Bottom-up Processing and Top-down Processing
bottom-up processing The processing of incoming sensory information as it travels up from the sensory structures to the brain.
top-down processing The brain’s use of knowledge, beliefs, and expectations to interpret sensory information.
Perception is the product of bottom-up and top-down processing. Bottom-up processing refers to the processing of incoming sensory input as it travels up from the sensory structures to the brain. It is called bottom-up because it is coming from the senses up to the brain. Bottom-up processing starts with the transduction of the incoming sensory signals. You can think of bottom-up processing as bringing the sensory input from the environment to the brain to be interpreted. However, the perceptual systems in the brain do not just randomly search through billions of possibilities to recognize the sensory input that is sent up. The search is greatly narrowed by top-down processing—the brain’s use of knowledge, beliefs, and expectations to interpret the sensory information. It is referred to as top-down because it is coming from the top (the brain) back down to the lower sensory structures. To understand the difference between these two types of processing, think about listening to someone speak in a language that is foreign to you. You have bottom-up processing in that you hear the sounds. You cannot interpret this sensory input, however, because you do not have top-down processing (comprehension of the foreign language is not part of your knowledge base). Because top-down processing is so critical to perception, there are more top-down neural connections than bottom-up connections, about a 10:1 ratio (Hickok, 2014).
To further your understanding of these two types of processing, look at Figure 3.9. Do you see a meaningful pattern? If not, then your top-down processing is letting you down. There is a cow staring directly at you. The head is on the left side of the image. To see it, your top-down processing has to organize various features in the figure successfully to fit your knowledge of what such a cow looks like. Once your brain does this, you won’t have trouble seeing it the next time you look at this figure. You’ll have the necessary top-down processing. In fact, using similar stimuli, Tovee, Rolls, and Ramachandran (1996) found that neurons in the temporal lobes permanently altered their connections once the meaningful pattern (such as the cow in our example) has been seen. In addition, using a jumble of black and white splotches from which you eventually see a dog, Ramachandran, Armel, and Foster (as reported in Ramachandran & Blakeslee, 1998, p. 297) found that if two completely different views of this dog are presented in rapid succession, naive subjects can see only incoherent motion of the black and white splotches; but if they have already seen the dog, it is seen to jump or turn in the appropriate manner, demonstrating the role of top-down object knowledge in motion perception. If you are still having trouble locating the cow, the dark splotches at the bottom of the figure, just to the left of center, represent her nose and mouth. Up higher are other dark areas that are her eyes and ears.

Figure 3.9: Figure 3.9 | Perceptual Organization and Top-down Processing | Do you see a meaningful object in this figure? There is one. It is a cow staring directly at you. Can you find it? To do so, your perceptual top-down processing mechanisms will have to organize some of the features of the figure to match your knowledge of what a cow looks like. If you are having trouble locating the cow, its head occupies most of the left half of the figure, and its body, the right half. Once you see it, you won’t have any difficulty seeing it the next time. Your top-down processing mechanisms will know how to organize the features so you perceive it.
(From American Journal of Psychology. Copyright 1951 by the Board of Trustees of the University of Illinois. Used with permission of the University of Illinois Press.)
perceptual set The interpretation of ambiguous sensory information in terms of how our past experiences have set us to perceive it.
The subjective nature of perception is due to this top-down processing. Our past experiences, beliefs, and expectations bias our interpretations of sensory input. As the French novelist Anais Nin observed, “We do not see things as they are, we see things as we are” (Tammet, 2009). Perceptual set and the use of contextual information in perception are two good examples of this biasing effect of top-down processing. Perceptual set occurs when we interpret an ambiguous stimulus in terms of how our past experiences have “set” us to perceive it. Our top-down processing biases our interpretation so that we’re not even aware of the ambiguity. Let’s consider how we perceive close plays in sporting events. Don’t we usually see them in favor of “our” team? We are set by past experiences to see them in this biased way. This means that past experiences guide our perception with top-down processing. In other words, we see it “our way.”
contextual effect The use of the present context of sensory information to determine its meaning.
Contextual effects are even stronger examples of top-down processing guiding perception. A contextual effect on perception occurs when we use the present context of sensory input to determine its meaning. Figure 3.10 shows a simple example of such contextual effects. Most people see the top line of characters as the alphabetic sequence A, B, C, D, E, F, and the second line as the numeric sequence 10, 11, 12, 13, 14. But if we now look at the characters creating the B and the 13, they are the same in each case. The context created by each line (alphabetic versus numeric) determined our interpretation. If surrounded by letters, the characters were interpreted as the letter B; if surrounded by numbers, the characters were interpreted as the number 13.

Figure 3.10: Figure 3.10 | A Context Effect on Perception | The interpretations of the ambiguous characters composing the second item in the first series and the fourth item in the second series are determined by the context created by the items on each side of them. In the first series, these items are letters so the interpretation of the ambiguous characters is a letter, B. In the second series, the items are numbers so the interpretation is a number, 13.
(Sensation and Perception (6th ed.), by S. Coren, L. M. Ward, & J. T. Enns, 2004, New York: Wiley. ISBN: 0471272558.)
Context is a crucial contributor to perception. Without contextual information, the brain may not be able to decide upon an interpretation. What about the following characters: IV? They could be alphabetical (the letters I and V) or numeric (the Roman numeral for 4). Inserted into a sentence with other words, such as “Jim was in the hospital and hooked up to an IV,” we would perceive them as letters. However, if they were inserted into the sentence, “Edward IV was the King of England in the fifteenth century,” we would perceive their numerical meaning. The addition of contextual information provides top-down processing that allows the brain to resolve such ambiguities in normal perception.
Perceptual Organization and Perceptual Constancy
Perceptual organization and constancy are essential processes for bringing order to the incoming sensory input. Let’s consider perceptual organization first. To be interpreted, the bits of incoming sensory data must be organized into meaningful wholes—shapes and forms. Some German psychologists working in the early part of the twentieth century developed many principles that explain how the brain automatically organizes visual input into meaningful holistic objects. Because the German word gestalt translates as “organized whole,” these psychologists became known as Gestalt psychologists. To the Gestalt psychologists, these organized wholes are more than just the sum of their parts. A good example of this is stroboscopic movement, the perceptual creation of motion from a rapidly presented series of slightly varying images. For example, we see smooth motion when watching a movie, but in actuality there are only still picture frames being shown rapidly in succession. The motion we perceive emerges from the parts, the still frames, but is not present in them. You have already experienced another example of the whole being greater than the sum of its parts in the last question in ConceptCheck 3, Chapter 2. The whole (a portrait of Rudolf II of Prague) is greater than the sum of its parts (fruits, flowers, and vegetables). To explain how we organize our visual input into holistic objects, Gestalt psychologists proposed many different organizational principles. We will consider two major ones—the figure-and-ground principle and the principle of closure.
figure-and-ground principle The Gestalt perceptual organizational principle that the brain organizes sensory information into a figure or figures (the center of attention) and ground (the less distinct background).
Gestalt psychologists developed a basic rule for perceptual organization, the figure-and-ground principle—the brain organizes the sensory input into a figure or figures (the center of attention) and ground (the less distinct background). To get a better understanding of this principle, let us examine the image in Figure 3.11. This reversible figure-ground pattern was introduced by Danish Gestalt psychologist Edgar Rubin in 1915 (Rubin, 1921/2001). What is the figure and what is the ground? These keep changing. We see a vase as a white object on a colored background, but then we see two faces in silhouette facing each other on a white background. What you see is determined by which side of the wavy lines extending down either side of the image your brain focuses on to form the figure (Restak & Kim, 2010). If you concentrate laterally (outwardly), then you’ll see the faces. If you concentrate medially (inwardly), then you’ll see the vase. This is what is called border ownership (Rubin, 2001). When you perceive the faces, you see the blue region as owning the border (the wavy lines); but when you perceive the vase, you see the white region as owning the border. With each switch in perspective, the brain keeps switching its figure and ground organization for these sensory data. This is called a reversible pattern because the figure and ground reverse in the two possible interpretations. What is figure in one interpretation becomes the background in the other. Without any context, top-down processing cannot determine which interpretation is the correct one. This is an example of a bistable perception—an unchanging visual stimulus that leads to repeated alternation between two different perceptions (Yantis, 2014).

Figure 3.11: Figure 3.11 | An Example of Figure-Ground Ambiguity | Do you see a white vase or two blue facial silhouettes looking at each other? You can see both, but only one at a time. When you switch your perception from one to the other, your brain is switching how the input is organized with respect to figure and ground. When you see a vase, the vase is the object, but when you see the two faces, the vase becomes the background.

John O’Brien/The New Yorker Collection/www.cartoonbank.com
The ambiguous vase–silhouettes illustration helps us to understand the figure-and-ground principle, but ambiguity can also be due to the possibility of more than one object on the same background. The features of the object may allow more than one interpretation. A classic example of such an ambiguity is given in Figure 3.12. Do you see an old woman or a young woman? The young woman is looking back over her right shoulder, and the old woman’s chin is down on her chest. The young woman’s ear is the left eye of the old woman. Actually, depending upon how you organize the features, you can see both, but not simultaneously. If you are able to see both, your top-down processing will keep switching your perception because there is no contextual information to determine which interpretation is correct.

Figure 3.12: Figure 3.12 | An Example of an Organizational Perceptual Ambiguity | Do you see the head and shoulders of an old woman or a young woman? If you’re having trouble seeing the old woman, she has a large nose, which is located below and to the left of the center of the figure. The old woman’s large nose is the chin and jaw of the younger woman. Now can you see both of them? Because there is no contextual information to determine a correct interpretation, your perception will keep switching from one interpretation to the other.
W. E. Hill, 1915.
This young/old woman organizational ambiguity is often credited to British cartoonist W. E. Hill who published it in a humor magazine in 1915, but it appears that Hill adapted it from an original concept that was popular throughout the world on postcards and trading cards in the nineteenth century. The earliest known depiction of the young/old woman ambiguity is on an anonymous German postcard from 1888 shown on the left in Figure 3.13 (Weisstein, 2009). Can you perceive both the young woman and the old woman? Having identified them in Hill’s illustration should have facilitated their perception on this card. As in Hill’s illustration, the old woman’s large nose is the chin and lower jaw of the younger woman. Botwinick (1961) created the male version of this figure (shown on the right in Figure 3.13) and entitled it “Husband and Father-in-Law” because the title of Hill’s female ambiguous figure was “Wife and Mother-in-Law.” If you’re having trouble perceiving the two men, the older man’s big nose (like the older woman’s big nose) is the chin and lower jaw of the younger man; but the two men are facing in the opposite direction of the two women in Hill’s illustration.

Figure 3.13: Figure 3.13 | Two More Organizational Perceptual Ambiguities | On the left is a young/old woman ambiguity taken from a German postcard from 1888. The ambiguity on this postcard is like the one in Figure 3.12. Can you see both the young woman and the old woman? Their head positions are just like those in Figure 3.12. The old woman’s big nose is the chin and jaw of the younger woman. On the right is a similar perceptual ambiguity that allows the perception of both a young man and an old man. If you’re having difficulty seeing both men, the old man’s big nose is the chin and jaw of the younger man just like in the ambiguous women’s version. The two men, however, are facing to the right and not to the left like the two women.
((a) Science Source; (b) Drawn by Mr. George P. Marsden, Chief, Medical Arts Section, DRS, NIH)
closure The Gestalt perceptual organizational principle that the brain completes (closes) incomplete figures to form meaningful objects.
subjective contour A line or shape that is perceived to be present but does not really exist. The brain creates it during perception.
Another important Gestalt perceptual organizational principle is closure, which refers to the tendency to complete (close) incomplete figures to form meaningful objects. You’ve already seen some examples of closure in Figures 3.9 and 3.10. Closure was used to perceive the cow in Figure 3.9 and to perceive the ambiguous characters in Figure 3.10 as the letter B in the alphabetic context. The French artist Paul Cézanne used the principle of closure in his paintings by leaving bare patches of canvas in them for the viewer to fill in the blanks (Lehrer, 2007; Sweeney, 2011). Significantly, he worked at about the same time as the Gestalt psychologists developed their principles of perceptual organization. In order to close a figure, we use top-down knowledge. Sometimes, however, the brain goes too far in using closure and creates figures where none exist. Such figures are called subjective contours—lines or shapes that are perceived to be present but do not really exist (Kanizsa, 1976). The white triangle that seems to be overlying three black circles and another triangle in Figure 3.14 is a subjective contour. Only three 45° angles and three black circles with a chunk missing are present. In perceiving these stimuli, the brain creates an additional object, the second triangle, by filling in the missing parts of the sides of this triangle; but this triangle doesn’t really exist. The caption for Figure 3.14 explains how to demonstrate that the overlying triangle is really not there. Because 4-month-old infants also see such subjective contours (Ghim, 1990), it appears that our brains are hardwired to make sense of missing information by using top-down processing to fill in what should be there (Hood, 2009). The visual cortex also responds to the illusory contours as if they are real. Von der Heydt, Peterhans, and Baumgartner (1984) found that illusory contours evoked responses in cells in the visual cortex that responded as if the contours were real lines and edges.
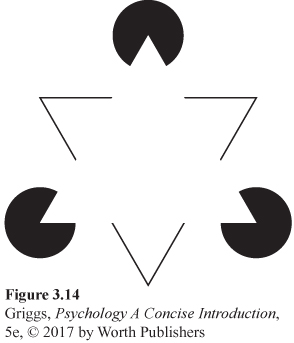
Figure 3.14: Figure 3.14 | An Example of a Subjective Contour | Does there appear to be a very bright triangle overlying three black circles and another triangle? This brighter-appearing triangle isn’t really there. It is a subjective contour created by your brain in its perception of the three black circles with a chunk missing (the three Pac Man–like characters). To demonstrate that this overlying brighter triangle is truly not there, cover up everything in the display but the horizontal blank center. When you do this, you will not see any difference in level of brightness across the horizontal center of the display. If the whiter triangle were really there, you would see differences in brightness.
Not only does the brain create subjective contours, but it also creates ones that are ambiguous. An example of an ambiguous subjective contour is the Necker cube in Figure 3.15 on page 134 (from Bradley, Dumais, & Petry, 1976). In perceiving a Necker cube, you have filled in the nonexistent lines that connect its corners. The cube seems to float in front of the page, with green circles behind it. All that is really there are green circles with white lines in them. Your brain constructs the cube’s subjective edges and its three-dimensional shape. You can show that this is a subjective contour by placing your finger over a green circle. The lines emanating from that circle will vanish. You can also reverse the orientation of this phantom cube just as you can for a true Necker cube (another example of a bistable perception). Focus on the “x.” It will move from the front edge of the cube to the back edge when the cube reverses orientation. This phantom cube not only illustrates an ambiguous subjective contour, but it also allows you to remove the subjective edges of the cube from your perception. Imagine that the green circles are holes and that you are looking at the cube through these holes. The cube is actually suspended behind the page. This perception may take a little longer to achieve, but be patient. Once you are able to perceive this interpretation, the illusory contour lines vanish, but the cube continues to reverse. Thus, there are four perceptions possible for this seemingly simple visual display, demonstrating that perception is a process of active construction. This display also demonstrates that the brain constructs our three-dimensional view of the world from the visual cues available in a visual stimulus, in this case a two-dimensional one (Hoffman, 1998). We will discuss how we perceive depth in the next section.

Figure 3.15: Figure 3.15 | Another Example of an Ambiguous Subjective Contour | This phantom Necker cube is an example of an ambiguous subjective contour. Instead of seeing green circles with white lines inside them, you see a cube, seemingly floating above the page. The lines between the circles that connect the corners of the cube are nonexistent. The cube also reverses orientation. Focus on the “x,” and it will move from the front edge of the cube to the back. You can also make the subjective segments of the cube vanish by viewing the circles as holes in the page and imagining that you are looking through the holes to see the cube suspended below. The cube below also reverses orientation so there are four different possible interpretations of this seemingly simple stimulus.
(Reprinted by permission from Macmillan Publishers Ltd: “Reply to Cavonius,” by D. R. Bradley, S. T. Dumais, & H. M. Petry, 1976, Nature, 261, p. 78.)
perceptual constancy The perceptual stability of the size, shape, brightness, and color for familiar objects seen at varying distances, different angles, and under different lighting conditions.
In addition to being able to organize and group sensory input to form meaningful objects, the brain must be able to maintain some type of constancy in its perception of the outside world, and it does. Perceptual constancy refers to the perceptual stability of the size, shape, brightness, and color for familiar objects seen at varying distances, different angles, and under different lighting conditions. These various types of constancy are referred to as size, shape, brightness, and color constancy, respectively. The retinal images for familiar objects change under different visual conditions such as different viewing angles or distances. For example, the size of a car doesn’t shrink in our perception as it drives away. The size of its retinal image shrinks, but its size in our perception doesn’t change. The brain adjusts our perceptions in accordance with what we have learned about the outside world. We know that the car’s size doesn’t change and realize that it is just farther away from us. Perceptual constancy must override this changing sensory input to maintain an object’s normal size, shape, brightness, and color in our perception of the object. Perceptual constancy is a very adaptive aspect of visual perception. It brings order and consistency to our view of the world.
Using our understanding of how the brain achieves these constancies, however, we can create situations that fool the brain, creating an illusion. Consider brightness constancy (also called lightness constancy). The brightness of an object depends upon the amount of light the object reflects relative to its surroundings. Look at Figure 3.16a. Which checker square is brighter, Square A or Square B? Doesn’t Square B appear brighter to you? It is not. The two squares are the same shade of gray. Edward H. Adelson at MIT created this illusion. What causes our illusory perception that the two squares are not the same brightness? Whereas there are other factors involved (e.g., how the brain uses shadow information because B is in the shadow and A is not), the primary one is that the two squares have different surrounding contexts. Square A appears darker because it is surrounded by lighter squares, and Square B appears lighter because it is surrounded by darker squares. The brain uses the surroundings of the two squares to determine their brightness and is led astray in this case. Look at Figure 3.16b. Now the surroundings of the two squares are the same so your brain judges their brightness to be the same and you perceive them as the same. Perceived brightness of an object depends upon its surrounding context. Remember that even knowing that the two tables in the Turning the Tables illusion given in Figure 3.1 were the same size, you could not make your brain perceive them as equal. The same holds here. Even knowing that the two squares in Figure 3.16a are the same, you cannot make your brain perceive them to be the same. If you are still not convinced that Squares A and B in Figure 3.16a are the same, then photocopy the page, cut the two squares out, and compare them. This will convince you.
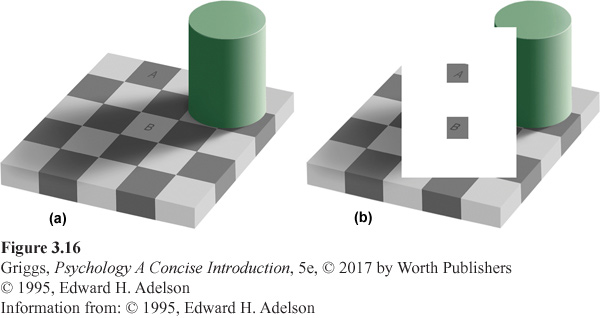
Figure 3.16: Figure 3.16 | Adelson’s Checker Shadow Illusion | (a) Which checker square is brighter—Square A or Square B? It certainly appears that Square B is brighter. However, the two squares are the same shade of gray. Whereas there are other factors involved in this brightness illusion, an important one is that the two squares have different surrounding contexts. Square A appears darker because it is surrounded by lighter squares, and Square B appears lighter because it is surrounded by darker squares. The message: Perceived brightness is relative. (b) The two squares are now surrounded by the same context, allowing you to see that they are indeed the same shade of gray.
© 1995, Edward H. Adelson
Information from: © 1995, Edward H. Adelson
Perceiving constancies also seems to have subjective components that can lead different people to see the same stimulus differently, but each person would still see it in a constant fashion. A good example is “The Dress” color debate (also known as “Dressgate”) that went viral on the Internet in February 2015. A photo of the dress to be worn by a mother-in-law-to-be was posted online in an attempt to solve the disagreement between the future bride and groom about the color of the dress in the photo. The bride saw the dress as white and gold, and the groom as blue and black (the actual colors of the dress). Indeed, the public also seemed to be firmly entrenched into white-and-gold and blue-and-black camps with the vast majority of people not being able to switch their color interpretations. These two perceptions of the dress are given in Figure 3.17. Why the difference in color perception? Whereas there are many explanations that have been proposed for this difference and perceptual researchers are still in disagreement about the explanation, one of the most plausible proposals argues that it stems from individual differences in color constancy (Macknik & Martinez-Conde, 2015). To achieve color constancy, the brain has to determine what the illumination source is for an object. Thus, it is possible that the differing color perceptions of the dress stem from people differing in their interpretation of what the illumination source for the dress is. According to Macknik and Martinez-Conde, light in the natural world comes from either direct golden sunlight or from the blue sky so the cortical color processing areas in the brain assume that most illumination has these colors. Thus, people looking at The Dress could assume that it is lit either by blue sky or golden sunlight. If the brain assumes it is blue sky, then it will subtract the blue from its perception of the dress, and the dress would appear white and gold. If it assumes illumination by sunlight, then it would subtract gold, and the dress would appear blue and black. It has also been proposed that the brains of people who stay up later (night owls) have more experience with artificial lighting which has more reddish light in it, so to achieve color constancy the brains of these people would subtract the red from their perception of the dress, which also results in seeing the dress as blue and black (Lafer-Sousa, Hermann, & Conway, 2015). In sum, to achieve color constancy different people make different assumptions about the light source that lead to different color perceptions of the dress. As Macknik and Martinez-Conde concluded, “The dress demonstrates that we can see the world in strikingly different ways depending on what our individual brain brings to the table” (p. 20).

Figure 3.17: Figure 3.17 | The Two Color Interpretations of “The Dress” | These are the two color interpretations of the photo of “The Dress” that went viral on the Internet in early 2015. People became firmly entrenched in their perception of the dress as white and gold or blue and black. The dress was actually blue and black. As explained in the text, the two interpretations may stem from subjective assumptions made by the brain about the illumination source for the dress.
Perceptual organization and perceptual constancy are essential processes in perception. Without them, our perceptions would be meaningless fragments in a constant state of flux. Constancy and organization bring meaning and order to them. However, neither of these aspects explains another crucial part of visual perceptual processing—how we perceive the third dimension: depth.
Depth Perception
depth perception Our ability to perceive the distance of objects from us.
Depth perception involves the judgment of the distance of objects from us. The brain uses many different sources of relevant information or cues to make judgments of distance. These cues may require both eyes (binocular cues) or only one eye (monocular cues).
retinal disparity A binocular depth cue referring to the fact that as the disparity (difference) between the two retinal images of an object increases, the distance of the object from us decreases.
The major binocular cue is retinal disparity. To understand retinal disparity, first consider that our two eyes are not in the same place on our face. Each eye (retina) takes in a slightly different view of the world. The difference (disparity) between these two views of each retina provides information about the distance of an object from us. It allows the brain to triangulate the distance from us. The retinal disparity cue refers to the fact that as the disparity (difference) between the two retinal images increases, the distance from us decreases.
To understand this, hold up your right hand in front of you and form a fist but extend your index finger upward. If you hold it stationary and focus on it, and now close one eye, and then rapidly open it and close the other one a few times, your finger will appear to move. If you now move the finger closer to you and repeat the rapid closing and opening of the eyes one at a time, again, the finger appears to move, but now much more because the retinal views of the finger are more disparate. When right in front of your eyes, you see maximal movement because the disparity between the two retinal images is at its maximum.
linear perspective A monocular depth cue referring to the fact that as parallel lines recede away from us, they appear to converge—the greater the distance, the more they seem to converge. Sometimes referred to as perspective convergence.
interposition A monocular depth cue referring to the fact that if one object partially blocks our view of another, we perceive it as closer to us.

Dan Piraro, reprinted with permission of King Features Syndicate
There are several monocular cues, but we will discuss only a couple of them so that you have some understanding of how such cues work. Linear perspective (sometimes called perspective convergence) refers to the fact that as parallel lines recede away from us, they appear to converge—the greater the distance, the more they converge. For example, think about looking down a set of railroad tracks or a highway. The tracks and the two sides of the road appear to converge as they recede away from us. Because convergence is involved, this cue is sometimes referred to as perspective convergence. Another monocular cue that is easy to understand is interposition—if one object partially blocks our view of another, we perceive it as closer. Near objects partially overlap farther ones.
Monocular cues, binocular cues, and various distance-judging principles the brain uses are normally valid distance indicators. However, sometimes these cues and principle lead the brain to create misperceptions. We refer to such misperceptions as illusions—misperceptions of reality. Two illusions are illustrated in Figure 3.18. The first (a) is called the Ponzo illusion because it was first demonstrated by the Italian psychologist Mario Ponzo in 1913. The two horizontal bars are identical in size, but the top one appears larger. The other illusion (b) is the Terror Subterra illusion (Shepard, 1990). The pursuing monster (the higher one) looks larger than the pursued monster, but the two monsters are identical in size. In addition to this size illusion, the identical faces of the two monsters are sometimes misperceived as expressing different emotions, such as rage in the pursuer and fear in the pursued monster. How are distance cues involved in these misperceptions of size in these two illusions?
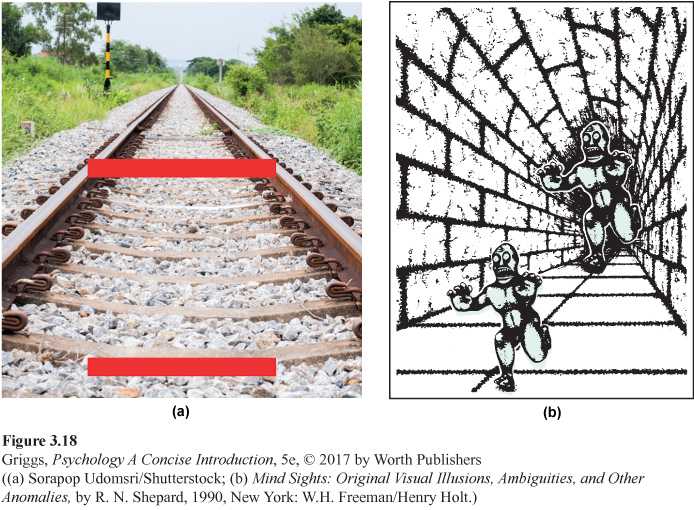
Figure 3.18: Figure 3.18 | The Ponzo and Terror Subterra Illusions | (a) The two red bars in the Ponzo illusion are identical in size. However, the top bar appears to be larger. (b) The two monsters in the Terror Subterra illusion are identical in size, but the pursuing monster (the top one) appears to be larger. To convince yourself that the two bars and the two monsters are identical, trace one of the bars (monsters) on a thin sheet of paper and then slide the tracing over the other bar (monster). Both illusions seem to be caused by the brain’s misinterpretation of the relative distance from us of the two bars in (a) and the two monsters in (b).
((a) Sorapop Udomsri/Shutterstock; (b) Mind Sights: Original Visual Illusions, Ambiguities, and Other Anomalies, by R. N. Shepard, 1990, New York: W.H. Freeman/Henry Holt.)
To understand how distance cues are involved in these illusions, we must first consider how the brain relates the retinal image size of an object to the object’s distance from us. As an object gets farther away from us, its size on the retina decreases. This is simple geometry, and the brain uses this geometric principle in creating our perception of the object. Now consider the situation in which two objects have equal retinal image sizes, but distance cues indicate to the brain that one of the objects is farther away. What would the brain conclude from this information? Using the principle relating retinal image size to distance, it would conclude that the object farther away must be larger. This is the only way that its retinal image size could be equal to that of the object closer to us. Thus, the brain enlarges the size of the more distant object in our perception of the objects. However, if the cues provided incorrect distance information and the objects were really equidistant from us, then we would see a misperception, an illusion. The brain incorrectly enlarged the object that it had mistakenly judged to be farther away. This is comparable to something we have experienced in working math problems: plug an incorrect value into an equation and get the problem wrong. This is essentially what the brain is doing when it uses incorrect information about distance, leading to a mistake in perception. It is important to realize that our brain’s computing of the retinal image size and distance from us of objects is done at the unconscious level of processing. We are privy only at a conscious perceptual level to the product of our brain’s calculations.
Now let’s apply this explanation to our sample illusions. Think about the Ponzo illusion shown in Figure 3.18a. If this illusion is due to the brain’s using incorrect distance information about the two horizontal bars, which cue that we described is responsible? That’s right—linear perspective. The convergence of the railroad tracks normally indicates increasing distance. Given this cue information, the brain incorrectly assumes that the top bar is farther away. Because the two horizontal bars are the same size and truly equidistant from us, they are the same size on our retinas. Because their retinal images are of equal size but the brain thinks that the bars are at varying distances from us, it incorrectly distorts the top bar (the one assumed to be farther away) to be larger in our perception, or, should I say, misperception.
The Terror Subterra illusion shown in Figure 3.18b can be explained in the same way. Monocular depth cues, mainly linear perspective, lead the brain to judge the pursuing monster to be farther away. Given that the retinal image sizes of the two monsters are equal because the two monsters are identical and equidistant from us and that the pursuing monster is incorrectly judged to be farther away, the brain enlarges the pursuing monster in our conscious perception, resulting in the illusion. As in the Ponzo illusion, the brain applies the valid principle relating retinal image size to the distance of objects from us, but uses incorrect distance information and thus creates a misperception.
The Müller-Lyer illusion depicted in Figure 3.19 (a and b) is another example of an illusion created by the brain misapplying the geometry relating retinal image size to distance from us (Gregory, 1968). As in the other two illusions, the brain mistakenly thinks that the line on the right with arrow feather endings is farther away than the line on the left with arrowhead endings. Why? In this case, the brain is using a relationship between distance and different types of corners that it has learned from its past perceptual experience. The line with arrow feather endings has the appearance of a corner that is receding away from us (like the corners where two walls meet in a room), while the line with arrowhead endings has the appearance of a corner that is jutting out toward us (like the corners where two sides of a building meet). These two types of corners are illustrated in Figure 3.19 (c and d). Thus, based on its past experience with such corners, the brain believes that the line with arrow feather endings is farther away.
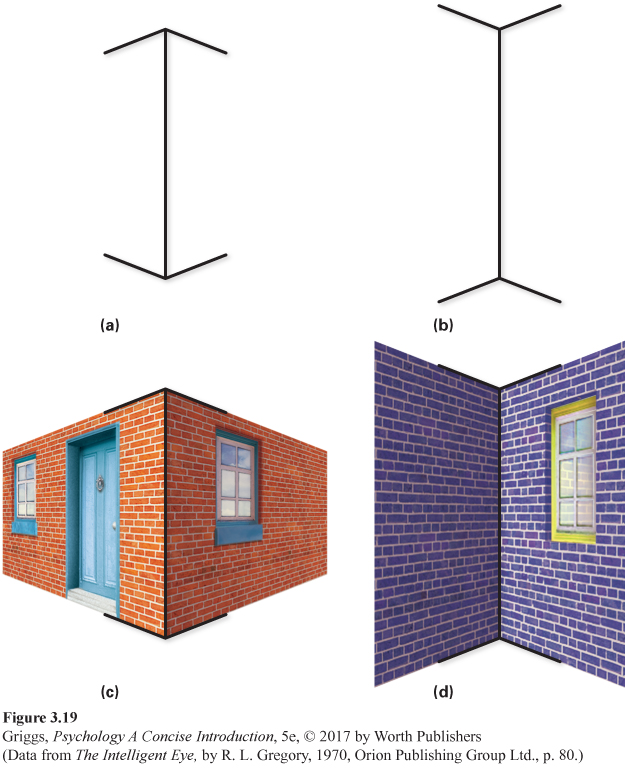
Figure 3.19: Figure 3.19 | The Müller-Lyer Illusion | (a and b) The two vertical line segments are equal in length. However, the one with the arrow feather endings on the right appears longer than the one with the arrowhead endings on the left. (c and d) Like the illusions in Figure 3.18, this illusion is created by the brain misapplying the geometry relating the retinal image size of objects and their distance from us. Based on its experiences with receding and projecting corners as illustrated here, our brain mistakenly thinks that the line with arrow feather endings is a receding corner and thus farther from us than the line with arrowhead endings, which our brain thinks is a projecting corner. Because the retinal images of the two lines are identical, the brain incorrectly lengthens the arrow feather line in our conscious perception.
(Data from The Intelligent Eye, by R. L. Gregory, 1970, Orion Publishing Group Ltd., p. 80.)
However, in reality, the line with the arrow feather endings is not farther away. The two vertical lines are identical in length and equidistant from us; therefore, their two retinal images are identical. Given the identical retinal images and the incorrect judgment about relative distance, the brain incorrectly enlarges the line with arrow feather endings so that we perceive it as being longer. In support of this explanation, cross-cultural researchers have found that people who live in physical environments without such distance-indicating corners are far less susceptible to seeing the illusion (Segall, Campbell, & Herskovits, 1963, 1966; Stewart, 1973).
The Turning the Tables illusion in Figure 3.1 also arises because our brain gives us a three-dimensional interpretation of a two-dimensional drawing (Shepard, 1990). Perspective cues indicate that the long side of the table on the left goes back in depth whereas the long side of the table on the right is more nearly at right angles to our line of sight. Thus, if the table on the left goes back in depth, the brain will think that its retinal image must be foreshortened (appear shorter than it really is) because this is what happens in true three-dimensional viewing. The fact that the retinal images of the two tabletops, however, are identical in length thus implies that the real length of the table on the left must be greater than the real length of the table on the right (and vice versa for the short sides of the two tables given their depth interpretations by the brain). Because these inferences about orientation, depth, and length are made automatically by the brain, we remain powerless to eliminate the illusion even though we know that the tabletops are identical. The drawing of the tables automatically triggers the brain to make a three-dimensional interpretation, and we cannot choose to see the drawing as what it is, patterns of lines on a flat piece of paper.

The Moon Illusion | The moon on the horizon appears much larger than it does when it is overhead, higher up in the sky, but this is an illusion. The moon is the same size and remains the same distance from us regardless of where it is in the sky. Objects near the horizon lead the brain to think that the horizon moon is farther away than when it is overhead, so the brain mistakenly enlarges its size in our perception because the retinal images of the horizon and overhead moons are the same size.
Paul Souders/The Image Bank/Getty Images
The moon illusion can also be explained in a similar way (Restle, 1970). The illusion is that the moon appears to be larger on the horizon than when it is overhead at its zenith. But the moon is the same size and at the same distance from us whether it is on the horizon or overhead. This means that the moon’s larger size on the horizon has to be an illusion. The objects near the horizon lead the brain to think that the moon is farther away when it is near the horizon than when it is overhead. Because the retinal images of the moon at these two locations are the same and the brain mistakenly thinks that the horizon moon is farther away, it distorts the moon’s size to appear much larger in our perception than when it is overhead, and this increase in apparent size makes it appear nearer (Gregory, 2009). It really isn’t, and it is easy to see that this is the case. To make the moon on the horizon shrink, we can roll up a sheet of cardboard into a viewer and look at the moon through this viewer so that we only see the moon and not any of the objects on the horizon. The moon will appear to shrink dramatically in size because the brain will no longer be led astray in its judgment of distance for the horizon moon.
Linear perspective (parallel lines converging as they recede away from us) plays a major role in many illusions, but what would the brain do if it were led to believe that parallel lines weren’t converging as they receded away from us? Look at Figure 3.20, the leaning tower illusion (Kingdom, Yoonessi, & Gheorghiu, 2007). The same exact photo of the Leaning Tower of Pisa is shown in both panels. Yet the tower on the right appears to be leaning more. Why? Our visual system treats the two images as if they are part of a single scene, rather than as two separate images of the same tower. Normally, if two adjacent towers rise at the same angle, they appear to converge as the tops of the towers recede from view; but because these are identical photos, the projections of the towers on the retina are parallel and do not converge in the distance (increasing height in this case). Thus, the brain decides that they are diverging. It employs its rule that lines receding away from us must diverge if their projections are parallel. Even knowing that these are identical photographs, you will not be able to override your brain’s misinterpretation and see them as such. They will remain the “Twin Towers of Pisa,” with one tower leaning more than the other.

Figure 3.20: Figure 3.20 | The Leaning Tower Illusion | These are duplicate pictures of the Leaning Tower of Pisa, but the one on the right seems to be leaning more. It isn’t, but you cannot override your brain’s interpretation to see these pictures as the same. To convince yourself that they are identical, photocopy the figure and then cut out one of the panels and compare it to the other panel.
Fred Kingdom
In creating the visual illusions that we have discussed, the brain is using valid principles, but faulty information about such factors as relative distance or perspective. The overall result (our perception) is incorrect. In summary, the distance cues and principles the brain uses to give us an accurate view of the external world work almost all of the time, but these same cues and principles sometimes cause misperceptions.
Section Summary
In this section, we looked at visual perception in more detail. Bottom-up and top-down processing are both necessary for smooth and efficient perception. While top-down processing is adaptive, as illustrated by perceptual constancy, it is also responsible for the subjective nature of perception. Perceptual bias and contextual perceptual effects are good examples of how our past experiences, beliefs, and expectations guide our interpretation of the world.
Perceptual organization and perceptual constancy are essential processes for giving order to incoming sensory input. Gestalt psychologists proposed many principles that guide the organization of sensory input into meaningful holistic objects, such as the figure-and-ground and closure principles. In addition to organizing the sensory input into meaningful objects, the brain must maintain constancy in its perception of the world. To achieve perceptual constancy, the brain uses top-down processing to change sensory input to maintain an object’s normal size, shape, brightness, and color in our perception of the object.
Depth perception (the judgment of the distance of objects from us) is a crucial part of visual perception. To judge depth, the brain uses information from binocular cues, such as retinal disparity, and monocular cues, such as linear perspective and interposition. The brain’s perception of object size is related to its distance from us. As an object gets farther away from us, its size on our retina decreases. However, sometimes the brain applies this geometric principle relating retinal image size to distance and creates a misperception (an illusion). The Ponzo, Terror Subterra, Müller-Lyer, Turning the Tables, and moon illusions are good examples of such misapplication. In each case, the brain incorrectly judges that the two objects involved in the illusion, which have equal retinal image sizes, are at varying distances, and so it mistakenly makes the object judged to be farther away larger in our perception.
3
Question
3.9
Explain why perceptual processing requires both bottom-up and top-down processing.
Perceptual processing requires both types of processing because without bottom-up processing you would have nothing to perceive and without top-down processing you would have no knowledge to use to interpret the bottom-up input.
Question
3.10
Explain how the top-down processing involved in context effects on perception is similar to that involved in using the Gestalt organizational principle of closure.
The similarity is that, in both cases, the brain uses top-down processing to complete the perception. In context effects, the brain uses the present context to complete the perception by determining what would be meaningful in that particular context. In closure, the brain uses the incomplete part of an object to determine what the remaining part should be in order for it to be a meaningful object.
Question
3.11
Explain why seeing one of your professors in a local grocery store makes it more difficult to recognize her.
It is more difficult to recognize your professor because she is in a very different context. Your brain is thrown for a “perceptual loop” because she doesn’t fit in this context (outside the classroom). This is why it takes your brain longer to find the relevant top-down knowledge.
Question
3.12
Explain why the brain’s application of the geometric relationship between retinal image size of an object and its distance from us leads the brain to create the Ponzo, Müller-Lyer, and moon illusions.
The retinal image sizes of the two objects in each case are equal because the two objects are actually equal in size and are equidistant from us. Available distance cues, however, lead the brain to believe mistakenly that one of the two objects in each case is farther away. Therefore, the brain enlarges the size of the object that it thinks is more distant because this would have to be the case in order for the geometric relationship between retinal image size and distance from us to hold. For example, in the Ponzo illusion, the linear perspective distance cue leads the brain to think that the top horizontal bar is farther away. Because the two horizontal bars have identical retinal image sizes, the brain then uses the geometric relationship and mistakenly creates an illusion by making the top bar larger in our perception.