can be recognized by comparing the deduced amino acid sequences. Many of these kinases are known to play a role in the progression of a variety of diseases. For example, Bcr-Abl kinase, a dysregulated kinase formed from a specific chromosomal defect, is known to contribute to certain leukemias and is the target of the drug imatinib mesylate (Gleevec; Section 14.5). Some of the other protein kinases undoubtedly play central roles in particular cancers as well. Similarly, the human genome encodes approximately 800 7TM receptors (Section 14.1), of which approximately 350 are odorant receptors. Many of the remaining 7TM receptors are known or potential drug targets. For example, the beta-blockers, which are widely used to treat hypertension, target the β1-adrenergic receptor, and the antiulcer medication ranitidine (Zantac) targets the histamine H2 receptor (a 7TM receptor that participates in the control of gastric acid secretion).
Novel proteins that are not part of large families already supplying drug targets can be more readily identified through the use of genomic information. There are a number of ways to identify proteins that could serve as targets of drug-development programs. One way is to look for changes in expression patterns, protein localization, or posttranslational modifications in cells from disease-afflicted organisms. Another is to perform studies of tissues or cell types in which particular genes are expressed. Such analyses of the human genome should increase the number of actively pursued drug targets.
Animal models can be developed to test the validity of potential drug targets
The genomes of a number of model organisms have now been sequenced. The most important of these genomes for drug development is that of the mouse. Remarkably, the mouse and human genomes are approximately 85% identical in sequence, and more than 98% of all human genes have recognizable mouse counterparts. Mouse studies provide drug developers with a powerful tool—the ability to disrupt (“knock out”) specific genes in the mouse (Section 5.4). If disruption of a gene has a desirable effect, then the product of this gene may represent a promising drug target. The utility of this approach has been demonstrated retrospectively. For example, disruption of the gene for the α subunit of the H+–K+ ATPase, the key protein for secreting acid into the stomach, produces mice with a gastric pH of 6.9. Under similar conditions, their wild-type counterparts produce a gastric pH of 3.2. This protein is the target of the drugs omeprazole (Prilosec) and lansoprazole (Prevacid and Takepron), used for treating gastroesophageal reflux disease.

Several large-scale efforts are underway to generate hundreds or thousands of mouse strains, each having a different gene disrupted. The phenotypes of these mice are a good indication of whether the protein encoded by a disrupted gene is a promising drug target. This approach allows drug developers to evaluate potential targets without any preconceived notions regarding physiological function.
Potential targets can be identified in the genomes of pathogens
Human proteins are not the only important drug targets. Drugs such as penicillin and HIV protease inhibitors act by targeting proteins within a pathogen. The genomes of hundreds of pathogens have now been sequenced, and these genome sequences can be mined for potential targets.
New antibiotics are needed to combat bacteria that are resistant to many existing antibiotics. One approach seeks proteins essential for cell survival that are conserved in a wide range of bacteria. Drugs that inactivate such proteins are expected to be broad-spectrum antibiotics, useful for treating infections from any of a range of different bacteria. One such protein is peptide deformylase, the enzyme that removes formyl groups present at the amino termini of bacterial proteins immediately after translation (Figure 30.19).
Alternatively, a drug may be needed against a specific pathogen. An example of such a pathogen is the strain of coronavirus responsible for severe acute respiratory syndrome (SARS). Within one month of the recognition of this emerging disease, investigators had isolated the virus that causes the syndrome, and, within weeks, completely sequenced its 29,751-base genome. This sequence revealed the presence of a gene encoding a viral protease, known to be essential for viral replication from studies of other members of the coronavirus family to which the SARS virus belongs. This structure has opened the possibility for specific antiviral treatments for this, and related, viruses (Figure 36.25).
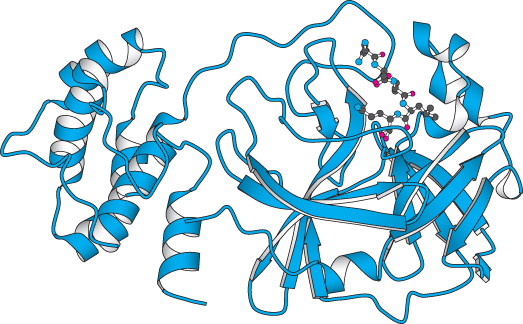
Figure 36.25: Emerging drug target. The structure of a protease from the coronavirus that causes SARS (severe acute respiratory syndrome) is shown bound to an inhibitor. This structure was determined less than a year after the identification of the virus.
[Drawn from 1P9S.pdb.]
Genetic differences influence individual responses to drugs
Many drugs are not effective in everyone, often because of genetic differences among individuals. Nonresponding persons may have slight differences in either a drug’s target molecule or the proteins taking part in drug transport and metabolism. The goal of the emerging fields of pharmacogenetics and pharmacogenomics is to design drugs that either act more consistently from person to person or are tailored to individual persons with particular genotypes.
Drugs such as metoprolol that target the β1-adrenergic receptor are popular treatments for hypertension. These drugs are often referred to as “beta-blockers.”
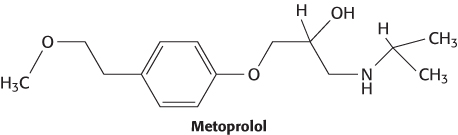
However, some individuals do not respond well to beta-blockers. Two variants of the gene coding for the β1-adrenergic receptor are common in the U.S. population. The most common allele has serine in position 49 and arginine in position 389. In some persons, however, glycine replaces one or the other of these residues. In clinical studies, participants with two copies of the most common allele responded well to metoprolol: their daytime diastolic blood pressure was reduced by 14.7 ± 2.9 mm Hg on average. In contrast, participants with one variant allele showed a smaller reduction in blood pressure, and the drug had no significant effect on participants with two variant alleles (Figure 36.26). These observations suggest the potential utility of genotyping individual patients at these positions. One could then predict whether treatment with metoprolol or other beta-blockers is likely to be effective.
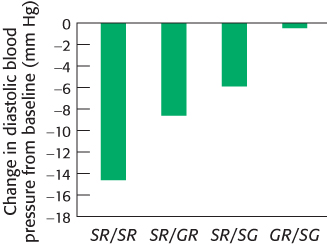
Figure 36.26: Phenotype–genotype correlation. Average changes in diastolic blood pressure on treatment with metoprolol. Persons with two copies of the most common allele (S49R389) showed significant decreases in blood pressure. Those with one variant allele (GR or SG) showed more modest decreases, and those with two variant alleles (GR/SG) showed no decrease.
[Data from J. A. Johnson et al., Clin. Pharmacol. Ther. 74:44–52, 2003.]
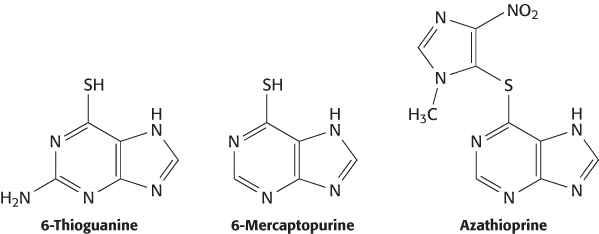
Given the importance of ADME and toxicity properties in determining drug efficacy, it is not surprising that variations in proteins participating in drug transport and metabolism can alter a drug’s effectiveness. An important example is the use of thiopurine drugs such as 6-thioguanine, 6-mercaptopurine, and azothioprine to treat diseases including leukemia, immune disorders, and inflammatory bowel disease.
A minority of patients who are treated with these drugs show signs of toxicity at doses that are well tolerated by most patients. These differences between patients are due to rare variations in the gene encoding the xenobiotic-metabolizing enzyme thiopurine methyltransferase, which adds a methyl group to sulfur atoms.

The variant enzyme is less stable. Patients with these variant enzymes can build up toxic levels of the drugs if appropriate care is not taken. Thus, genetic variability in an enzyme participating in drug metabolism plays a large role in determining the variation in the tolerance of different persons to particular drug levels. Many other drug-metabolism enzymes and drug-transport proteins have been implicated in controlling individual reactions to specific drugs. The identification of the genetic factors will allow a deeper understanding of why some drugs work well in some individuals but poorly in others. In the future, doctors may examine a patient’s genes to help plan drug-therapy programs.