Transcription Factors Interact with DNA and Proteins through Structural Motifs
The recognition of DNA by a regulatory protein almost always occurs through certain amino acid side chains of an α helix referred to as the recognition helix. A limited set of structural motifs function to present the recognition helix to the DNA. Amino acid side chains in this helix usually “read” the DNA sequence along the major groove, because (as you will recall from Chapter 5) more hydrogen-bond donor and acceptor atoms of nucleotide bases are found in the major groove than in the minor groove (Figure 19-15).
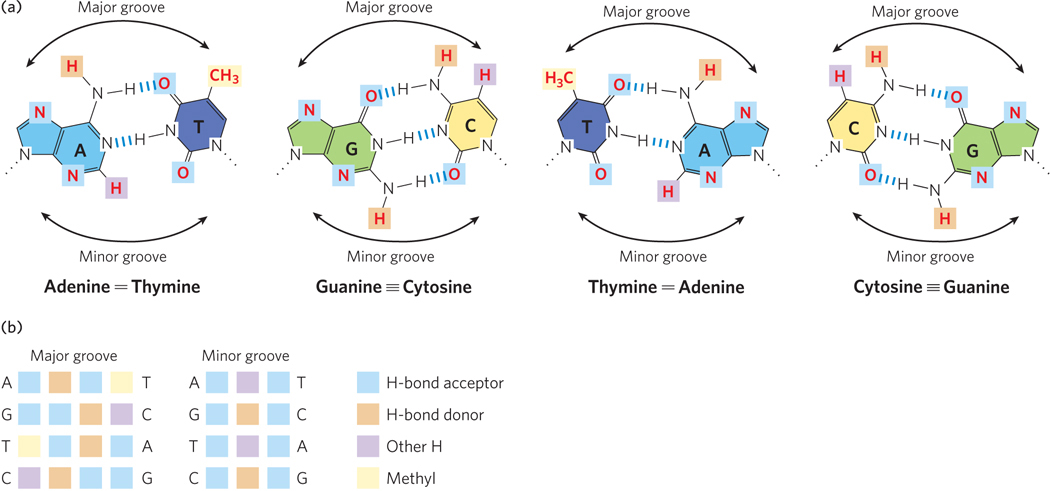
Figure 19-15: Hydrogen-bond donor and acceptor atoms in the major and minor grooves of DNA. (a) Shown here are the functional groups (in red) of all four base pairs as displayed in the major and minor grooves. Hydrogen-bond donor and acceptor atoms that can be used for base-pair recognition by proteins are indicated by light brown and blue squares, respectively. Other hydrogen atoms are indicated by purple squares, and methyl groups by yellow squares. (b) The atoms (color-coded as shown on the right) that can be used for protein recognition for each base pair are grouped as sets of four in each major groove (left) and as sets of three in each minor groove (middle). Notice how the sequence of the atoms in both the major and minor groove differs for the different base pairs, and how the four possible base pairs are chemically distinct in the major groove but not in the minor groove.
The DNA binding sites for regulatory proteins are often short inverted nucleotide repeats where multiple (usually two) subunits of the regulatory protein bind cooperatively (Figure 19-16). Accordingly, many bacterial and eukaryotic activators and repressors are dimers. Crystal structures of activators and repressors bound to DNA show that each monomer of a homodimer binds the same nucleotide sequence within the inverted repeat. Regulatory proteins use several structural motifs to promote dimerization.
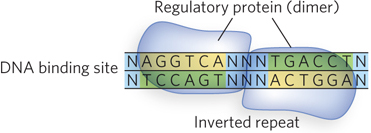
Figure 19-16: An inverted repeat at the site of transcription factor binding. A nucleotide sequence followed by the reverse, complementary sequence is known as an inverted repeat. It can have a variable number of base pairs that are not part of the repeat between the two repeated sequences. A palindrome is an inverted repeat with no base pairs between the two repeat sequences. Proteins that bind to inverted repeats are dimeric, and each subunit binds to one half of the repeat. Illustrated here is a homodimer binding an inverted repeat (N = any nucleotide).
Examples of DNA-binding and protein-dimerization motifs are described in Chapter 4. Here we focus on those that play prominent roles in the function of regulatory proteins.
Helix-Turn-Helix Motif Bacterial regulators most commonly use the helix-turn-helix motif to present the recognition helix to DNA, and several eukaryotic regulatory proteins also interact with DNA through this motif. The helix-turn-helix motif consists of about 20 amino acid residues that form two short α helices connected by a β turn (Figure 19-17). This motif lacks intrinsic stability and is generally part of a somewhat larger DNA-binding domain. Only one of the two α-helical segments serves as the recognition helix; it packs against other regions of the protein and protrudes from the protein surface for insertion into the major groove.
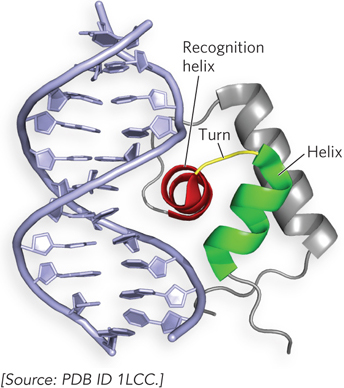
Figure 19-17: The helix-turn-helix DNA-binding motif. This molecular structure shows the DNA-binding domain of the bacterial Lac repressor (as a ribbon structure) interacting with the major groove of DNA. The helix-turn-helix motif is red and green; the DNA recognition helix is red.
Homeodomain Motif Researchers first identified the homeodomain motif as a conserved 60 amino acid sequence in transcription activators encoded by genes that regulate body pattern development in fruit flies. We now know that the homeodomain is found in proteins from a wide variety of multicellular organisms, including humans. When the structure of the homeodomain was determined, it was found to contain a helix-turn-helix motif—but with some important differences. First, the homeodomain is composed of three α helices, only two of which correspond to the helix-turn-helix motif. Second, the N-terminal residues of the homeodomain reach around the DNA and interact with the minor groove (Figure 19-18).
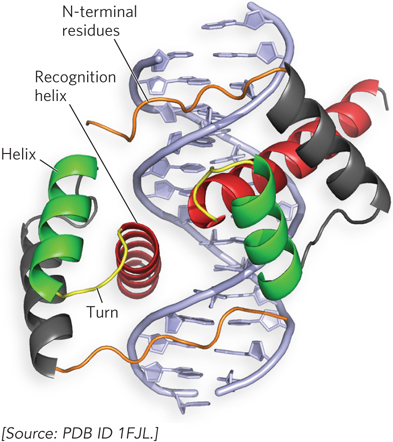
Figure 19-18: The homeodomain DNA-binding motif. This molecular structure shows the homeodomain motifs of the Drosophila transcription factor known as Paired, a dimeric protein (only a small part of the much larger Paired dimer is shown). The recognition helix in each subunit is stacked on two other α helices and can be seen protruding into the major groove. The N-terminal residues reach around the DNA and interact with the minor groove.
Basic Leucine Zipper and Basic Helix-Loop-Helix Motifs The leucine zipper motif is an amphipathic α helix, with a series of hydrophobic amino acid residues concentrated on one side of the helix. A striking feature of this α helix is the occurrence of Leu residues at every seventh position, forming a hydrophobic surface along one side of the helix—the site where two identical subunits dimerize. Researchers initially thought that dimerization was caused by interdigitating Leu residues (hence the name “zipper”). We now know that the two subunits dimerize through packing of the residues along the inner surface of the interface, where they form a coiled-coil structure. Certain transcription factors use leucine zippers in combination with basic residues at one end of the α helices that make up the recognition helices, forming basic leucine zipper motifs (Figure 19-19). These basic leucine zipper regulators are sometimes referred to as bZIP proteins. The crystal structure of bZIPs shows that they grip and bind DNA like a set of tongs (see Figure 19-19b). However, there are many regulatory proteins that use leucine zipper helices only for dimerization and contain a separate motif for DNA binding. Leucine zippers are found in many eukaryotic transcription activators and in a few bacterial regulators.
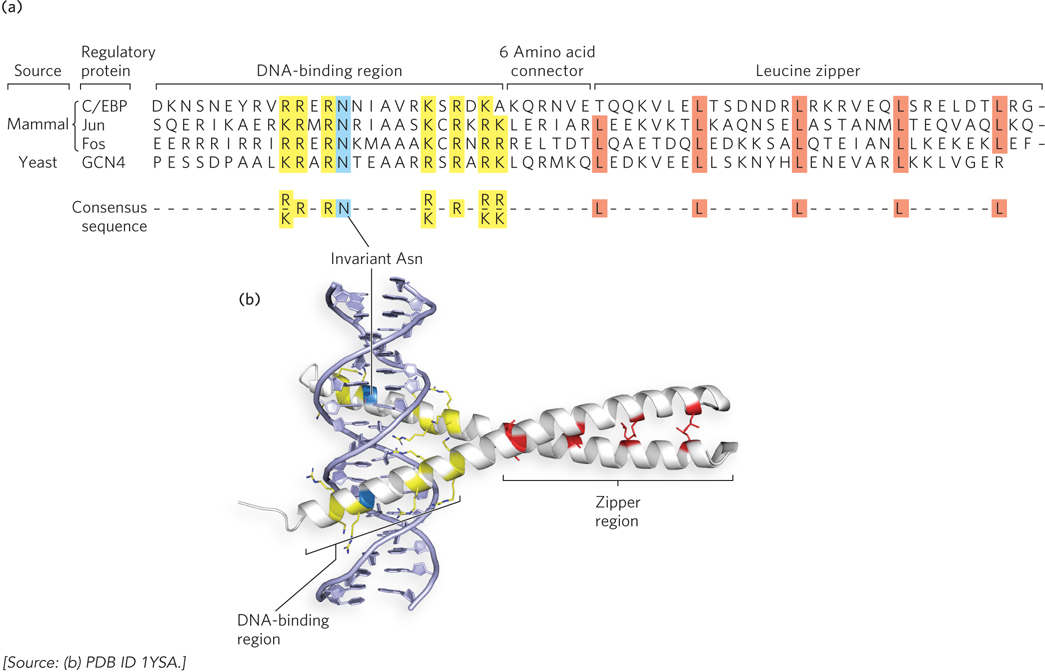
Figure 19-19: The basic leucine zipper motif. This motif is often used to mediate protein-protein interactions in eukaryotic transcription factors. (a) The amino acid sequences of several basic leucine zipper (bZIP) proteins. Notice the Leu (L) residues at every seventh position in the zipper region and the number of basic residues—Lys (K) and Arg (R), and one invariant Asn (N)—in the DNA-binding region. A consensus sequence is shown at the bottom. (b) A basic leucine zipper from the yeast activator protein GCN4. Only the two “zippered” α helices, each from a different subunit of the dimeric protein, are shown. The helices wrap around each other in a coiled-coil. This molecular structure shows the interacting Leu residues (red), the basic residues in the DNA-binding region (yellow), and the invariant Asn residue (blue).
A somewhat similar structural motif in some eukaryotic transcription factors is the basic helix-loop-helix motif (Figure 19-20). These proteins share a conserved region of about 50 residues that are important for both DNA binding and protein dimerization. The basic helix-loop-helix region contains two amphipathic α helices—one of which contains basic residues—linked by a loop of variable length. Dimer formation is mediated by one set of amphipathic α helices, and DNA binding is mediated by the amphipathic α helices that contain basic residues. The recognition helices grip the binding sequence in DNA in much the same way as the basic leucine zipper.
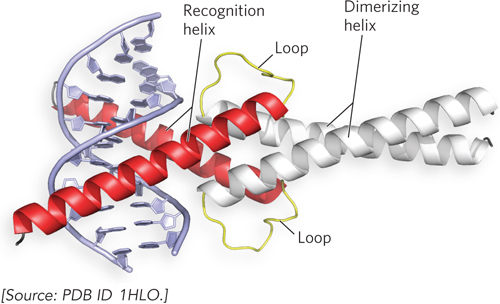
Figure 19-20: The basic helix-loop-helix motif. This ribbon model shows the human homodimeric transcription factor Max bound to its DNA target site. The two amphipathic α helices of each Max subunit are shown in red and white; the loop is yellow in both. The two subunits form a four-helix bundle through association of their dimerizing α helices (white), and the DNA-binding α helices (red) extend from the bundle.
Zinc Finger Motif The zinc finger motif comes in a few varieties, two of which are discussed here. A zinc finger domain consists of about 30 residues that form an elongated loop held together at the base by a single Zn2+ ion. The Zn2+ ion is coordinated to four amino acid side chains, usually four Cys residues or two Cys and two His residues. The zinc functions to stabilize the motif, which presents a recognition helix to DNA; the Zn2+ does not interact with the DNA directly. The interaction of a single zinc finger with DNA is typically weak, and this particular binding motif has the unique feature that the protein can have multiple copies of the motif that act together as a chain. Multiple zinc fingers are found in many DNA-binding proteins, and they substantially enhance binding affinity by interacting simultaneously with the DNA. In fact, one DNA-binding protein of the frog Xenopus laevis has 37 zinc fingers! In the mouse regulatory protein Zif268, the zinc finger domains present the recognition helix so that it winds around the DNA following the major groove (Figure 19-21). Zinc finger proteins in this class are among the few regulatory proteins that function as monomers. They do not require the DNA binding site to be an inverted repeat and can recognize a long sequence of DNA that contains no internal repeat sequences, because each recognition helix is unique.
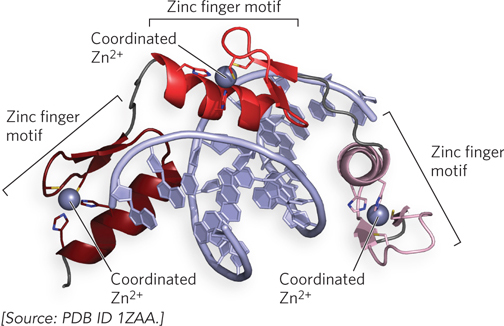
Figure 19-21: The zinc finger motif. This ribbon structure of a fragment from the mouse regulatory protein Zif268 shows three zinc fingers (different colors) arranged one after the other in the protein. The Zif268 recognition helices enter the major groove of the DNA, and the three fingers wind around the DNA helix.
Another type of regulatory zinc finger protein combines the Zn2+-binding motif with the helix-turn-helix motif (Figure 19-22). This type of zinc finger protein uses two Zn2+ ions to stabilize the DNA-binding domain, which has a helix-turn-helix motif. These proteins bind to the DNA as dimers; the example shown in Figure 19-22 uses a leucine zipper to mediate the dimer contacts. Zinc finger motifs are common in eukaryotes, and there are a few examples among bacterial regulators.
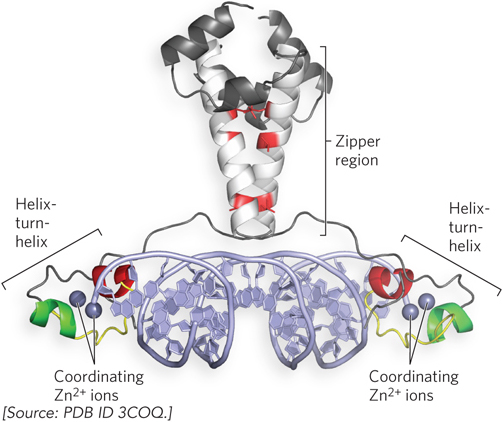
Figure 19-22: Zinc finger, helix-turn-helix, and leucine zipper motifs in the same regulatory protein. The Gal4 protein (Gal4p), a yeast transcription activator, is a dimer, held together by a leucine zipper. Each of the two DNA-binding domains contains two Zn2+ ions, which help hold the recognition helix (red) of the helix-turn-helix motif in the proper geometry for DNA recognition.
Transcription-Activation Motifs In addition to structural domains devoted to DNA binding and protein dimerization, transcription activators contain regions used for recruiting RNA polymerase or other protein factors. These recruitment regions are thought to be relatively unstructured. The first one was noted in the Gal4 protein (Gal4p), a yeast transcription activator. Researchers observed that several acidic residues were associated with the activating function, and the region could be altered by mutation without much effect on function; the region was referred to as an “acid blob.”
Other activation domains of transcription factors have also been shown to contain unstructured regions characterized (like Gal4p) by acidic residues or by other types of amino acids. For example, certain activation domains are glutamine-rich or proline-rich, and also appear to be unstructured. The current understanding is that these activation regions function as many short sections of amino acid residues that act together like a patch of Velcro: the more there are, the greater their effect. This somewhat unstructured approach to achieving activation might enable transcription factors to extend their range of protein-protein interactions for combinatorial control (see Section 19.1).
Transcription Activators Have Separate DNA-Binding and Regulatory Domains

Mark Ptashne
Transcription activators typically contain a regulatory domain that is separate from and functionally independent of the DNA-binding domain. An early and now classic experiment demonstrating this property of transcription activators was performed by Mark Ptashne and his colleagues (Figure 19-23). They proposed that the regulatory and DNA-binding functions of a transcription activator are independent and separable. To test this idea, they spliced together DNA encoding the transcription-activation domain of a eukaryotic activator and DNA encoding the DNA-binding domain of a bacterial repressor. The prediction was that the fusion protein would activate transcription of a gene under the control of the eukaryotic activator, provided that the gene contained an upstream binding sequence recognized by the bacterial repressor. The researchers chose for their study the yeast transcription activator Gal4p, which drives the expression of genes for galactose metabolism, including the gene GAL1. The C-terminal activation sequences of Gal4p were fused to the N-terminal DNA-binding region of an E. coli repressor, LexA. The new gene encoding the LexA-Gal4 fusion protein was inserted into a plasmid and transferred to yeast, along with a second plasmid that contained the GAL1 gene promoter fused to the bacterial β-galactosidase gene, lacZ. As predicted, in the transformed yeast, the new LexA-Gal4 fusion protein activated the GAL1-lacZ gene construct containing an upstream LexA-binding sequence, but it did not activate the GAL1-lacZ gene on the plasmid that lacked the LexA-binding site.
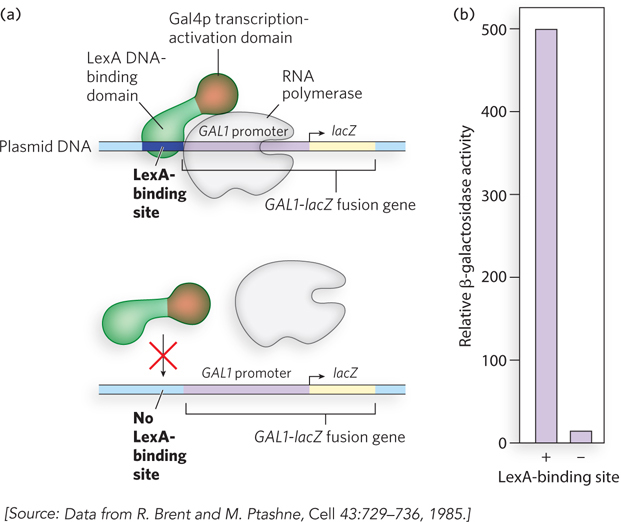
Figure 19-23: Experiment demonstrating the separate DNA-binding and regulatory domains of transcription activators. (a) A GAL1-lacZ fusion gene is inserted in a plasmid downstream from a LexA-binding site (top), or downstream from a DNA segment lacking the LexA-binding site (bottom). In both cases, cells are transformed with a plasmid encoding a fusion protein containing the bacterial LexA DNA-binding domain fused to the transcription-activation region of yeast Gal4p. (b) Expression of the GAL1-lacZ fusion gene is measured as described in the text. Expression of β-galactosidase is induced in cells containing plasmids with the LexA-binding site.
As shown in Figure 19-23, the LexA-Gal4 fusion protein activated the production of β-galactosidase more than 500-fold when the LexA-binding site was present (compared with when absent) in the GAL1-lacZ gene construct. Production of β-galactosidase is easily measured by using a synthetic substrate that yields a blue product when cleaved by the enzyme. The LexA-Gal4 fusion protein did not activate transcription from the wild-type GAL1 promoter, because the protein no longer recognized the Gal4p-binding site upstream from the GAL1 gene.
This experiment not only demonstrated the modular nature of regulatory proteins but also gave molecular biologists yet another tool for studying the inner workings of the cell. The widely used yeast two-hybrid assay makes use of the fact that the DNA-binding and transcription-activation regions of the Gal4p regulatory protein are stable, separate domains (see Chapter 7).
SECTION 19.2 SUMMARY
The DNA-binding domains of transcription factors are usually constructed from a limited set of structural motifs, including the helix-turn-helix, homeodomain, leucine zipper, helix-loop-helix, and zinc finger motifs.
Many transcription factors form dimers and bind inverted repeat sequences, thereby increasing their affinity for DNA.
The basic leucine zipper and basic helix-loop-helix motifs facilitate both DNA binding and protein dimerization.
Many transcription-activation domains are composed of acidic, proline-rich, or glutamine-rich regions.
Transcription activators typically contain separable and functionally independent DNA-binding and regulatory domains.