Transposition Takes Place by Three Major Pathways
Transposition mechanisms are summarized in Figure 14-10. Some transposons move by a simple cut-and-paste mechanism. The element is completely excised from the donor DNA and then inserted into a target site. In an alternative, replicative pathway, the transposon is joined to the target site before it is completely excised from the donor DNA. Replication then creates two complete copies of the element, one in the donor site and one in the target site. Elements that make use of either of these pathways are sometimes simply referred to as DNA transposons. A third pathway uses an RNA intermediate to copy the element and insert the copy at a second, target site; these elements are referred to as retrotransposons. At least one phosphoryl transfer reaction in which a free 3′-hydroxyl group at the end of a transposon attacks a phosphodiester in genomic DNA is a feature of all three pathways. Hydrolytic cleavage of phosphodiester bonds (phosphoryl transfer to water; see Figure 14-1) is also a key reaction, often occurring to generate the free 3′ end.
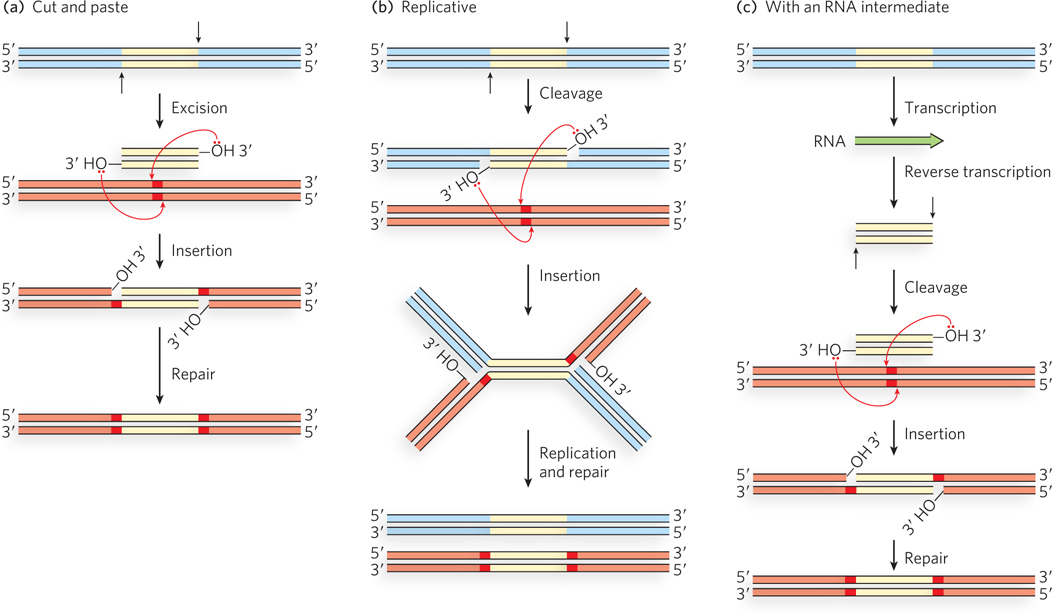
Figure 14-10: Three general transposition pathways. (a) Cut-and-paste transposition leaves behind a broken chromosome (double-strand break) that must be repaired. The excised transposon inserts itself into another chromosome at a new location. (b) Replicative transposition leaves a copy of the transposon at the original site, as does (c) transposition that uses an RNA intermediate.
The basic transposition systems consist of the transposable DNA element and an enzyme, a transposase, usually encoded by a gene within the transposable element. The transposable element is present at one location in a genome, part of the contiguous genomic DNA, and moves to a new location. The reactions do not involve the formation of covalent intermediates between the transposase and the DNA. Instead, the transposase catalyzes the two key reactions mentioned above, in succession: hydrolysis of a phosphodiester bond at the end of the transposable element, then attack of the liberated 3′ hydroxyl on another phosphodiester bond in a transesterification reaction (Figure 14-11). The reactions generally leave behind breaks or gaps in the genomic DNA strands at the original site of the transposable element, which must be repaired by the cell. The two-reaction sequence during transposition occurs at both ends of the transposable element. Thus, two liberated 3′-hydroxyl groups attack phosphodiester bonds at the new genomic location (the target site), inserting into each strand of the target. The insertion sites on each strand of the target are offset, or staggered. The immediate product of the transesterifications is the transposable element linked to genomic DNA at both ends at the new location, but with short single-strand gaps at each end. The gaps are filled in by DNA polymerase and ligase to create short repeated sequences at each end of the inserted transposon (the dark red DNA segments in Figure 14-10).
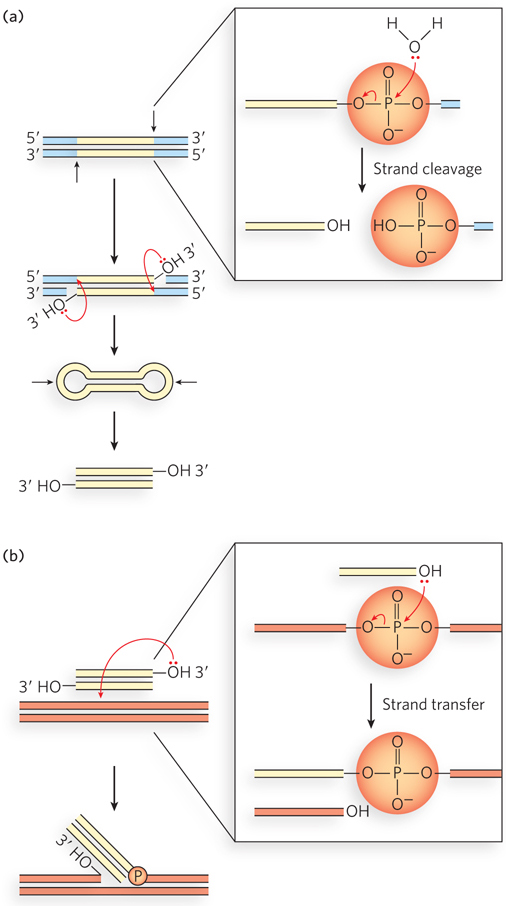
Figure 14-11: Hydrolytic cleavage and a transesterification reaction involved in transpositions. These are the reactions promoted by integrases and transposases. In both (a) and (b), the left side shows the fate of the DNA, and the right side shows reaction details. (a) The first step in transposition is usually the attack of a water molecule on a phosphodiester bond at each end of the transposon to create free 3′ ends. This creates a nick in one DNA strand at each transposon end, but the other DNA strand remains intact. The additional steps illustrate the reactions that complete the excision of the transposon in cut-and-paste transposition. The transposase catalyzes attack of each liberated 3′ hydroxyl on a phosphodiester bond in the complementary strand, immediately opposite. The transposon is fully excised, with its ends structured as closed hairpin loops, and a double-strand break is left in the DNA where the transposon originated. The closed hairpin loops are opened by yet another hydrolytic cleavage of a phosphodiester bond, again catalyzed by the transposase. (b) The 3′-OH thus liberated acts as a nucleophile, attacking another phosphodiester bond in the target DNA. The attacked bond is cleaved, and a new bond is created.
In cut-and-paste transposition, the transposon is completely excised by double-strand cuts on each side, and the transposon moves to a new location (Figure 14-12a). This leaves a double-strand break in the donor DNA that must be repaired. The mechanism used by the well-characterized bacterial transposon Tn5 illustrates some additional details. Prior to the cleavage reaction, transposases bound to each end of the transposon come together to form a complex. Each transposase subunit catalyzes phosphodiester bond cleavage at one end of the transposon, generating a free 3′ end. Each of the 3′ hydroxyls then makes a nucleophilic attack on a phosphodiester bond in the complementary strand immediately across from it. Both strands are thus cleaved, and the transposon is excised along with the DNA at both ends in the form of a closed hairpin loop. Next, the transposase catalyzes the hydrolysis of a phosphodiester bond at each end, again creating free 3′-hydroxyl groups, and then the attack of these free 3′ hydroxyls on phosphodiester bonds in each strand at a new genomic location, thus inserting the transposon at the target site. The insertion points on the two strands of the target DNA are offset, as mentioned earlier, leaving single-strand gaps in the target DNA at each end of the transposon. Repair of these gaps results in the duplication of a short target-derived DNA sequence at either end of the inserted element. The cleaved donor DNA from which the transposon was originally excised is repaired by ligation or recombinational DNA repair (see Chapter 13), or in some cases it is simply degraded.
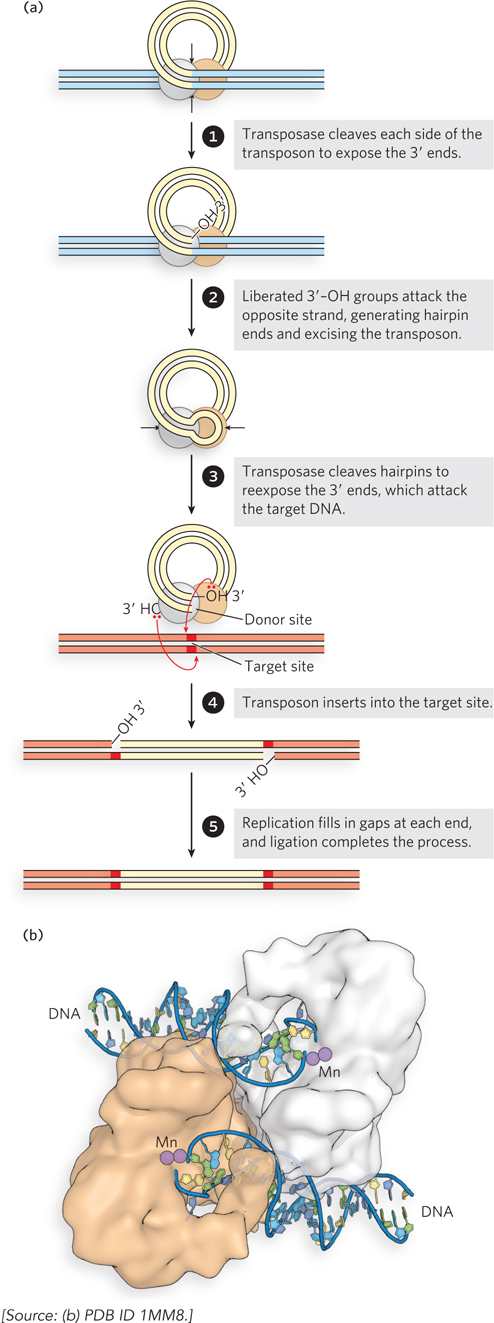
Figure 14-12: Cut-and-paste transposition. (a) The transposition steps. (b) Structure of the Tn5 transposase, bound to cleaved transposon ends. The manganese (Mn) ions (present during crystallization) are bound where the Mg2+ ions would bind in the normal reaction.
The use of three successive phosphoryl transfer reactions to effect a double-strand break at each end of the transposon might seem overly elaborate, until we consider the economy involved. One transposase active site at each end of the transposon catalyzes all three phosphoryl group transfers, effectively cleaving two DNA strands of opposite polarity to excise the element from the donor DNA. The hairpin ends are transient intermediates, which researchers have detected in several well-studied transposition reactions. The hairpin intermediate is unique to transposons and similar systems requiring the cleavage of both strands at an element end. The steps following excision of the transposon are more broadly observed in virtually all transposon systems.
At the end of the transposon excision process, the transposase active sites at each end are poised to catalyze yet a fourth phosphoryl transfer, to insert the transposon into a new genomic site. The attack of the 3′ hydroxyl at the end of one strand on a phosphodiester bond in a contiguous DNA molecule is sometimes called strand transfer, as the phosphoryl group becomes joined to a new strand. Figure 14-12b shows the structure of the Tn5 transposase bound to transposon ends, ready to promote two staggered strand transfer reactions in the complementary DNA strands at the target site (see Figure 14-12a, step 4). The type of complex produced at the end of the cut-and-paste process illustrated in Figure 14-12a is broadly representative of that used in the strand transfer reactions discussed in the rest of this chapter.
In replicative transposition (Figure 14-13), the transposon ends are again brought together in a complex with the transposase, but only one strand is cleaved at each end of the transposon DNA to create nicks and initiate the process. The cleavage exposes the 3′ end of each transposon DNA strand, and these 3′ ends are then used as nucleophiles in two strand transfers to insert the transposon at a DNA target site in the same or a different DNA molecule. The two strand transfers occur on different DNA strands in the target, staggered a few base pairs apart. This creates a rather complex intermediate, with DNA branches at either end of the transposon. The strand transfers create free 3′ ends in the target DNA, and these are used to prime replication of both strands of the entire transposon. The replication gives rise to an intermediate called a cointegrate. Since the strand transfers were staggered, the replication fills in a short repeated sequence derived from the target DNA at each end of the transposon. In a cointegrate, the DNA from the donor region where the transposon originated is covalently linked to DNA at the target site to which the transposon is moving. Most important, two complete copies of the transposon are present in the cointegrate, both having the same relative orientation in the DNA. If the target site is in a different DNA molecule (plasmid or chromosome), the DNAs harboring the transposons in the donor and target sites are linked together in the cointegrate. In some well-characterized transposons, such as the bacterial Tn3, this cointegrate is resolved in a process through which the two DNAs are separated by site-specific recombination in which specialized recombinases promote the required deletion reaction. Completion of the reaction installs the transposon at the target site while leaving a copy behind at the donor location.
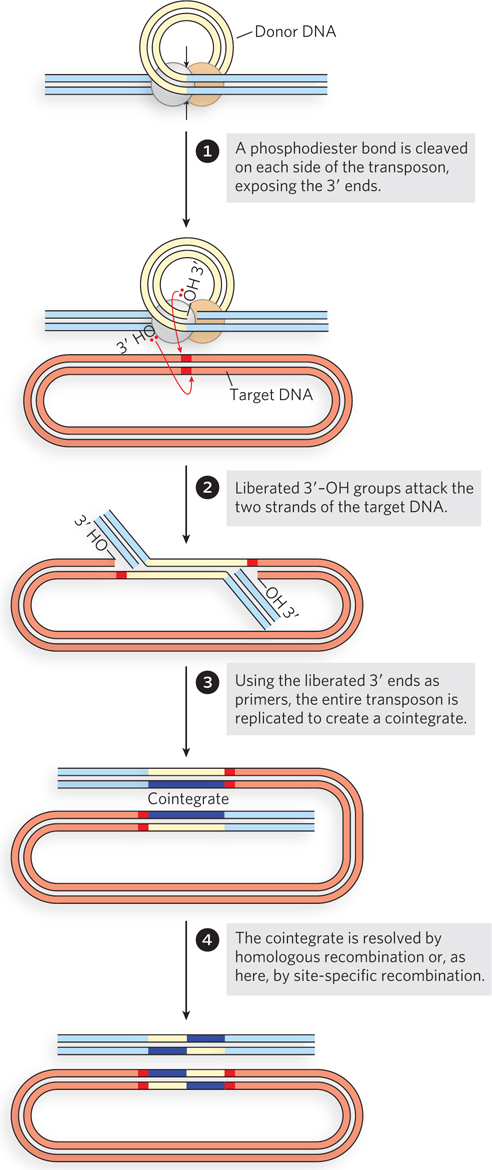
Figure 14-13: Replicative transposition. Only one strand at each end of the transposon is cleaved and transferred to the target site in the early steps. The liberated 3′ ends in the target site are used to prime DNA replication of both DNA strands in the transposon, creating two copies of it.
Transposons that produce an RNA intermediate in the process of transposition are called retrotransposable elements, or retrotransposons. These transposons can be classified according to the presence or absence of long terminal repeat (LTR) sequences at their termini. The terminal repeats range from about 100 bp to more than 5,000 bp and generally include binding sites for enzymes that function in the transposition process. Both LTR and non-LTR retrotransposons are widely dispersed, particularly in eukaryotic organisms.
The retrotransposon DNA is first transcribed by an RNA polymerase to create a single-stranded RNA transcript. The transcript is then converted into double-stranded DNA. The conversion uses a specialized enzyme encoded by the retrotransposon, called reverse transcriptase. Reverse transcriptase is a DNA polymerase that can use either RNA or DNA as a template, and the conversion to DNA occurs in two major steps (Figure 14-14). The RNA intermediate is first used as a template to generate a complementary DNA strand, forming an RNA-DNA hybrid duplex. The DNA strand of the duplex is then used as a template in the second step to generate a complementary DNA strand and a complete double-stranded DNA. The RNA strand is degraded during this second step by a ribonuclease H (RNase H) activity that is present either as a distinct functional domain of the reverse transcriptase or as a separate enzyme. RNase H is a class of nonspecific ribonuclease enzymes found in nearly all organisms.
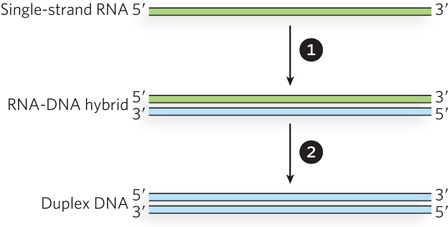
Figure 14-14: Reactions catalyzed by reverse transcriptase. A single strand of RNA is first converted to an RNA-DNA hybrid, using the RNA as a template to generate a complementary DNA strand. The RNA strand is then displaced (and eventually degraded) as the DNA strand is used as a template to generate a complementary DNA strand. Duplex DNA is the final product. The sources of the primers used to initiate DNA synthesis in each step are not shown.
The polymerization mechanism used by reverse transcriptase is largely identical to the one used by DNA polymerase (see Chapter 11), and DNA synthesis proceeds in the same 5′→3′ direction. Like DNA polymerase, reverse transcriptase adds nucleotides to a primer but cannot initiate DNA synthesis de novo.

Marlene Belfort
In addition to their distinct structures, LTR and non-LTR retrotransposons have different mechanisms of propagation that use primers from different sources, as proposed by Marlene Belfort and her colleagues. For LTR retrotransposons, the priming occurs on the free single-stranded RNA after the retrotransposon DNA is transcribed. These extrachromosomally primed (EP) retrotransposons borrow some aspects of both cut-and-paste and replicative transposition systems (Figure 14-15a). First, a sequence at one end of the LTR retrotransposon (a promoter) directs transcription of the transposon DNA into RNA. (The process of transcription, promoted by RNA polymerases, is described in Chapter 15.) The resulting single strand of RNA is identical in sequence to one of the two strands of the transposon (with U replacing T). Reverse transcriptase, encoded by the retrotransposon, uses the new RNA strand as a template to synthesize a complementary strand of DNA in two steps, as shown in Figure 14-14. The primer for DNA synthesis is often a cellular tRNA with a 3′ end that is complementary to, and anneals to, the retrotransposon RNA. Once the DNA strand is completed, reverse transcriptase uses this strand to generate a DNA complement (the source of primer for this synthesis also varies), resulting in a double-stranded DNA fragment that represents a complete copy of the transposon. Another enzyme, integrase, catalyzes insertion of this free DNA transposon copy into a DNA target site. The integrase is related to certain transposases, and it uses the 3′ ends of the transposon to attack phosphodiester bonds in the target in the same kind of strand transfer process we have seen in cut-and-paste and replicative transposition systems. DNA gaps left at the ends of the inserted transposon are again repaired by host replication and ligation enzymes, leading to the generation of short sequences repeated at both ends.
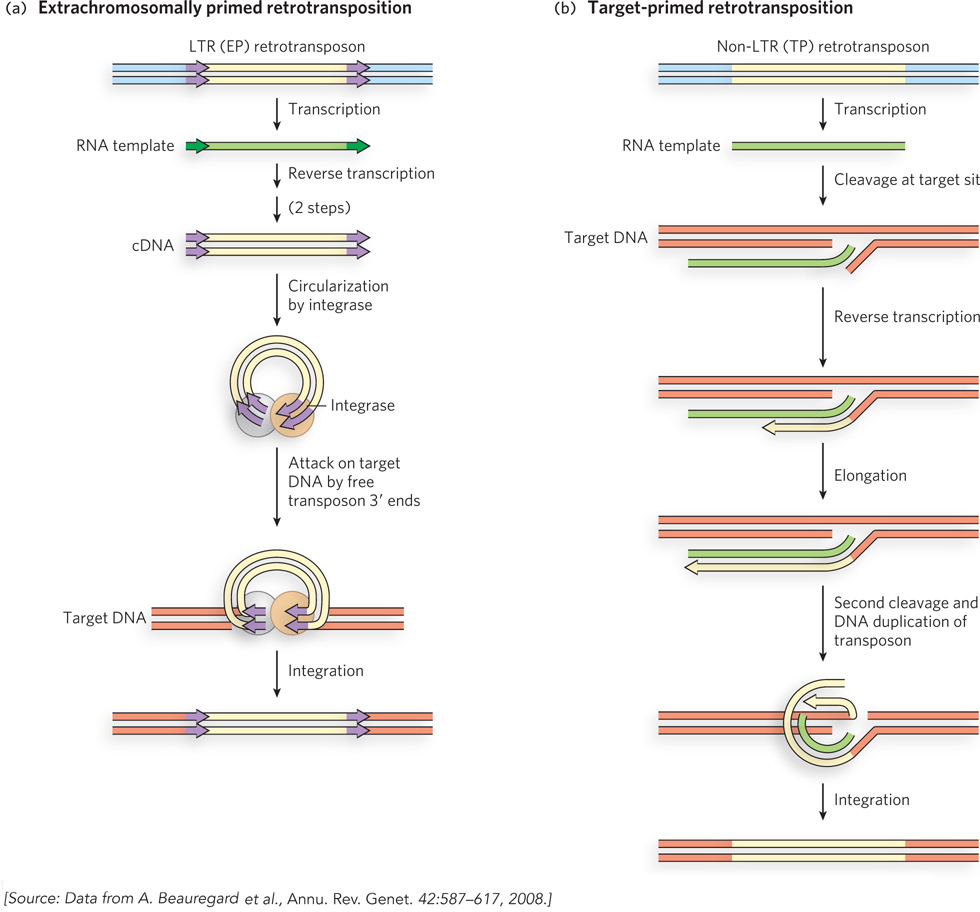
Figure 14-15: Retrotransposition. (a) In extrachromosomally primed (EP) retrotransposition, a tRNA or other RNA that can anneal to the transposon RNA is used as a primer for reverse transcription of the RNA to create a double-stranded DNA fragment, in two steps. This DNA fragment inserts itself into a DNA target site, as in cut-and-paste transposition. (b) In target-primed (TP) retrotransposition, the RNA migrates to the target site, where a phosphodiester bond is cleaved hydrolytically. The exposed 3′ end is used to prime reverse transcription of the RNA, which is again converted to double-stranded DNA in two steps. The insertion is completed by ligation.
In the case of non-LTR retrotransposons, the RNA intermediate is brought to and sometimes linked to the DNA target site by an enzyme encoded by the retrotransposon itself, before the reverse transcriptase reaction (Figure 14-15b). The enzyme makes a cut in one strand of the target DNA and uses the liberated 3′ end as the primer for DNA synthesis. These non-LTR elements are sometimes called target-primed (TP) retrotransposons. A second cut liberates a primer for synthesis of the second DNA strand, a process coupled to elimination of the RNA strand. The product is a double-stranded DNA transposon joined to the target site.
Bacteria Have Three Common Classes of Transposons
Most of the transposons found in bacteria make use of transposition pathways that do not have RNA intermediates. Bacterial transposons are broadly classified as insertion sequences, composite transposons, or complex transposons (Figure 14-16).
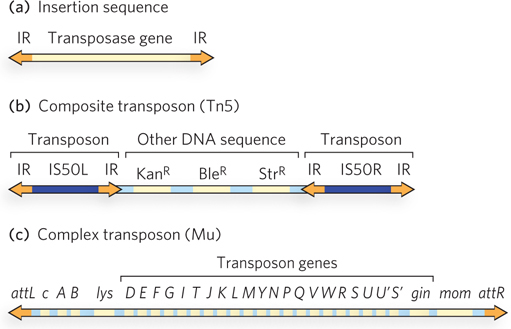
Figure 14-16: Three types of bacterial transposons. (a) Insertion sequences (IS elements) are the simplest transposons, consisting of a transposase-encoding gene and a transposase-binding site within the inverted repeat (IR) sequence at either end. (b) Composite transposons usually consist of two IS elements flanking some additional genes. The transposon Tn5, with two IS50 elements flanking three genes specifying antibiotic resistance, is an example. (c) Complex transposons contain genes, in addition to the transposase gene, that are required for general maintenance. An example is bacteriophage Mu, which can function as either a very efficient transposon or a bacteriophage; attL and attR are the transposase-binding sites.
Insertion sequences (also called IS elements) are simple transposons that contain only the sequences required for transposition and the genes for the proteins (transposases) that carry out the transposition. Composite transposons contain one or more genes in addition to those needed for transposition. These extra genes might, for example, confer antibiotic resistance, thereby enhancing the survival chances of the host cell. Indeed, transposition contributes substantially to the spread of antibiotic-resistance elements among pathogenic bacterial populations, which is rendering some antibiotics ineffective (see Highlight 9-1). Complex transposons often have larger genomes and include genes for auxiliary proteins that activate or otherwise assist the transposase, and even some enzymes that promote processes other than transposition. Some complex transposons bridge the distinction between viruses and transposons, exhibiting a capacity not only to transpose within a cell but to migrate as viruses between different cells. A bacteriophage called Mu is one example.
Many hundreds of distinct insertion sequences have been identified in bacteria. Some of these are found in many different species, demonstrating a capacity to cross species lines. The interspecies transfer might happen, for example, on rare occasions when a bacterium dies and pieces of its degraded DNA are taken up at random by another bacterial species. Most insertion sequences transpose by a cut-and-paste mechanism, but a few use replicative transposition. Closely related insertion sequences can be organized into subgroups or families. The IS3, IS4, and IS5 families are particularly widespread.
Composite transposons typically consist of two insertion sequences flanking several other genes. An example is the transposon Tn5, which has two IS elements called IS50 (found elsewhere in bacteria as simple insertion sequences) flanking a group of genes conferring resistance to the antibiotics kanamycin, bleomycin, and streptomycin (Figure 14-16b). Only the outer end of each IS50 element functions in transposition, such that the entire composite transposon is moved by cut and paste.
Complex transposons exhibit the most variety among the bacterial elements. Several, including bacteriophage Mu (Figure 14-16c), have been studied in some detail (see the How We Know section at the end of this chapter). Mu has a 37 kbp genome. Like bacteriophage P1, its life cycle features both lysogenic and lytic pathways. When Mu infects a bacterial cell, a copy of its genome is generally inserted into a random site in the chromosome, probably by cut and paste, and can be replicated passively there. To promote lysis of the cell, the bacteriophage DNA not only is replicated to produce new phage particles but also undergoes rapid transposition to additional random sites in the host chromosome by replicative transposition. The insertion of Mu DNA into random sites in the chromosome can create mutations, often inactivating host genes (Mu is for mutator.)
Retrotransposons Are Especially Common in Eukaryotes
Eukaryotic DNA transposons are structurally similar to bacterial transposons, and they migrate by a cut-and-paste mechanism. Retrotransposons are much more richly represented in eukaryotes than are other types of transposons. In the human genome, more than 46% of the DNA in each cell consists of transposon sequences. More than 90% of that transposon DNA comes from retrotransposons. Of all the retrotransposons in the human genome, just over 20% are LTR retrotransposons (about 8% of the human genome) and the remainder are non-LTR. We consider first the DNA transposons that use the simple cut-and-paste mechanism, then the elements that utilize an RNA intermediate.
Eukaryotic Cut-and-Paste Transposons Transposons of the Tc1/mariner family are possibly the most phylogenetically widespread transposons in nature, found in eukaryotes ranging from fungi to plants to humans. First discovered in the early 1980s in the nematode worm Caenorhabditis elegans (Tc is derived from transposon Caenorhabditis), the family acquired the mariner moniker as the ubiquitous presence of these transposons became evident—mariner was the name first attached to one of these transposons discovered in Drosophila. The Tc1/mariner elements transpose by a cut-and-paste mechanism and are closely related to the bacterial transposon family IS630.
The transposable elements in this family are 1,300 to 2,400 bp long, and each contains a gene encoding a transposase. Active Tc1/mariner transposons can move about the cellular genomes of just about any species. However, few of them are active (capable of transposition), due to mutations in the transposase genes. When active, transposons of this family jump into other DNA sites more or less randomly, so the potential for disruption and inactivation of essential host genes is considerable. Transposons that have successfully made the jump into a particular genome have either undergone selection to prevent further transposition or are subject to cellular silencing mechanisms that prevent transposition. Genetic engineering has been used to reactivate transposons of this family, for use in genetic research (Highlight 14-2).
HIGHLIGHT 14-2 EVOLUTION: Awakening Sleeping Beauty
After a transposon successfully integrates into a genome, evolution tends to favor inactivation of the transposase, preventing further transposition and its possible detrimental effects on the host. Thus, virtually all cut-and-paste transposons found in vertebrates are inactive. For a geneticist, this is not always a good thing. Many transposons, with their capacity to integrate into chromosomal sites more or less at random, have the potential to disrupt and thereby inactivate genes at random. Researchers can use this property to create libraries in which each individual organism has one gene inactivated, allowing broad explorations of gene function. To realize this potential, however, the transposons must be made to hop once again. Can these sleeping transposons be awakened?
The answer is clearly yes. Ronald Plasterk, Zsuzanna Izsvak, and their colleagues creatively used genomics to peer back into evolutionary time and deduce the structure of an active transposase. Beginning with a set of related Tc1/mariner elements from fish, the researchers carefully compared the sequences of the embedded and inactive transposase genes (Figure 1). Reasoning that the mutations inactivating the transposon would be different in different species of fish, they used a majority-rule kind of analysis: if a particular sequence was present in most of the transposable elements, it was likely to be the original functional sequence in the original active transposon. Sequences unique to one or a few elements were likely to represent the inactivating changes. Once the research group had established a consensus sequence for a putative active element, they began reconstructing it. Alterations were introduced into one of the inactive genes to make it identical to the consensus.
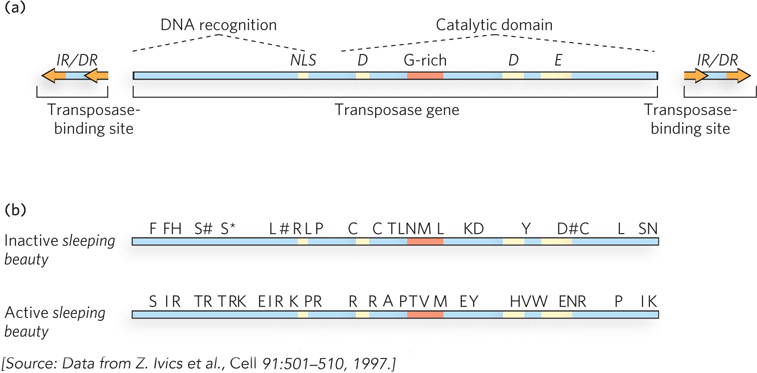
FIGURE 1 Reconstruction of an active Tc1/mariner transposase gene led to creation of the engineered transposon sleeping beauty. (a) The structure of an active Tc1/mariner element. (b) Amino acids that were changed to make sleeping beauty active again. The asterisk denotes a stop codon, and pound signs denote frameshift mutations.
The scheme was completely successful. The engineered transposon was highly active, not just in fish but in a wide range of eukaryotic cells, including human cells. The new element was dubbed sleeping beauty, an apt name for an element awakened from a transposon that had probably been dormant for millennia. Researchers continue to study sleeping beauty to learn more about Tc1/mariner transposition mechanisms, and it is increasingly used as a tool to mutagenize genes in many different organisms. For example, the introduction of sleeping beauty into the mouse genome leads to pups that rapidly develop tumors because of inactivation of genes controlling cell division. Particular types of tumors can be screened to identify the genes in which the engineered transposon is inserted, and a list generated of all the genes that, when inactivated, produce particular tumor types.
Eukaryotic Retrotransposons Both the LTR (extrachromosomally primed) and non-LTR (target-primed) retrotransposon classes are abundant in eukaryotes. Among the LTR retrotransposons are several different Ty elements of S. cerevisiae and the element gypsy of Drosophila. Non-LTR retrotransposons include elements classified as LINEs (long interspersed nuclear elements) and SINEs (short interspersed nuclear elements), along with certain types of introns.
LTR retrotransposons are very closely related to the retroviruses, discussed shortly. Transposition of these elements is illustrated by the Ty transposition cycle (Figure 14-17). A Ty element, integrated in the DNA chromosome of the host cell, is transcribed to produce a single-stranded mRNA molecule with the poly(A) tail characteristic of eukaryotic mRNAs (as described in Chapter 16). The mRNA is transported from the nucleus to the cytoplasm, where it is translated to produce several Ty proteins, including reverse transcriptase (Pol), integrase (Int), and a structural protein called Gag. The mRNA is encapsulated in a viruslike particle (VLP), where reverse transcriptase catalyzes formation of a complementary linear, double-stranded DNA, in two steps. The DNA is transported back into the nucleus with the aid of the VLP. Inside the nucleus, the VLP’s outer shell, consisting of Gag protein, is shed, and integrase inserts the duplex DNA into the host chromosome at a new location. Almost every step is aided by one or more proteins encoded by the host cell.
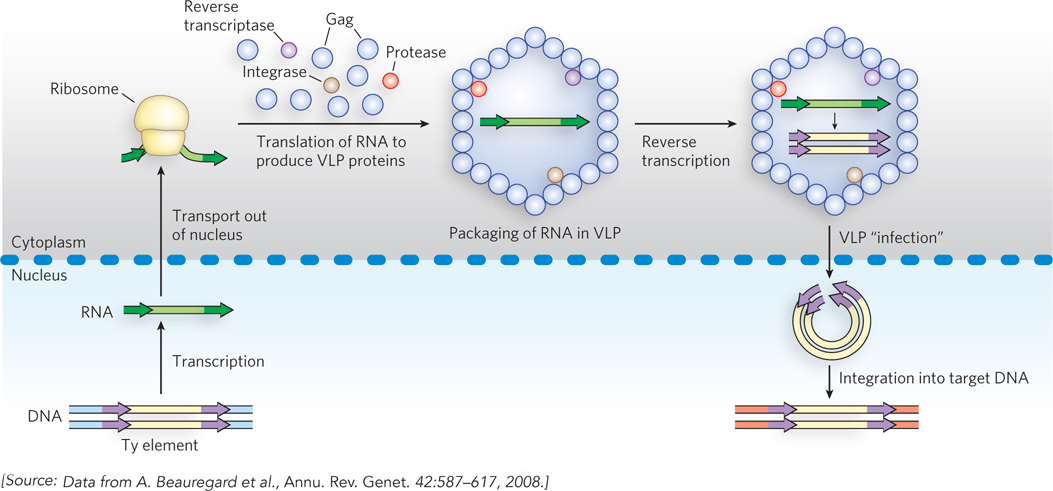
Figure 14-17: Retrotransposition by a Ty element in yeast. The Ty element, within the host DNA, is transcribed to produce an mRNA, which is transported to the cell cytoplasm and translated to produce a polyprotein (pol) that is cleaved to generate a protease, reverse transcriptase, integrase, and Gag (a structural protein). Within the viruslike particle (VLP), reverse transcriptase converts the RNA to double-stranded DNA. The VLP is transported back into the nucleus, the Gag protein coat is shed, and the DNA transposon is integrated into a new target site in the host chromosome.
The non-LTR retrotransposons also rely on reverse transcriptase, but the transposition pathways vary. LINEs and SINEs are the most common types of transposons in the human genome. Prominent in all mammalian genomes, they also occur in other classes of eukaryotes and have played important roles in genomic evolution. The most common human LINE is L1, approximately 6,000 bp long. Present in about 520,000 copies, L1 elements account for about 17% of the entire human genome. A LINE element is first transcribed to mRNA in the nucleus. The mRNA is transported to the cytoplasm, where it is translated to produce two proteins: one that has both reverse transcriptase and endonuclease functions, and another that helps form a ribonucleoprotein complex important to several steps in the cycle. The ribonucleoprotein complex is transported into the nucleus, where the RNA is converted to duplex DNA by reverse transcriptase and integrated into the genomic DNA, as described for all non-LTR (TP) retrotransposons above.
LINE transposition occurs primarily in germ-line cells, using enzymes encoded by the LINE. A LINE is defined as an autonomous element, as it encodes the main enzymes needed for its transposition. The transposition cycle of SINEs (<500 bp long) is similar, with one significant difference: SINEs lack the genes needed to code for their own transposition and must rely on enzymes encoded by LINEs. When a transposon relies on enzymes encoded by other elements in this way, it is said to be a nonautonomous element.
Retrotransposons and Retroviruses Are Closely Related
Retroviruses are RNA viruses that contain reverse transcriptase. Most retroviruses infect animal cells. On infection, the virus’s single-stranded RNA genome (∼10,000 nucleotides), along with molecules of reverse transcriptase carried in the viral particle, enters the host cell. The reverse transcriptase converts the viral RNA to double-stranded DNA (Figure 14-18). The resulting viral DNA often becomes incorporated into the genome of the eukaryotic host cell. These integrated (and dormant) viral genes can be activated and transcribed, and the gene products—viral proteins and the viral RNA genome—are packaged as new viruses.
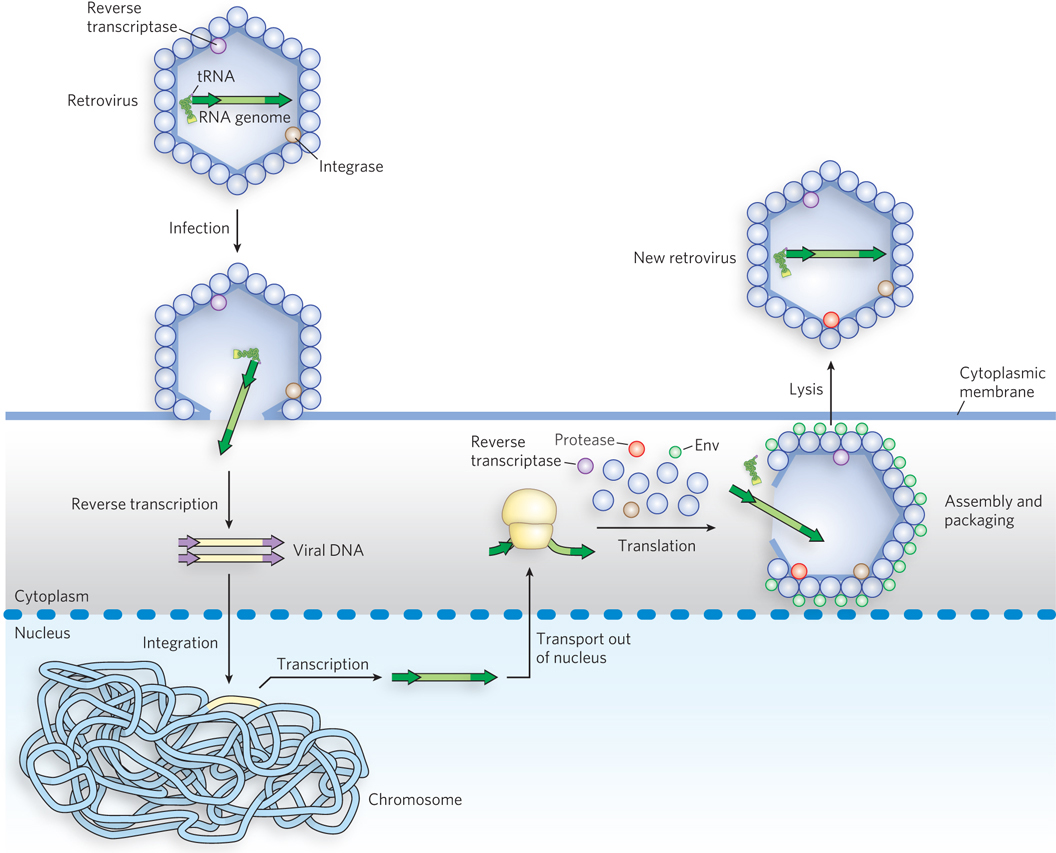
Figure 14-18: Retroviral infection of a mammalian cell. Viral particles entering the host cell (left) carry reverse transcriptase and a cellular tRNA (from a previous host) already base-paired to the retroviral RNA. The tRNA facilitates immediate conversion of the RNA to double-stranded DNA by the action of reverse transcriptase. The DNA enters the nucleus and is integrated into the host genome, a process catalyzed by a virally encoded integrase. On transcription and translation of the viral DNA, new viruses are formed and released by cell lysis (right).

Howard Temin, 1934–1994
The idea that biological information could flow from RNA to DNA in the retroviral life cycle was predicted by Howard Temin in 1962. The enzyme that promotes this reaction, reverse transcriptase, was ultimately detected by Temin and, independently, by David Baltimore in 1970. This discovery aroused much attention as dogma-shaking proof that genetic information can flow “backward,” from RNA to DNA.

David Baltimore
Retroviruses typically have three genes: gag, pol, and env (Figure 14-19). (The name gag is from the historical designation group-specific antigen.) In a sense, the retrovirus is simply a retrotransposon, with one additional gene, env, which encodes the proteins of the viral envelope. The additional gene is critical because it gives the element the capacity to move from cell to cell instead of just within a genome. The transcript (mRNA) that contains gag and pol is translated into a long polyprotein. This single large polypeptide is cleaved into six proteins with distinct functions. The proteins derived from the gag gene make up the interior core of the viral particle. The pol gene encodes a protease that cleaves the polyprotein, an integrase that inserts the viral DNA into the host chromosome, and reverse transcriptase. Many reverse transcriptases have two subunits, a and b. The pol gene specifies the b subunit (Mr 90,000), and the a subunit (Mr 65,000) is simply a proteolytic fragment of the b subunit. At each end of the retrovirus’s linear RNA genome are LTR sequences of a few hundred nucleotides, analogous to the LTR sequences found at the ends of LTR retrotransposons. Transcribed into double-stranded DNA, these sequences facilitate integration of the viral chromosome into the host DNA and contain promoters for viral gene expression.
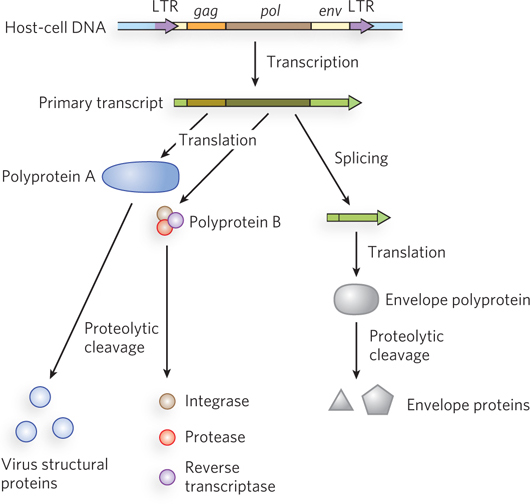
Figure 14-19: The structure and gene products of an integrated retroviral genome. The retroviral RNA genome is flanked by long terminal repeats (LTRs), which contain sequences needed for the regulation and initiation of transcription. The primary retroviral transcript encompasses the gag, pol, and env genes as well as sequences on either side of those genes. Translation of the primary transcript yields two different polyproteins. One is derived only from the gag gene, and this polyprotein is cleaved into three different proteins that make up the viral core, matrix, and capsid. The second polyprotein, generated at lower levels, is derived from the gag and pol genes. This polyprotein is cleaved into six distinct proteins, including those derived from the gag gene as well as the reverse transcriptase, integrase, and protease derived from the pol gene. The primary transcript is spliced to generate a shorter transcript used for translation of the env gene. The polyprotein derived from the env gene is similarly cleaved to generate viral envelope proteins.
Viral reverse transcriptases catalyze three different reactions: RNA-dependent DNA synthesis, RNA degradation (by a separate RNase H domain), and DNA-dependent DNA synthesis. For DNA synthesis to begin, the reverse transcriptase requires a primer. As seen for many LTR retrotransposons, the primer is a cellular tRNA obtained during an earlier infection and carried in the viral particle. This tRNA is base-paired at its 3′ end with a complementary sequence in the viral RNA. The new DNA strand is synthesized in the 5′→3′ direction, as in all RNA and DNA polymerase reactions. Reverse transcriptases, unlike DNA polymerases, do not have 3′→5′ proofreading exonucleases. They generally have error rates of about 1 per 20,000 nucleotides added. An error rate this high is extremely unusual in DNA replication and seems to be a feature of most enzymes that replicate the genomes of RNA viruses. A consequence is a higher mutation rate and a faster rate of viral evolution, which are factors in the frequent appearance of new strains of disease-causing retroviruses.
Reverse transcriptases have become important reagents in the study of DNA-RNA relationships and in DNA cloning techniques. They make possible the synthesis of DNA complementary to an mRNA template, and synthetic DNA prepared in this manner, called complementary DNA (cDNA), can be used to clone cellular genes (see Figure 7-8).