3.2 CHEMICAL COMPOSITION AND STRUCTURE OF DNA
By about 1950, some biologists were convinced by the work of Griffith, Avery, and others that DNA is the genetic material. To serve as the genetic material, DNA would have to be able to replicate itself, undergo rare mutations, replicate mutant forms as faithfully as the original forms, and direct the synthesis of other macromolecules in the cell. How could one molecule do all this? Part of the answer emerged in 1953, when James D. Watson and Francis H. C. Crick announced a description of the three-dimensional structure of DNA. This discovery marked a turning point in modern biology. The discovery of the structure of DNA opened the door to understanding how genetic information is stored, faithfully replicated, and altered by rare mutations.
3.2.1 A DNA strand consists of subunits called nucleotides.
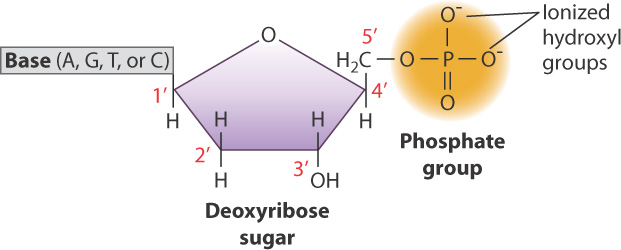
In the 50 years since the publication of Watson and Crick’s paper, we have all become familiar with the iconic double helix of DNA. The elegant shape of the twisting strands relies on the structure of DNA’s subunits, called nucleotides. As we saw in Chapter 2, nucleotides consist of three components: a 5-carbon sugar, a base, and one or more phosphate groups (Fig. 3.4). Each component plays an important role in DNA structure. The 5-carbon sugars and phosphate groups form the backbone of the molecule, with each sugar linked to the phosphate group of the neighboring nucleotide. The bases sticking out from the sugar give each nucleotide its chemical identity. Each strand of DNA consists of an enormous number of nucleotides linked one to the next.
3-5
DNA had been discovered 85 years before its three-dimensional structure was determined, and in the meantime a great deal had been learned about its chemistry, specifically the chemistry of nucleotides. Fig. 3.4 illustrates a nucleotide. In the figure, the 5-carbon sugar is indicated by the pentagon, in which each vertex represents the position of a carbon atom. By convention the carbon atoms of the sugar ring are numbered with primes (1′, 2′, and so forth, read as “one prime,” “two prime” and so forth). Technically, the sugar in DNA is 2′-deoxyribose because the chemical group projecting downward from the 2′ carbon is a hydrogen atom (−H) rather than a hydroxyl group (−OH), but for our purposes the term deoxyribose will suffice.
Note in Fig. 3.4 that the phosphate group attached to the 5′ carbon has negative charges on two of its oxygen atoms. These charges are present because at cellular pH (around 7), the free hydroxyl groups attached to the phosphorus atom are ionized by the loss of a proton, and hence are negatively charged. It is these negative charges that make DNA a mild acid, which you will recall from Chapter 2 is a molecule that tends to lose protons to the aqueous environment.
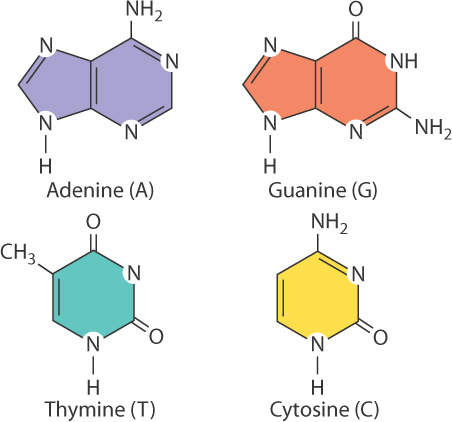
Each base is attached to the 1′ carbon of the sugar and projects above the sugar ring. A nucleotide normally contains one of four kinds of bases, denoted A, G, T, and C (Fig. 3.5). Two of the bases are double-ring structures known as purines; these are the bases adenine (A) and guanine (G), shown across the top of the figure. The other two bases are single-ring structures known as pyrimidines; these are the bases thymine (T) and cytosine (C), shown across the bottom.
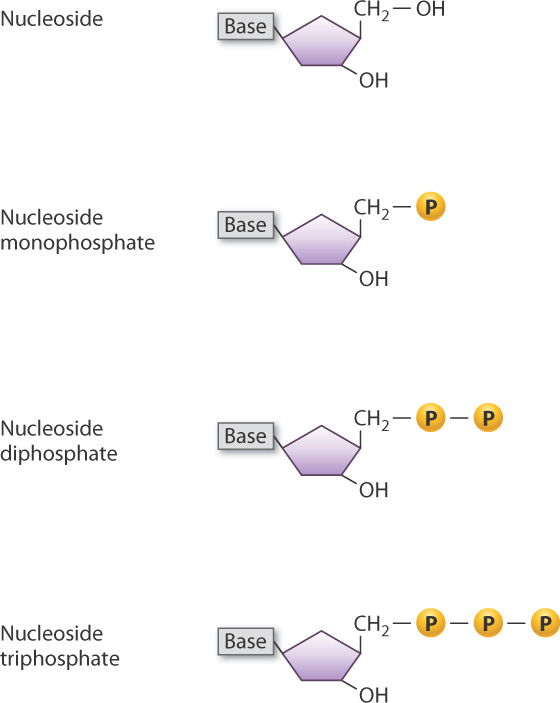
The combination of sugar and base is known as a nucleoside, which is shown in simplified form in Fig. 3.6. A nucleoside with one or more phosphate groups constitutes a nucleotide. When a nucleoside has one phosphate group attached to the 5′ carbon, it is called a nucleoside 5′-monophosphate, in which the 5′ indicates where a phosphate group is attached to the ring. The nucleotide shown in Fig. 3.4 is therefore a nucleoside 5′-monophosphate. When one of the free hydroxyl groups attached to the phosphorus atom is in turn attached to another phosphate group, the nucleotide becomes a nucleoside 5′-diphosphate and if yet another phosphate group is attached to the second, it becomes a nucleoside 5′-triphosphate (Fig. 3.6). The nucleoside triphosphates are particularly important because, as we will see later in this chapter, they are the molecules that are used to form nucleotide polymers, such as DNA and RNA. In addition, nucleoside triphosphates have other functions in the cell, notably as carriers of chemical energy in the form of ATP and GTP.
3-6
3.2.2 DNA is a linear polymer of nucleotides linked by phosphodiester bonds.
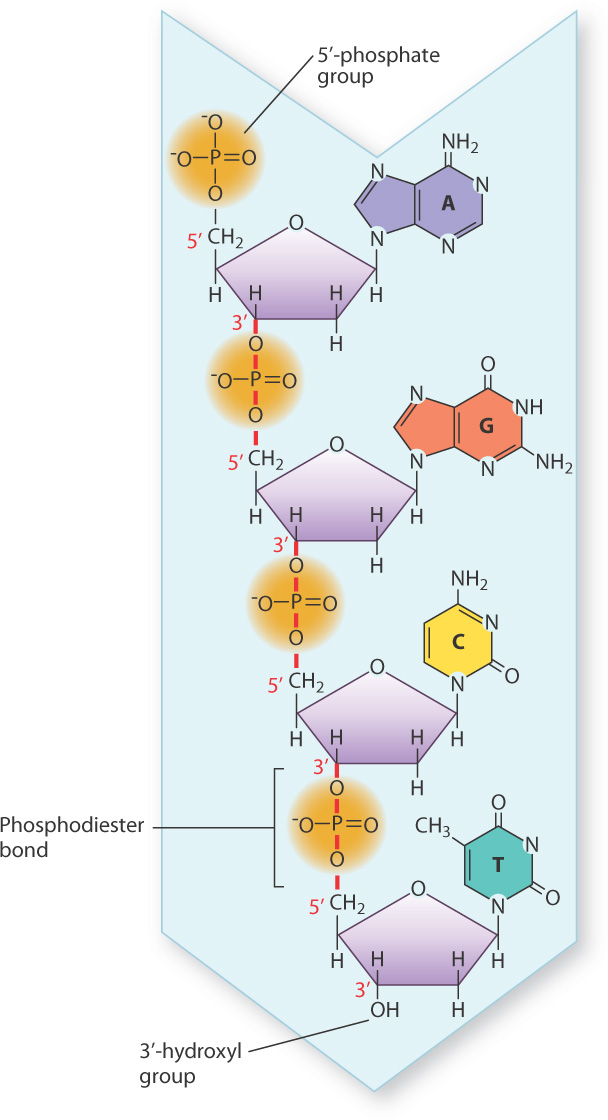
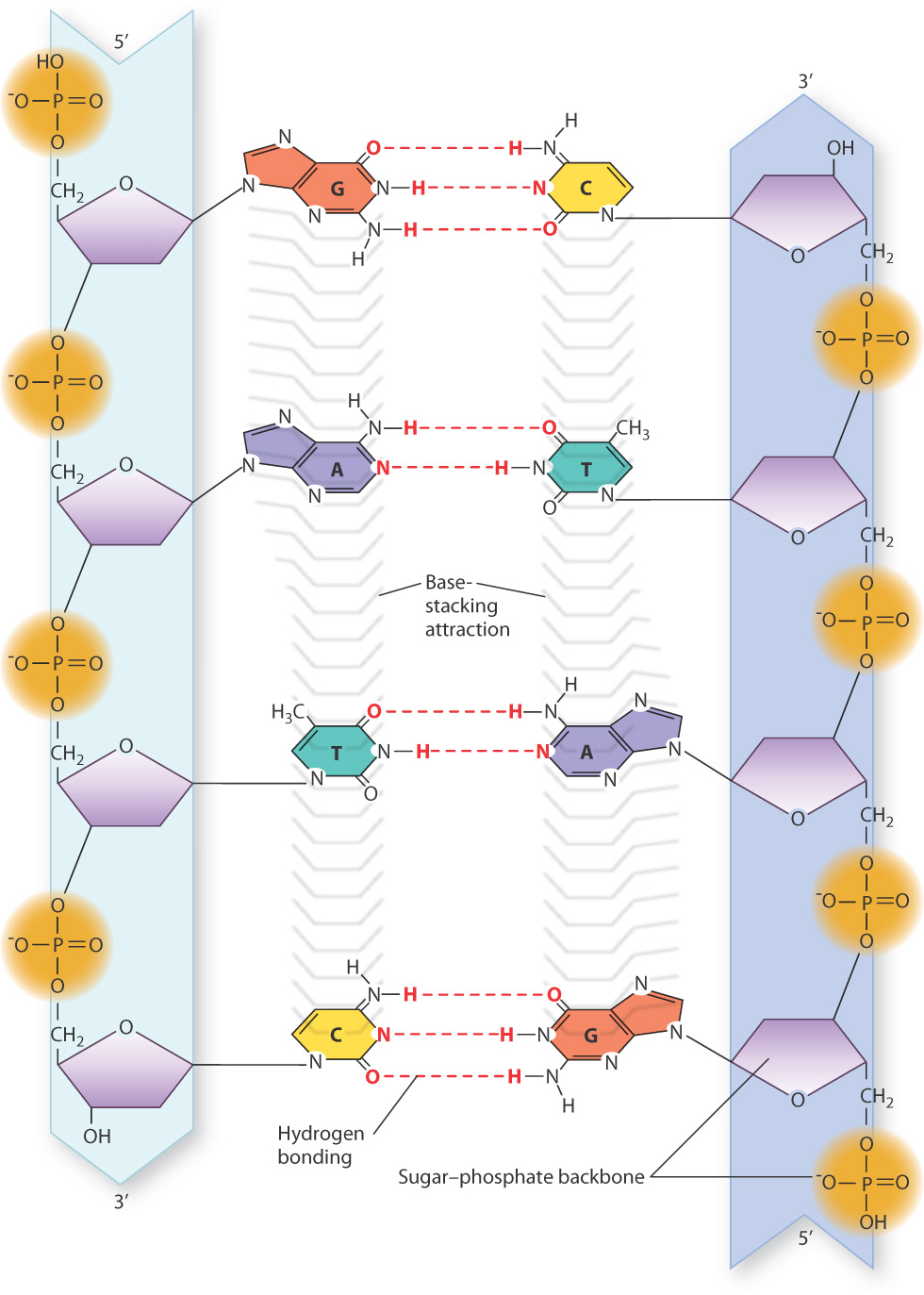
Not only were the nucleotide building blocks of DNA known before the structure was discovered, it was also known how they were linked into a polymer. The chemical linkages between nucleotides in DNA are shown in Fig. 3.7. The characteristic covalent bond that connects one nucleotide to the next is indicated by the vertical red lines that connect the 3′ carbon of one nucleotide to the 5′ carbon of the next nucleotide in line through the 5′-phosphate group. This C–O–P–O–C linkage is known as a phosphodiester bond, which in DNA is a relatively stable bond that can withstand stress like heat and substantial changes in pH that would break weaker bonds. The succession of phosphodiester bonds traces the backbone of the DNA strand.
The phosphodiester linkages in a DNA strand give it polarity, which means that one end differs from the other. In Fig. 3.7, the nucleotide at the top has a free 5′ phosphate, and is known as the 5′ end of the molecule. The nucleotide at the bottom has a free 3′ hydroxyl and is known as the 3′ end. The DNA strand in Fig. 3.7 has the sequence of bases AGCT from top to bottom, but because of strand polarity we need to specify which end is which. For this strand of DNA, we could say that the base sequence is 5′-AGCT-3′ or equivalently 3′-TCGA-5′. When a base sequence is stated without specifying the 5′ end, by convention the end at the left is the 5′ end. Hence, we could say the sequence in Fig. 3.7 is AGCT, which means 5′-AGCT-3′.
3.2.3 Cellular DNA molecules take the form of a double helix.
To the knowledge of the chemical makeup of the nucleotides and their linkages in a DNA strand, Watson and Crick added results from earlier physical studies indicating that DNA is a long molecule. They also relied on important information from X-ray diffraction studies by Rosalind Franklin implying that DNA molecules form a helix with a simple repeating structure. Analysis of the pattern of X-rays diffracted from a crystal of a molecule can indicate the arrangement of atoms in the molecules.
With these critical pieces of information in hand, Watson and Crick set out to build a model of DNA that could account for the results of all previous chemical and physical experiments, using sheet metal cutouts of the bases and wire ties for the sugar–phosphate backbone. After many false starts and much disappointment, they finally found a structure that worked. They realized immediately that they had made one of the most important discoveries in all of biology, and that day, February 28, 1953, they lunched at the Eagle, a pub across the street from their laboratory, where Crick loudly pronounced, “We have discovered the secret of life.” The Eagle is still there in Cambridge, England, and sports on its wall a commemorative plaque marking the table where the two ate.
Why all the fuss (and why the Nobel Prize 9 years later)? First, let’s look at the structure, and you will see that the structure itself tells you how DNA carries and transmits genetic information. The Watson-Crick structure, now often called the double helix, is shown in Fig. 3.8. Fig. 3.8a is a space-filling model, in which each atom is represented as a color-coded sphere. The big surprise of the structure is that it consists of two DNA strands like that in Fig. 3.7, each wrapped around the other in the form of a helix coiling to the right, with the sugar–phosphate backbones winding around the outside of the molecule and the bases pointing inward. In the double helix, there are 10 base pairs per complete turn, and the diameter of the molecule is 2 nm, a measurement that is hard to relate to everyday objects, but it might help to know that the cross section of a bundle of 100,000 DNA molecules would be about the size of the period at the end of this sentence. The outside contours of the twisted strands form an uneven pair of grooves, called the major groove and the minor groove. These grooves are important because proteins that interact with DNA often recognize a particular sequence of bases by making contact with the bases via the major or minor groove or both.
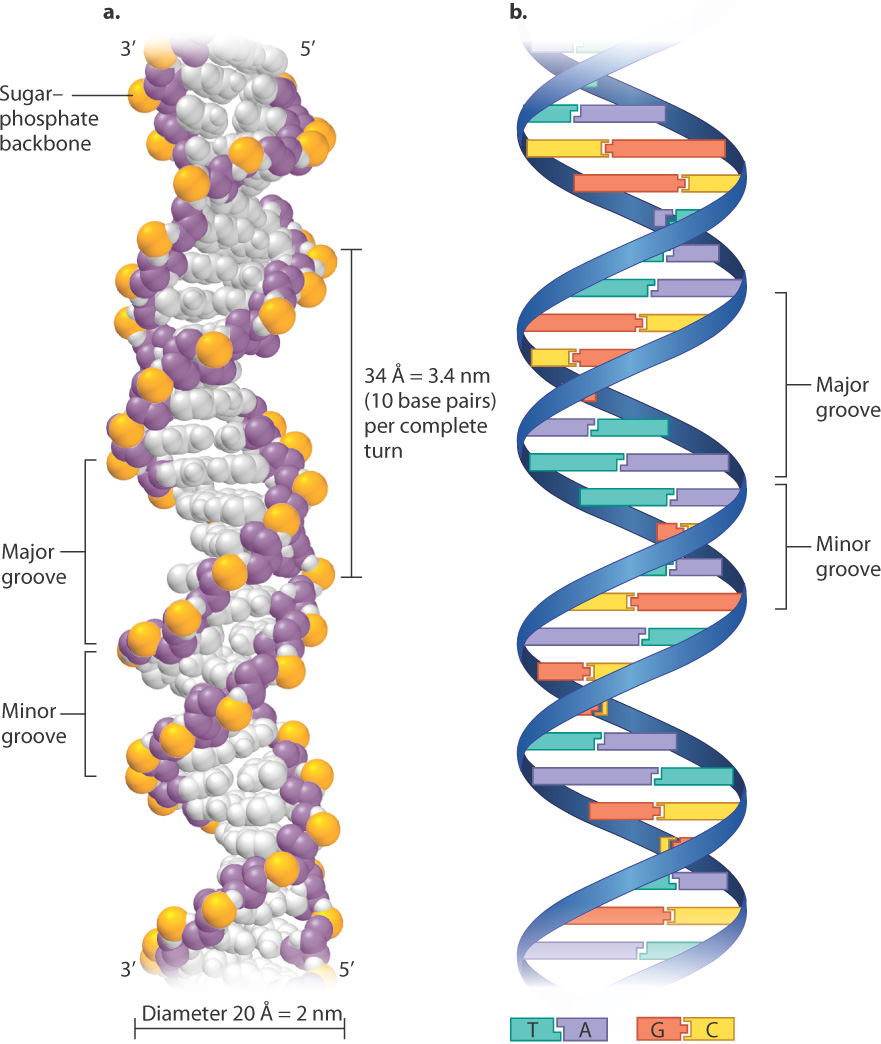
3-7
Importantly, the individual DNA strands in the double helix are antiparallel, which means that they run in opposite directions. That is, the 3′ end of one strand is opposite the 5′ end of the other. In Fig. 3.8a, the strand that starts at the bottom left and coils upward begins with the 3′ end and terminates at the top with the 5′ end, whereas its partner strand begins with its 5′ end at the bottom and terminates with the 3′ end at the top.
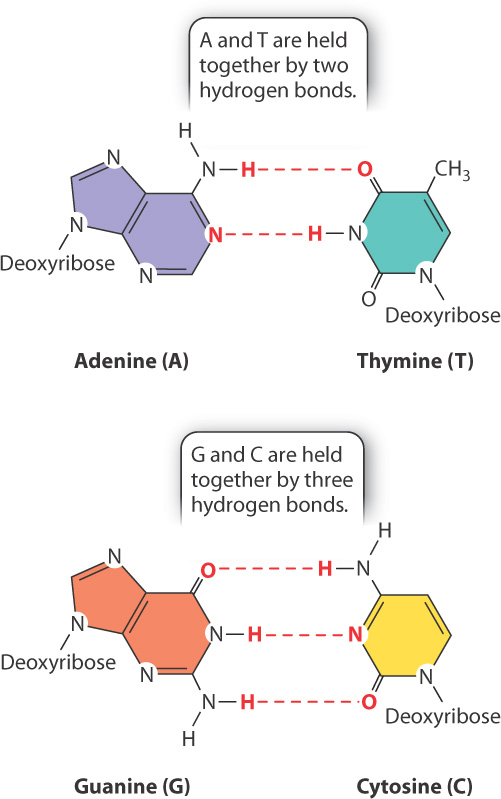
Fig. 3.8b shows a different depiction of double-stranded DNA, called a ribbon model, which clearly shows the sugar–phosphate backbones winding around the outside with the bases paired between the strands. The ribbon model of the structure closely resembles a spiral staircase, with the backbones forming the banisters and the base pairs the steps. If the amount of DNA in the human genome (3 billion base pairs) were scaled to the size of a real spiral staircase, it would reach from Earth to the moon.
Note that, as shown in Fig. 3.8b, an A in one strand pairs only with a T in the other, and G pairs only with C. Each base pair contains a purine and a pyrimidine. This precise pairing maintains the structure of the double helix, since pairing two purines would cause the backbones to bulge, and pairing two pyrimidines would cause them to narrow. The pairing of one purine with one pyrimidine preserves the distance between the backbones along the length of the entire molecule.
Because they form specific pairs, the bases A and T are said to be complementary, as are the bases G and C. Why is it that A pairs only with T, and G only with C? Fig. 3.9 illustrates the answer. The specificity of base pairing is brought about by hydrogen bonds that form between A and T (two hydrogen bonds) and between G and C (three hydrogen bonds). A hydrogen bond in DNA is formed when an electronegative atom (O or N) in one base shares a proton (H) with another electronegative atom in the base across the way. Hydrogen bonds are relatively weak bonds, typically 5% to 10% of the strength of covalent bonds, and can be disrupted by high pH or heat. However, in total they contribute to the stability of the DNA double helix.
3-8
An almost equally important factor contributing to the stability of the double helix is the interactions between bases in the same strand (Fig. 3.10). This stabilizing force is known as base stacking, and it occurs because the nonpolar, flat surfaces of the bases tend to group together away from water molecules, and hence stack on top of one another as tightly as possible.
3.2.4 The three-dimensional structure of DNA gave important clues about its functions.
The double helix is a good example of how chemical structure and biological function come together. The structure of the molecule itself immediately suggested how genetic information can be stored in DNA. One of the most important features of DNA structure is that there is no restriction on the sequence of bases along a DNA strand. The lack of sequence constraint suggested that the genetic information in DNA could be encoded in the sequence of bases along the DNA, much as textual information in a book is stored in a sequence of letters of the alphabet. With any of four possible bases at each nucleotide site, the information-carrying capacity of a DNA molecule is unimaginable. The number of possible base sequences of a DNA molecule only 133 nucleotides in length is equal to the estimated number of electrons, protons, and neutrons in the entire universe! This is the secret of how DNA can carry the genetic information for so many different types of organisms, and how variation in DNA sequence even within a single species can underlie genetic differences among individuals.
Watson and Crick’s model still left many questions unanswered in regard to how the information is read out and what it does, but in the years following it became clear that the major processes in the readout of genetic information were transcription and translation (see Fig. 3.3).
The sequence of bases along either strand completely determines that of the other because wherever one strand carries an A, the other must carry a T, and wherever one carries a G, the other must carry a C. The complementary base sequences of the strands means that, in any double-stranded DNA molecule, the total number of A bases must equal that of T, and the total number of G bases must equal that of C. These equalities are often written in terms of the percent (%) of each base in double-stranded DNA. In these terms, the base-pairing rules imply that %A = %T and %G = %C. Interestingly, these equalities were known and described by the American biochemist Erwin Chargaff before the double helix was discovered, and they provided important clues to the structure of DNA. It was the double helix that finally showed why they are observed.
3-9
Question Quick Check 1
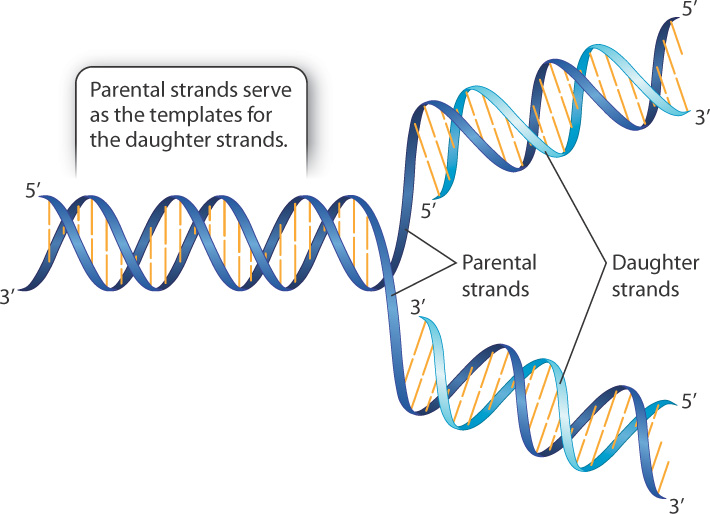
CGUT4V8KOdhH5s+TWs8+TAfzjbnpv8X2NB1jMX2nlbczri20GgECHmmkVkDtmVQ/2yHHlqdhnBQKXJvfMf5UFV0rnJ25epP3SNuH07ZFa1ult6wHDY6UXUuxwLcQQCZ0dC7gSHLa62NQnGN7h7ztZ/lOKgrY6lscBZUaWius8tMW/SLg5d3+2+s8xBQyavL/heLfjcpDPKYrSqEkixRQyuqaVC0xcomVWv/Ko4QdQ4Y2XrK182MNkGnMqYJj4YjEThe complementary, double-stranded nature of the double helix also suggested a mechanism by which DNA replication could take place. In fact, in their 1953 paper describing the structure of DNA, Watson and Crick wrote, “It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.”
A simplified outline of DNA replication is shown in Fig. 3.11. In brief, the two strands of a parental double helix unwind, and as they do each of the parental strands serves as a pattern, or template, for the synthesis of a complementary daughter strand. When the process is complete, there are two molecules, each of which is identical in sequence to the original molecule, except possibly for rare errors (mutations) that cause one base pair to be replaced with another. Although the process of replication as depicted in Fig. 3.11 looks exceedingly simple and straightforward, there are technical details that make the actual process more complex. These are discussed in Chapter 12.
3.2.5 Cellular DNA is coiled and packaged with proteins.
The DNA molecules inside cells are highly convoluted. They have to be because DNA molecules in cells have a length far greater than the diameter of the cell itself. The DNA of a bacterium known as Mycoplasma,, for example, if stretched to its full linear extent, would be about 1000 times longer than the diameter of the bacterial cell. Many of the double-stranded DNA molecules in prokaryotic cells are circular and form supercoils in which the circular molecule coils upon itself, much like what happens to a rubber band when you twist it between your thumb and forefinger (Fig. 3.12). Supercoiling is caused by enzymes called topoisomerases that cleave, partially unwind, and reattach a DNA strand, which puts strain on the DNA double helix. Supercoils then relieve the strain and help to preserve the 10 base pairs per turn in the double helix.
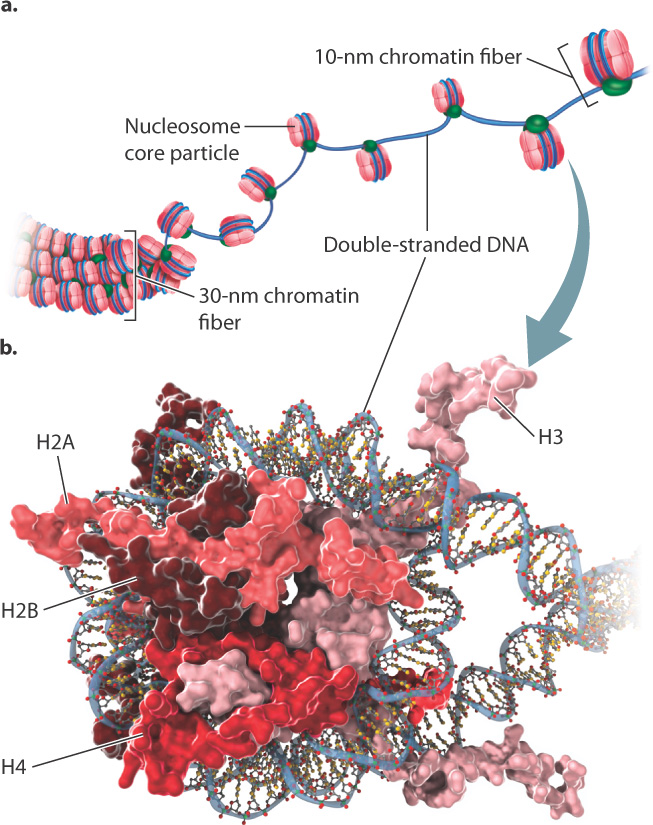
In eukaryotic cells, most DNA molecules in the nucleus are linear, and each individual molecule forms one chromosome. There is a packaging problem here, too, which you can appreciate by considering that the length of the DNA molecule contained in a single human chromosome is roughly 6000 times greater than the average diameter of the cell nucleus (Fig. 3.13). Double-stranded DNA molecules in eukaryotes are usually packaged with proteins called histones into a 30-nm chromatin fiber (Fig. 3.13a). In regions of the nucleus in which transcription is actively taking place, the 30-nm fiber is usually relaxed into a 10-nm chromatin fiber (Fig. 3.13a), which is about 5 times the diameter of the double helix. Chromatin fibers of either dimension are often referred to simply as chromatin.
3-10
The 10-nm chromatin fiber is composed of a beadlike repeating unit known as a nucleosome (Fig. 3.13b). The core particle of each nucleosome is a flattened sphere consisting of approximately 150 base pairs of double-stranded DNA wrapped around a cluster of two molecules each of the histones H2A, H2B, H3, and H4. Each of these histone proteins is rich in the positively charged amino acids lysine and arginine, which enables them to form ionic bonds with the negatively charged sugar–phosphate backbone of DNA. The DNA double helix is wrapped twice around the core particle.
Histone proteins are found in all eukaryotes, and they interact with double-stranded DNA without regard to sequence. In addition, histone proteins from any organism can form nucleosomes with the DNA of any other organism. The reason for this ability is that these proteins are evolutionarily conserved, which means that they are very similar in sequence from one organism to the next. Conserved DNA, RNA, or protein sequences indicate that they serve an essential function and therefore have not changed very much over long stretches of evolutionary time. The more distantly related two organisms are that share conserved sequences, the more highly conserved the sequence is. Among the histone proteins, histones H3 and H4 are the most conserved; for example, 98% of the amino acids in histone H4 are identical in organisms as diverse as domesticated cattle and the garden pea. Histones are very highly conserved, reflecting their key role in packaging DNA.