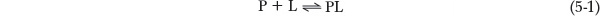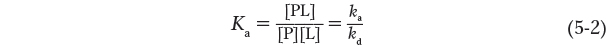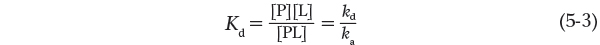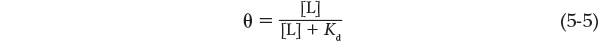Protein-Ligand Interactions Can Be Quantified
The function of many proteins depends on their ability not only to bind to a ligand but also to release the ligand when and where it is needed. Function in molecular biology often revolves around a reversible protein-ligand interaction of this type. A quantitative description of this interaction is therefore a central part of many investigations.
In general, the reversible binding of a protein (P) to a ligand (L) can be described by a simple equilibrium expression (Figure 5-1a):
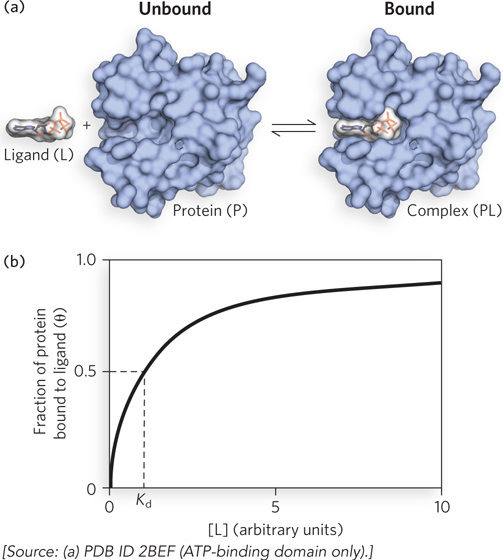
Figure 5-1: Ligand binding. (a) Reversible binding of a protein (P) to a ligand (L). The protein shown here is nucleoside diphosphate kinase and the ligand is ATP. (b) The fraction of ligand-binding sites occupied, θ, is plotted against the concentration of free ligand, [L]. A hypothetical binding curve is shown. The [L] at which half the available ligand-binding sites are occupied is equivalent to 1/Ka, or Kd. The curve has a horizontal asymptote at θ = 1 and a vertical asymptote (not shown) at [L] = −Kd.
The reaction is characterized by an equilibrium constant, Ka, such that:
where ka and kd are rate constants that describe, respectively, the rate of association and dissociation of the ligand and the protein. Ka is an association constant (not to be confused with the Ka that denotes an acid dissociation constant, described in Chapter 3). It describes the equilibrium between the complex and the separate, unbound components of the complex. The association constant provides a measure of the affinity of the ligand L for the protein P. Ka has units of m-1; a higher value of Ka corresponds to a higher affinity of the ligand for the protein.
It is more common (and intuitively simpler), however, to consider the dissociation constant, Kd, which is the reciprocal of Ka (Kd = 1/Ka) and is given in units of molar concentration (m). Kd is the equilibrium constant for the release of ligand. Note that a lower value of Kd corresponds to a higher affinity of ligand for the protein. The relevant expression changes to:
We can now consider the binding equilibrium from the standpoint of the fraction, θ (theta), of ligand-binding sites on the protein that are occupied by ligand:
Substituting Ka[P][L] for [PL] (see Equation 5-2) and rearranging terms gives:
Any equation of the form x = y/(y + z) describes a hyperbola, and θ is thus found to be a hyperbolic function of [L] (Figure 5-1b). The fraction of ligand-binding sites occupied approaches saturation asymptotically as [L] increases. The [L] at which half of the available ligand-binding sites are occupied (i.e., θ = 0.5) corresponds to the Kd: when [L] = Kd, half of the ligand-binding sites are occupied. As [L] falls below Kd, progressively less of the protein has ligand bound to it. For 90% of the available ligand-binding sites to be occupied, [L] must be nine times Kd.
The mathematics can be reduced to simple statements: Kd equals the molar concentration of ligand at which half the available ligand-binding sites are occupied. At this point, the protein is said to have reached half-saturation with respect to ligand binding. The more tightly a protein binds a ligand, the lower is the concentration of ligand required for half the binding sites to be occupied, and thus the lower the value of Kd. Some representative dissociation constants are given in Table 5-1, along with a range of such constants found in typical biological systems.

Figure 5-1: Protein Dissociation Constants
DNA-Binding Proteins Guide Genome Structure and Function
DNA-binding proteins are a key example of proteins that simply bind to a ligand (in this case DNA) reversibly without altering its covalent structure. DNA-binding proteins protect DNA, organize DNA, regulate genes or groups of genes, alter the conformation of DNA, facilitate all aspects of the metabolism of DNA, and ensure the proper segregation of chromosomes during cell division. DNA-binding proteins fall into two principal categories. Some bind to DNA nonspecifically, independent of DNA sequence; others recognize particular DNA sequences and bind tightly at the genomic locations where those sequences occur. The distinction is not absolute. “Nonspecific” DNA-binding proteins often display a measurable bias for binding of DNA sequences with particular features. “Specific” DNA-binding proteins generally exhibit some measurable (albeit much weaker) binding to nonspecific sequences (an example is the lactose repressor; see Table 5-1).
The binding of proteins to DNA, and thus the measured Kd of these interactions, is almost always sensitive to parameters such as pH and salt concentration. DNA is a polyelectrolyte (a polymer with multiple ionizable groups). In a cell, the negative charges of the phosphates in the DNA backbone are neutralized by interaction with counterions, and there is generally a high concentration of ions such as Mg2+ and K+ surrounding the DNA. As a protein binds to DNA some of these ions are released, and some bound water molecules are released from both the protein and the DNA as well. The release of ions and water has both positive and negative effects on the association of a protein with DNA. The positive effects come from a general gain in entropy (ΔS ≫ 0) as the water and ions are released. The negative effects reflect the energy of interactions between the water and ions and the macromolecules, interactions that must be eliminated to make the protein-DNA complex. Protein-DNA interactions are thus rarely as simple as the coming together of two complementary macromolecules. The interactions are affected in important ways by additional interactions of each macromolecule with water and with ions.
Two additional parameters are notable and are characteristic of interactions between proteins and nucleic acids. First, the number of nucleotides (in single-stranded DNA) or base pairs (in double-stranded DNA) that are occluded by the bound protein defines the binding site size, n. This parameter helps determine the number of binding sites on the DNA that might be available to a protein, and a knowledge of n for a particular protein is necessary for any complete description of its binding equilibrium. Second, some DNA-binding proteins, particularly certain proteins that bind to DNA nonspecifically, exhibit cooperativity in binding; that is, when one protein molecule binds to a nucleic acid, it facilitates the binding of another protein molecule. Cooperativity can also have important effects on binding equilibria.
The examples that follow focus on proteins with physical and structural properties that are particularly well studied.
Nonspecific DNA-Binding Proteins As we will discuss in Chapter 9, chromosomes are the largest macromolecules found in cells. If chromosomal DNA molecules were laid out linearly, they would typically be hundreds or even thousands of times longer than the cells in which they are housed. The protection and compaction of chromosomal DNA is largely the job of myriad nonspecific DNA-binding proteins found in every cell. These proteins also organize some key chromosomal functions, such as facilitating DNA replication and repair or guiding chromosomal segregation at cell division.
In most cases, nonspecific DNA-binding proteins exhibit only limited hydrogen-bonding interactions with bases in the DNA. Instead, electrostatic interactions with the negatively charged phosphate groups, hydrogen bonds to the backbone deoxyribose, and the nonspecific hydrophobic effect with the bases predominate, to varying degrees (Figure 5-2). The hydrophobic interactions often take the form of an aromatic amino acid side chain (Tyr, Trp, or Phe) intercalating between two adjacent bases.
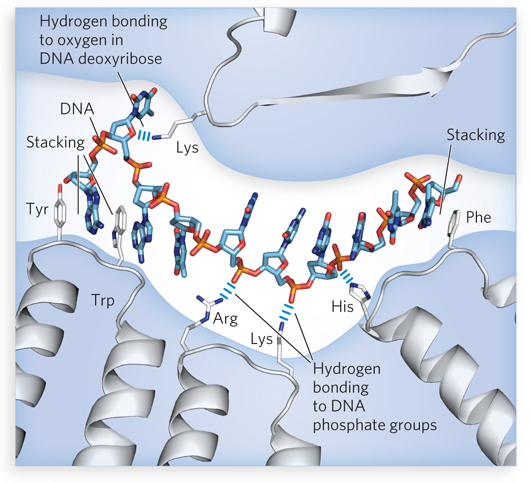
Figure 5-2: Nonspecific interactions of proteins with nucleic acids. Electrostatic interactions occur between proteins and the DNA backbone. The charged phosphate groups are exposed at the exterior surface of a single-stranded DNA molecule, where positively charged amino acid side chains (Arg, Lys, His) can interact. Hydrogen bonds occur between the protein and the deoxyribose groups in the DNA backbone. Hydrophobic interactions involving the intercalation of Tyr, Trp, or Phe side chains between two stacked bases are also prominent in many cases of nonspecific DNA-protein binding. Similar interactions occur with RNA.
An example of a nonspecific DNA-binding protein is the bacterial single-stranded DNA–binding protein (SSB). SSB binds and protects single-stranded DNA as it is transiently created during DNA replication and repair. The importance of this protein is illustrated by a simple observation: if SSB function is lost, the cell dies. The structure of the SSB from Escherichia coli is typical for bacteria, consisting of four identical subunits around which the single-stranded DNA wraps (Figure 5-3a). Each subunit contains one oligonucleotide/oligosaccharide-binding fold, or OB fold, a structural unit that often binds single-stranded DNA. The OB fold is common to all proteins in the SSB class (Figure 5-3b), as well as many others that associate with single-stranded DNA as part of their function.
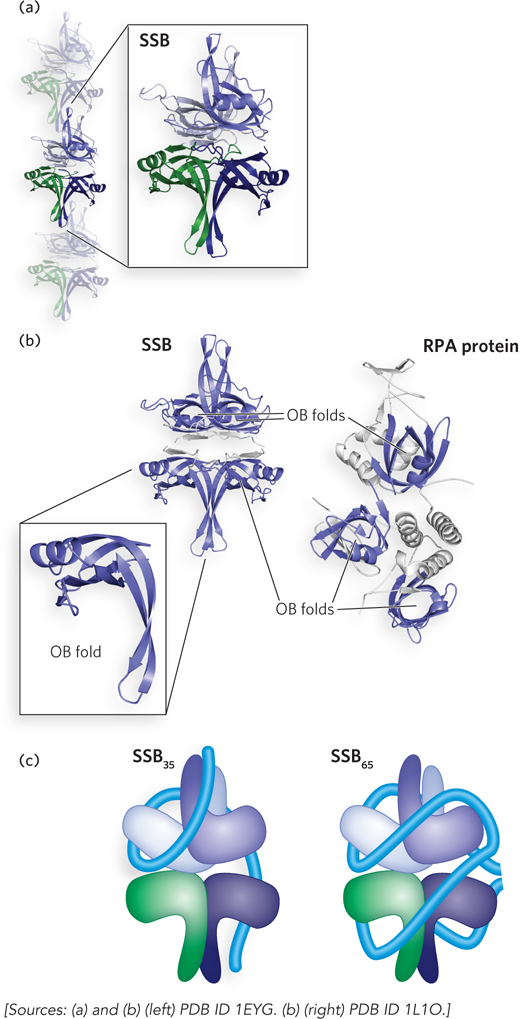
Figure 5-3: Binding of single-stranded DNA to single-stranded DNA–binding proteins. (a) Single-stranded DNA–binding protein (SSB) can bind in a filamentous form on single-stranded DNA. A single SSB tetramer is highlighted. (b) The key structural element that functions in single-stranded DNA binding is an OB fold. The basic fold consists of two three-stranded antiparallel β-sheets that share strand 1, with the strands ordered 1-2-3-5-4-1 (with the numbering coinciding to their order in the linear protein sequence). The sheets are tightly curved to form a small β-barrel, and an α-helix often connects strands 3 and 4. The structure can vary in appearance due to differences in lengths of the β-strands. The four OB folds in an SSB tetramer are highlighted in blue (left). The eukaryotic replication protein A (RPA) binds to single-stranded DNA in a similar fashion, using the OB folds in each subunit of the heterotrimer (right). (c) SSB can bind to single-stranded DNA in multiple binding modes, with the two most prominent modes shown in this schematic. The blue tube represents bound single-stranded DNA.
In addition to binding to single-stranded DNA, bacterial SSBs interact directly and reversibly with a range of other proteins in DNA metabolism. The E. coli SSB interacts with at least 15 different proteins (which we will encounter in Chapters 11–14), thereby helping to organize the functions of DNA replication and repair (Table 5-2) All of these interactions occur through a conserved C-terminus of SSB, a segment that features multiple negatively charged amino acid residues among the final eight to nine residues of the polypeptide.
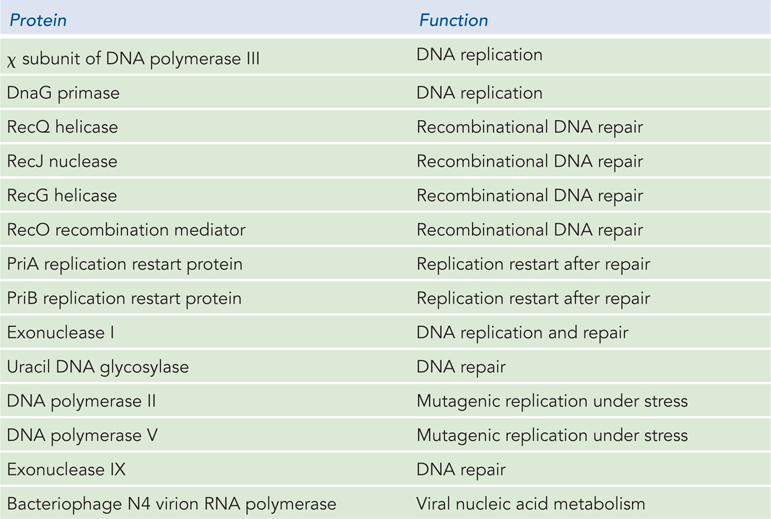
Figure 5-2: Proteins That Interact with Bacterial Single-Stranded DNA–Binding Protein
SSBs are found in every class of organism, and they always play essential roles in DNA metabolism. The eukaryotic SSB is called replication protein A (RPA). It consists of three different subunits (i.e., it is a heterotrimer) containing a total of six OB folds. Its function is quite similar to that of the bacterial SSBs, and it also interacts with a range of other proteins as part of its function in eukaryotic DNA metabolism.
In the test tube, the E. coli SSB binds to single-stranded DNA according to several different binding modes, depending on the concentrations of salt and protein. Two of these binding modes are notable. At relatively low concentrations of salt, SSB binds with a binding site size (n) of ∼35 nucleotides and with a very high degree of cooperativity between tetramers. In this mode, called SSB35, the single-stranded DNA is bound to two of the four subunits in each SSB tetramer (Figure 5-3c), and the tetramers are arranged on the DNA as a fairly regular filamentlike structure (see Figure 5-3a). When the salt concentration is higher, the SSB65 (n = 65 nucleotides) binding mode predominates. Here, the single-stranded DNA is wrapped around all four SSB subunits (see Figure 5-3c); the cooperativity between SSB tetramers is reduced, and filaments form less readily. The SSB binding modes affect SSB function and interactions with other proteins in vitro and presumably in vivo. In both cases, SSB binds to single-stranded DNA with a combination of electrostatic interactions with the phosphoribose backbone and intercalation of particular Trp and Phe side chains between adjacent DNA bases. The E. coli SSB binds tightly to single-stranded DNA, with measured Kd values generally in the range of 8 to 700 nM, depending on the solution conditions.
Many other proteins that bind to single-stranded or double-stranded DNA with little specificity also bind such that the DNA is wrapped or bent around the protein. For example, duplex DNA wraps tightly around the nucleosomes of eukaryotic chromosomes, as we will see in Chapter 10. Although the histone proteins that make up a nucleosome are considered nonspecific DNA-binding proteins, the positioning of nucleosomes on double-stranded DNA is not entirely random. In particular, DNA sequence elements that facilitate the bending or wrapping of double-stranded DNA around a protein, such as regions with several contiguous A = T base pairs, can have strong effects on the locations of bound nucleosomes along the DNA.
Specific DNA-Binding Proteins Proteins that bind with an enhanced affinity to particular DNA sequences are critical to the regulation of many processes in DNA metabolism. Many of these proteins regulate the expression of genes. Their affinity for specific target sequences is roughly 104 to 106 times their affinity for any other DNA sequence. Most regulatory proteins have discrete DNA-binding domains containing substructures that interact closely and specifically with the DNA. These binding domains usually include one or more of a relatively small group of recognizable and characteristic structural motifs (described in Chapter 4), often called binding motifs to reflect their function.
To bind to specific DNA sequences, regulatory proteins must recognize and distinguish surface features on the DNA. Most of the chemical groups that differ among the four bases and thus permit discrimination between base pairs are hydrogen-bond donor and acceptor groups exposed in the major groove of DNA. These interactions are illustrated by the binding of a eukaryotic regulatory protein with its DNA binding site (Figure 5-4). Most of the protein-DNA contacts that impart specificity are hydrogen bonds. A notable exception is the nonpolar surface near C-5 of thymine and cytosine, where the two are readily distinguishable by the protruding methyl group of thymine. Protein-DNA contacts are also possible in the minor groove of DNA, but the hydrogen-bonding patterns there generally do not allow ready discrimination between base pairs.
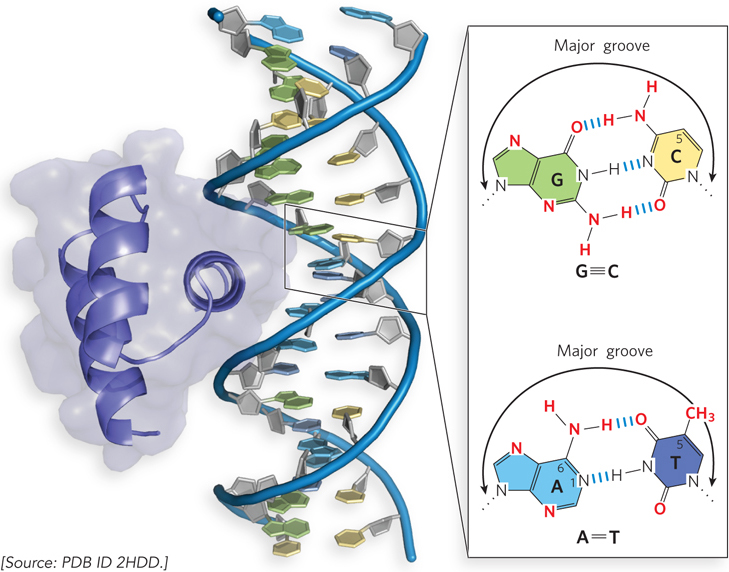
Figure 5-4: Groups in DNA that can guide specific protein binding. The eukaryotic DNA-binding protein called Engrailed interacts with the major groove of double-stranded DNA. Shown in the inset are functional groups on base pairs displayed in the major and minor grooves. Red indicates groups that can be used for base-pair recognition by proteins. Most specific binding is through interactions with the major groove.
In specific DNA-binding proteins, the amino acid side chains that most often hydrogen-bond to bases in the DNA are those of Asn, Gln, Glu, Lys, and Arg residues. Is there a simple recognition code in which a particular amino acid always pairs with a particular base? Two hydrogen bonds can form between Gln or Asn and the N6 and N-7 positions of adenine but not any other base. An Arg residue can form two hydrogen bonds with N-7 and O6 of guanine (Figure 5-5). However, examination of the structures of many DNA-binding proteins has revealed that the proteins can recognize each base pair in more than one way, leading to the conclusion that there is no simple amino acid–base code. For some proteins, the Gln-adenine interaction can specify A=T base pairs; for others, a van der Waals pocket for the methyl group of thymine can recognize A=T base pairs. As yet, researchers cannot examine the structure of a DNA-binding protein and predict the DNA sequence to which it binds.
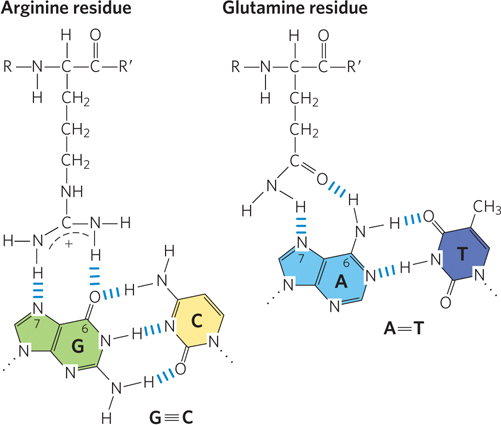
Figure 5-5: DNA-protein binding. Two examples of amino acid–base pair interactions that have been observed in DNA-protein binding. An asparagine residue can participate in the same type of interaction as the glutamine residue.
An example of a specific DNA-binding protein is the well-studied lactose (Lac) repressor of E. coli (see the How We Know section at the end of this chapter). This protein is part of a regulatory network that controls the expression of three consecutive genes in the E. coli chromosome, all of them involved in some aspect of lactose metabolism. The three genes are transcribed together in a unit described as an operon (Figure 5-6), and regulation of transcription occurs in and around a specific sequence, called the Lac operator, where the Lac repressor binds to the DNA. When the Lac repressor is bound to the Lac operator, transcription of the operon genes is blocked. The lactose operon is described in detail in Chapter 20, and we use the Lac repressor here simply to illustrate a common property of sequence-specific DNA-binding proteins. The DNA binding sites for regulatory proteins are often inverted repeats of a short DNA sequence, where multiple (usually at least two) subunits of a regulatory protein bind cooperatively. The Lac repressor functions as a tetramer, with two dimers tethered together at the end distant from the DNA-binding sites.
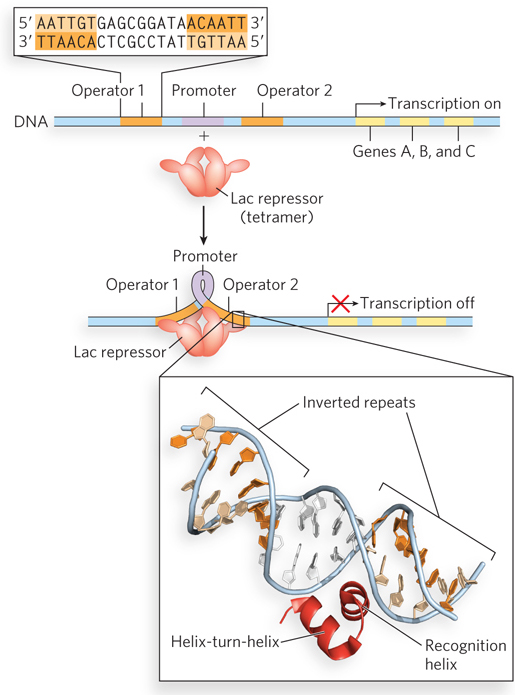
Figure 5-6: Simplified representation of the lac operon. When the Lac repressor is not bound to the operon’s promoter region, RNA polymerase binds to the promoter and transcribes several linked genes, here labeled A, B, and C. The Lac repressor binds to two operators on either side of the promoter to shut down transcription, apparently forming a loop in the DNA that prevents RNA polymerase from binding to the promoter. Each operator consists of an inverted repeat (top inset). The helix-turn-helix motif of the repressor protein binds specifically in the major groove of the operator recognition sequences (bottom inset). See Chapter 20 for a more in-depth discussion of the lac operon.
An E. coli cell usually contains about 20 tetramers of the Lac repressor protein. Each of the tethered dimers can independently bind to an operator sequence, in contact with 17 base pairs of a 22 base pair region in the lac operon (see Figure 5-6). The tetrameric Lac repressor binds to two proximal operator sequences in vivo with an estimated Kd of about 10−10 m. The repressor discriminates between the operators and other sequences by a factor of about 106, so binding to these few dozen base pairs among the 4.6 million or so of the E. coli chromosome is highly specific.
The Lac repressor interacts with DNA through a helix-turn-helix motif, a DNA-binding motif that is crucial to the interaction of many bacterial regulatory proteins with DNA; similar motifs occur in some eukaryotic regulatory proteins. The helix-turn-helix motif comprises about 20 amino acid residues in two short α-helical segments, each 7 to 9 residues long, separated by a β turn (Figure 5-6, bottom inset). This structure generally is not stable by itself; it is simply the functional portion of a somewhat larger DNA-binding domain. One of the two α-helical segments is called the recognition helix, because it usually contains many of the amino acid residues that interact with the DNA in a sequence-specific way. This α helix is stacked on other segments of the protein structure so that the helix protrudes from the protein surface.
One set of amino acid residues in the recognition helix of the Lac repressor’s helix-turn-helix domain participates in both nonspecific and specific interactions with DNA. The nonspecific interactions, even though they are weaker, usually occur first and play an important role in accelerating the search for the specific DNA binding site. In the nonspecific binding mode, these residues interact electrostatically with the DNA’s phosphoribose backbone (Figure 5-7). When bound to the specific recognition sequences in the Lac operator, the recognition helix is positioned in, or nearly in, the major groove. A network of specific hydrogen bonds and hydrophobic interactions governs the stability of this complex.
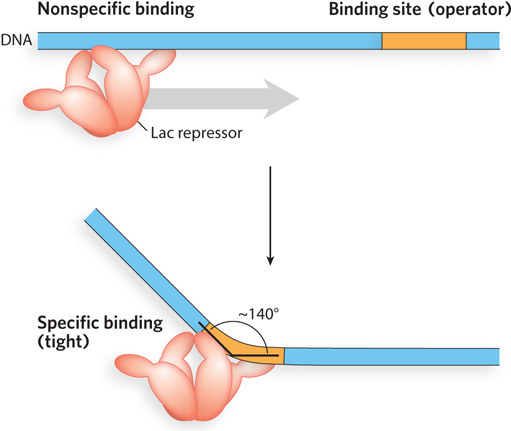
Figure 5-7: Nonspecific versus specific DNA binding. The Lac repressor interacts transiently and nonspecifically with the DNA phosphoribose backbone during the search for its specific DNA binding site. When the sequence of its normal binding site is located, the repressor interacts specifically with the nucleotide bases in that site. Binding results in bending of the DNA.
There are many proteins that bind to specific sequences in a nucleic acid, and we will encounter numerous examples of these in later chapters.
SECTION 5.1 SUMMARY
Many proteins bind reversibly to other molecules, known as ligands. Ligand binding often involves protein conformational changes, in the process of induced fit.
Ligand binding can be quantified, and the key parameter is the dissociation constant, Kd, which is the concentration of ligand at which half of the protein’s binding sites are occupied by ligand. A lower Kd corresponds to higher affinity for (tighter binding to) the ligand.
A DNA- or RNA-binding protein may bind to a nucleic acid either nonspecifically or in a sequence-dependent manner. Nonspecific binding usually involves interactions with the phosphoribose backbone of the nucleic acid. Specific DNA or RNA binding requires an interaction of amino acid side chains in the protein with functional groups in the nucleic acid bases, especially those exposed in the major groove of DNA.