Making Sense of Data: A Statistics Primer
943
This appendix is designed help you understand the analysis of biological data in a statistical context. We outline major concepts involved in the collection and analysis of data, and we present basic statistical analyses that will help you interpret, understand, and complete the Apply the Concept and Analyze the Data problems throughout this book. Understanding these concepts will also help you understand and interpret scientific studies in general. We present formulas for some common statistical tests as examples, but the main purpose of this appendix is to help you understand the purpose and reasoning behind these tests. Once you understand the basis of an analysis, you may wish to use one of many free, online websites for conducting the tests (such as http://vassarstats.net).
Why Do We Do Statistics?
Almost Everything Varies
We live in a variable world, but within the variation we see among biological organisms there are predictable patterns. We use statistics to find and analyze these patterns. Consider any group of common things in nature—all women aged 22, all the cells in your liver, or all the blades of grass in your yard. Although they will have many similar characteristics, they will also have important differences. Men aged 22 tend to be taller than women aged 22, but of course not every man will be taller than every woman in this age group.
Natural variation can make it difficult to find general patterns. For example, scientists have determined that smoking increases the risk of getting lung cancer. But we know that not all smokers will develop lung cancer and not all nonsmokers will remain cancer-free. If we compare just one smoker with just one nonsmoker, we may end up drawing the wrong conclusion. So how did scientists discover this general pattern? How many smokers and nonsmokers did they examine before they felt confident about the risk of smoking?
Statistics helps us find and describe general patterns in nature, and draw conclusions from those patterns.
Avoiding False Positives and False Negatives
When a woman takes a pregnancy test, there is some chance that it will be positive even if she is not pregnant, and there is some chance that it will be negative even if she is pregnant. We call these kinds of mistakes “false positives” and “false negatives.”
Doing science is a bit like taking a medical test. We observe patterns in the world, and we try to draw conclusions about how the world works from those observations. Sometimes our observations lead us to draw the wrong conclusions. We might conclude that a phenomenon occurs, when it actually does not; or we might conclude that a phenomenon does not occur, when it actually does.
For example, planet Earth has been warming over the past century (see Concept 45.4). Ecologists are interested in whether plant and animal populations have been affected by global warming. If we have long-term information about the locations of species and about temperatures in certain areas, we can determine whether shifts in species distributions coincide with temperature changes. Such information, however, can be very complicated. Without proper statistical methods, one may not be able to detect the true impact of temperature, or instead may think a pattern exists when it does not.
Statistics helps us avoid drawing the wrong conclusions.
How Does Statistics Help Us Understand the Natural World?
Statistics is essential to scientific discovery. Most biological studies involve five basic steps, each of which requires statistics:
- Step 1: Experimental Design
Clearly define the scientific question and the methods necessary to tackle the question. - Step 2: Data Collection
Gather information about the natural world through observations and experiments. - Step 3: Organize and Visualize the Data
Use tables, graphs, and other useful representations to gain intuition about the data. - Step 4: Summarize the Data
Summarize the data with a few key statistical calculations. - Step 5: Inferential Statistics
Use statistical methods to draw general conclusions from the data about the world and the ways it works.
Step 1: Experimental Design
We make observations and conduct experiments to gain knowledge about the world. Scientists come up with scientific ideas based on prior research and their own observations. These ideas start as a question such as “Does smoking cause cancer?” From prior experience, scientists then propose possible answers to the question in the form of hypotheses such as “Smoking increases the risk of cancer.” Experimental design then involves devising comparisons that can test predictions of the hypotheses. For example, if we are interested in evaluating the hypothesis that smoking increases cancer risk, we might decide to compare the incidence of cancer in nonsmokers and smokers. Our hypothesis would predict that the cancer incidence is higher in smokers than in nonsmokers. There are various ways we could make that comparison. We could compare the smoking history of people newly diagnosed with cancer with that of people whose tests came out negative for cancer. Alternatively, we could assess the current smoking habits of a sample of people and see whether those who smoke more heavily are more likely to develop cancer in, say, 5 years. Statistics provides us with tools for assessing which approach will provide us with an answer with smaller costs in time and effort in data collection and analysis.
944
We use statistics to guide us in planning exactly how to make our comparisons—what kinds of data and how many observations we will need to collect.
Step 2: Data Collection
Taking Samples
When biologists gather information about the natural world, they typically collect representative pieces of information, called data or observations. For example, when evaluating the efficacy of a candidate drug for medulloblastoma brain cancer, scientists may test the drug on tens or hundreds of patients, and then draw conclusions about its efficacy for all patients with these tumors. Similarly, scientists studying the relationship between body weight and clutch size (number of eggs) for female spiders of a particular species may examine tens to hundreds of spiders to make their conclusions.
We use the expression “sampling from a population” to describe this general method of taking representative pieces of information from the system under investigation (FIGURE B1). The pieces of information together make up a sample of the larger system, or population. In the cancer therapy example, each observation was the change in a patient’s tumor size 6 months after initiating treatment, and the population of interest was all individuals with medulloblastoma tumors. In the spider example, each observation was a pair of measurements—body weight and clutch size—for a single female spider, and the population of interest was all female spiders of this species.
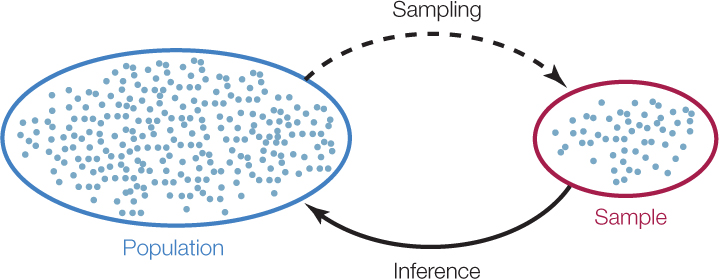
Sampling is a matter of necessity, not laziness. We cannot hope (and would not want) to collect and weigh all of the female spiders of the species of interest on Earth! Instead, we use statistics to determine how many spiders we must collect to confidently infer something about the general population and then use statistics again to make such inferences.
Data Come in All Shapes and Sizes
In statistics we use the word “variable” to mean a measurable characteristic of an individual component of a system. Some variables are on a numerical scale, such as the daily high temperature or the clutch size of a spider. We call these quantitative variables. Quantitative variables that take on only whole number values (such as spider clutch size) are called discrete variables, whereas variables that can also take on a fractional value (such as temperature) are called continuous variables.
945
Other variables take categories as values, such as a human blood type (A, B, AB, or O) or an ant caste (queen, worker, or male). We call these categorical variables. Categorical variables with a natural ordering, such as a final grade in Introductory Biology (A, B, C, D, or F), are called ordinal variables.
Each class of variables comes with its own set of statistical methods. We will introduce a few common methods in this appendix that will help you work on the problems presented in this book, but you should consult a biostatistics textbook for more advanced tests and analyses for other data sets and problems.
Step 3: Organize and Visualize the Data
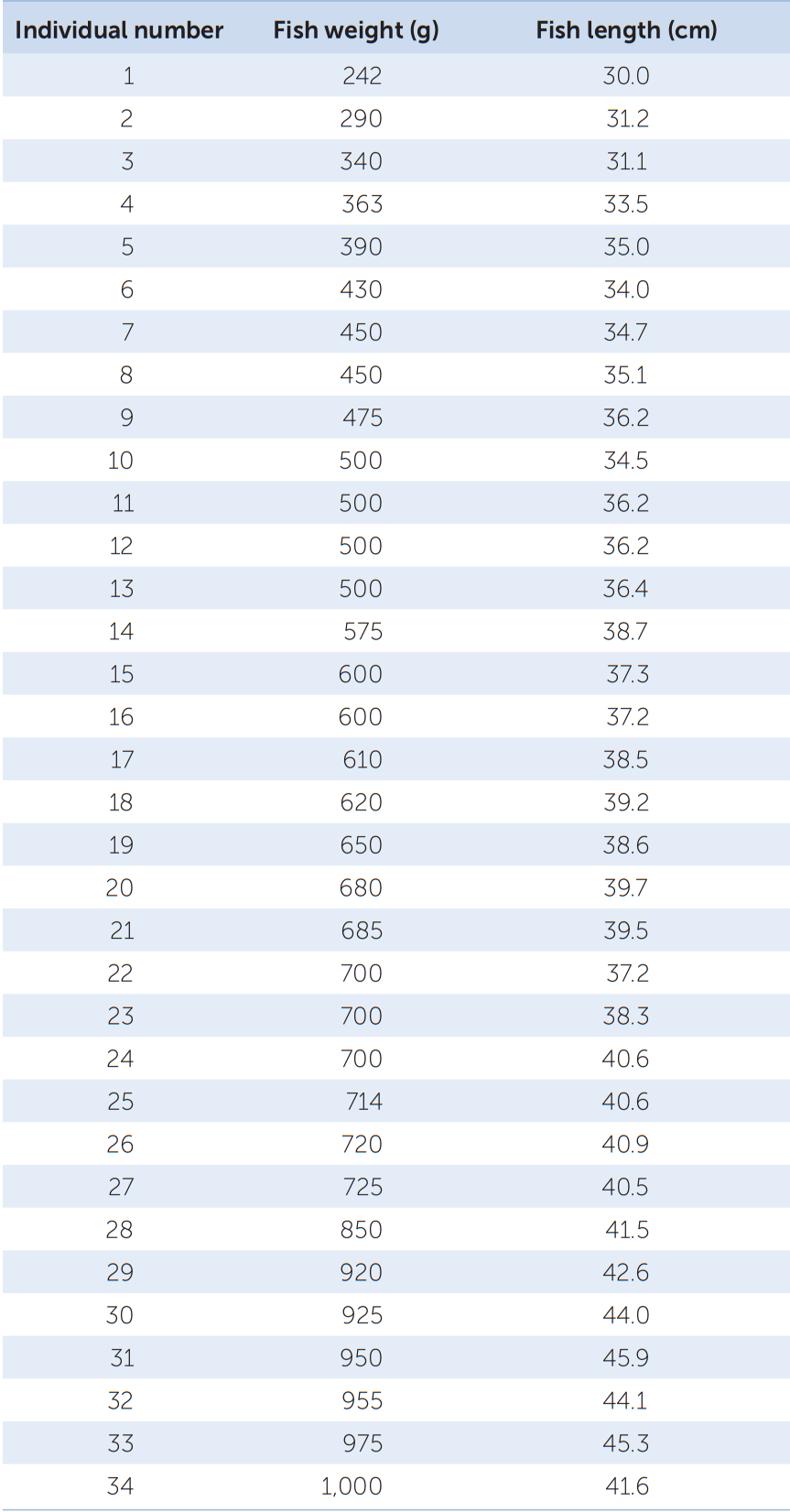
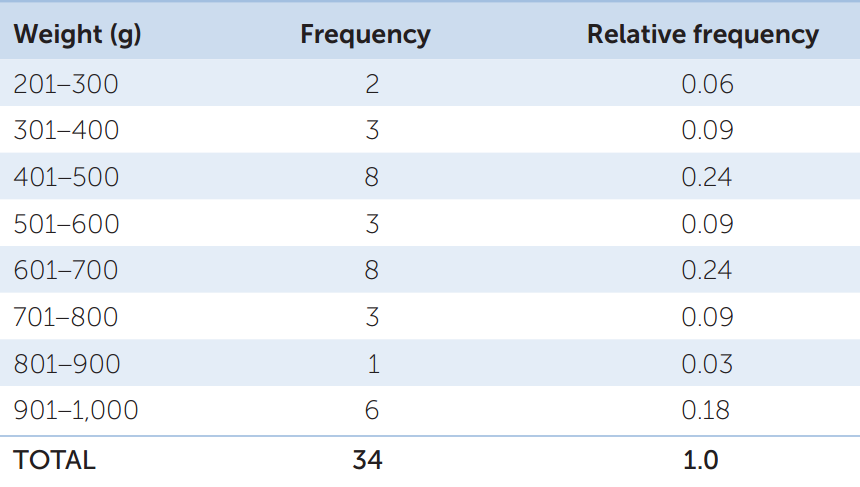
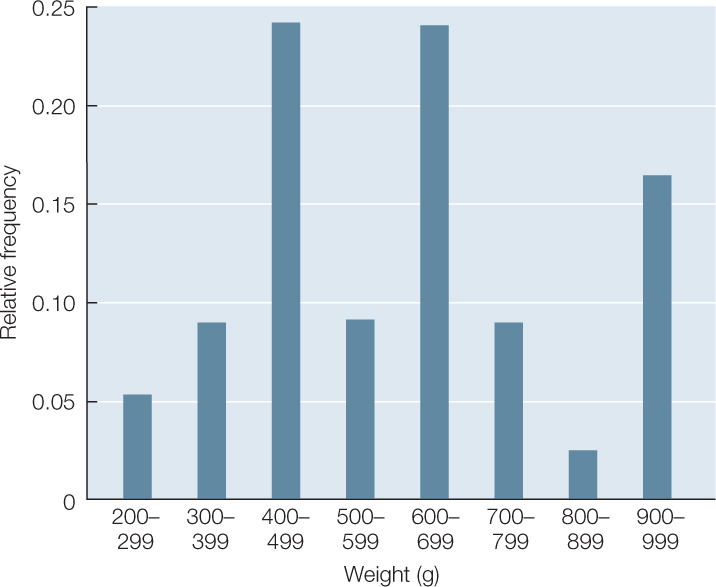
Your data consist of a series of values of the variable or variables of interest, each from a separate observation. For example, TABLE B1 shows the weight and length of 34 fish (Abramis brama) from Lake Laengelmavesi in Finland. From this list of numbers, it’s hard to get a sense of how big the fish in the lake are, or how variable they are in size. It’s much easier to gain intuition about your data if you organize them. One way to do this is to group (or bin) your data into classes, and count up the number of observations that fall into each class. The result is a frequency distribution. TABLE B2 shows the fish weight data as a frequency distribution. For each 100-gram weight class, Table B2 shows the number, or frequency, of observations in that weight class, as well as the relative frequency (proportion of the total) of observations in that weight class. Notice that the data take up much less space when organized in this fashion. Also notice that we can now see that most of the fish fall in the middle of the weight range, with relatively few very small or very large fish.

Go to MEDIA CLIP B1 Interpreting Frequency Distributions
PoL2e.com/mcB1
It is even easier to visualize the frequency distribution of fish weights if we graph them in the form of a histogram such as the one in FIGURE B2. When grouping quantitative data, it is necessary to decide how many classes to include. It is often useful to look at multiple histograms before deciding which grouping offers the best representation of the data.
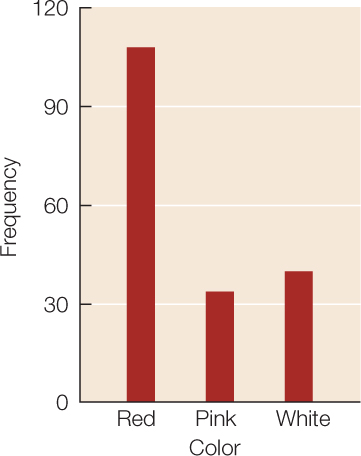
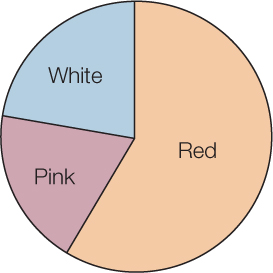
Frequency distributions are also useful ways of summarizing categorical data. TABLE B3 shows a frequency distribution of the colors of 182 poinsettia plants (red, pink, or white) resulting from an experimental cross between two parent plants. Notice that, as with the fish example, the table is a much more compact way to present the data than a list of 182 color observations would be. For categorical data, the possible values of the variable are the categories themselves, and the frequencies are the number of observations in each category. We can visualize frequency distributions of categorical data like this by constructing a bar chart. The heights of the bars indicate the number of observations in each category (FIGURE B3). Another way to display the same data is in a pie chart, which shows the proportion of each category represented like pieces of a pie (FIGURE B4).

946
Sometimes we wish to compare two quantitative variables. For example, the researchers at Lake Laengelmavesi investigated the relationship between fish weight and length, from the data presented in Table B1. We can visualize this relationship using a scatter plot in which the weight and length of each fish is represented as a single point (FIGURE B5). These two variables have a positive relationship since the slope of a line drawn through the points is positive. As the length of a fish increases, its weight tends to increase in an approximately linear manner.
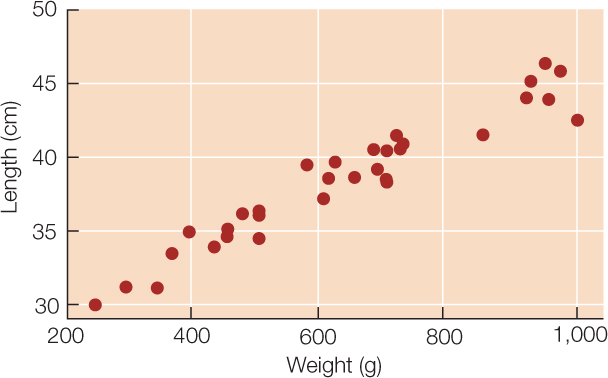
Tables and graphs are critical to interpreting and communicating data, and thus should be as self-contained and understandable as possible. Their content should be easily understood simply by looking at them. Axes, captions, and units should be clearly labeled, statistical terms should be defined, and appropriate groupings should be used when tabulating or graphing quantitative data.
Step 4: Summarize the Data
A statistic is a numerical quantity calculated from data, whereas descriptive statistics are quantities that describe general patterns in data. Descriptive statistics allow us to make straightforward comparisons among different data sets and concisely communicate basic features of our data.
Describing Categorical Data
For categorical variables, we typically use proportions to describe our data. That is, we construct tables containing the proportions of observations in each category. For example, the third column in Table B3 provides the proportions of poinsettia plants in each color category, and the pie chart in Figure B4 provides a visual representation of those proportions.
Describing Quantitative Data
For quantitative data, we often start by calculating measures of center, quantities that roughly tell us where the center of our data lies. There are three commonly used measures of center:
- The mean, or average value, of our sample is simply the sum of all the values in the sample divided by the number of observations in our sample (FIGURE B6).
- The median is the value at which there are equal numbers of smaller and larger observations.
- The mode is the most frequent value in the sample.
RESEARCH TOOLS: FIGURE B6 Descriptive Statistics for Quantitative Data
Below are the equations used to calculate the descriptive statistics we discuss in this appendix. You can calculate these statistics yourself, or use free internet resources to help you make your calculations.
Notation:
x1, x2, x3,…xn are the n observations of variable X in the sample.

In regression, the independent variable is X, and the dependent variable is Y. b0 is the vertical intercept of a regression line. b1 is the slope of a regression line.
Equations
- Mean:
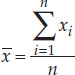
- Standard deviation: s =
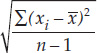
- Correlation coefficient: r =
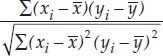
- Least-squares regression line: Y = b0 + b1X where
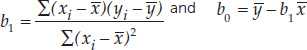
- Standard error of the mean:
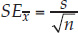
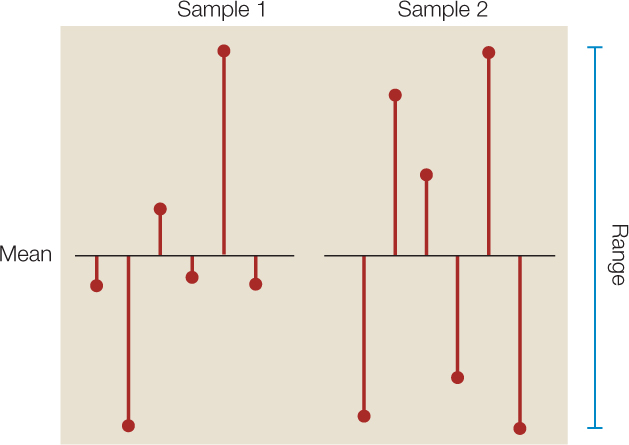
It is often just as important to quantify the variation in the data as it is to calculate its center. There are several statistics that tell us how much the values differ from one another. We call these measures of dispersion. The easiest one to understand and calculate is the range, which is simply the largest value in the sample minus the smallest value. The most commonly used measure of dispersion is the standard deviation, which calculates the extent to which the data are spread out from the mean. A deviation is the difference between an observation and the mean of the sample. The standard deviation is a measure of how far the average observation in the sample is from the sample mean. Two samples can have the same range, but very different standard deviations if observations in one are clustered closer to the mean than in the other. In FIGURE B7, for example, sample 1 has a smaller standard deviation (s = 2.6) than does sample 2 (s = 3.6), even though the two samples have the same means and ranges.
947
To demonstrate these descriptive statistics, let’s return to the Lake Laengelmavesi study (see the data in Table B1). The mean weight of the 34 fish (see equation 1 in Figure B6) is:
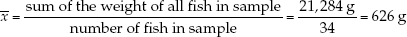
Since there is an even number of observations in the sample, then the median weight is the value halfway between the two middle values:
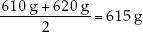
The mode of the sample is 500 g, which appears 4 times. The standard deviation (see equation 2 in Figure B6) is:
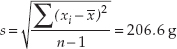
and the range is 1,000 g - 242 g = 758 g.
Describing the Relationship Between Two Quantitative Variables
Biologists are often interested in understanding the relationship between two different quantitative variables: How does the height of an organism relate to its weight? How does air pollution relate to the prevalence of asthma? How does lichen abundance relate to levels of air pollution? Recall that scatter plots visually represent such relationships.
We can quantify the strength of the relationship between two quantitative variables using a single value called the Pearson product–moment correlation coefficient (see equation 3 in Figure B6). This statistic ranges between –1 and 1 and tells us how closely the points in a scatter plot conform to a straight line. A negative correlation coefficient indicates that one variable decreases as the other increases; a positive correlation coefficient indicates that the two variables increase together; and a correlation coefficient of zero indicates that there is no linear relationship between the two variables (FIGURE B8).
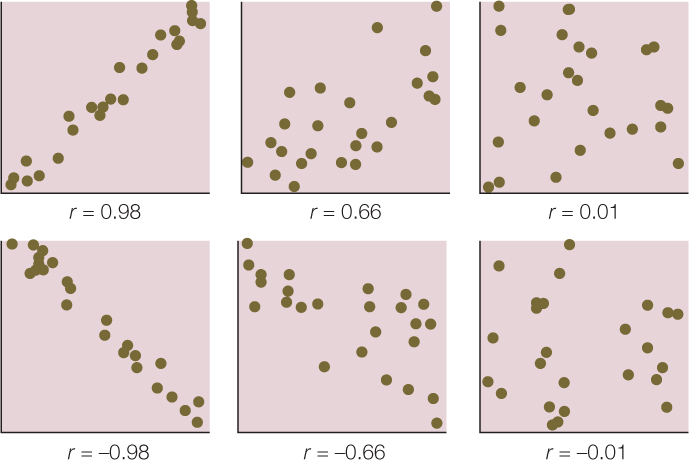
One must always keep in mind that correlation does not mean causation. Two variables can be closely related without one causing the other. For example, the number of cavities in a child’s mouth correlates positively with the size of his or her feet. Clearly cavities do not enhance foot growth; nor does foot growth cause tooth decay. Instead the correlation exists because both quantities tend to increase with age.
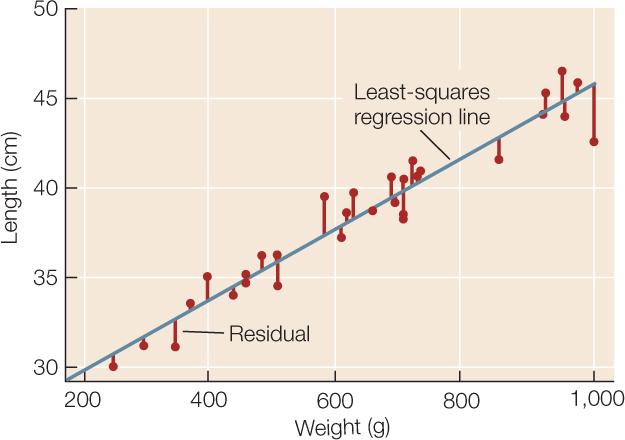
Intuitively, the straight line that tracks the cluster of points on a scatter plot tells us something about the typical relationship between the two variables. Statisticians do not, however, simply eyeball the data and draw a line by hand. They often use a method called least-squares linear regression to fit a straight line to the data (see equation 4 in Figure B6). This method calculates the line that minimizes the overall vertical distances between the points in the scatter plot and the line itself. These distances are called residuals (FIGURE B9). Two parameters describe the regression line: b0 (the vertical intercept of the line, or the expected value of variable Y when X = 0), and b1 (the slope of the line, or how much values of Y are expected to change with changes in values of X).
948
Step 5: Inferential Statistics
Data analysis often culminates with statistical inference—an attempt to draw general conclusions about the system under investigation—the larger population—from observations of a representative sample (see Figure B1). When we test a new medulloblastoma brain cancer drug on ten patients, we do not simply want to know the fate of those ten individuals; rather, we hope to predict the drug’s efficacy on the much larger population of all medulloblastoma patients.
Statistical Hypotheses
Once we have collected our data, we want to evaluate whether or not they fit the predictions of our hypothesis. For example, we want to know whether or not cancer incidence is greater in our sample of smokers than in our sample of nonsmokers, whether or not clutch size increases with spider body weight in our sample of spiders, or whether or not growth of a sample of fertilized plants is greater than that of a sample of unfertilized plants.
Before making statistical inferences from data, we must formalize our “whether or not” question into a pair of opposing hypotheses. We start with the “or not” hypothesis, which we call the null hypothesis (denoted H0) because it often is the hypothesis that there is no difference between sample means, no correlation between variables in the sample, or no difference between our sample and an expected frequency distribution. The alternative hypothesis (denoted HA) is that there is a difference in means, that there is a correlation between variables, or that the sample distribution does differ from the expected one.
Suppose, for example, we would like to know whether or not a new vaccine is more effective than an existing vaccine at immunizing children against influenza. We have measured flu incidence in a group of children who received the new vaccine and want to compare it with flu incidence in a group of children who received the old vaccine. Our statistical hypotheses would be as follows:
H0: Flu incidence was the same in both groups of children.
HA: Flu incidence was different between the two groups of children.
In the next few sections we will discuss how we decide when to reject the null hypothesis in favor of the alternative hypothesis.
Jumping To The Wrong Conclusions
There are two ways that a statistical test can go wrong (FIGURE B10). We can reject the null hypothesis when it is actually true (Type I error), or we can accept the null hypothesis when it is actually false (Type II error). These kinds of errors are analogous to false positives and false negatives in medical testing, respectively. If we mistakenly reject the null hypothesis when it is actually true, then we falsely endorse the incorrect hypothesis. If we are unable to reject the null hypothesis when it is actually false, then we fail to realize a yet undiscovered truth.
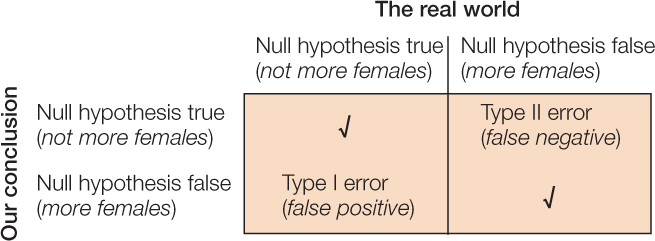
Suppose we would like to know whether there are more females than males in a population of 10,000 individuals. To determine the makeup of the population, we choose 20 individuals randomly and record their sex. Our null hypothesis is that there are not more females than males; and our alternative hypothesis is that there are. The following scenarios illustrate the possible mistakes we might make:
- Scenario 1: The population actually has 40% females and 60% males. Although our random sample of 20 people is likely to be dominated by males, it is certainly possible that, by chance, we will end up choosing more females than males. If this occurs, and we mistakenly reject the null hypothesis (that there are not more females than males), then we make a Type I error.
- Scenario 2: The population actually has 60% females and 40% males. If, by chance, we end up with a majority of males in our sample and thus fail to reject the null hypothesis, then we make a Type II error.
Fortunately, statistics has been developed precisely to avoid these kinds of errors and inform us about the reliability of our conclusions. The methods are based on calculating the probabilities of different possible outcomes. Although you may have heard or even used the word “probability” on multiple occasions, it is important that you understand its mathematical meaning. A probability is a numerical quantity that expresses the likelihood of some event. It ranges between zero and one; zero means there is no chance the event will occur, and one means the event is guaranteed to occur. This only makes sense if there is an element of chance, that is, if it is possible the event will occur and possible that it will not occur. For example, when we flip a fair coin, it will land on heads with probability 0.5 and land on tails with probability 0.5. When we select individuals randomly from a population with 60% females and 40% males, we will encounter a female with probability 0.6 and a male with probability 0.4.
949
Probability plays a very important role in statistics. To draw conclusions about the real world (the population) from our sample, we first calculate the probability of obtaining our sample if the null hypothesis is true. Specifically, statistical inference is based on answering the following question:
Suppose the null hypothesis is true. What is the probability that a random sample would, by chance, differ from the null hypothesis as much as our sample differs from the null hypothesis?
If our sample is highly improbable under the null hypothesis, then we rule it out in favor of our alternative hypothesis. If, instead, our sample has a reasonable probability of occurring under the null hypothesis, then we conclude that our data are consistent with the null hypothesis and we do not reject it.
Returning to the sex ratio example, let’s consider two new scenarios:
- Scenario 3: Suppose we want to infer whether or not females constitute the majority of the population (our alternative hypothesis) based on a random sample containing 12 females and 8 males. We would calculate the probability that a random sample of 20 people includes at least 12 females assuming that the population, in fact, has a 50:50 sex ratio (our null hypothesis). This probability is 0.13, which is too high to rule out the null hypothesis.
- Scenario 4: Suppose now that our sample contains 17 females and 3 males. If our population is truly evenly divided, then this sample is much less likely than the sample in scenario 3. The probability of such an extreme sample is 0.0002, and would lead us to rule out the null hypothesis and conclude that there are more females than males.
This agrees with our intuition. When choosing 20 people randomly from an evenly divided population, we would be surprised if almost all of them were female, but would not be surprised at all if we ended up with a few more females than males (or a few more males than females). Exactly how many females do we need in our sample before we can confidently infer that they make up the majority of the population? And how confident are we when we reach that conclusion? Statistics allows us to answer these questions precisely.
Statistical Significance: Avoiding False Positives
Whenever we test hypotheses, we calculate the probability just discussed, and refer to this value as the P-value of our test. Specifically, the P-value is the probability of getting data as extreme as our data (just by chance) if the null hypothesis is in fact true. In other words, it is the likelihood that chance alone would produce data that differ from the null hypothesis as much as our data differ from the null hypothesis. How we measure the difference between our data and the null hypothesis depends on the kind of data in our sample (categorical or quantitative) and the nature of the null hypothesis (assertions about proportions, single variables, multiple variables, differences between variables, correlations between variables, etc.).
For many statistical tests, P-values can be calculated mathematically. One option is to quantify the extent to which the data depart from the null hypothesis and then use look-up tables (available in most statistics textbooks or on the internet) to find the probability that chance alone would produce a difference of that magnitude. Most scientists, however, find P-values primarily by using statistical software rather than hand calculations combined with look-up tables. Regardless of the technology, the most important steps of the statistical analysis are still left to the researcher: constructing appropriate null and alternative hypotheses, choosing the correct statistical test, and drawing correct conclusions.
After we calculate a P-value from our data, we have to decide whether it is small enough to conclude that our data are inconsistent with the null hypothesis. This is decided by comparing the P-value to a threshold called the significance level, which is often chosen even before making any calculations. We reject the null hypothesis only when the P-value is less than or equal to the significance level, denoted a. This ensures that, if the null hypothesis is true, we have at most a probability a of accidentally rejecting it. Therefore the lower the value of a, the less likely you are to make a Type I error (see the lower left cell of Figure B10). The most commonly used significance level is a = 0.05, which limits the probability of a Type I error to 5%.
If our statistical test yields a P-value that is less than our significance level a, then we conclude that the effect described by our alternative hypothesis is statistically significant at the level a and we reject the null hypothesis. If our P-value is greater than a, then we conclude that we are unable to reject the null hypothesis. In this case, we do not actually reject the alternative hypothesis, rather we conclude that we do not yet have enough evidence to support it.
Power: Avoiding False Negatives
The power of a statistical test is the probability that we will correctly reject the null hypothesis when it is false (see the lower right cell of Figure B10). Therefore the higher the power of the test, the less likely we are to make a Type II error (see the upper right cell of Figure B10). The power of a test can be calculated, and such calculations can be used to improve your methodology. Generally, there are several steps that can be taken to increase power and thereby avoid false negatives:
- Decrease the significance level, a. The higher the value of a, the harder it is to reject the null hypothesis, even if it is actually false.
- Increase the sample size. The more data one has, the more likely one is to find evidence against the null hypothesis, if it is actually false.
- Decrease variability in the sample. The more variation there is in the sample, the harder it is to discern a clear effect (the alternative hypothesis) when it actually exists.
It is always a good idea to design your experiment to reduce any variability that may obscure the pattern you seek to detect. For example, it is possible that the chance of a child contracting influenza varies depending on whether he or she lives in a crowded (e.g., urban) environment or one that is less so (e.g., rural). To reduce variability, a scientist might choose to test a new influenza vaccine only on children from one environment or the other. After you have minimized such extraneous variation, you can use power calculations to choose the right combination of a and sample size to reduce the risks of Type I and Type II errors to desirable levels.
There is a trade-off between Type I and Type II errors: as a increases, the risk of a Type I error decreases but the risk of a Type II error increases. As discussed above, scientists tend to be more concerned about Type I than Type II errors. That is, they believe it is worse to mistakenly believe a false hypothesis than it is to fail to make a new discovery. Thus they prefer to use low values of a. However, there are many real-world scenarios in which it would be worse to make a Type II error than a Type I error. For example, suppose a new cold medication is being tested for dangerous (life-threatening) side effects. The null hypothesis is that there are no such side effects. A Type II error might lead regulatory agencies to approve a harmful medication that could cost human lives. In contrast, a Type I error would simply mean one less cold medication among the many that already line pharmacy shelves. In such cases, policymakers take steps to avoid a Type II error, even if, in doing so, they increase the risk of a Type I error.
Statistical Inference With Quantitative Data
Statistics that describe patterns in our samples are used to estimate properties of the larger population. Earlier we calculated the mean weight of a sample of Abramis brama in Lake Laengelmavesi, which provided us with an estimate of the mean weight of all the Abramis brama in the lake. But how close is our estimate to the true value in the larger population? Our estimate from the sample is unlikely to exactly equal the true population value. For example, our sample of Abramis brama may, by chance, have included an excess of large individuals. In this case, our sample would overestimate the true mean weight of fish in the population.
The standard error of a sample statistic (such as the mean) is a measure of how close it is likely to be to the true population value. The standard error of the mean, for example, provides an estimate of how far we might expect a sample mean to deviate from the true population mean. It is a function of how much individual observations vary within samples (the standard deviation) and the size of the sample (n). Standard errors increase with the degree of variation within samples, and they decrease with the number of observations in a sample (because large samples provide better estimates about the underlying population than do small samples). For our sample of 34 Abramis brama, we would calculate the standard error of the mean using equation 5 in Figure B6:
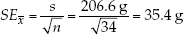
The standard error of a statistic is related to the confidence interval—a range around the sample statistic that has a specified probability of including the true population value. The formula we use to calculate confidence intervals depends on the characteristics of the data, and the particular statistic. For many types of continuous data, the bounds of the 95% confidence interval of the mean can be calculated by taking the mean and adding and subtracting 1.96 times the standard error of the mean. Consider our sample of 34 Abramis brama, for example. We would say that the mean of 626 grams has a 95% confidence interval from 556.6 grams to 695.4 grams (626 ± 69.4 grams). If all our assumptions about our data have been met, we would expect the true population mean to fall in this confidence interval 95% of the time.
Researchers typically use graphs or tables to report sample statistics (such as the mean) as well as some measure of confidence in them (such as their standard error or a confidence interval). This book is full of examples. If you understand the concepts of sample statistics, standard errors, and confidence intervals, you can see for yourself the major patterns in the data, without waiting for the authors to tell you what they are. For example, if samples from two groups have 95% confidence intervals of the mean that do not overlap, then you can conclude that it is unlikely that the groups have the same true mean.

Go to ANIMATED TUTORIAL B1 Standard Deviations, Standard Errors, and Confidence Intervals
PoL2e.com/atB1
Biologists conduct statistical tests to obtain more precise estimates of the probability of observing a given difference between samples if the null hypothesis that there is no difference in the populations is true. The appropriate test depends on the nature of the data and the experimental design. For example, we might want to calculate the probability that the mean weights of two different fish species in Lake Laengelmavesi, Abramis brama and Leusiscus idus, are the same. A simple method for comparing the means of two groups is the t-test, described in FIGURE B11. We looked earlier at data for Abramis brama; the researchers who collected these data also collected weights for six individuals of Leusiscus idus: 270, 270, 306, 540, 800, and 1,000 grams. We begin by stating our hypotheses and choosing a significance level:
RESEARCH TOOLS: FIGURE B11 The {em}t{/em}-test
What is the t-test? It is a standard method for assessing whether the means of two groups are statistically different from each another.
- Step 1: State the null and alternative hypotheses:
- H0: The two populations have the same mean.
- HA: The two populations have different means.
- Step 2: Choose a significance level, a, to limit the risk of a Type I error.
- Step 3: Calculate the test statistic: ts =
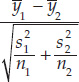
Notation: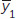 and
and 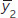 are the sample means; s1 and s2 are the sample standard deviations; and n1 and n2 are the sample sizes.
are the sample means; s1 and s2 are the sample standard deviations; and n1 and n2 are the sample sizes. - Step 4: Use the test statistic to assess whether the data are consistent with the null hypothesis:
Calculate the P-value (P) using statistical software or by hand using statistical tables. - Step 5: Draw conclusions from the test:
- If P = a, then reject H0, and conclude that the population distribution is significantly different.
- If P > a, then we do not have sufficient evidence to conclude that the means differ.
- H0: Abramis brama and Leusiscus idus have the same mean weight.
- HA: Abramis brama and Leusiscus idus have different mean weights.
- a = 0.05
951
The test statistic is calculated using the means, standard deviations, and sizes of the two samples:
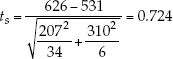
We can use statistical software or one of the free statistical sites on the internet to find that the P-value for this result is P = 0.497. Since P is considerably greater than a, we fail to reject the null hypothesis and conclude that our study does not provide evidence that the two species have different mean weights.
You may want to consult an introductory statistics textbook to learn more about confidence intervals, t-tests, and other basic statistical tests for quantitative data.
Statistical Inference With Categorical Data
With categorical data, we often wish to ask whether the frequencies of observations in different categories are consistent with a hypothesized frequency distribution. We can use a chi-square goodness-of-fit test to answer this question.
FIGURE B12 outlines the steps of a chi-square goodness-of-fit-test. As an example, consider the data described in Table B3. Many plant species have simple Mendelian genetic systems in which parent plants produce progeny with three different colors of flowers in a ratio of 2:1:1. However, a botanist believes that these particular poinsettia plants have a different genetic system that does not produce a 2:1:1 ratio of red, pink, and white plants. A chi-square goodness-of-fit can be used to assess whether or not the data are consistent with this ratio, and thus whether or not this simple genetic explanation is valid. We start by stating our hypotheses and significance level:
RESEARCH TOOLS: FIGURE B12 The Chi-Square Goodness-of-Fit Test
What is the chi-square goodness-of-fit test? It is a standard method for assessing whether a sample came from a population with a specific distribution.
- Step 1: State the null and alternative hypotheses:
- H0: The population has the specified distribution.
- HA: The population does not have the specified distribution.
- Step 2: Choose a significance level, a, to limit the risk of a Type I error.
- Step 3: Determine the observed frequency and expected frequency for each category:
- The observed frequency of a category is simply the number of observations in the sample of that type.
- The expected frequency of a category is the probability of the category specified in H0 multiplied by the overall sample size.
- Step 4: Calculate the test statistic:
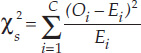
Notation: C is the total number of categories, Oi is the observed frequency of category i, and E1 is the expected frequency of category i. - Step 5: Use the test statistic to assess whether the data are consistent with the null hypothesis:
- Calculate the P-value (P) using statistical software or by hand using statistical tables.
- Step 6: Draw conclusions from the test:
- If P = a, then reject H0, and conclude that the population distribution is significantly different than the distribution specified by H0.
- If P > a, then we do not have sufficient evidence to conclude that population has a different distribution.
H0: The progeny of this type of cross have the following probabilities of each flower color:
Pr{Red} = .50, Pr{Pink} = .25, Pr{White} = .25
HA: At least one of the probabilities of H0 is incorrect. a = 0.05
We next use the probabilities in H0 and the sample size to calculate the expected frequencies:

Based on these quantities, we calculate the chi-square test statistic:
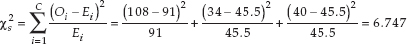
952
We find the P-value for this result to be P = 0.034 using statistical software. Since P is less than a, we reject the null hypothesis and conclude that the botanist is likely correct: the plant color patterns are not explained by the simple Mendelian genetic model under consideration.
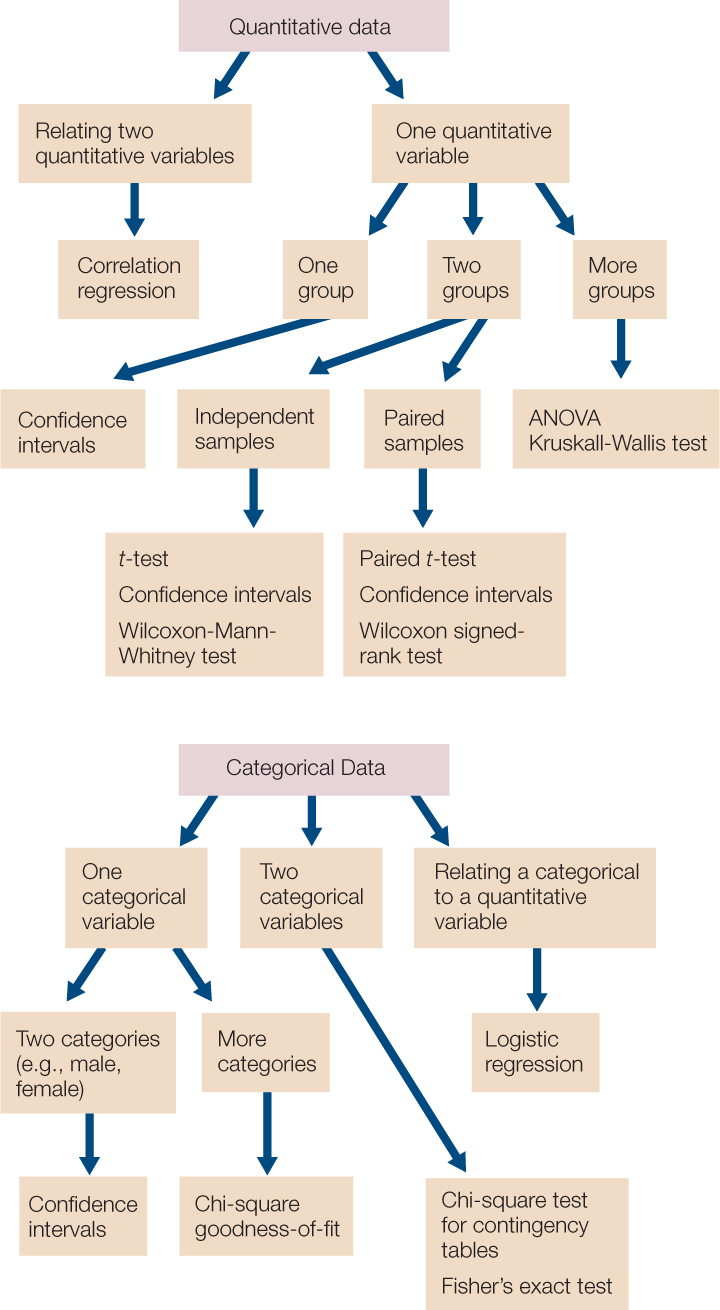
This introduction is meant to provide only a brief introduction to the concepts of statistical analysis, with a few example tests. FIGURE B13 provides a summary of some of the commonly used statistical tests that you may encounter in biological studies.